
重介质选煤过程模型与数据混合驱动的自适应运行反馈控制
2020-04-11 13:52伟张凌智褚菲马小平
控制理论与应用 2020年2期
代 伟张凌智褚 菲马小平
(1.中国矿业大学信息与控制工程学院,江苏徐州 221008;2.东北大学流程工业综合自动化国家重点实验室,辽宁沈阳 110018)
1 引言
煤炭洗选过程是煤炭生产和高效利用过程中的重要工序,也是实现煤炭清洁生产利用最直接、最有效的措施之一.重介质旋流器选煤是用密度介于净煤与矸石之间的介质进行分选的过程[1].其以分选精度高、密度调节范围宽、处理量大等特点,被广泛使用[2–4].当前,在我国能源结构优化的趋势下,发展洁净煤技术是提高煤质的重要举措之一[5].由于灰分是评价重介质选煤产品质量的重要指标,因此,实现灰分的稳定控制成为重介质选煤过程控制系统的主要任务.
长期以来,由于重介质悬浮液密度对分选效果的影响最直接、最重要,直接决定精煤质量和产率[6],因此控制系统的研究集中在重介质悬浮液密度的稳定控制[7–9].但正如著名选矿控制专家D.Hodouin教授指出的“控制器的性能远没有为其选择正确设定值重要”[10],因此忽略偏离最优分选密度设定值的控制器难以保证系统运行最优化,也难以提高选煤产品质量.先进控制技术一直被认为是复杂工业过程提高产品质量、减少能耗与物耗的关键.如今,其前沿核心技术是工业过程运行反馈控制,其是通过实时优化设定值控制整个运行过程,实现工业过程的优化运行[11].本文即是研究对重介质悬浮液密度设定值进行调节的运行反馈控制方法.
重介质悬浮液密度可根据原煤信息和精煤产品,通过原煤的可选性浮沉试验所确定的分选密度理论来获得,然而在实际生产过程中,原煤性质等生产边界条件总是实时变化的,因此重介质悬浮液密度设定值也必须随着参数的改变而及时调整.为实现上述目标,文[12]在基础回路采用重介质悬浮液密度与介质桶液位模糊控制器的基础上,采用PID控制以及基于继电反馈的自整定算法,对重介质悬浮液密度进行设定值在线调节.但给定的PID控制器往往只能获到较为满意的结果,无法实现最优.为提高系统的最优性和鲁棒性,文[13]提出了基于模型预测控制(model predictive control,MPC)的重介质悬浮液密度在线优化方法,并通过仿真验证了对灰分控制的有效性.以提高煤质和保证系统稳定为目标,文[14]采用由最优前馈控制和MPC反馈控制组成的重介质悬浮液密度控制器,通过内环执行器控制作用,达到控制灰分的目的.但是由文[15–16]所建立的重介质选煤过程数学模型可知,重介质选煤过程具有强非线性特性,因此MPC的求解并非易事,其实时性难以保证.
当前,随着分布式控制系统(distributed control system,DCS)在重介质选煤过程中广泛使用,每天都在产生并存储着大量过程数据,这些数据隐含生产运行的各类信息,数据驱动方法通过利用被控系统的在线和离线数据,摆脱了对被控系统数学模型的依赖,得到了广泛应用[17–18].文[19]将已有的数据驱动控制方法分为3类,分别是基于在线数据的数据驱动控制理论与方法、基于离线数据的数据驱动控制理论与方法、基于在线和离线数据相结合的数据驱动控制理论与方法.数据驱动方法在重介质选煤过程中也已被尝试使用[20–22],主要集中在基于离线数据的方法研究.如,文[21]在重介质分选密度与液位解耦控制基础上,基于历史数据,采用时间序列的最小二乘支持向量机,建立了重介质悬浮液密度给定模型.文[22]以原煤灰分、精煤灰分实际值、重介质悬浮液实际密度作为输入,以重介质悬浮液设定值作为输出,建立了基于极限学习机的重介质悬浮液密度给定预测模型,并采用基于最大最小蚂蚁系统优化算法的抗滞后无模型自适应控制算法实现其跟踪控制.上述基于历史数据所建立的无模型密度设定值调节方法,虽然避免了对模型先验知识的依赖,但其外推能力差,在新过程或新工况下需要长时间的训练过程,实际工业生产难以接受.
本文为实现重介质悬浮液密度设定值的自适应在线调整,将数据驱动与基于模型的控制方法相结合,进行优势互补,利用先验知识所建立的重介质选煤过程模型以及在线运行数据,提出一种模型与数据混合驱动的重介质选煤过程自适应运行反馈控制方法,并分析了所提方法的稳定性.在重介质选煤三维虚拟仿真平台上进行的对比仿真实验表明了所提方法的有效性.
2 重介质选煤过程控制问题描述
2.1 重介质选煤过程描述
典型的重介质选煤过程由重介质旋流器、混料桶、合介桶、高浓介质桶、磁选机、脱水脱介筛,以及合介泵等若干执行器和仪表组成,如图1所示.

