
一种面向结构化文本图像识别的深度学习模型
2020-04-08 12:48唐三立程战战
杭州电子科技大学学报(自然科学版) 2020年2期
唐三立,程战战,钮 毅,雷 鸣
(杭州海康威视数字技术股份有限公司,浙江 杭州 310051)
0 引 言
结构化文本识别[1]是在通用文本识别技术[2]的基础上,增加了文本结构化的功能需求。其中,通用文本识别技术通常应用于非结构化文本场景,例如交通场景图像中的车牌号识别、物流运输场景图像中的集装箱号识别等。在这类场景中,仅需通过检测算法对图像中的车牌号、集装箱号文本区域进行定位,再使用文本识别模型对仅包含文本的图像区域进行识别,从而得到所需的文本字符串。而在结构化文本场景中,要求模型不仅仅能检测、识别出图像中的文本,还要对不同字段的文本属性进行分类。例如,对于一张出租车票,要求模型将识别得到的“2017年01月01日”归为“日期”类别,将识别得到的“上海市”归为“归属地”类别。因此,结构化文本图像识别解决方案需要具有对图像中若干文本区域检测、区域内文本识别和区域内文本属性分类等3种能力。现有结构化文本识别系统通常由3个分立的模型构成:文本检测模型、文本识别模型及信息结构化模型。对于一张结构化文本图像,先使用检测模型[3-5]对图像中的文本字段进行定位,然后将裁剪后的文本子图输入识别模型[6-8]获得相应的文本内容,最后根据识别结果以及文本所在图像中的位置,设计一套基于版式、规则或者可学习模型的算法[9],进而得到每个文本的属性类别。但是,这3个子模型在训练时单独优化,各自达到最优解时往往不是全局的最优解;每个检测到的文本区域均需要送入识别模型进行文本识别,大量不感兴趣区域的文本识别造成计算资源的浪费;同时,模型数量多、参数量大、开发调试困难。针对以上不足,本文提出一种可端到端训练优化的结构化文本识别模型,包含3个分支,即文本检测、结构化与识别。3个分支共享1个图像特征提取子模块,可进行全局训练优化;并将结构化分支嵌入检测与识别分支之间,利用结构化分支对检测得到的所有文本区域进行筛选,仅将“感兴趣”属性对应的文本区域送入识别分支进行识别;同时,通过端到端训练使图像特征提取子模块接收来自检测、识别分支的监督信号,提取特征的同时能抽取到文本信息结构化所需的文本几何特征和语义特征,从而使得文本结构化分支有较高的分类准确率。
1 结构化文本识别模型设计
