
基于博弈机制的多目标粒子群优化算法
2020-04-23 05:42喻金平巫光福
计算机工程与设计 2020年4期
喻金平,王 伟,巫光福,梁 文
(1.江西理工大学 工程研究院,江西 赣州 341000;2.江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
优化问题大部分都是多目标优化问题,(multi-objective optimization problems,MOPs),多个目标函数之间存在相互冲突,需要同时进行优化。PSO[1](particle swarm optimization)算法因其收敛速度快,参数设置少的优点,因此被广泛用于解决MOPs。
PSO算法的改进部分集中在加快算法的收敛速度和获得多样性较好的解上,因此针对收敛性方面,Hu等[2]提出了一种从进化过程中检测反馈信息,用于动态调整种群在开采和开发中平衡的算法。杨等[3]给出了一种融合策略,引入分解思想和支配并存的思想,在速度和位置更新时,引入“多点”变异,即随着迭代的增加,根据相应判据对其位置的更新做出不同的变异,最后将更新后的种群和最优解集进行非支配排序,能很好提升算法的收敛性。在改进种群的多样性方面,韩等[4]给出了高斯混沌变异和精英学习的自适应方案,使用自适应参数的机制和精英学习方法,有效提升了算法的多样性。韩等[5]给出了参考点的高维多目标粒子群算法,使用参考点作为依据,利用坐标空间中的参考点选出多样性良好的粒子,有效保持了解的多样性。种群多样性丢失、收敛快、容易陷入局部最优一直是本研究的重点,但是这一问题并没有较好的解决,因此本文提出了一种基于博弈机制的多目标粒子群算法(game mechanism based multi-objective particle swarm optimization,GMOPSO)。
本文首先采用了多尺度混沌变异的策略,在算法追求快速收敛的同时,避免陷入局部最优。一种新的精英粒子的选取方式,采用了非占优解排序[6]和拥挤距离[3]共同排序,该方法可以较好提升算法的收敛性,不需要存储全局最优粒子的外部集,降低了算法时间复杂度。提出了一种粒子更新机制,博弈机制,提升了所得解的多样性。
