
基于特征贡献度的安卓恶意应用检测
2020-04-23 05:42刘启川覃仁超卜得庆
计算机工程与设计 2020年4期
刘启川,覃仁超,刘 玲,卜得庆,袁 平
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010)
0 引 言
目前,Android恶意应用检测方法主要集中在提取不同的特征和机器学习算法改进上,通过提取出应用中的API[1]、权限[2,3]、调用关系[4]和IP地址[5]等特征,并将这些特征使用朴素贝叶斯(Naive Bayesian,NB)、决策树(decision tree)、支持向量机(support vector machine,SVM)和K最近邻(k-nearest neighbors,KNN)等不同的机器学习算法构造分类器进行分类[5,6]。但多特征包涵大量冗余信息,文献[7]指出更多的特征可能导致更差的分类性能。为了得到更好的检测效果,消除冗余特征,特征选择算法已被大量用于Android恶意软件检测方法中[8]。
在Android恶意应用检测中,使用不同的特征选择算法已经成为不少学者提高检测效率的研究方法,当前主要方法为卡方检验(Chi-squared test,CHI)、信息增益法(information gain,IG)和粒子群优化算法等[9,10],其特征选择算法大多借鉴于其它领域,忽略了Android应用数据集特征的分布特点,并未通过量化特征对分类效果的贡献程度来选择特征。因此,本文提出了一种基于特征贡献度(feature contribution,FC)的特征选择算法,该算法通过计算应用的权限、敏感方法、组件信息和硬件信息等基本特征的贡献度,能选择出对分类最有帮助的特征进行恶意应用检测。
1 特征贡献度
1.1 卡方检验和信息增益
卡方检验是统计学中一种用于独立性检验的假设检验方法,即验证两个变量是否相互度量,其数学公式如式(1)所示
(1)
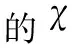
而信息增益算法是信息论中的重要概念,其衡量标准是通过量化特征为分类系统带来多少信息,越重要的特征带来的信息越多,信息增益也就越大。其数学公式如式(2)所示
IG(fi)=H(C)-H(C|fi)
(2)
其中,H(C) 表示整个系统的信息熵,H(C|fi) 是在给定特征fi下的条件熵,此时IG(fi) 即为信息增益。其中,信息增益算法更加偏向选择在恶意和良性应用中广泛分布的特征,因为这种特征具有更大的信息增益。
上述两种传统特征选择算法都不适用于恶意应用检测领域,因此针对恶意应用检测中的特征选择算法十分必要。
1.2 特征贡献度计算
贡献度通常用于衡量某一因素对整体的贡献程度。在Android应用特征数据集特征的分布有着如下特点:
(1)良性应用中使用过的特征数量通常大于在恶意应用中使用过的特征数量;