图1 典型重介质选煤过程工艺流程图Fig.1 Flow diagram of classical dense medium coal preparation process
经过脱泥和脱水处理后的原煤首先被送至混料桶与重介质悬浮液充分混合,形成矿浆后经给料泵进入重介质旋流器中进行煤矸分离;在重力和离心力的作用下,比重介质悬浮液密度低的精煤浮起并随内螺旋流上升,从溢流口排出,高密度矸石下沉并随外螺旋流从底流口排出;溢流和底流经脱水脱介筛处理后,精矿和尾矿矿浆分别进入相应的后续作业中,重介质通过磁选机进行回收;回收的介质流入合介桶,同时加入一定的高浓重介质或稀释水以保证分选所需要的重介质悬浮液密度.
2.2 重介质选煤过程运行反馈控制问题
灰分是反映煤矿产品质量的重要指标,其主要影响因素为重介质悬浮液密度和重介质旋流器入口压力.实际生产过程中,重介质旋流器入口压力往往固定为正常工作范围内的某一常值[23],因此灰分的控制主要通过调整重介质悬浮液密度来实现.在实际重介质选煤过程中,通常由操作员根据精煤灰分检测值,凭借人工经验给出重介质悬浮液密度设定值,然后基于DCS的基础回路控制系统采用PID等基础反馈控制算法,调整高浓重介质阀门开度和稀释水阀门开度,使重介质悬浮液密度跟踪其设定值,实现对精煤灰分的控制.
然而由于人的主观性和随意性,即使经验丰富的操作员也往往难以保证所给出的重介质悬浮液密度设定值适用于当前工况,特别是在原煤性质和处理量等边界条件频繁大范围波动情况下,重介质悬浮液密度设定值往往不能及时准确的得以调整,造成精煤灰分远远偏离目标值,生产出不合格精煤.重介质选煤过程运行反馈控制的目标即是在底层基础回路控制可实现重介质悬浮液密度跟踪其设定值的基础上,设计一个以重介质悬浮液密度设定值为输出的上层控制器,使灰分尽可能的接近其期望值.
2.3 重介质选煤过程特性分析
重介质选煤过程主要涉及混料、重介质旋流器分选以及重介质回收3个过程,根据物料平衡原理[15],分析各部分的动态特性,如下:
1)混料过程动态特性.
输送的原煤首先是与从合介桶中抽出的重介质悬浮液在混料桶内充分混合,进而送入重介质旋流器进行分选,根据质量平衡原理,可建立混料过程的动态模型:


2)重介质旋流器分选过程动态特性.
混合矿浆在重介质旋流器中,基于阿基米德原理,在离心力和重力的共同作用下分离成溢流和底流两部分矿浆,其中各成分的动态特性可通过以下质量平衡方程获得:
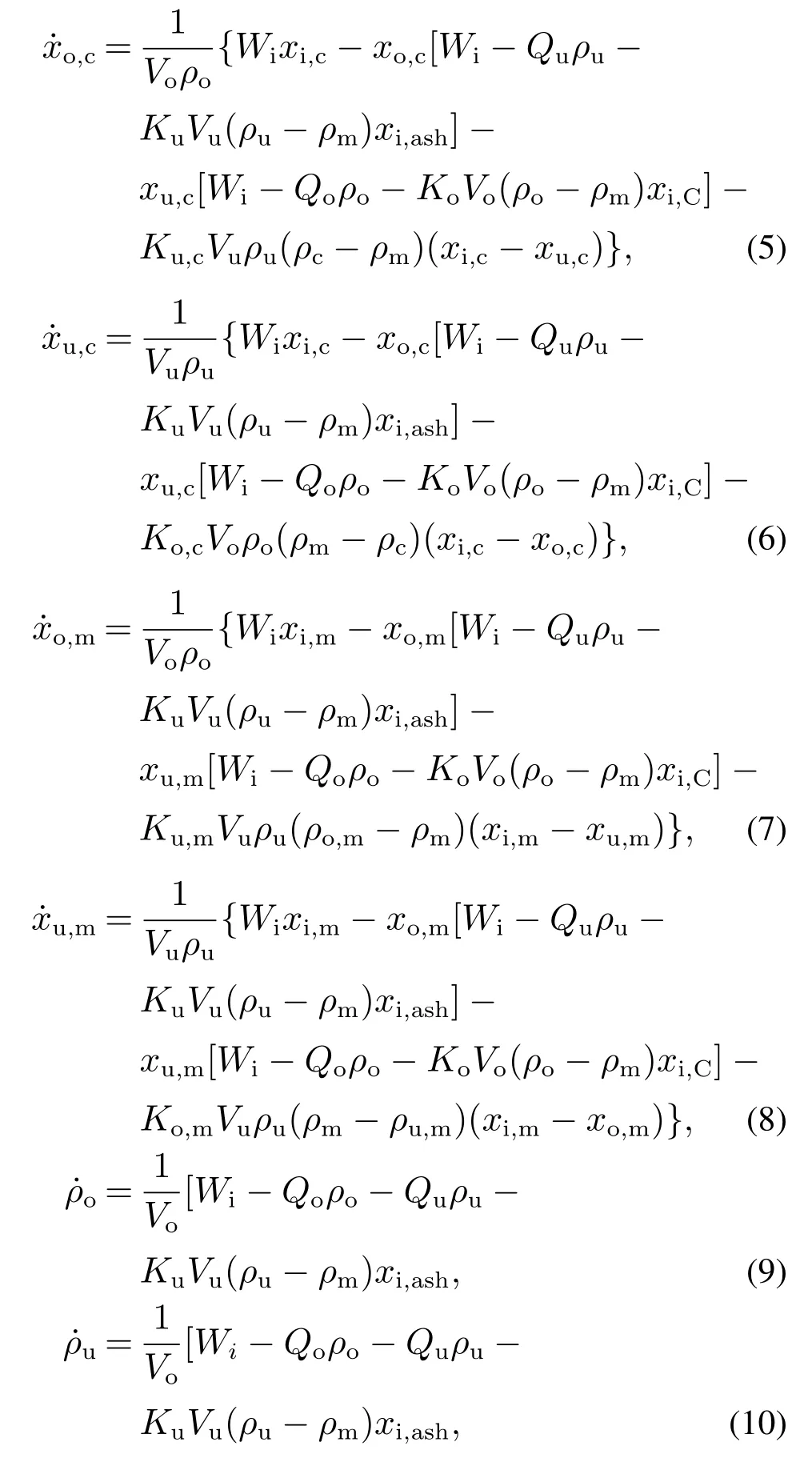
其中:xo,c和xu,c分别表示溢流和底流中各组分的百分含量;xo,m和xu,m分别表示溢流和底流矿浆中重介质的百分含量;xi,C=1−xi,m−Σcxi,c表示重介质旋流器给矿矿浆中的碳百分含量;ρo和ρu分别表示溢流和底流矿浆的密度;Vc为旋流器内矿浆体积,假设固定不变;Vo和Vu分别表示溢流和底流矿浆的体积;Qo和Qu分别表示溢流和底流矿浆的流速;Ko,c,Ku,c,Ko,m,Ku,m,Ko和Ku是与重介质旋流器相关的特定参数.由于矿浆在重介质旋流器中按一定比例α进行分离,因此可获得溢流和底流矿浆的体积和流速,即