基于单模型的可端到端训练的结构化文本识别模型网络结构如图1所示,包含卷积特征提取模块、文本区域粗定位模块、文本区域精定位与属性分类模块和文本识别模块。一张输入图像经过卷积特征提取模块得到相应的卷积特征,常用的卷积特征提取网络有残差网络(Residual Networks,ResNet)[10]、VGGNet[11]等。图像卷积特征通过文本区域粗定位模块得到文本区域矩形框坐标,可通过区域生成网络(Region Proposal Network, RPN)[12]等网络来实现。根据粗定位的矩形坐标在全局卷积特征中截取相应区域的特征,并通过可求导的特征对齐方式缩放至固定尺寸。再由文本区域精定位与属性分类模块获得精确的文本区域坐标与文本属性,根据文本属性筛选出感兴趣的字段区域。随后,通过1次特征对齐得到用于识别的卷积特征,最后通过序列解码得到每个感兴趣字段区域内的识别结果字符串。至此,依次获得输入图像中图像文本区域坐标、对应文本区域的属性以及文本区域内的字符串识别结果。
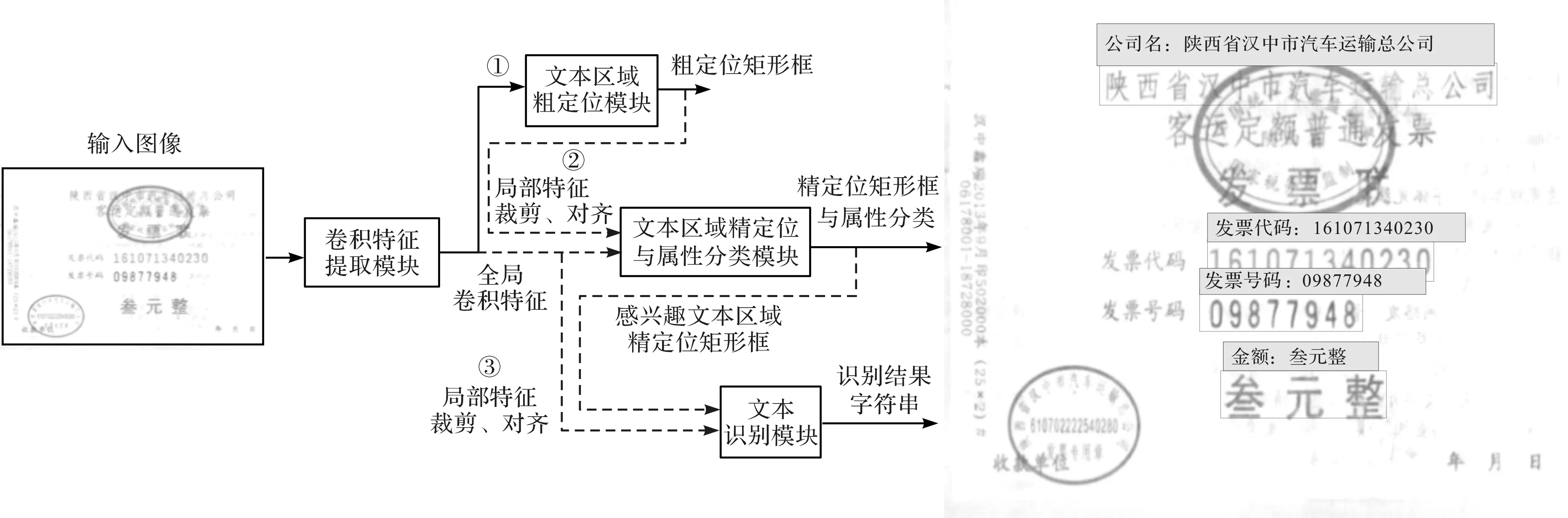
图1 可端到端训练的文本结构化识别模型网络结构图
1.1 卷积特征提取模块
本文采用ResNet50[10]结合特征金字塔(Feature Pyramid Network, FPN)[13]模块得到卷积特征,并且在ResNet50的最后一个卷积层增加一个步长为2的最大池化层,得到相对于原图下采样4,8,16,32,64倍的5组特征图。通过引入FPN模块,5组卷积特征图各自融合来自更高层级的、语义信息更丰富的上下文特征,在保留高分辨率的纹理特征的同时增大了网络的感受野。因此,卷积特征提取模块能获取输入图像不同分辨率层级的卷积特征,为后续检测、识别不同尺寸大小的文本奠定基础。
1.2 文本区域粗定位模块
文本区域粗定位模块与Faster RCNN[12]网络中RPN模块类似,由全卷积网络构成。通过计算预先生成的一系列不同大小、长宽比的锚点矩形框(anchor)与图中真实文本区域的交并比(Intersection of Unit,IoU)来确定其是否包含文本区域以及其与真实文本框的几何差值,即对应于文本区域粗定位模块的分类损失与回归损失。
对于分类损失,当IoU大于0.7时,为正样本,标注为p*=1;当IoU小于0.3时,为负样本,p*=0;当IoU介于0.3与0.7之间时,在训练时将其忽略。对于RPN预测的某一锚点矩形框为正样本的概率p,使用交叉熵来定义其分类损失:
(1)