1 相关工作
1.1 粒子群算法
PSO在1995年被就提出了。PSO算法源自对一群在指定区域内寻找食物的鸟群运动的研究,将鸟抽象为不计重量和体积的粒子,食物被定义为所得解。这些粒子被随机分散在次区域中,并且具有一定的初始速度,每轮循环迭代中,粒子都是根据自身历史最优位置和当前种群中全局最优的粒子更新自己的速度和位置。其中速度和位置更新公式请参考文献[1]。
1.2 博 弈
博弈理论是PSO的一个变体,由Cheng等[7]提出,用来解决SOPs(single-objective optimization problems)。在博弈机制中,通过博弈对粒子进行更新,而不是使用全局最优粒子和个体最优粒子,从而大大提高了种群的多样性,避免了算法过早收敛。具体来讲,在博弈机制中,粒子从当前的种群中随机两两配对进行博弈,博弈失败的粒子则通过向胜利者学习来更新自身的速度和位置,胜利者则保持原有的状态,直接过渡到下一轮迭代,以此类推,直至所有粒子更新完毕。种群更新公式如下
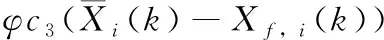
(1)
Xf,i(k+1)=Xf,i(k+1)+vf,i(k+1)
(2)
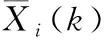
2 基于博弈机制的多目标粒子群算法
2.1 混沌映射
多目标粒子群算法以快速收敛著称,但是收敛过快容易陷入局部最优,使得所得解不真实,所以需要采用混沌变异机制,使其跳出局部最优,因此,本文采用了Tent[8]映射公式如下

(3)
其中,Xi是混沌数,i为迭代次数。
2.2 多尺度混沌变异策略
如上所述,过快的收敛速度导致算法容易陷入局部最优,所以在算法初期使用上一部分提出的混沌映射的方法,使算法跳出该局部最优,其中变异的距离由粒子的分布情况决定,不同的稀疏程度采用不同的变异方案。