3)重介质回收过程动态特性.
对重介质旋流器分离后溢流和底流中的重介质进行回收,首先需要进行脱水脱介筛处理,然后收集稀释的重介质溶液进而送入磁选机中进行回收,合格介质进入合介桶.
考虑到重介质在回收过程中必然有损耗,因此假设重介质旋流器到磁选机之间重介质的回收率为β,磁选机到合介桶之间重介质的回收率为γ,磁选机出口的重介质的密度维持在ρrm,由此重介质回收过程描述如下:
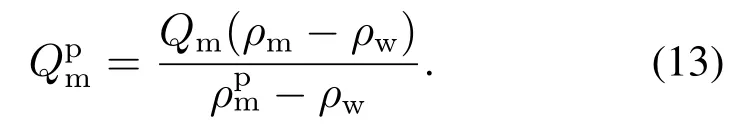
重介质流入磁选机中的质量流量为
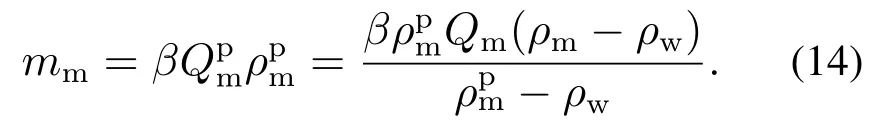
最终从磁选机回收的重介质体积流量Qrm为

合介桶中的重介质悬浮液密度是通过调节加入水、高浓介质来进行控制的,其动态特性可由下式表示:

其中:Qmm和ρmm表示高浓介质桶的体积流量和密度;Vcor表示合介桶中介质的体积;向合介桶中所补加水的体积流量Qw由阀门决定,即
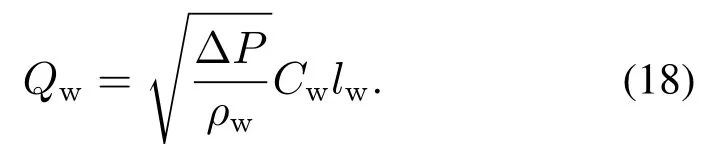
本文所研究的重介质选煤运行过程是以重介质悬浮液密度ρm作为输入u,以重介质旋流器溢流中灰分xo,ash作为输出y.根据灰分定义,重介质选煤运行过程的输出可表示为

由式(1)–(18)容易得到

其中f1,f2,f3和f4表示复杂非线性函数.
将式(20)和式(21)代入式(19)即可得到系统输入输出模型,由此可看出重介质选煤是一个复杂的非线性过程.此外,由于生产过程中原煤给煤量Wore由上游生产过程决定,可测但不可控,其与原煤成分在系统运行过程中不稳定、频繁波动,直接影响选煤产品灰分,因此重介质选煤是一个易受干扰影响的复杂非线性过程.
3 混合驱动的自适应运行反馈控制方法
3.1 控制策略
本文在重介质悬浮液密度回路控制基础上,通过在线调整重介质悬浮液密度设定值,实现对精煤灰分的稳定控制,从而保证选煤产品的质量.针对以灰分为输出,以重介质悬浮液密度为输入的重介质选煤运行过程,将机理模型在工作点处进行泰勒展开,得到
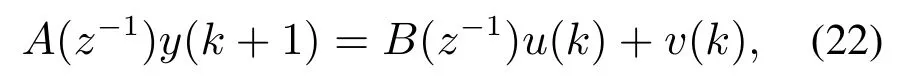
其中:A(z−1)=1+a1z−1+a2z−2;B(z−1)=b0+b1z−1;v(k)表示包括干扰在内的未建模动态.由于在正常运行过程中受诸多生产条件的限制,系统各运行参数均会维持在一定范围内,因此可认为经泰勒展开后的高阶项即v(k)是有界的,即|v(k)|M.
由于给煤量Wore及重介质溶液中各成分含量常常频繁波动,v(k)始终处于动态波动之中,导致控制器的积分作用失效,因此需要控制器能够消除v(k)的不利影响.为此,本文将数据建模、未建模动态补偿、PI控制、一步最优控制相结合,提出了模型与数据混合驱动的自适应运行反馈控制方法,如图2所示.所提方法由模型驱动的自适应PI控制器和数据驱动的虚拟未建模动态补偿器组成.其中自适应PI控制器基于线性辨识模型,采用一步最优性能指标设计控制律u1(k);虚拟未建模动态补偿器首先通过建立随机向量函数链接网络(random vector functional link networks,RVFLN),实现未建模动态v(k)的动态估计,进而通过设计补偿信号u2(k),以消除未建模动态v(k)的影响,从而形成组合控制律,即
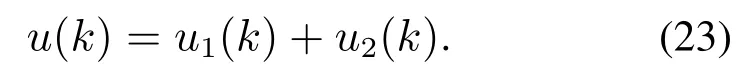
设计的控制器u1(k)和u2(k)分别表示为
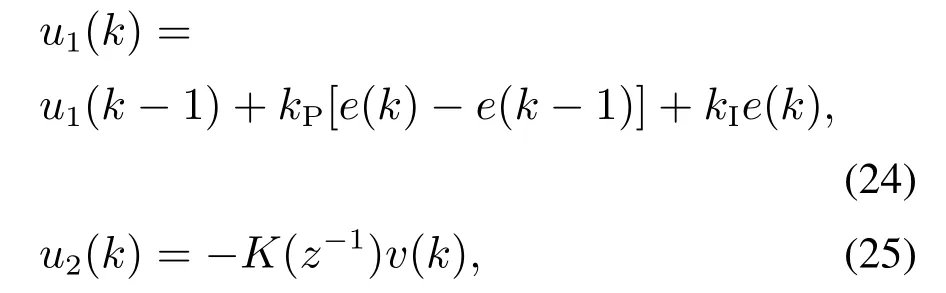
式中跟踪误差e(k)=ysp(k)−y(k),K(z−1)为关于z−1的多项式.