对于回归损失,本文只将属于正样本的锚点矩形框与其对应的真实文本框的差值作为网络的回归目标。设锚点矩形框的几何中心、宽高分别为xa,ya,wa,ha,与其对应的真实文本矩形框的几何中心、宽高分别为xg,yg,wg,hg。对于锚点矩形框,网络的回归目标为:
(2)
回归损失用连续可导的SmoothL1函数计算:
(3)
式中,σ为预先设定的可调参数。
由此,对于某一锚点矩形框,RPN对其与对应的真实文本矩形框预测的偏差为ax,ay,aw,ah,则RPN模块的回归损失函数为:
(4)
式(4)中对应式(3)中SmoothL1函数的超参σ设为1/9。
本文将锚点矩形框的宽长比设置为0.1,0.2,0.4,0.8,1.6,3.2,尽可能覆盖极长、短、竖排文本;锚点矩形框面积设为322,642,1282,2562像素,尽可能覆盖不同大小的文本。不同长宽比和尺寸相互组合,使RPN输出的预测图的每个坐标位置对应6×4=24个锚点矩形框区域。
1.3 文本区域精定位与属性分类模块
将经过RPN网络预测误差矫正过的正样本锚点矩形框和一定数量的负样本锚点矩形框作为提议矩形框(proposal),由RoIAlign[12]特征截取对齐后,得到固定尺寸的特征图,再送入文本区域精定位与属性分类模块。
文本区域精定位与属性分类模块主要承担结构化文本识别任务中文本高精度检测与信息结构化的功能,由若干卷积与全连接运算构成,其网络结构如图2所示。
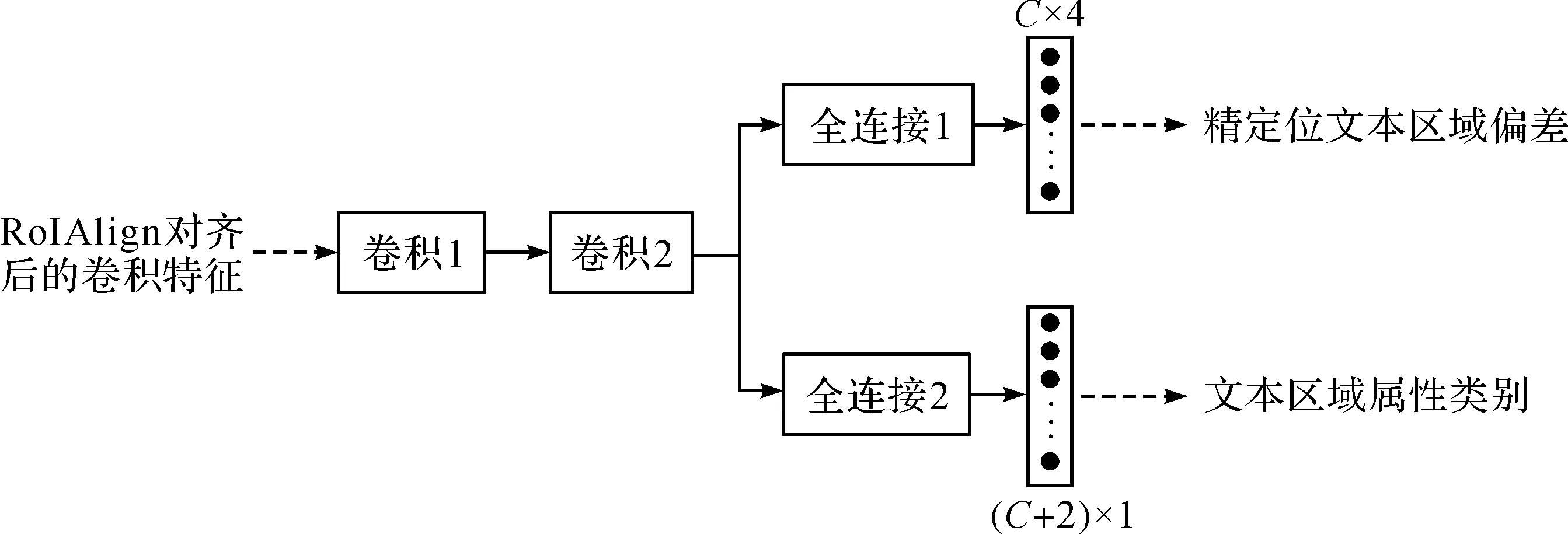
图2 文本区域精定位与属性分类模块网络结构图
对于文本高精度位置的检测,模型通过预测提议矩形框到其对应的真实矩形框的中心点坐标偏差px,py和宽高偏差pw,ph,实现文本区域定位的二次矫正。同时,文本高精度检测仅对感兴趣区域的提议矩形框进行预测,不对负样本及属性为不感兴趣的文本区域进行预测。其损失误差与RPN网络中定义基本一致,
(5)
式(5)中对应式(3)中SmoothL1函数的超参σ设为1.0。
对于文本属性的分类,通过一个简单的全连接网络来实现。对于需要分为感兴趣的C类属性的不同文本区域,通过全连接网络输出C+2个预测单元,分别代表对输入提议矩形框预测的属于感兴趣的C类文本区域属性、不感兴趣的1类文本区域属性以及1类背景区域的概率,该分类损失使用多分类的交叉熵Lcls2进行衡量。
至此,通过文本区域精定位与属性分类模块,本文提出的结构化文本识别模型已经能够对结构化文本图像中文本区域进行精确定位,同时对文本属性进行分类,实现了结构化文本识别模型中文本检测、信息结构化的功能。
1.4 文本识别模块
