
基于循环神经网络的螺丝锁附状态检测
2020-04-29 12:43宋雪倩周稻祥韩晓红李心宇
中北大学学报(自然科学版) 2020年3期
宋雪倩,周稻祥,韩晓红,李心宇
(太原理工大学 大数据学院,山西 太原 030024)
随着工业自动化的发展,为节省人力,提高产品生产效率,自动锁螺丝机被大量运用于精密电子产品装配流水线. 因此,自动锁螺丝机对优化产品装配过程和提升产品质量起着关键作用. 但是,自动锁螺丝机在闭环控制下运行复杂性高、 变量多,导致机器故障无法及时排查并准确定位,一旦锁螺丝机发生故障,整个流水线的生产将会受到影响. 精密电子产品的螺丝尺寸小,装配过程严格且精确,这就要求在不干预锁螺丝机工作的同时检测故障,在发生故障前预判有故障的自动锁螺丝机并进行维修或更换,以保障锁螺丝机的装配质量,从而避免整个流水线停产带来的损失.
目前检测自动锁螺丝机锁附故障的方法主要有以下两种: 一种是把产品固定在传感器上,将传感器信息反馈给可编程逻辑控制器(PLC)进行处理来测定螺丝的锁附情况. 但是,这种方法要求所有螺丝在同一平面,否则传感器不能兼顾所有螺丝,而精密电子产品上的所有螺孔不可能都在同一平面上,这样就需要多次反复调整传感器,操作繁琐且耗时耗力. 另一种则是在锁附端添加一个伸缩弹簧,拧紧螺丝时会有一个压缩量,增加一个光栅尺测定弹簧的压缩量,通过比较压缩量来判断是否存在浮锁故障. 以上两种方法检测的过程主要依赖于额外传感器的工作、 光栅尺对弹簧压缩量的测量,还需要人工调整检测设备,这就大大增加了检测锁螺丝机工序的开销、 复杂性和不确定性. 况且在手机内部检测时,装配这些检测设备再拆除很有可能造成不必要的产品磨损和损失. 并且它们只能检测浮锁,并不能检测精密电子螺丝装配可能产生的锁斜、 未锁进等多种故障. 因此,设计高效的方法实现各种锁附状态的检测是很有意义的研究课题.
自动锁螺丝机的组件扭矩传感器用于测量锁附过程中螺丝被锁入时的扭矩,其产生的一列具有序列关系的数据能够反映锁附过程和锁附状态. 因此,我们可以采用扭矩传感器返回的序列数据,利用序列数据分类的方法,构造螺丝锁付状态检测模型来预判每颗螺丝被锁附的结果,既节省人力物力又能够实现锁附和检测的闭环控制. 因为数据可以敏感地反映出螺丝锁附的各种状态,所以相比于传统的检测方法,基于时间序列数据构造的模型可以检测出更多种类的故障且准确率更高.
基于序列分类方法的有效性与高效性,研究者们对序列分类方法进行了广泛的研究. Lines和Bagnall对多种结合距离和1NN的序列分类方法作对比,结果显示DTW结和1NN的序列分类器效果最好[1]. 之后,他们又发现基于几种距离集成的NN分类器的分类结果优于基于单独一种距离的分类器. 因此,最近几年的方法集中于发展集成方法,其中Lines等人提出的HIVE-COTE是当前性能最好的集成分类器[2-3],但是训练该集成模型的计算开销非常大[4]. 自动锁螺丝机在精密电子产品的螺丝装配过程中产生的数据具有序列超长,不同类别序列趋势相似等特点,这为基于集成的序列分类方法解决锁附序列分类问题带来了很大的困难.
深度学习在多种分类任务中有很好的效果[5],这启发了研究者们用深度学习方法解决序列分类问题[6-9]. 因而,本文提出基于循环神经网络的方法,利用序列前后信息更快更准确地检测自动锁螺丝机的锁附故障. 由于序列超长,一方面会造成网络反向传播时梯度消失,另一方面也会占用大量的CPU处理时间和存储空间. 所以,检测锁附故障时,缩短序列是简化计算过程,提高故障检测准确率的重要步骤. 为了解决这一问题,本文对收集到的原始锁附序列,采用降采样补末值的预处理方法,得到了可建模的序列,最后输入所设计的循环神经网络并得到检测结果.
