
结合行人检测和重识别的人员搜索框架在搜寻走失儿童中的应用分析
2020-04-21 07:50毕君郁
无线互联科技 2020年5期
关键词:深度学习
毕君郁


摘 要:我国每年失踪儿童约有20万人,如何利用人工智能技术寻找走失儿童是社会讨论的热点问题。首先,文章将行人检测和行人重识别相结合,建立了端到端的行人搜索框架,并使用OIM监督学习。然后,在Person Search数据集上进行训练后,分别用儿童和成年人的图片作为输入进行测试。最后,根据评价指标证明文章的搜索框架有70%以上的成功率,且儿童比成年人更加难以搜寻。
关键词:行人重识别;行人检测;寻找走失儿童;深度学习
1 行人重识别技术
如何利用人工智能技术寻找走失儿童一直是社会关注的热点问题,行人重识别是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。虽然现今已经提出了大量的行人重识别方法,但是还是很难被应用到现实世界中,因为行人重识别的研究使用的数据集大多数是手工剪切过的图片,如图1所示。
可见,行人重识别是在假设行人检测已经做得完美的基础上做的重识别研究。而想要实现寻找走失儿童,必须将行人检测和行人重识别相结合,所以本文使用一个端到端的行人搜索框架,其在一个卷积神经网络(Convolutional Neural Networks,CNN)中处理这两个任务,省去了模块间的操作。
本研究CNN包括两个部分:行人候选网络和身份识别网络。给定一个输入图像,通过行人候选网络生成候选行人的包围框,然后将候选行人放入身份识别网络来提取特征,与目标行人进行比较。行人候选网络和身份识别网络在训练时可以互相适应,例如:行人候选框会优先提高召回率而不是准确率,因为召回率变高则假正例率也会变高,而这些假正例(非行人却被误认为是行人的候选框)会在身份识别网络中被剔除。
传统的重识别特征学习主要使用Pair wise或者Triplet损失函数,然而,这两种损失函数都不是非常有效,因为每次比较的样本数量较少。而另一个方法是用Softmax损失函数来分类标识,此函数可以同时比较所有的样本。但是当类别增加时,训练会变得非常缓慢,甚至无法收敛。所以本研究使用在线实例匹配(Online Instance Matching Loss,OIM)损失函数[1]来训练该网络。OIM损失函数适用于类别较多、每类样本又较少的分类问题。
2 相关工作
2.1 行人重识别
传统的行人重识别采取的方法是:手工设计特征值、手工将摄像机视角转化成特征值、手工设计距离度量函数(损失函数)。后来提出使用基于深度学习的方法来处理上述方面,Li等[1]设计了CNN模型,其输入的是裁剪过的行人图片,使用二进制验证损失函数来训练网络参数。Cai等[2]使用Triplet来训练CNN以使同一行人的图片的特征值尽可能相似,不同行人图片之间的特征值尽可能相异(同小异大原则)。
近期还有许多工作关注于非正常图片的行人重识别,如:分辨率低、局部遮挡的图片。
2.2 行人检测
传统方法中,DPM,ACF和Checkerboards是最常用的行人检测器,依靠手工制作和线性分类器来检测行人。近年来,基于CNN的行人检测器也得到了发展[3],众多学者研究了包括CNN模型结构、训练数据和不同训练策略在内的各种因素。
2.3 寻找走失儿童
现有许多不同方向针对寻找走失儿童的研究工作开展,例如:跨年龄人脸识别、人脸重建、人脸老化等,但是针对儿童的数据集较少,并且儿童成长面部变化较大,所以这方面研究还面临着巨大的挑战。
3 本文算法结构
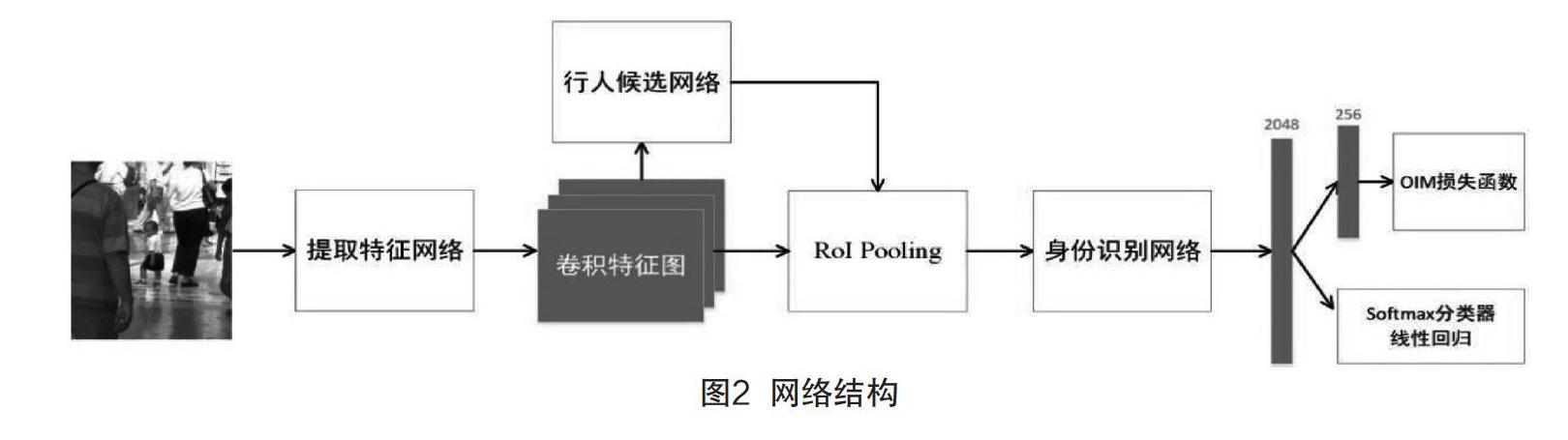
本文的CNN结合了行人检测和行人重识别网络,结构如图2所示,输入一张完整的图像后,经过特征提取网络将像素矩阵转换成卷积特征图后,行人候选网络将此作为输入来预测行人的边界框。然后,将其输入到具有RoI-Pooling的身份识别网络中,为每个边界框包围的行人提取256维的特征向量。在寻人阶段,根据目标行人和候选行人的特征向量之间的距离进行排名。在训练阶段,研究使用OIM损失函数来监督网络。
3.1 模型结构