算法1展示了该多尺度混沌变异策略,该策略首先将初始化后的群体使用拥挤距离,对每个粒子进行降序排列。排在前20%的粒子,分布不是很密集,不容易陷入局部最优,可以用小半径μ*r进行变异,其中μ是变异尺度;排在后20%的粒子由于容易陷入局部最优,因此使用较大的变异半径r;中间60%的粒子,因为陷入局部最优的概率处于两者之间,所以随机从以上两种方法中选择一种进行变异。具体变异过程看算法1。其中(M,N)表示用混沌模型产生的混沌序列,Crowding(pop)表示计算种群中粒子的拥挤距离并将其用降序排列。
算法1: ChaosMutation
输入: 种群pop(M,N)变异尺度μ
输出: 新种群Npop
(1)初始赋值r=(Xmax-Xmin)/2,μ=0.3
(2)Tent(M,N)
(3)Crowding(pop)
(4)for I=1∶M
(5) If (I<0.2*M)
(6) r=μ×r
(7) else if (I>0.8*M)
(8) r=r
(9) else if (rand>0.5)
(10) r=μ×r
(11) else
(12) r=r
(13) end if
(14) end if
(15) t=Tent (I,:)
(16) Npop(I,:)=pop(I,:)+r*(2*t-1)
(17)End for
2.3 GMOPSO框架
本文提出的GMOPSO算法的跟博弈群优化器理论还是存在差异,原始的博弈理论是将初始化种群划分成两部分,一半是博弈成功者,另一半是博弈失败者,博弈失败者向博弈成功者学习更新,主框架如算法2所示。
算法2: main
输入: POP(种群大小); Iter(当前迭代次数)
MaxIter(最大迭代次数); E(精英集)
输出: FP(粒子的最终位置)。
(1)初始化所有粒子的位置(X)和速度(V)
(2)while Iter<=MaxIter
(3) 通过拥挤距离选出10%的粒子加入E
(4) 执行博弈机制更新粒子的位置和速度
(5) 环境选择,选出新的种群
(6)end while
(7)Return FP
本算法是基于精英集确定的前提下的博弈,即待更新粒子从精英集中随机选出两个精英粒子,进行博弈,博弈成功者将成为引导者,引导待更新粒子和博弈失败者进行更新,博弈成功者将维持原有的速度和方向前进。其主要框架如算法2,由两部分组成:新博弈机制的速度更新部分和种群环境选择部分。其中环境选择部分是出自SPEA2[9],博弈机制的速度更新将会在2.4部分详细介绍。