图2 模型与数据混合驱动的自适应运行反馈控制结构图Fig.2 Structure of model-data hybrid driven adaptive feedback control
所设计的虚拟未建模动态补偿器u2(k)用于消除未建模动态对系统的影响,从而可以设计线性控制器u1(k)将灰分y(k)控制在其期望值ysp(k)附近.
3.2 模型驱动的PI控制器
自适应PI控制器是在传统数字型增量式PI控制算法的基础上,针对系统线性化的模型部分(A,B)来进行设计的.
将式(24)中的传统数字型增量式PI控制算法转换为

式中:H(z−1)=1−z−1;G(z−1)=g0+g1z−1;g0=kP+kI以及g1=−kP.
将式(26)与式(25)代入式(23)中,得到控制器u(k):
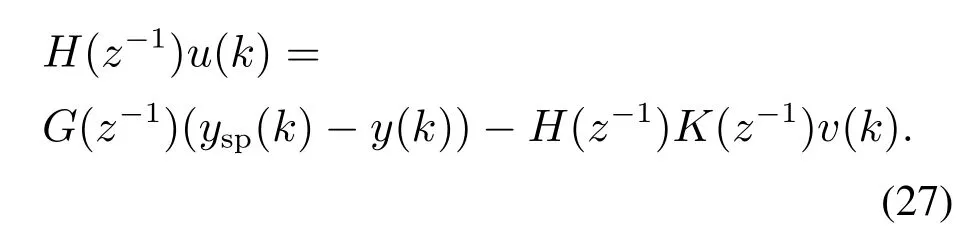
引入一步最优性能指标[24]:
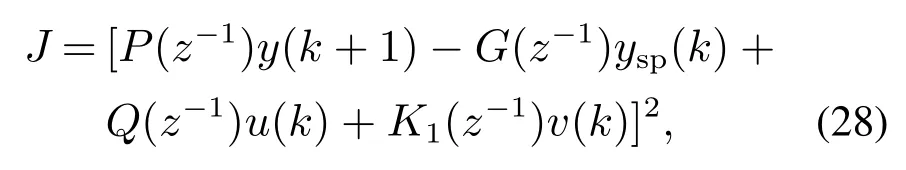
式中P(z−1),Q(z−1),K1(z−1)均为关于z−1的加权多项式.
引入广义输出Φ(k+1):

定义广义理想输出Φ∗(k+1):
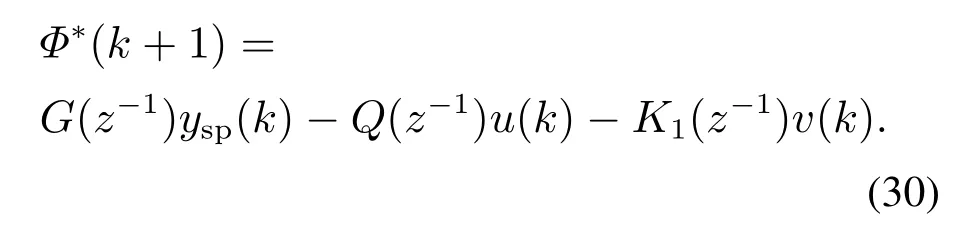
定义P(z−1):

定义一步最优预报Φ(k+1/k)为

令Φ(k+1/k)=Φ(k+1),将式(31)和式(32)代入式(29)可得

将式(33)代入式(28)中,同时使一步最优性能指标Jmin=0,可得带有未建模动态补偿的一步最优控制律为

由式(27)和式(34)可得多项式Q(z−1),K1(z−1)分别为

将式(34)和式(35)代入式(22)中,可以得到系统的闭环特征方程为
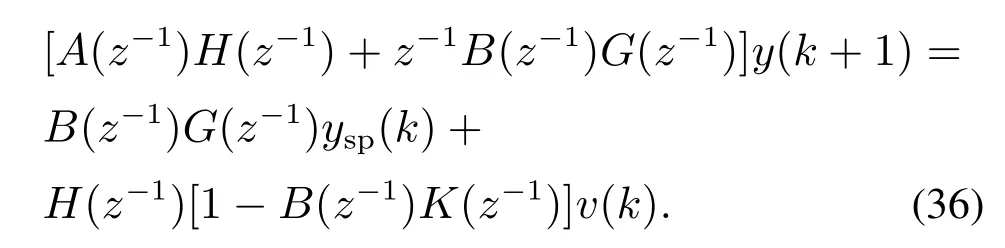
为保证系统稳定,根据Jury判据,可知需选择合适的控制器参数g0和g1,使其满足

3.3 数据驱动的未建模动态补偿器
由闭环特征方程(36)可得,当下式成立时将消除未建模动态v(k)对闭环系统的影响:

因此设置补偿项为

此时,未建模动态补偿器u2(k)可表示为
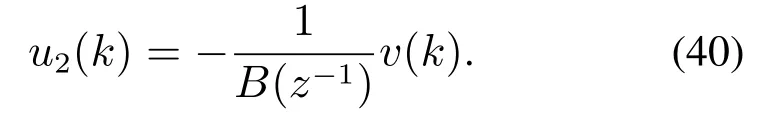
由上式可以看出,u2(k)的求解需要未建模动态v(k)和B(z−1).但由于v(k)未知,因此在实际过程中通过采用RVFLN来建立未建模动态估计模型,给出其估计值(k),从而求得u2(k)以消除未建模动态对闭环系统的影响.
由特性分析可知,v(k)主要受y(k),y(k −1),y(k−2),u(k),u(k −1)和Wore(k)的影响,但通过实验发现在采用RVFLN对未建模动态v(k)进行估计时,y(k −2)对估计精度的提高并不大,反而增加了模型的复杂度和在线学习的负荷.因此,针对本文所研究的这一典型的重介质选煤过程,所建立的基于RVFLN的未建模动态估计模型以y(k),y(k −1),u(k),u(k−1)和Wore(k)为输入,以估计值(k)为输出,如图3所示.