本文采用与文本区域精定位及属性分类模块相同的特征裁剪及对齐方式对感兴趣的C类文本区域进行处理,获得感兴趣区域文本纹理特征,并将这些特征送文本识别模块。文本识别模块由任意的基于CTC[14]或者Attention[6-7]的文本识别网络构成,文本所采用的识别模块由一系列卷积特征提取操作、基于双向长短期记忆模型(Long Short-Term Memory, LSTM)的序列编码操作以及基于注意力(Attention)的序列解码操作组成,最后对解码后的特征通过全连接网络对不同的字符进行分类。其中,识别分支的卷积特征提取由修改后的ResNet32[10]构成,将步长为2的卷积下采样替换为步长为2的最大值池化(MaxPooling)。为了适应大多数水平排布文本特征提取,保证特征在水平方向上有较高分辨率,将最后2个池化最大值池化水平方向上步长设为1。双向LSTM模块隐层及输出层特征维度均为256。Attention序列解码模块的隐层特征维度为256,序列长度为25。
设zi为识别模块在第i时刻预测的字符,oi为LSTM在第i时刻的输出,h为文本区域的卷积特征,其特征图高为1。识别模块输出端全连接网络权重为Wout,bout,则识别模块的预测输出表示为:
p(zi|z1,…,zi-1,h)=Softmax(Woutoi+bout)
(6)
LSTM的外部输入为经过Attention加权得到的文本区域的卷积特征ci,LSTM网络第i-1时刻的隐层特征为si-1,则LSTM网络表示为:
(oi,si)=LSTM(zi-1,si-1,ci)
(7)
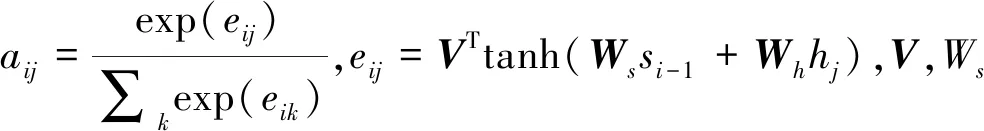
对于长度为N的字符串,设数据集中中英文字符类别数目为K,字符串中第n个字符标签为yn,则基于Attention解码的文本识别网络损失函数如下:
(8)
综上,本文提出的结构化文本识别模型兼具了文本检测、文本属性分类、文本图像识别功能。上述4个子模块中所有运算均可导,且各子模块衔接时使用可导的RoIAlign进行局部区域特征对齐,故本文模型可以进行端到端训练,其目标函数由文本粗定位模块、文本区域精定位与属性分类模块、文本识别模块的损失函数加权构成:
L=(Lcls+Lreg)+α(Lcls2+Lreg2)+βLrecog
(9)
式中,超参α与β分别控制文本区域精定位与属性分类模块、文本识别模块的损失占总损失的相对权重。为了缓解文本检测、识别分支训练速度差异大的问题,本文设为α=1,β=5。