特征提取网络:采用ResNet-50作为CNN模型的基础。首先是一个7×7的卷积层,其次是4个block,分别包含3,4,6,3个残差单元。本研究把以上作为主干部分。给定输入图像,能够产生的特征图有1 024个channels,分辨率是原图的1/16。
行人候选网络:首先通过512×3×3的卷积层提取出行人特征,按照每个特征圖的位置关联9个anchors。然后使用Softmax分类器来判断是否为行人,同时通过线性回归来调整他们的位置。最后,选出128个边界框。
身份识别网络:用于提取每个候选区的特征,并和目标特征对比。首先利用ROI-Pooling从每个候选区的特征图中池化得到一个1 024×14×14的区域。然后,将这些区域通过ResNet-50中的con4_4到conv5_3。最后通过全局的平均池化层汇总成2 048维特征向量。
一方面,因为行人检测不可避免地会有错误或偏差,所以使用Softmax分类器去除无行人的边界框,使用线性回归矫正偏差的边界框。另一方面,在推理阶段,将这些特征放到L2正则化的256维子空间中,并且计算其与目标行人的余弦相似度。在训练阶段,用OIM和其他损失函数进行监督,用多任务学习方式联合训练。
3.2 损失函数OIM
因为目标是区分不同的人,所以应该尽量减少同一行人的个体之间的差异,同时增大不同行人之间的差异。思想有点类似Triplet损失函数,但是为了解决Triplet损失函数训练样本少导致迭代次数过多的问题,OIM建立了一张查询表(假设训练集中有L个身份)和一个循环队列,其中D为特征向量的维数,Q为队列大小。查询表用来存储有注释身份的行人特征,循环队列用来存储无注释身份的行人特征。
候選内容(经过行人候选网络得到的候选框中的内容)有3种类型:有注释身份的行人,无注释身份的行人和非行人。当候选内容为有注释身份的行人时,将其放入查询表并分配一个ID(从1到L);当候选内容为无注释身份的行人时,将其放入循环队列。OIM不需要考虑候选内容是背景的情况,因为其在分类中会被自动筛除。
对于查找表,正向传播过程时,计算训练样本和查找表的余弦距离。在反向传播过程中,如果目标的ID为t,将查找表中ID为t的向量vt更新为γvt+(1-γ)x,其中γ∈[0,1],x为训练样本的特征向量,。
对于循环队列,同样计算训练样本和循环队列的余弦距离,每次迭代后,将新的特征向量存入队列,同时弹出过期的特征向量以保持队列大小不变。
基于上述两个数据结构,OIM定义Softmax函数将x识别为查找表中ID为i的可能性为:
(1)
其中,τ控制概率密度的平缓程度,实验设置为0.1。同样,Softmax函数将x识别为循环队列中第i的可能性为:
(2)
OIM的目标是最大化期望对数似然函数:
(3)
对x的梯度可以表示为:
(4)
所以,从公式(1—2)可以看出,OIM损失函数有效地将训练样本和有注释身份的行人、无注释身份的行人进行了对比,即实现了缩小相同ID人的特征距离,同时增大不同ID的人的特征距离的目的。
4 实验结果和分析
本文选择在Person Search数据集上进行训练,此数据集是一个大规模且场景多样化的人员搜索数据集,其中包含18 184张图像,8 432个身份和99 809个带注释的边界框。随后,将测试集中的查询对象分成全部为儿童和全部为成年人,分别对模型进行测试。最后,根据实验结果(返回的搜索图像和各评价指标)进行比较和分析。
4.1 测试结果
从实验结果来看,搜索准确率较高,候选框非常贴合行人,测试结果中有很多令人满意的结果,如图3所示。
但是,对于一些被遮挡,或者行人姿势不太好的情况,也会影响测试的结果,如图4所示。
可见,在衣着颜色比较特别、查询图像是正面且没有遮挡的情况下,人员搜索成功概率将大大提高。
4.2 模型评价指标和比较分析
本文选择大部分行人重识别研究选择的评价指标:平均精度(Mean Average Precision,mAP)和累计匹配曲线(Cumulative Match Characteristic,CMC)top-1,查询对象为儿童和成年人时,算法的mAP和CMC top-1如表1所示。