(2)大部分特征都是非典型特征,有很大一部分特征的存在对分类没有帮助;
(3)在良性应用中频繁使用的特征和恶意应用中频繁使用的特征有着明显的区别。
因此,本文根据上述的特点将特征贡献度定义为单个特征对分类的贡献程度。通过计算特征的贡献度对特征进行选择,选出的特征在分类时越能表征样本类间的特性和样本类内的特性,则该特征就对样本的分类贡献越大。故有定义如下:
定义1 类间贡献度:类间贡献度表示特征项在类间分布中的贡献程度,特征项在类间分布越不平衡,其贡献程度越大,记作FCout。
FCout(fi) 计算公式如式(3)所示
(3)
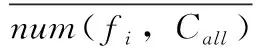
定义2 类内贡献度:类内贡献度反应了特征项在类内中的贡献程度,特征项在类内出现频率越高,其贡献程度越大,记作FCin。
FCin(fi) 计算公式如式(4)所示
(4)
其中,num(sam(fi)all,Cj) 表示j类中包含fi特征的样本数量,num(samall,Cj) 表示j类中所有样本数,num(fall,Call-Ci) 表示除了i类中特征的数量,num(fall,Call) 表示所有特征的数量。公式的主要目的是为了将类别中的特征频率归一化后求得类内贡献度。
定义3 特征贡献度:fi特征的特征贡献度指的是对fi特征对分类的贡献程度,用FC(fi) 表示,综合式(3)和式(4),FC(fi) 如式(5)所示
FC(fi)=FCout(fi)×FCin(fi)
(5)
由式(3)、式(4)和式(5)可得:
(1)当特征项只在一个类别中出现时,其分类能力最强,此时FCout最大为1;当特征项在各个类别中均匀分布时,其分类能力最弱,此时FCout最小为0。显然,FCout与分类能力成正比。
(2)当特征项在类中出现频率越高,其越能代表这个类,FCin也越大;当特征项在类别中出现的频率越低,其越不具有代表性,FCin也越小。显然,FCin与代表性成正比。
本文提出的贡献度算法不仅考虑到了特征在类中的出现频率,还考虑到了特征在类间的分布情况。通过特征贡献度式(5)的运算后的FC(fi) 的值越大,就越能说明特征fi的贡献度越大,其作用也越重要。
2 系统的架构与实现
2.1 模型设计
本文的恶意应用检测系统主要包括3个部分:特征提取模块、特征选择模块和分类模块,其模型如图1所示。其中,特征提取模块主要作用是将应用进行逆向,并提取权限、敏感方法、组件信息和硬件调用信息特征,将其向量化,生成特征向量集合;特征选择模块则是对特征向量集合中的特征使用基于特征贡献度的算法进行贡献度分配,选择出典型特征数据集;分类模块则是将前面构建好的数据集运用机器学习算法,训练分类器进行预测和分析。
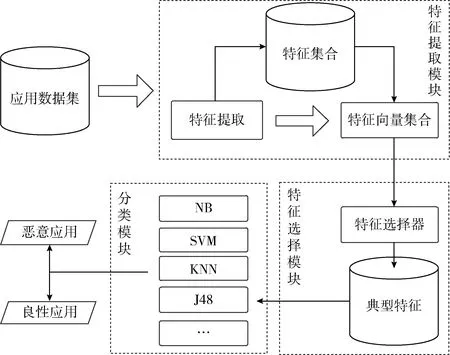
图1 系统总体设计
2.2 特征提取模块