2 实验分析
在自建的票据及电子简历等结构化文本场景数据集中验证本文提出的结构化文本识别模型的有效性。数据集如表1所示。数据集中各类票据图像均为扫描版图像,且票据主体占据图像区域的80%以上,电子简历数据直接从pdf格式简历转换至图像格式。

表1 结构化文本数据集
作为对照组,本文采用一个三阶段的结构化文本识别方案进行对比(后称为“三阶段模型”),分别为文本检测、文本识别与文本结构化(属性分类)独立模型或算法,这也是当前绝大多数结构化文本识别所采用的方案[2]。文本检测模型类似于1.2节所述的文本区域粗定位模块,文本识别模型类似于1.4节所述的文本识别模块,文本结构化模型为利用各类结构化文本图像特点定制的文本属性分类算法,其输入为图像中所有文本框坐标以及相应的文本内容,结合版式、规则等特点,输出每个文本矩形框所属的类别。上述3个独立的文本检测、识别、信息结构化模型均在表1相应数据集中进行训练及验证,各自达到最优后串接形成作为对照组的结构化文本识别解决方案。
本文提出的结构化文本识别模型以及作为对照的“三阶段模型”中的检测模型、识别模型、结构化模型均在8块V100 32GB的GPU上进行训练,其测试基于单块V100 32GB的GPU。对于模型效率的分析,采用帧率(Frame Per Second, FPS)进行衡量。在后续实验分析中,将本文提出的可端到端训练的结构化文本识别模型称为“单阶段模型”。
针对不同数据集特点,训练时进行以下数据扩增:(1)旋转:除电子简历数据集外,图像随机旋转(-10°,10°);(2)缩放:出租车发票、定额发票、火车票数据集长边随机缩放至(600,900)像素,电子简历数据集长边随机缩放至(1 200, 1 800)像素,短边进行等比例缩放;(3)图像亮度及对比度:亮度随机增加(-32,32)像素值,对比度随机缩放(0.5,1.5)倍。测试时,除电子简历数据长边缩放至1 500像素外,其余数据集图像长边均缩放至750像素,短边进行等比例缩放,在单一尺度下进行测试,无其它数据增强方式。
在出租车发票中,需要识别“发票代码”、“发票号码”、“日期”、“上车时间”、“下车时间”、“行驶里程”、“单价”、“等候时间”、“金额”等9个感兴趣的字段,两种模型在出租车发票测试集中的测试结果如表2所示,其预测结果可视化如图3所示。图3中,冒号前表示结构化分支预测的文本框属性,冒号后表示识别分支预测的字符串结果,属性“nc”表示不感兴趣的文本区域。为了更好地区分不同属性的文本区域,图3中用不同颜色的矩形框表示不同属性类别的文本。