1 锁附检测网络模型
1.1 神经元结构
长短期记忆网络[10](Long Short-Term Memory,LSTM)模型是对普通循环神经网络进行改进而得到的,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题. 简单来说,LSTM对比普通循环神经网络在类似锁附序列这样的长序列(如图1 所示)问题中有更好的表现.

图1 锁附序列Fig.1 Locking sequence
本文将LSTM网络中的隐藏单元称为LSTM神经元,将隐藏单元为LSTM神经元的循环神经网络称为LSTM网络或者LSTM. 本文介绍的LSTM架构来自于Hochreiter[10].

ft=σ(Wfht-1+Ufxt+bf),
(1)
it=σ(Wiht-1+Uixt+bi),
(2)

(3)

(4)
ot=σ(Woht-1+Uoxt+bo),
(5)
ht=ot*tanh(Ct).
(6)
1.2 网络结构
针对螺丝锁附数据包含多个变量以及变量之间相关的特征,本文设计了多变量LSTM锁附序列多分类网络. 该模型的网络结构包括4层: 输入层、 两个隐藏层和输出层,网络结构如图2 所示. 其中,输入层控制输入数据的格式,输入层包含的神经元个数等于一个序列的时间步; 隐藏层本质就是对特征的一种提取,隐藏层的输出维度是对RNN网络特征复杂度的表征,需要区分的特征越复杂,神经元就需要越多的输出维度来表征. 第一层隐藏层神经元的输出维度为256,第二层隐藏层神经元的输出维度为64. 输出层为softmax层,softmax函数(7)输出以样本属于各类的概率组成的向量,向量长度为类别个数.

图2 循环神经网络结构Fig.2 Recurrent neural network structure
输入层控制输入数据的格式,将预处理后的锁附序列数据转化为样本数、 时间步数、 特征数的三维向量形式作为输入层. 序列的时间长度设为时间步,以每个时刻的特征数作为该时刻的输入维度,接着把每一个时间步的特征输入到隐藏层直到完成所有时间步.
第一层隐藏层包含的LSTM神经元个数等于输入层序列时间步的数目,第二层隐藏层包含的神经元个数等于第一层隐藏层的输出维度.t时刻神经元的输出ht作为该神经元的输出和t+1时刻的输入,直到完成所有时间步的输入. 把第二层隐藏层最后时间步神经元的输出输入到输出层.
基于沿时间轴反向传播算法BPTT[11]的思想,利用深度学习领域流行的Adam[12]优化算法,结合交叉熵的计算结果就可以灵活调整网络的各个权重,直至误差收敛. 另外,对于多变量多参数深度神经网络训练过程中常见的过拟合问题,本文采用隐层加入Dropout[13]的解决办法,其核心是训练期间从神经网络中随机丢弃单元及其连接,这种算法能够有效缓解过拟合问题. 最后,针对数据不平衡的问题,本文采用深度学习框架keras的成熟技术,调整class_weight参数,设置各类数据对应不同权重的方式达到平衡的目的.
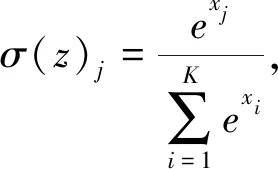
(7)
式中:xi为输入向量第i位的值;K为类别数;σ(z)j为softmax函数的第j个输出值.

(8)
式中:yj为输入向量第j位的真实值;σ(z)j为预测值的第j位;K为类别数.