2.4 新博弈更新机制
新的博弈更新机制如算法3所示,采用夹角角度比较,不再是适应度值进行比较,在多目标情况下,过度强调适应度值,往往会使部分粒子远离局部最优,导致算法总体收敛效果很差,比较角度能有效改善这个问题。其核心过程就是,非精英粒子从精英集中随机选出两个精英粒子,计算两个精英粒子间与非精英粒子之间的夹角,所成夹角小的粒子将成为这个粒子的引导者。博弈机制循环开始于精英粒子的确定,精英粒子是通过非占优排序[7]和拥挤距离[1]来选出的。非占优排序是依据个体的非劣解水平对种群分层。它是一个循环的适应值分级过程,首先找出种群的第一层非占优解,记为F1,然后将第一层删去,接着找第二层,以此类推,直至所有的粒子都分好层。接下来根据每一层的粒子计算拥挤距离并降序排列。拥挤距离是在同一级别中,该粒子与相邻前后两粒子间所能形成的最大矩形的边长和。
算法3: 博弈更新机制
输入: X(粒子的位置), V(速度), E(精英集)
Iter(当前迭代次数), MaxIter(最大迭代次数)
输出: NP(粒子的新位置)
(1) 将NP设为空集
(2) forXi∈Xdo
(3) 从E中随机选两个粒子Xa,Xb
(4) 计算粒子a,b与粒子x之间夹角θ1和θ2
(5) ifθ1<θ2
(6)Xw=Xa;
(7) else
(8)Xw=Xb;
(9) end if
(10) 使用式(4),式(5)更新粒子的位置和速度
(11) while Iter < 0.4*MaxIter
(12) 执行ChaosMutation
(13) 将更新的粒子位置和速度加入到NP中
(14)end for:
(15)多项式变异
(16)Return NP
该机制十分突出的一点就是,精英集粒子只需要通过拥挤距离和非占优排序选举出来,而且对于精英集的规模的选择也十分重要,较小的精英集将会导致早熟收敛,较大的精英集能延缓收敛的速度,避免陷入局部最优,所以我们将精英集的大小设定为粒子种群数量的10%。