特征提取模块中需要解决的首要问题是确定Android应用中那些特征与恶意应用检测紧密相关。大致思想是通过逆向Android应用软件,提取与其功能和行为相对应的所有特征,提取的特征可以分为4个不同的类别:
(1)权限:Android应用程序必须根据其所提供的功能明确声明它们将使用哪些权限。例如,某应用程序声明了SEND_SMS和READ_CONTACTS权限,该程序就具有通过短信泄露手机联系人的威胁;若声明了SEND_SMS和READ_SMS,该程序就具有通过短信泄露用户短信的威胁[2]。因此,可以使用权限功能来对良性应用程序和恶意应用程序进行分类。
(2)敏感方法:仅依赖Android权限管理系统不能完整的体现应用的功能和行为,部分恶意软件可以绕过权限控制,但是调用API却无法隐藏,比如获取设备ID需要调用getDeviceId()方法,发送短信需要调用sendTextMessage()方法。显然,增加与Android系统相关的敏感方法,可以帮助恶意应用检测。
(3)组件信息:Android应用程序通常由活动(Activity)、内容提供器(Content Provider)服务(Service)和广播接收器(Broadcast Receiver)构成。恶意代码行为的实现需要通过组件的形式表达,在某种程度上说,Android应用程序组件信息在可以表示其运行时的行为,并且同一家族的恶意代码,其组件有一定的相似性。因此可以选择组件信息对应用程序分类。
(4)硬件调用信息:在Android系统中,要使用硬件除了声明相应的权限以外还要使用与硬件相关的类。例如在调用与wifi相关的方法时,就必然使用到Android.hardware.wifi类。因此,硬件调用信息也可以作为分类的信息之一。
特征提取模块中另一个需要解决的问题是如何提取和表示这4种具有代表性的特征,本文主要通过以下步骤:
(1)对样本库中APK文件进行逆向得到大量xml或smali文件,如AndroidManifest.xml和Class.dex文件。
(2)遍历AndroidManifest.xml文件和包含源代码的.Smali文件,可以获得部分应用程序的基本信息,如权限信息、四大组件信息和与Android相关的API调用信息等。
(3)对样本应用数据进行上述处理,生成了一个包含24 605特征的特征集合,其所对应的数学表达为F=(f1,f2,…,fn,label), 其中n为特征数量,label为特征的标签。
(4)将每个应用逆向后的特征信息与特征库比对,有该特征记为1,没有记为0。数学表示形如:si=(1,0,…,0,y), 当应用为良性应用时,y为0,否则y为1。
最终,应用数据集变为一个包含0、1的信息矩阵S=(s1,s2,…,sn)T, 其中si表示i应用的特征向量,实现了数据集的矩阵化。
2.3 特征选择模块