2 锁附数据收集
2.1 锁附数据收集
螺丝锁附状态检测系统可分为锁附模块和检测模块两部分. 锁附模块主要是借助扭矩传感器收集锁附过程产生的角度、 扭矩、 速度序列数据放入存储系统. 锁附模块每完成一次锁附操作,专家根据经验判断锁附结果并作为序列的真实标签写入存储系统. 当数据存储系统有足够多序列(带有真实标签)时,将其用于训练网络. 当网络收敛时,将网络保存用于检测锁附状态. 检测系统主要从存储系统中读取锁附过程的原始数据进行预处理,接着锁附判别模型分析预处理后的数据得到判别结果,如果锁附成功,那么重复以上过程判别下一颗螺丝. 如果锁附失败,根据模型判定的故障类别指导和监视锁附模块排除故障. 同时,判别结果返回并保存至存储系统. 这里,存储系统保存所有数据,一方面是为网络训练提供数据,另一方面是为了后续研究积累更多数据,从而进一步优化模型. 系统流程如图3 所示.
2.2 锁附数据预处理
为了实现端到端的多分类模型,在使锁附序列数据保持原始信息的基础上,区别于机器学习复杂的数据预处理过程,本文提出的模型在数据预处理过程中只需解决两个问题: 第一,规定序列长度,使变化的序列长度全部相等; 第二,确定一个值用来补齐原始长度小于规定长度的序列,使短序列达到规定长度.
在LSTM模型中,步长一般会被限制在250~500之间[14]. 而锁附序列的长度超过1 000个时间步,若给模型输入原始序列,进行反向传播时会出现梯度消失现象. 因此,对原始序列降采样后能减少时间步,对提高模型精度有帮助.
常见的序列补齐值为0,这种补齐方式是为了满足神经网络输入序列等长的要求,并没有具体问题具体分析. 结合螺丝锁附数据分类问题分析,螺丝锁附数据共分为四类,分别为OK、 浮锁、 未锁进、 锁斜. 每个样本包含三个序列,分别为角度、 扭矩、 速度. 不同类别的序列末值向量(角度、 扭矩、 速度)是不同的,因此用带有特征的序列末值补齐,能够更好地保持序列信息的完整性.
3 实 验
3.1 数据描述
本文实验中锁附模块收集的数据集共包含1 189个样本,其中包含370个OK样本,382个浮锁样本,194个未锁进样本,243个锁斜样本. 取60%作为训练集,20%作为验证集,20%作为测试集,以分层抽样的方式抽取数据,保证测试集和训练集各类比例相同. 每个样本为N×5的矩阵,N为序列数据的长度,5个属性依次为行号、 时间、 角度、 扭矩、 速度. 其中角度、 扭矩、 速度与螺丝锁附过程相关,故本文实验取这三个属性的序列作为输入. 同时,对各类标签作one-hot处理.
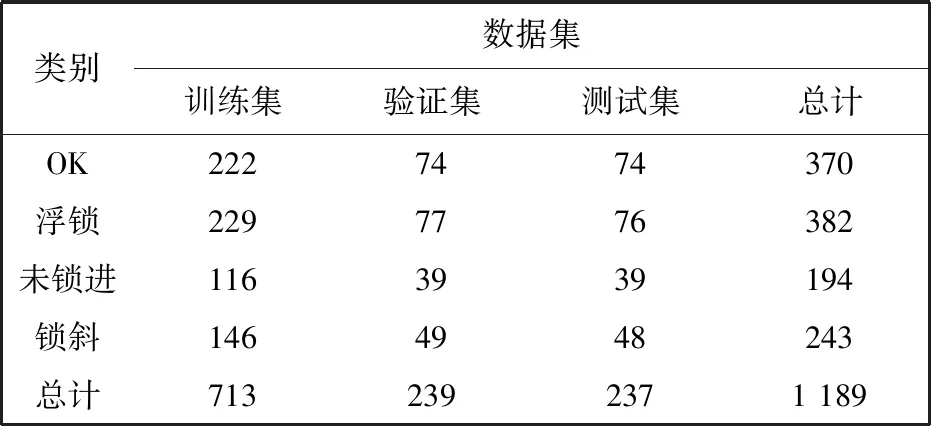
表1 数据集
3.2 数据预处理
由于网络要求序列数据是等长的,本文实验对比两种补齐值,补零或补序列末值. 由于长短期记忆网络是较长的短期记忆网络,序列长度越小,网络可以保留的前期信息越多,从而可以使分类精度越高. 样本集中序列最大长度为4 658,若设计将超长序列缩短为原长度的十分之一,可保证每个超长序列预处理后,长度均小于500. 本文实验将不同标准长度与不同补齐值两两结合作对比试验,共四种结合方式: 序列保持原始长度补零至等长(OZ); 序列保持原始长度补末值至等长(OL); 缩短序列补零至等长(SZ); 缩短序列补末值至等长(SL). 最后,四种不同的预处理方式与本文所设计的网络结合,利用螺丝锁附数据,对锁附状态进行检测. 实验证明本文提出的缩短补末值准确率更高.