图3 RVFLN结构图Fig.3 Structure diagram of RVFLN
基于RVFLN的未建模动态估计模型可表示为
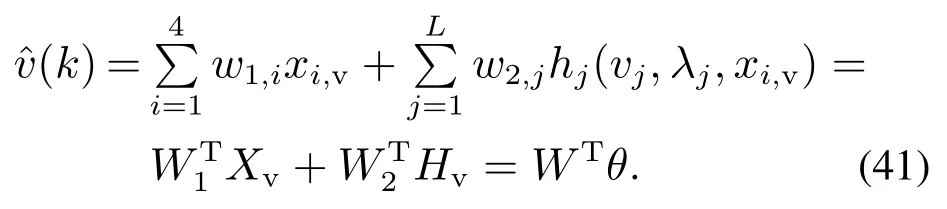
由图3和式(41)可以看出,未建模动态估计模型包括输入直接连接(direct links,DL)和输入非线性映射两部分.其中L为隐含层节点数,需根据实验来确定.Xv=[x1,vx2,vx3,vx4,vx5,v]T=[y(k)y(k −1)u(k)u(k −1)Wore(k)]T为模型输入;vj和λj分别表示从输入层到隐含层的输入权值和偏置,即隐含层节点随机参数;激活函数hj表示隐含层特征映射,通常采用径向基函数或者sigmoid函数;Hv为隐层输出矩阵;W1={w1,k}(k=1,2,···,5)表示从输入层到输出层的直接连接权值矩阵,W2={w2,j}(j=1,2,···,L)表示隐含层节点与输出节点之间的权值矩阵;θ=[XvHv]T;W=[WT1WT2]T表示输出权值矩阵.文[25]已证明RVFLN 的隐层参数(输入权值υj和偏置λj)在一个均匀分布范围内时随机选取,只调整输出权值W,则可以逼近任意连续函数.
3.4 控制器自适应在线更新
1)基于投影辨识算法的控制器线性模型更新.
由于系统模型A(z−1)和B(z−1)是由机理模型线性化所得,而机理模型是在众多理想情况下建立的,其与实际重介质选煤过程存在差异,再加上重介质选煤过程受到原材料和设备性能变化影响,总是处于缓慢变化过程中,因此系统模型A(z−1)和B(z−1)在系统运行时需在线更新,以匹配当前工况.
首先将式(22)改写为如下形式:

其中:X(k)=[y(k)y(k −1)u(k)u(k −1)]T表示由系统的输入输出组成的数据向量;ϑT=[a0a1b0b1].
根据式(42)定义非线性估计模型为


由此,k时刻系统的线性模型参数分别为

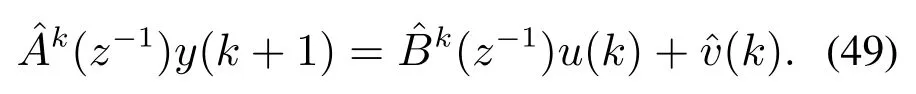
从而得到k时刻的控制律,表示为
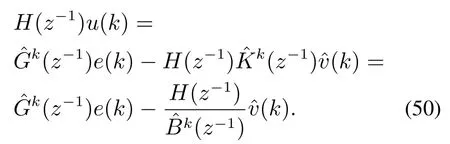
2)基于RVFLN的虚拟未建模动态估计模型更新.
本文采用(Levenberg Marquardt,LM)算法,通过使估计偏差,即

极小来校正未建模动态估计模型参数.
注1由于未建模动态在k时刻为未知参数,因此RVFLN在线学习是在k时刻采用v(k −1)与(k −1)之间的差值作为学习误差进行参数更新,其中v(k −1)可根据当前时刻采集的系统输出y(k)以及上一时刻计算的控制输入u(k −1),通过式(22)获得,即

其中A∗(z−1)=A(z−1)−1.
经更新后,输出权值W(k)为

其中:µ为一正数;αl >0为学习率;Ja(k)是ev(k)对W(k)的雅克比矩阵,即
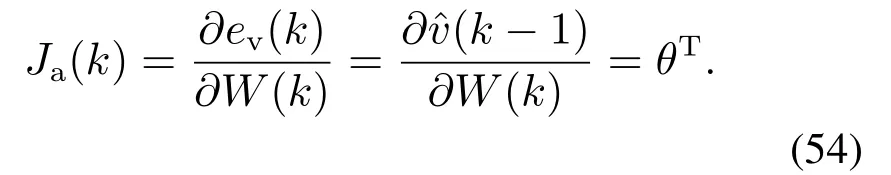
由此可得
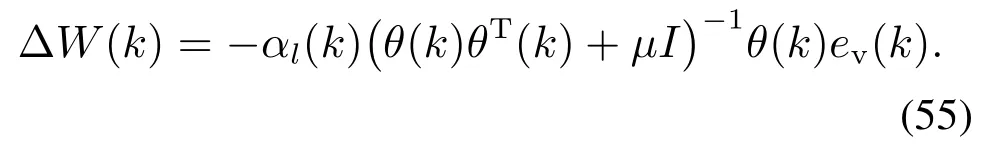
定理1当学习率αl满足

则网络的学习过程是收敛的.
证首先定义离散的Lyapunov函数为
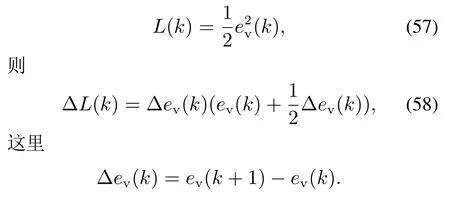
由全微分定理得
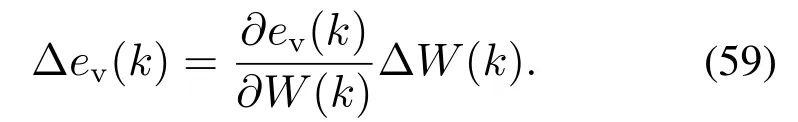
将式(54)–(55)和式(59)代入到式(58),可得