样本集通过特征提取器提取后,提取出了24 605个特征。但是其中大部分特征对于分类都不具有帮助,只有少部分特征可以用于对应用进行分类。在特征选择模块中,首先,信息矩阵通过方差检测,消除了全为1或者全为0的特征。随后,通过设置特征贡献度的最小值选择方式选择典型特征,形成了一个只有典型特征的特征矩阵S′=(s′1,s′2,…,s′n)T。
如表1所示,与短信相关的特征能够对恶意应用分类有着更大的贡献。某些特征(如:INTERNET权限)在恶意应用和良性应用中都被大量使用,这种特征不具有区分度;又比如,某些特征(如:android.hardware.screen.portrait硬件信息)只有很少的应用使用,这种特征不具有代表性。

表1 贡献度top5特征
2.4 分类模块
机器学习算法已经广泛应用于许多领域,如文本分类、图像识别和恶意应用检测等。首先,分类模块将通过特征选择模块后生成的矩阵S′作为Android恶意应用检测数据集输入。随后,选取了几种常见的机器学习算法如:NB、SVM,KNN和J48对数据集进行训练和预测。最后,输出相应的评估结果等详细信息,以便选取出最适合的分类器。
3 实验结果与分析
为了评估基于贡献度的特征选择算法的效果,本文先进行了多次实验以选择出最好的机器学习分类算法,再与其它两种特征选择算法进行比较。实验所用原始数据集包含2306个应用程序,其中50%是恶意应用,另外50%是良性应用程序。恶意应用是从https://virusshare.com/[11]中收集的,良性应用是从Google Play,小米应用商店等应用市场上下载得到的,并使用Virus Total网站进行扫描,以确保它们都不是恶意应用。本文使用的机器学习分类算法是通过机器学习和数据挖掘工具Weka实现和验证的,验证方式采用了十折交叉验证。
3.1 实验分析
为了找到合适的分类算法,本文比较了NB、SVM、KNN和J48这几种常见的分类算法的性能。通过准确率(Accuracy)和召回率(Recall)对分类效果进行评价,数学公式如式(6)、式(7)所示
(6)
(7)
其中,TP、FP、FN和TN分别指的是分类正确的正例(TP)、分类错误的正例(FP)、分类错误的负例(FN)和分类正确的负例(TN)的数量。
本文的特征贡献度阈值分别设定为0.2,0.18,0.16,0.14和0.1,分别选择出来19,34,119,316和1342个特征,之后使用上述4种算法在典型特征上构建分类器。
从表2可以看出,首先,随着典型特征数量的增加,除了NB以外的3种算法的准确度和召回率都有所提高。其次,在这些算法中,SVM和KNN可以在特征变化时始终达到较高的精度,最好达到了96.1%的准确率和召回率,甚至比使用了全部特征的准确率和召回率都要高。再次,除了NB算法外的其它算法的召回与准确率几乎相同,这意味着特征选择后的特征可以等同地分类恶意应用和良性应用。最后,可以看到在NB中,随着特征的增多,其准确率和召回率反而下降。这是因为贝叶斯算法要求特征具有严格的独立性。举例来说,当SEND_SMS这个权限特征的特征贡献度高时候,与其相关的敏感API的特征贡献度也很可能比较高,此时选出来的特征相关性较强,反而影响NB的分类效果。