可见,无论mAP还是CMC top-1,结果都在70%以上,证明算法效果较好,已经可以在实际问题中提供一些帮助。但是对比来看,在各种评价指标中,搜索成年人比搜索儿童的效果都要好,原因是儿童身高不高,在图像中所占像素较少,在检测时可能会被忽略,且儿童的衣着较为统一,不同儿童之间差别较小,特征不明显。所以,通过行人重识别解决儿童走失问题还是一个具有挑战性的研究。
5 结语
为了寻找走失儿童,本文将行人检测和行人重识别相结合,建立了端到端的行人搜索框架,并使用OIM损失函数进行监督。在实验中,测试了行人搜索框架,发现mAP和CMC top-1都在70%以上,证明本文算法能够应用在寻找走失儿童中。研究还发现,行人搜索框架寻找成年人的成功率比寻找儿童的成功率高10%左右。如何调整网络结构,使行人搜索框架能更加针对儿童,是下一步需要研究的方向。
[参考文献]
[1]LI W,ZHAO R,XIAO T,et al.Deepreid:deep?lter pairing neural network for person re-identi?cation[C].Columbia:IEEE Conference on Computer Vision and Pattern Recognition,2014.
[2]CAI Z,SABERIAN M,VASCONCELOS N.Learning complexity-aware cascades for deep pedestrian detection[C].Beijing:IEEE International Conference on Computer Vision,2015.
[3]FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactions on Software Engineering,2010(9):1627-1645.
Analysis of the application of human search framework combined with
pedestrian detection and recognition in the search of lost children
Bi Junyu
(School of Computer Science and Technology, Tiangong University, Tianjin 300387, China)
Abstract:There are about 200 000 missing children in our country every year, how to use artificial intelligence technology to find lost children is a hot topic in social discussion. Firstly, this paper combines pedestrian detection and pedestrian recognition to establish an end-to-end pedestrian search framework and uses OIM to supervise learning. Secondly,after training on the Person Search dataset, the childrens and adults pictures were tested as input, respectively. Finally, according to the evaluation index, the search framework of this paper has more than 70% success rate, and children are more difficult to search than adults.
Key words:pedestrian recognition; pedestrian detection; search for lost children; deep learning
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