由于(θ(k)θT(k)+µI)−1是正定的,所以式(56)成立,则∆L(k)0,学习误差可收敛到0. 证毕.
4 稳定性分析
引理1投影辨识算法(44)–(46)有如下性质:
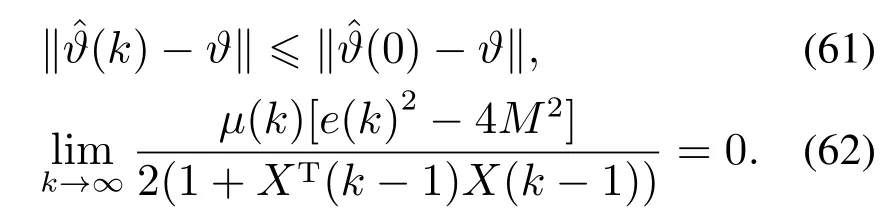
引理2将投影辨识算法(44)–(46)和自适应组合控制率(50)应用到系统(49)时,系统的输入输出动态特性方程如下,式中省略了多项式z−1:

式(63)得证. 证毕.
定理2通过采用实验方法选取合适的RVFLN参数以及学习率,使系统未建模动态估计误差满足|∆(k)|=|v(k)−ξ,其中ξ表示估计误差上界,则当k→∞时,在控制律(50)的作用下,被控对象的闭环系统输入输出一致有界,即
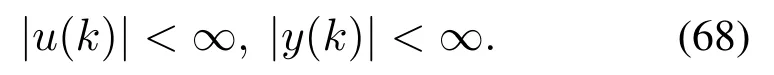
设定值ysp(k)与被控对象的输出值y(k)之间的稳态误差e(k)可满足
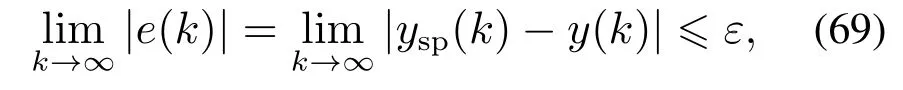
其中ε表示稳态误差的预设上界值.
证由式(63)可知重介质悬浮液密度u(k)与灰分期望值ysp(k)之间的关系为
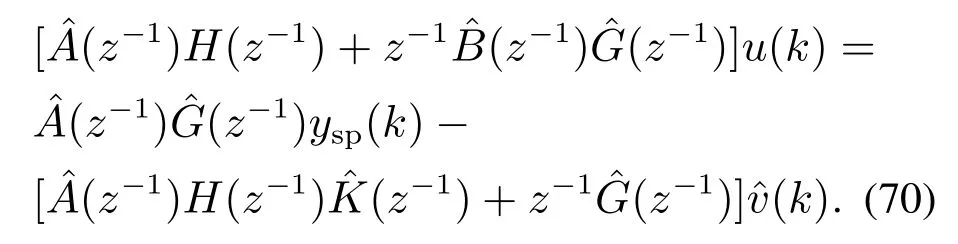
由v(k)和的有界性可知有界:
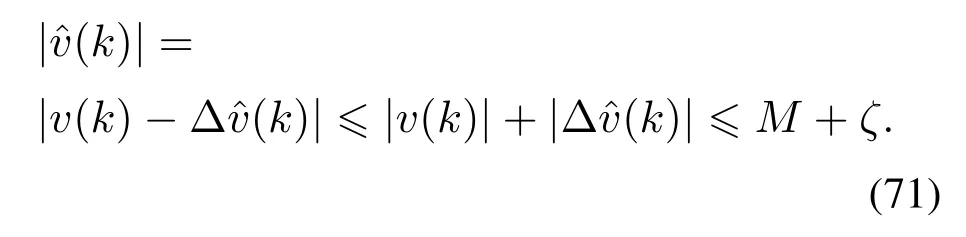
根据文[27]中的方法,由式(70),ysp(k)以及的有界性可知,存在正常数c1,c2满足
由式(37)(63)以及ysp(k)和的有界性可知,存在正常数c3,c4满足
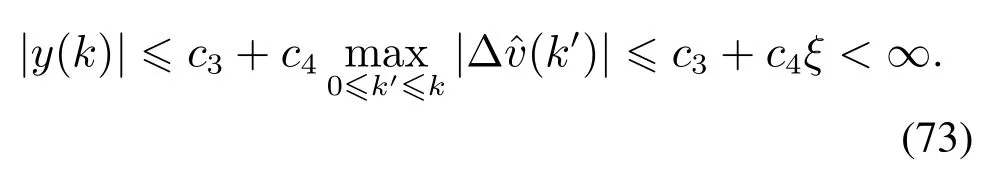
综上可知,系统的输入u(k)和输出y(k)有界.由式(63)可得,当k→∞时,有
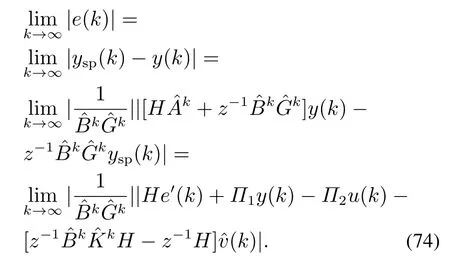
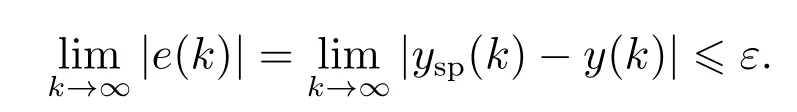
证毕.
5 实验研究
为验证本文所提出的重介质选煤过程的模型与数据混合驱动的运行反馈控制方法的有效性,本文在重介质选煤三维虚拟仿真平台上进行了仿真实验研究.
5.1 实验系统描述
重介质选煤三维虚拟仿真平台采用Unity3D,MATLAB与SQL Server分别实现了可视化显示、控制算法设计、数据管理的功能.可视化显示如图4所示,其采用Unity3D实现了重介质选煤生产过程三维虚拟仿真及实时控制效果的可视化,并使用ActiveX控件技术,将仿真实时数据存储在由SQL Server开发的数据库中.本文提出的模型与数据混合驱动的自适应运行反馈控制方法采用MATLAB开发,仿真开始时通过Unity3D脚本启动MATLAB,进而通过开放数据库连接(open database connectivity,ODBC)技术从SQL Server数据库中采集实时过程数据,执行控制算法,写入控制指令,实现三维虚拟仿真的数据交互.值得注意的是实时控制效果在可视化显示界面中以二维点绘制方式最前端显示,也可由MATLAB从SQL Server数据库中采集数据后进行统计分析,本文中的实验结果均采用后一种实现方式.