当精英集粒子确定完毕后,进行博弈,博弈成功者将作为全局最优粒子指引种群中其它粒子飞行,在每一对博弈当中,待更新粒子从精英集中随机选出两个精英粒子a和b,两个精英粒子就两者与非精英粒子从坐标轴远点出发所形成的夹角进行博弈,所形成角度小的博弈成功,如图1所示,精英粒子a与非精英粒子x形成的夹角θ1小,故而粒子a引导粒子x进行速度和位置更新,速度更新公式如下。从选择精英到比较角度这整个过程称之为博弈,因为精英粒子的选择是随机的,待更新粒子不清楚最终会选定哪个引导者,引导者自身的属性会决定粒子更新的效果,属性较好的引导者引导更新效果更好,反之,属性一般的引导者引导更新效果次之,粒子更新效果完全取决于引导者,所以称之为博弈
v′i=c4vi+c5(Xw-Xi)
(4)
X′i=Xi+v′i
(5)
其中,c4和c5是[0,1]之间的随机产生的向量,Xw是博弈成功者的位置,Xi是粒子的当前位置,vi是粒子的当前速度。
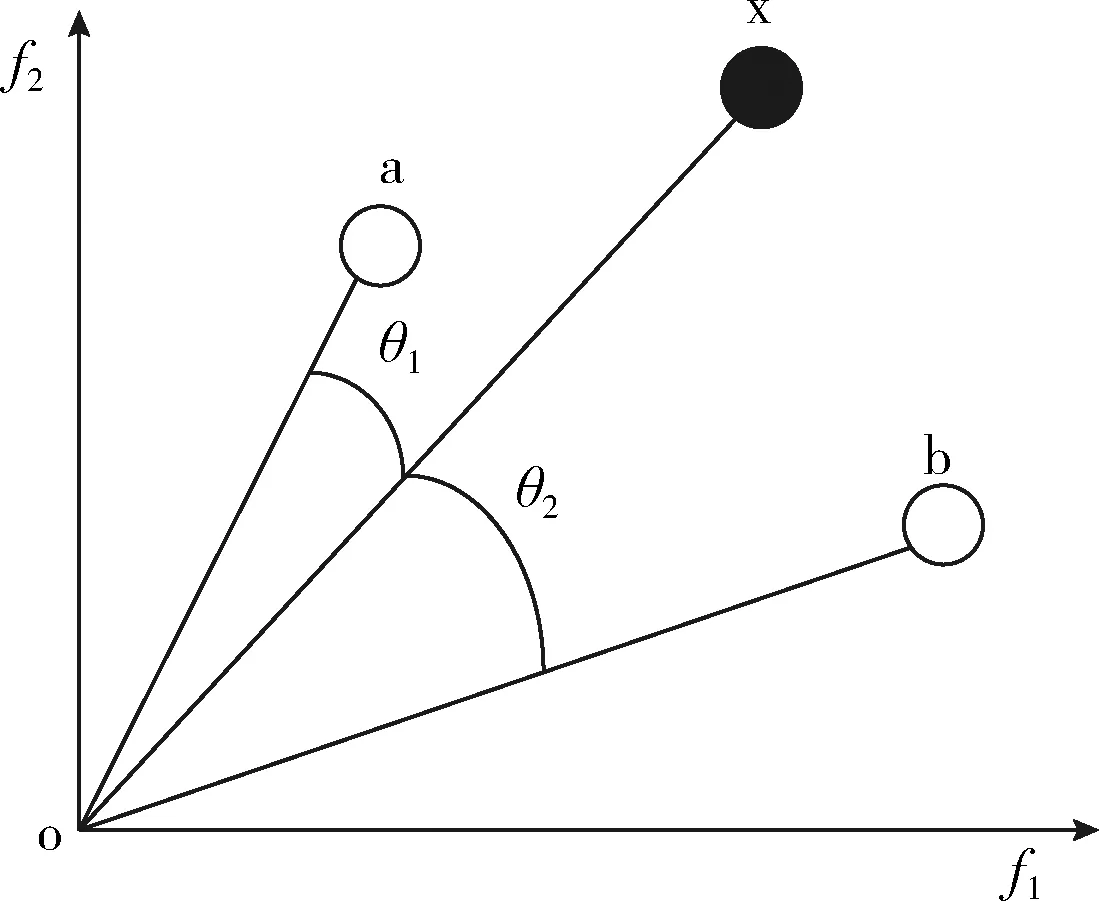
图1 两精英粒子进行博弈
2.5 时间复杂度分析
博弈机制,不需要外部储备集,能有效加快算法的收敛速度,本文以时间复杂度来分析本文算法的收敛速度,本文算法和MOPSO都用到了非占优排序,而非占优排序最慢需要O(mn2), 最快需要O(mnlogn), 非占优排序采用最快情况下的时间复杂度。
基于博弈的GMOPSO
O(M*(mnlog(n)+n+2mnlog(2n)))
未采用博弈的MOPSO
O(M*(2mnlog(2n)+n+2mnlog(2n)))
其中,M为最大迭代次数;m为目标的个数;n是种群中粒子的个数。由以上可知,采用博弈机制能有效提升算法的收敛速度。
3 实验仿真
3.1 实验设置
本文使用的测试函数是现今比较流行的测试函数系列,分别是ZDT系列、DTLZ系列和WFG系列测试函数,总共21个函数构成,进行28项测试。ZDT系列中,由于ZDT5是布尔函数,使用此测试函数需要二进制编码,所以就没有用该测试函数,ZDT系列标准测试函数进行两目标测试。DTLZ系列由DTLZ1至DTLZ7组成的一类标准测试函数,DTLZ系列标准测试函数分别进行了两目标和三目标测试,WFG系列标准测试函数进行三目标测试。对比算法分别是NSGA-II[10]、MOEAD[11]、MOPSO[2]、MPSOD[12]、MMOPSO[13]、和SMPSO[14],这些算法都是常用的经典对比算法,故本文将与这些算法对比来验证算法的有效性。