表2 预处理
3.3 实验结果分析
从训练集实验结果表3 可以看出,对比锁附状态检测模型一和模型三、 模型二和模型四,在预处理过程中对锁附序列降维后,检测模型的准确率显著提高,且模型的训练时间加快了10倍左右. 这说明序列缩短后在保持了锁附序列数据本身特点的同时,能够使循环神经网络的记忆更长,进而提高模型最终的检测准确率. 对比模型一和模型二、 模型三和模型四,无论在原始锁附序列添加末值还是在缩短序列添加末值,模型检测准确率均有提升. 这是因为不同类别的序列末值不同,因此对于检测模型来说该特征是有效的特征. 而对不同序列均补零,不会增加有效特征甚至对数据增加了噪声. 模型二相比模型一,原始锁附序列补末值准确率增加十位量级; 而模型四对比模型三,缩短序列补末值准确率增加个位量级. 原始序列长度是缩短序列的10倍,也就是说原始序列相比缩短多补齐10倍末值,这也进一步说明序列末值是有效特征.
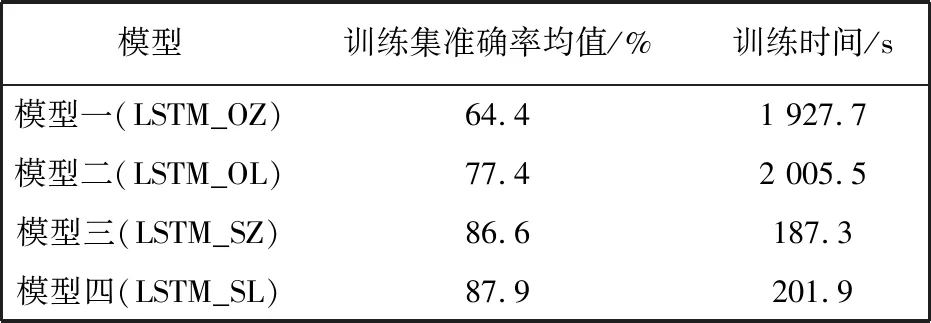
表3 训练集准确率
各类故障会造成产品整体报废,产生更大的经济损失. 表4 结果显示检测模型的故障识别准确率即将故障分为相应故障类的准确率达到了预期值. 衡量各类的检测准确率后,模型四的效果最好,各类的检测准确率均达到预期值. 实验结果中个别模型在某类的准确率为0或100%,在多次添加新的数据后模型检测准确率无明显变化,若增大数据集,准确率可能会上升或下降但范围不会过大.
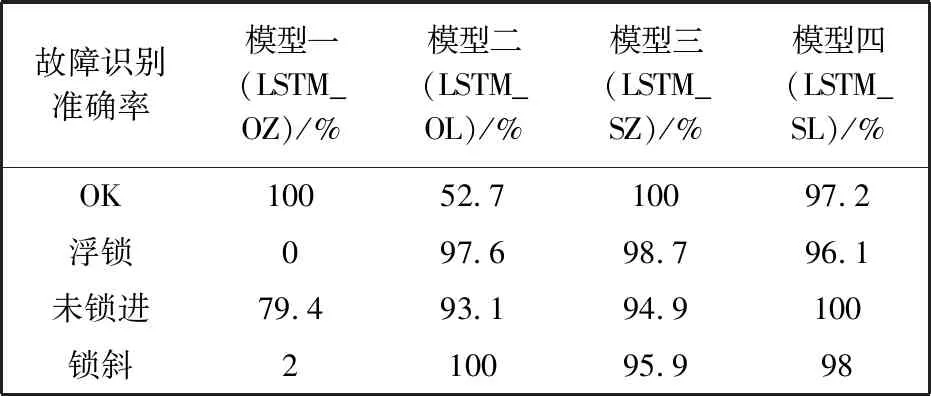
表4 故障识别准确率
表5 所示实验结果将模型四和其他常见的序列分类模型对各类的分类准确率做了对比. 实验结果显示,除锁斜类别外,本文提出的检测模型对其他各类的分类准确率均远高于其他模型. 结合表4 可以看出,虽然本文模型对锁斜类别检测准确率略低于DTW+1NN和LDA,但模型只把锁斜类的2%错分为OK类,基本不会造成经济损失. 进一步分析,本文所提模型对锁斜类别的检测准确率低于其他类别,其原因来自两方面: 一方面是锁斜样本长度的分布不集中,如表6 所示,即样本长度分布在多种值上,因此,无论如何随机划分训练集和测试集,训练样本和测试样本的分布都会有较大的偏移,导致模型难以记住测试样本; 另一方面,锁斜类别数据有多种序列趋势,如图4所示,这种变化性对模型识别该类序列的准确率造成影响.