图4 虚拟仿真平台界面Fig.4 Interface of virtual simulation platform
5.2 控制器参数设计
由于本文所研究的方法假设重介质悬浮液密度可以在较短的时间内跟踪其设定值,因此本文的仿真实验是在忽略了重介质悬浮液密度调节过程的基础上展开的.仿真模型参数参考实际工业重介质选煤过程,其设置如表1所示.
将重介质选煤过程模型在灰分、硫分、水分、挥发分4种杂质含量分别为17.6%,2.5%,1.59%,12.6%处进行线性化处理,所得到的控制器设计模型参数如下所示:
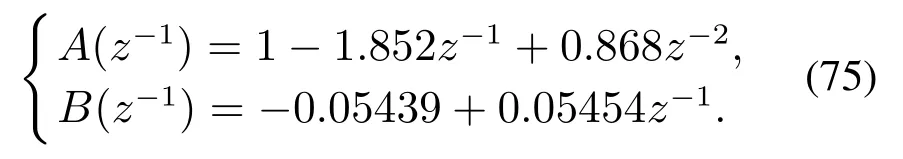
根据式(37)(39)和式(75),求得模型与数据混合驱动运行反馈控制器的参数为
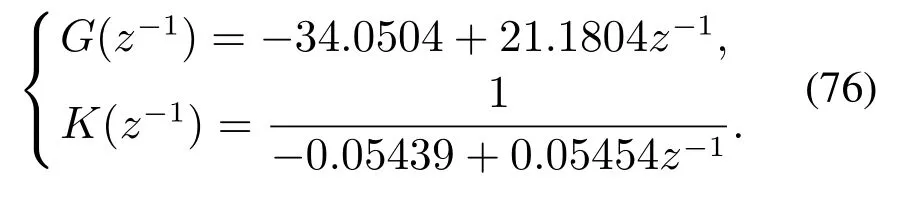
对于RVFLN,通过实验方法得知,当隐层节点L=80时预测效果即可达到要求,同时不会出现过拟合.

表1 重介质选煤过程动态模型相关参数Table 1 Model parameters of the dense medium coal preparation progress
5.3 实验研究
为了验证本文提出的控制方法的有效性,本文针对灰分期望值变化和给煤量Wore频繁波动两种情况,将所提方法与传统PI控制方法进行仿真对比实验.
1)灰分跟踪控制实验.
设置线性化工作点为初始状态,仿真时间为60 min.为验证控制器的快速跟踪性能,分别在第0 min,20 min和40 min时改变精煤灰分的期望值,以验证控制器跟踪控制的效果.仿真过程中,给煤量Wore设置为8 kg/s,由于实际工业重介质选煤过程中,给煤量Wore常常处于波动变化之中,因此仿真中对给煤量Wore增加了[–1,1]kg/s的随机扰动,其仿真结果如图5–7所示.

图5 灰分含量y变化曲线Fig.5 The curve of percentage of ash y
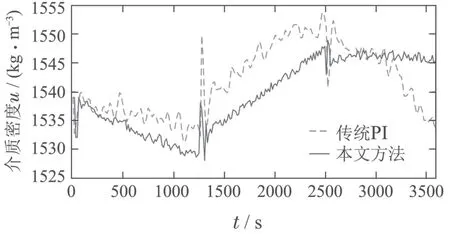
图6 重介质悬浮液密度u变化曲线Fig.6 The curve of medium density u
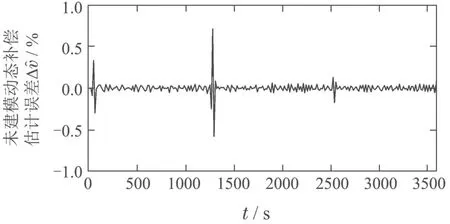
图7 未建模动态估计误差∆Fig.7 The estimation error of unmodeled dynamics ∆
图5为使用本文方法和传统PI控制方法得到的灰分跟踪曲线,其中传统PI控制的调节参数通过ZN整定法确定.由图5可以看出,在实验开始时,使用本文方法得到的跟踪曲线振荡与传统相近.此时虚拟未建模动态补偿器未起作用.之后在基于RVFLN的在线学习和基于投影辨识算法的系统参数在线更新的作用下,虚拟未建模动态补偿器对非线性部分做出补偿,跟踪效果明显较传统PI 控制好.当期望值分别在20 min和40 min改变时,灰分跟踪曲线有更小的振荡和更快的响应速度,且跟踪效果更好.
图6为使用本文方法和传统PI控制方法得到的重介质悬浮液密度控制曲线.可以看出在20 min 和40 min时刻灰分期望值改变时,本文算法求得的重介质悬浮液密度振荡较小,前后变化的幅值分别为9与6 kg/m3,且在40 min之后变化较为平缓;而传统PI算法下重介质悬浮液密度的振荡较大,且始终具有大范围波动.这是因为传统PI在初始设定kP和kI参数后没有再对PI进行调整,而系统一直受到给煤量和原煤成分的干扰,在其时变特性的影响下控制效果变差.上述结果说明使用本文方法可以通过更小的重介质悬浮液密度变化获得更稳定的控制效果.
表2为灰分跟踪控制的统计结果.当采用本文方法控制重介质选煤系统时,控制输入范围较传统PI有所下降,重介质悬浮液密度波动累积和由231.85降至201.74 kg/m3,灰分均方根误差由0.1186%降至0.0557%.说明采用本文方法能降低重介质悬浮液密度波动,保证系统的稳定控制,同时有效提高灰分的跟踪性能.
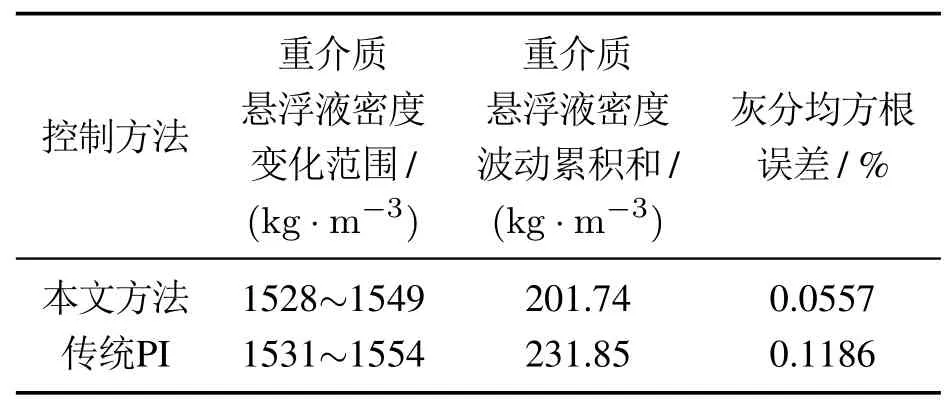
表2 灰分跟踪控制实验的性能评价Table 2 The performance evaluation of ash tracking control experiment
2)灰分稳定控制实验.
在实际的重介质选煤过程中,精煤灰分的期望值通常由工艺工程师根据原煤性质和产率等因素来决定,在系统较长运行时间内保持不变.因此,在一定的灰分期望值下,系统受扰后的稳定性对于重介质选煤过程至关重要.为此,本文设定灰分期望值为14%,并选取实际重介质选煤过程中变化的给煤量数据[15](如图8所示),开展灰分稳定控制实验.控制效果如图9–11所示.