表2 出租车发票测试集各字段准确率与帧率
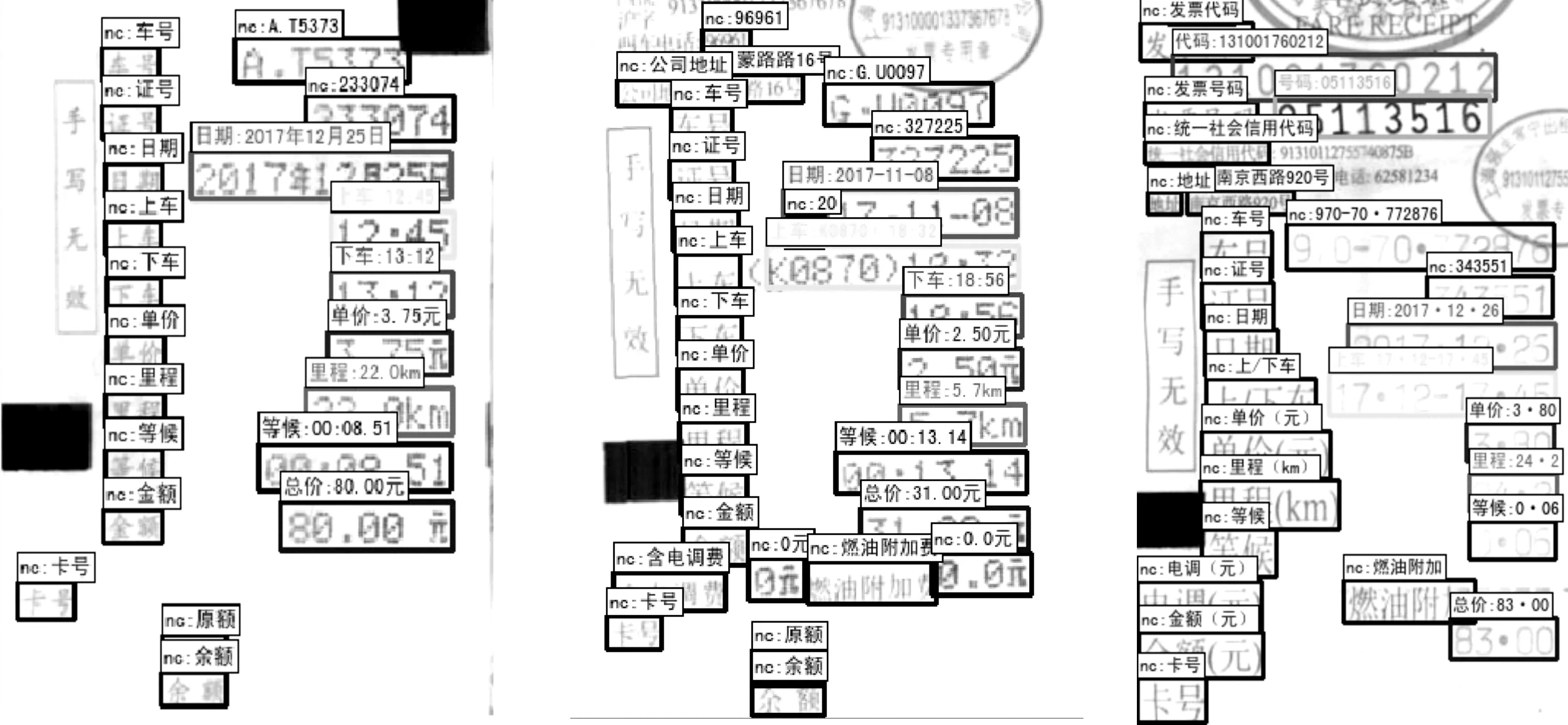
图3 出租车测试集的结构化文本识别结果可视化图
两种模型在火车票、定额发票、简历测试集中的测试结果如表3所示。

表3 火车票、定额发票、简历测试集各字段准确率与帧率
由表2和表3可以看出:本文提出的结构化文本识别模型不仅在识别精度上优于三阶段模型,同时帧率上有3~5倍的提高,效率上有明显的优势。
分别使用本文提出的单阶段结构化文本识别模型、现有的三阶段模型在火车票数据集上进行可视化分析,其中部分敏感信息已被人工擦除,结果如图4所示。图4中,在“起始城市”字段识别时,三阶段模型将“站”表示地点的关键信息错误地预测成“不感兴趣”,而单阶段模型通过联合训练使得结构化分支同时接受来自检测的文本几何特征与来自识别的语义特征,从而做出正确的属性类型预测。又如“日期时间”字段,由于时间冒号“:”不清晰导致了三阶段模型输出缺少“:”,给后续结构化分析增加了难度。而单阶段模型的识别分支通过接受来自结构化分支的“日期时间”字段属性特征,使得识别分支面对模糊字段仍然做出正确预测。因此,单阶段模型通过联合训练优化能有效消除各模块单独训练时不兼容的依赖关系,各子模块之间相辅相成,达到联合最优效果。

图4 两种模型在火车票图像上的识别结果
3 结束语
本文提出一种集检测、属性分类、识别功能为一体的结构化文本识别模型,在识别精度上达到或超过由3个独立子模型构成的结构化文本识别算法,效率上也有3~5倍的提升。本文设计的文本属性分类模块通过学习模型对文本属性进行预测,避免了人工设计繁琐的规则,在实际应用中能有效减少开发、维护成本,具有较大的工业应用价值。但是,本文所提出的结构化文本识别模型仅局限于小角度倾斜的扫描版结构化文本图像识别,对于较大角度的倾斜、弯曲等文本图像场景,模型的文本识别与字段属性分类精度受到一定程度上的影响。此外,随着检测、识别、结构化等子领域技术的发展,本文所述结构化文本识别模型中各检测、识别、文本结构化等子模块可以进行同步更新换代,从而进一步提高模型的性能。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
电子制作(2019年11期)2019-07-04
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