本次实验是在Windows7系统下完成的,算法性能评价指标采用的是逆代距IGD(inverted generational distance)和Pareto前沿。所有算法的种群大小设为100,有外部集的算法其存档容量均设为100,测试函数运行次数除了DTLZ3迭代1000次以外,其它的测试函数均迭代300次,所有算法独立运行50次,所得结果是50次独立运行的IGD的平均值及标准差,IGD值越小,算法得出解得性能就越好。
3.2 IGD对比分析
表1和表2展示了6种对比算法和本文算法在21个测试函数上进行的28项的测试值,其中含有IGD的平均值和标准差,以及t检验结果,t测试中“+”、“-”和“=”分别表示强于、弱于和等于本文算法在对应测试函数上的显著性区分结果,使用字体加粗的方法把所得结果在每一个测试函数上的最小IGD的值进行了标记。表1中和表2中M代表目标个数。
从表1可以看出,4个算法中,原始的MOPSO算法性能最差,本文提出的算法性能最佳。在28项标准测试函数当中,GMOPSO在15项标准测试函数中取得了较好的IGD值,尤其是在ZDT系列和WFG系列中。MOEAD在3项标准测试函数中取得了最小的IGD值,但有16项标准测试函数次于本文算法;MOPSO在1项标准测试函数中表现较好,但有26项标准测试函数劣与本文算法;NSGAII在10项标准测试函数中表现最好,但有18项标准测试函数差于本文算法。
从表2中得出,与目前流行的多目标进化算法相比,本文提出的GMOPSO算法在标准测试函数上整体表现良好,在14项标准测试函数中IGD值明显优于其它算法,说明了博弈机制的有效性。从t检验来看,相比SMPSO算法,本文算法在20项标准测试函数上强于它,6项测试函数劣于它,两个测试函数与它持平。相比改进的MMOPSO算法,本文算法在16项测试函数上强于它,9项测试函数劣于它,3项测试函数与它持平。与MPSOD算法相比较,本文算法在21项测试函数上优于它,4项函数劣于它,3项函数与它持平。