图8 给煤量Wore实际变化曲线Fig.8 The curve of actual coal feed rate Wore
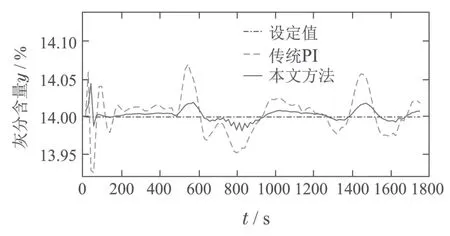
图9 灰分y实际变化曲线Fig.9 The curve of actual percentage of ash y
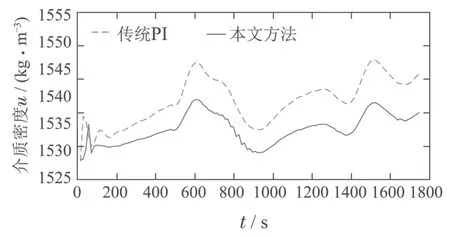
图10 重介质悬浮液密度u实际变化曲线Fig.10 The curve of actual medium density u
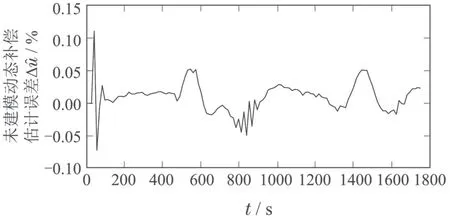
图11 未建模动态估计误差∆Fig.11 The estimation error of unmodeled dynamics ∆
在实际给煤量于3.4∼10 kg/s之间大幅度波动的情况下,由响应曲线可以看出,采用本文控制方法后的灰分在较小范围内波动,其均方根误差由0.0264%减小至0.0095%,如表3所示.此外,相对于传统PI控制,本文方法下的重介质悬浮液密度波动的累积和由55.77降至47.82 kg/m3,且整体下降了5 kg/m3.说明采用本文控制方法可以利用较少的重介质达到灰分的控制目标,实现降低生产成本、提高生产效率的目的.

表3 灰分稳定控制实验的性能评价Table 3 The performance evaluation of ash stability control experiment
由上述实验研究可以看出,采用本文提出的重介质选煤过程模型与数据混合驱动运行反馈控制方法,可以在干扰频繁大范围波动下,利用实时运行数据与先验模型知识,通过调节底层重介质悬浮液密度设定值实现对灰分期望值的稳定跟踪,确保煤质符合生产要求.
6 结论
本文为提高重介质选煤产品质量,针对其关键参数即重介质悬浮液密度的在线调节问题,将一步最优控制律与PI控制相集成,RVFLN与补偿器相结合,提出了一种由基于模型的自适应PI控制器和基于数据的虚拟未建模动态补偿器组成的自适应运行反馈控制方法及其稳定性分析理论.在灰分期望值变化和给煤量大范围波动两种情况下,在重介质选煤过程三维虚拟仿真平台上开展了仿真实验研究,由结果可以看出,使用本文方法不仅可以快速跟踪灰分期望值的变化,而且在处理量大范围变化时,灰分的平稳性有明显的改善,有利于选煤产品质量的提高.本文方法是针对基于二产品重介质旋流器的选煤过程的控制方法研究,具有一定的普适性,可通过改进本文方法,扩展应用于基于三产品重介质旋流器的选煤过程或其他洗选煤生产过程,具有一定的学术以及实际应用参考价值.
猜你喜欢
选煤技术(2022年2期)2022-06-06
选煤技术(2022年2期)2022-06-06
自动化仪表(2022年2期)2022-02-25
湖北农机化(2021年7期)2021-12-07
煤化工(2021年4期)2021-09-13
四川蚕业(2021年4期)2021-03-08
中南大学学报(自然科学版)(2021年1期)2021-02-22
人工晶体学报(2020年10期)2020-11-18
矿业科学学报(2020年6期)2020-11-09
科学技术创新(2020年12期)2020-06-22