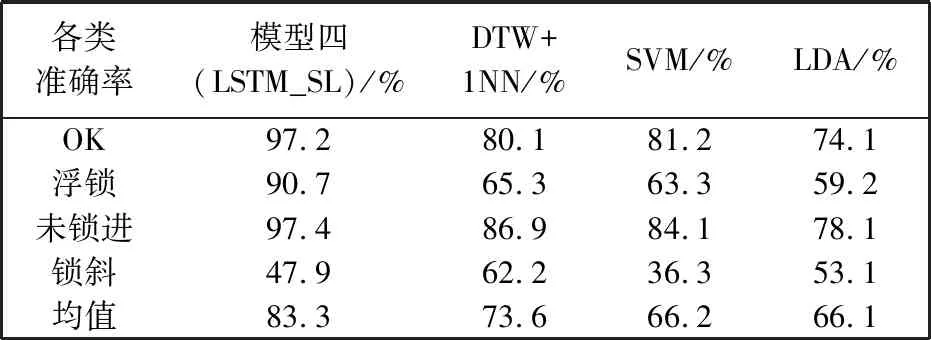
表5 测试集准确率
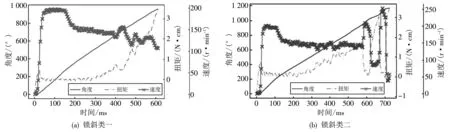
图4 锁斜类角度、 扭矩、 速度序列Fig.4 Crooked locking angle, torque and speed sequence
4 结 论
循环神经网络是一类处理序列数据的神经网络,LSTM相对普通循环神经网络有较大突破,也是近年来在处理序列数据时被广泛应用的变体. 随着深度模型在工业领域的发展,本文将LSTM首次应用在锁附操作的工业场景中,并在数据收集、 数据预处理、 模型训练. 模型应用四个方面提供了详细介绍. 面对自动锁螺丝机锁附故障判定的任务,利用自动锁螺丝机采集的数据,采用循环神经网络结合序列缩短和补齐的预处理方式,得到一个锁附状态检测模型,能够有效判定锁附故障. 本文首次将循环神经网络技术应用于判定自动锁螺丝机锁附故障的任务中,相比传统检测方法发现故障更及时,从而降低了故障带来的风险. 并且检测故障类型的多样性能够为进一步改进自动锁附技术提供依据. 检测自动锁螺丝机的故障对保障流水线生产更高效,提高经济效益有重大作用.
收集螺丝锁附数据并对数据定义正确的标签,需要大量的人力,但人的加入给需要严格定义的标签带来了极大的不稳定. 所以,借助序列数据聚类结果作为一个标签,同时参考人定义的标签,利用多标签分类方法能使自动锁螺丝机锁附故障的判定更加准确,这也是进一步研究的方向.
猜你喜欢
幼儿画刊(2022年6期)2022-06-06
现代电力(2022年2期)2022-05-23
当代陕西(2022年6期)2022-04-19
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
阅读(科学探秘)(2020年4期)2020-07-04
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