综上所述,与现有的各种多目标粒子群算法相比较,本文提出的GMOSPO能在保证快速收敛的同时保持种群的多样性,这也证实了GMOPSO所提出的博弈机制能很好的平衡收敛性和多样性,并且在求解多目标优化问题上具有良好的性能和前景。
3.3 Pareto前沿比较
表3给出了性能对比中较好的4个算法在部分测试函数的Pareto前沿比较图。从表中可以看出:所给出的标准测试函数中,本文算法仅在ZDT4标准测试函数上性能较差,不能有效收敛至Pareto前沿,且最终结果所得的粒子群分布不均,但是在其它展示出来的标准测试函数上都能表现出良好的性能;在ZDT2标准测试函数上,本文算法能很好的收敛至Pareto前沿,性能最差的是MOPSO算法,没有收敛到Pareto前沿,另外两个算法虽然能收敛到 Pareto 前沿,但是分布不是很均匀;在ZDT3标准测试函数上,本文算法相比其它算法性能最好,但是分布存在不均匀,性能最差的是MOPOS算法,图片上分布比较均匀,但是与Pareto前沿相差很多,不能收敛到前沿,另外两种算法表现不是很理想,算法的收敛性和种群的多样性表现都较差;在ZDT4标准测试函数上,NSGAII算法性能最好,能兼顾收敛性和多样性,另外3种算法都性能较差;就DTLZ4标准测试函数上的对比来看,本文算法性能最好,最终所得解能有效收敛至真实前沿,且分布很均匀,MOEAD算法性能最差,另外两种算法能收敛到Pareto前沿,但是分布不是很均匀;就DTLZ5标准测试函数上的对比来看,GMOPSO与NSGAII都表现较好,图片中展示了这两个算法具有较好的收敛性和多样性。MOEAD性能最差,虽然能收敛到Pareto,但是分布不均;就DTLZ7标准测试函数上的对比来看,本文算法性能最好,算法收敛性较好和所得解多样性较完善,原始的MOPSO算法性能最差。
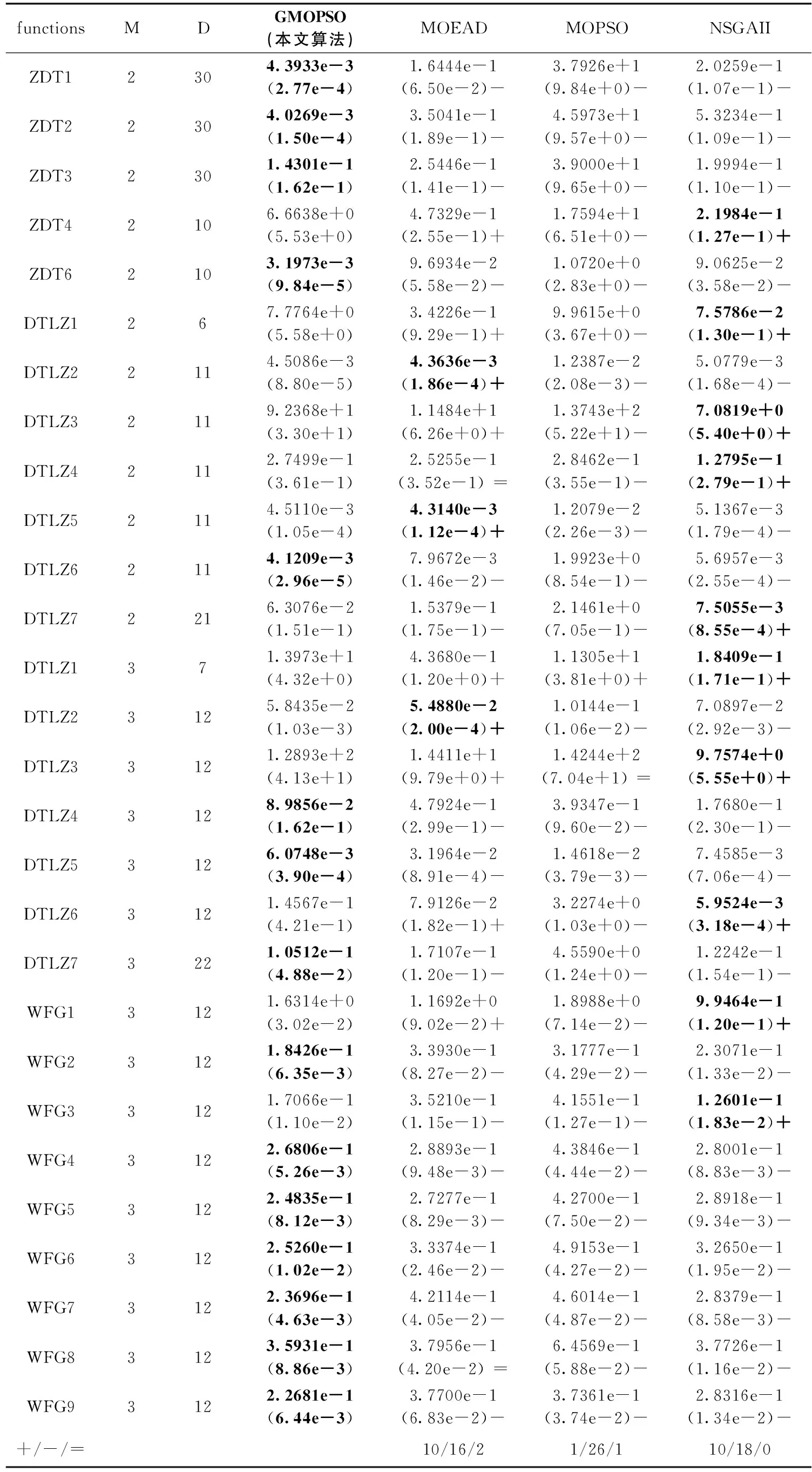
表1 4种算法在标准测试函数上的IGD平均值和标准差
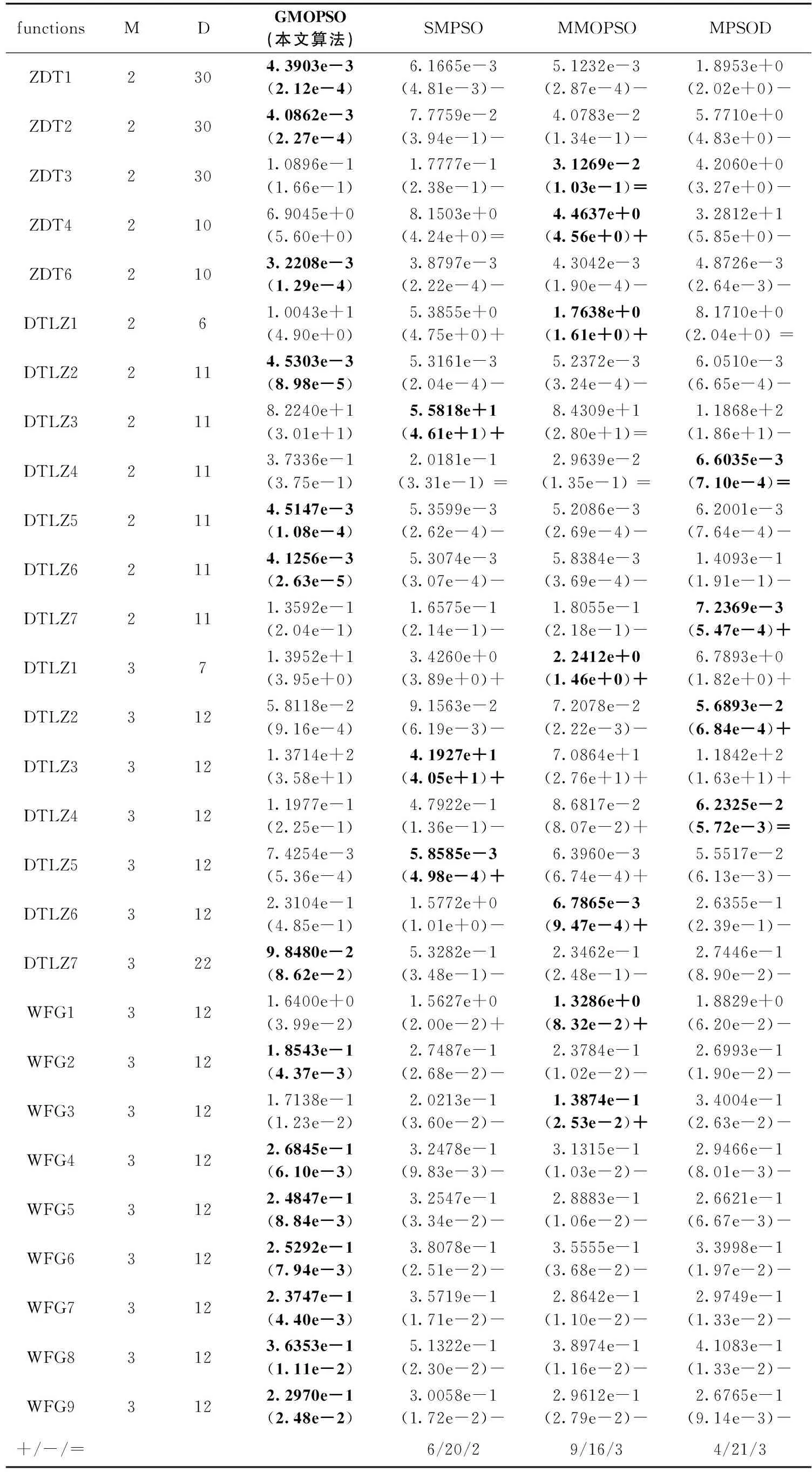