3.2 实验对比
为了评估特征选择的性能,本文比较了卡方检验、信息增益和本文提出的特征选择算法。由表2可知SVM和KNN算法有着较好的分类效果,本文选择了前19,34,119,316和1342个特征并且分别构建了基于KNN和SVM的检测模型,结果如图2所示,其中图2(a)和图2(b)表示不同特征选择算法在SVM分类器下的准确率和召回率。图2(c)和图2(d)表示不同特征选择算法在KNN分类器下的准确率和召回率。
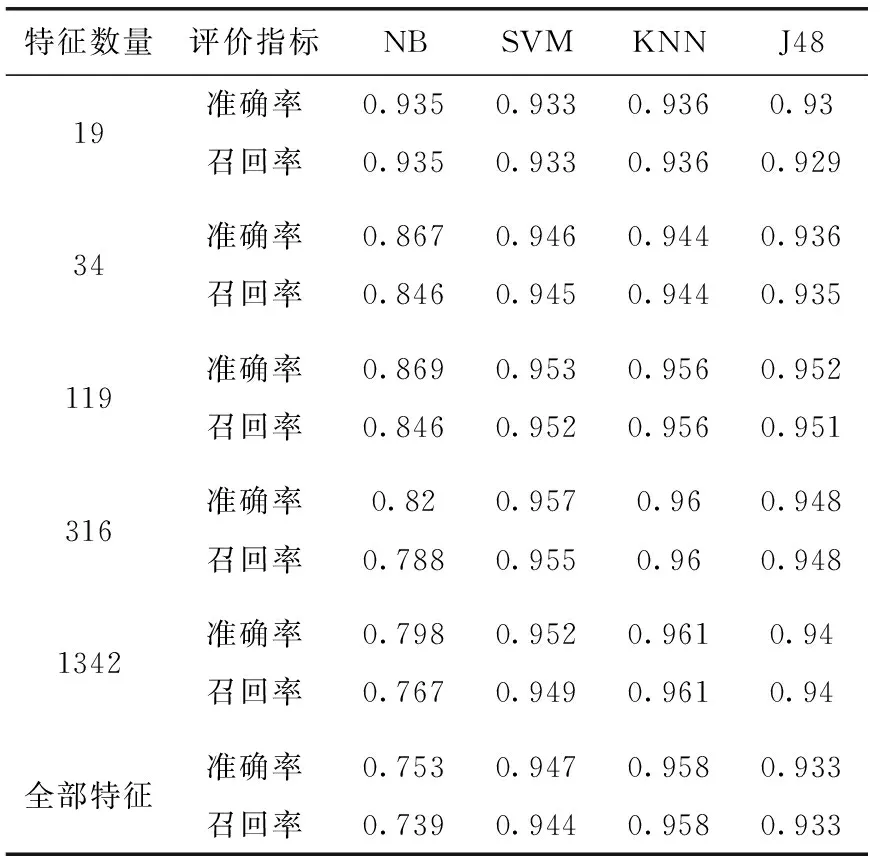
表2 不同数量的特征对不同分类器的比较
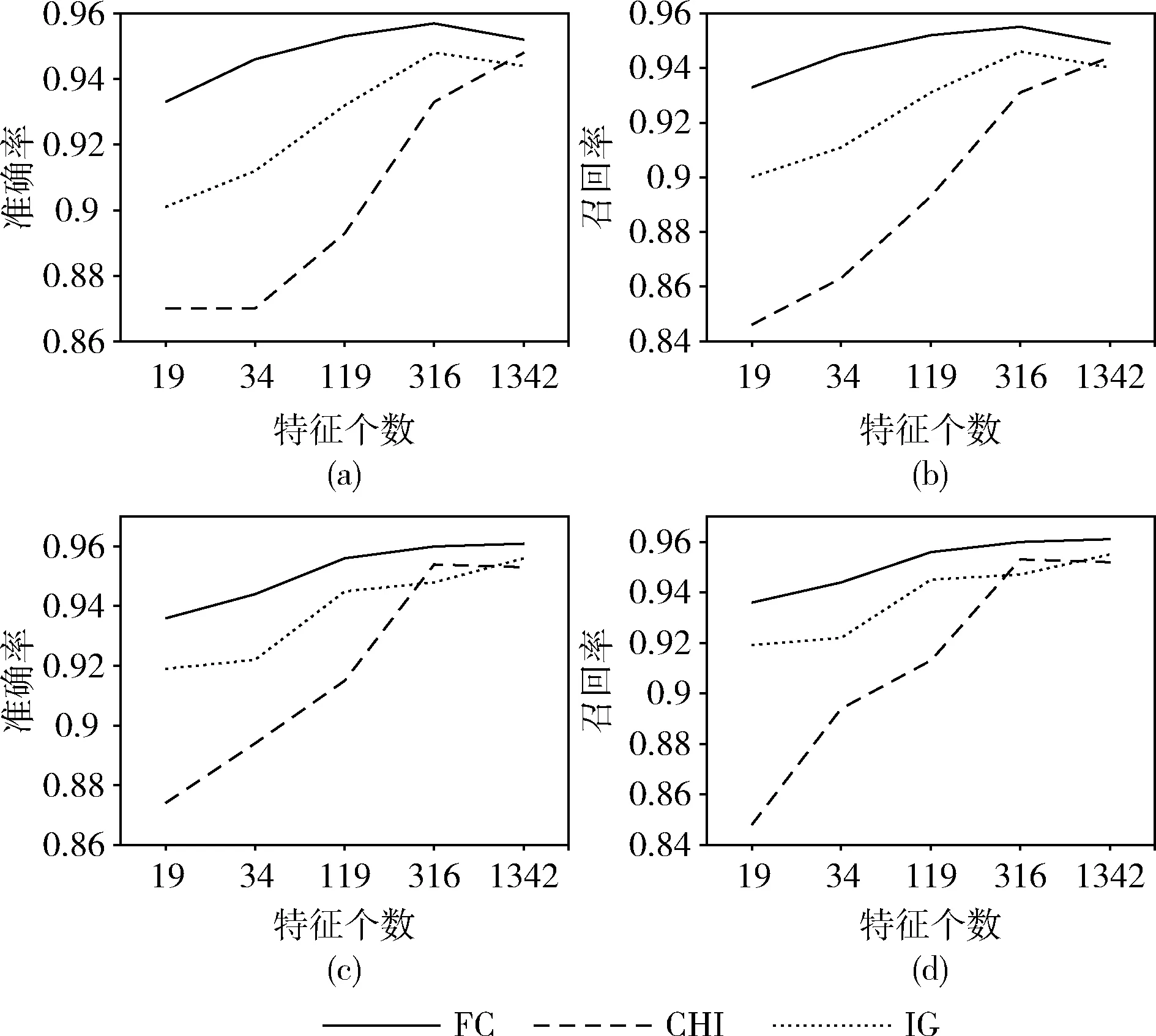
图2 不同特征选择算法在不同分类器的准确率和召回率
由图2可知,无论哪种特征选择算法,随着被选择的特征数量越多,SVM和KNN分类器的准确率和召回率总体都呈上升趋势。而本文提出的特征选择算法在准确率和召回率方面明显优于其它两种算法,尤其是在选择了较少特征的时候。可以得到:基于贡献度的特征选择算法可以在选择更少的特征的情况下,达到比传统特征选择算法更优异的效果。
4 结束语
本文根据应用数据集中特征的分布特性提出了基于特征贡献度的特征选择算法。实验结果表明:
(1)本文的特征选择算法适合恶意应用检测数据集,所选择的特征明显好于传统的特征选择算法选择的特征,对于恶意应用检测是有效和可靠的。
(2)算法选择的特征在分类器中的准确率和召回率最高可达到96.1%,且准确和召回率十分接近,具有优异的检测效果。
(3)相比与CHI和IG算法,该算法可以在较少特征的情况下达到理想的检测效果,能大大提高检测的效率。
下一步的工作中,将从以下几个方面拓展本文的研究:首先,对特征选择算法进行改进,例如使其自适应的选择阈值,而不用人工的设置阈值。其次可以对特征选择算法拓展到对恶意应用家族进行分类,针对不同类型的恶意应用(如:流氓行为、资费消耗、信息窃取等)进行选择典型特征,提高算法的应用范围。
猜你喜欢
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27
中国生物医学工程学报(2019年4期)2019-07-16
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
上海农业学报(2017年3期)2017-04-10
电子制作(2017年23期)2017-02-02
军事运筹与系统工程(2016年3期)2016-09-26
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
航天返回与遥感(2014年5期)2014-07-31