表2 4种算法在标准测试函数上的IGD平均值和标准差
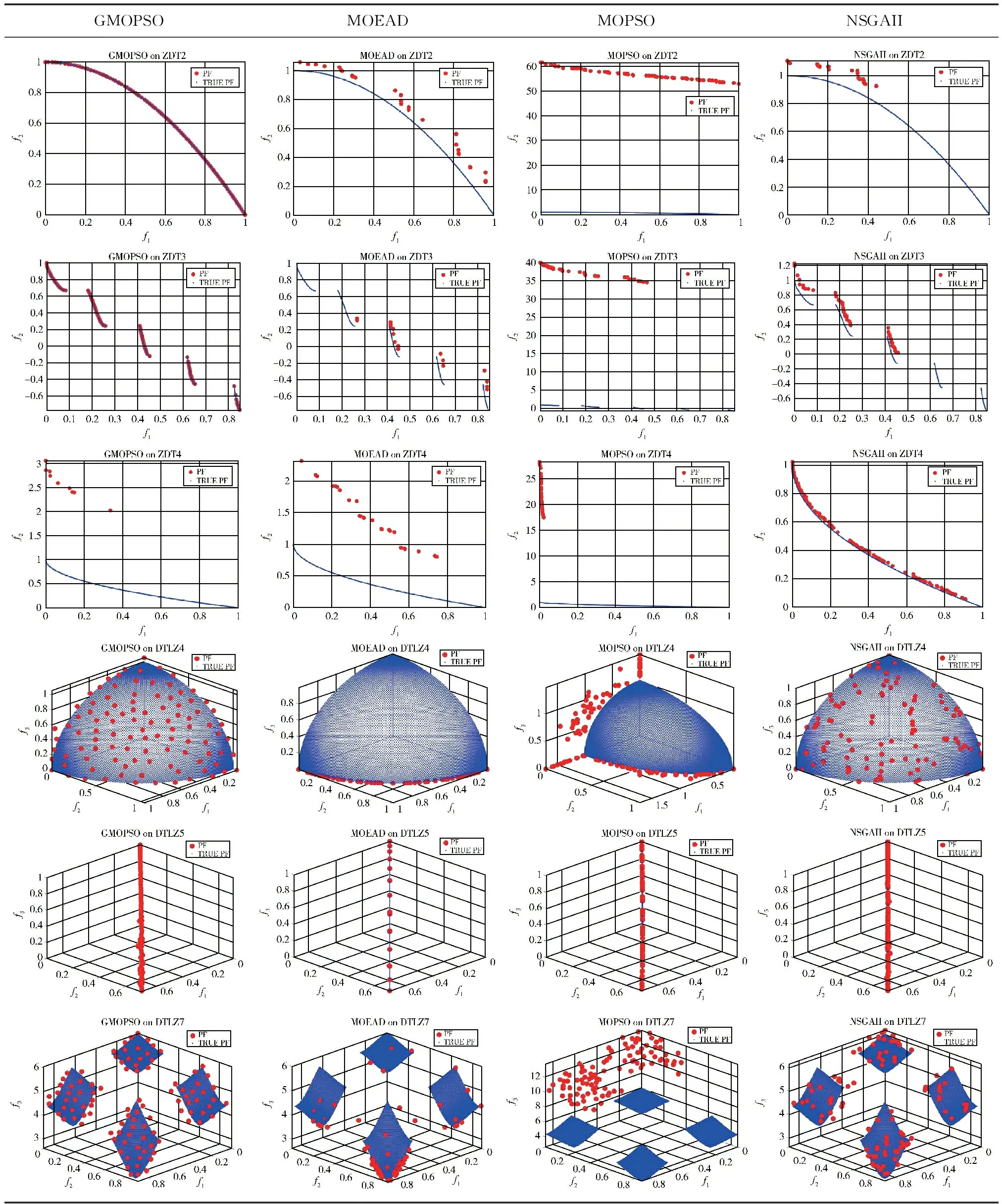
表3 各算法在部分测试函数上的Pareto前端
综上所述可知,新的精英粒子选取方式可以很好地提升算法的收敛性,并且博弈机制的随机性,不同于原始算法,种群在一轮迭代中全局引导者只有一个,导致众多粒子远离自身最优的位置,多样性丢失,在精英集中选择的随机性,以及比较两个随机选出的精英粒子与待更新粒子之间夹角的过程有效维护了种群的多样性,以及多尺度混沌变异有效跳出局部最优能够很好地保持算法的多样性,很好提升了算法的性能,使得本文算法能有效收敛到真实的Pareto前沿。
4 结束语
本文提出了一种特殊机制的多目标粒子群算法即博弈机制。通过使用多尺度混沌变异以及特殊的精英粒子选取方式来提高群智能算法普遍存在的容易陷入局部最优的问题,博弈机制下的粒子更新方式,所有粒子都能成为引导者,很好维持了种群的多样性。待更新者通过博弈成功者的速度和位置更新自己的速度和位置,因为博弈是在当前的种群挑选出的精英粒子中进行的,所以就省去了保存粒子个体最优和全局最优粒子的外部集策略,极大降低了算法的时间复杂度。就本文所做的研究和实验结果来看,本文算法在三目标问题上取得的成绩比在二目标问题上取得成绩要好,说明本文提出的算法倾向于进行高维多目标优化。在3类测试函数上与现今流行的多目标进化算法相比,结果表明了本文所提出的GMOPSO算法在算法收敛性和所得解的多样性上性能优良。
猜你喜欢
太原科技大学学报(2022年1期)2022-02-24
计算机仿真(2021年1期)2021-11-18
数学小灵通·3-4年级(2020年9期)2020-10-27
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
东北大学学报(自然科学版)(2020年1期)2020-02-15
NBA特刊(2018年11期)2018-08-13
物联网技术(2017年5期)2017-06-03
海外星云(2016年7期)2016-12-01
世界汽车(2016年8期)2016-09-28
