
基于神经网络的违禁品检测研究
2020-05-20 15:05马喆丁军航谭虹
青岛大学学报(工程技术版) 2020年2期
马喆 丁军航 谭虹


摘要: 为了解决违禁品带入公共场合的问题,本文对违禁品的识别进行了研究。在安检仪中,加入改进的YOLOv3网络检测算法,使其能够检测出违禁品,而在基础网络上,引入多维输入图和多分辨率输入图,增加了样本的多样性,有效解决了模型的适应性差的问题。在端到端的网络上,用分层方法进行特征提取和分类,获得不同尺度的特征图,以此来提高网络测试的精度,并采用聚类算法确定目标轮廓,使其能够精准定位。实验结果表明,改进的网络识别目标精度在90%以上,高于原网络的精准度。本网络效果好,具有较高的识别率,且封装在模块中,操作简单。该研究可有效提醒安检员防止违禁品带入公共场合,造成公共事故。
关键词: YOLOv3; 端到端; 特征提取; 聚类算法
中图分类号: TP391.41文献标识码: A
收稿日期: 20191031; 修回日期: 20191230
基金项目: 国家自然科学基金资助项目(61573203);青岛市博士后人员应用研究项目(2016021)
作者简介: 马喆(1994),男,硕士研究生,主要研究方向为模式识别。
通信作者: 丁军航(1979),男,博士,副教授,硕士生导师,主要研究方向为模式识别与图像处理。 Email: dingjunhang@163.com随着人口的不断增多,公共场所的人口密度变得越来越大,一旦发生事故就后会产生拥堵的情况,逃离的可能性很小,因此,严禁违禁品带入人口密度大的场合[1]是解决问题的关键。2011年,在河南信阳段高速上,因车厢内违法装载易燃危险化学品突然发生爆燃,导致客车起火燃烧,造成人员的死亡和受伤。目前,安全检查主要包括行李物品检查、旅客证件检查、手提行李物品检查和旅客身体检查。其中,旅客证件检查主要是确定乘客基本信息,其它三项检查均是防止乘客携带刀、枪、易燃易爆品等危险物品,以确保公共场所及交通的安全。但在春运或法定假期期间,由于客流量较大,排队安检会发生拥堵情况,而且工作量的增加,也会使工作人员观察不仔细,导致违禁品带入公共场合,危害公共安全[2]。因此,针对这种状况,本文比较了你只看一次[35](you only look once version 3,YOLOv3)、单一多盒检测器[67](single shot multibox detector,SSD)、快速區域卷积神经网络[89](fast regionbased convolutional neural network,Fast RCNN)等网络的区别,最终选择了基于卷积结构的YOLOv3网络,对其进行改进,优化网络架构及层数,使其在计算过程中减少计算量。同时,根据样本信息,更改先验框维度大小,提高对目标的精准定位,对样本进行多样化处理,并进行多尺度训练,以保证算法能够快速准确的识别和定位出目标物体。该研究为工作人员减轻了工作负担,同时也降低了公共场合事故的发生率。
1YOLOv3相关理论
1.1基础层
1.1.1Darknet53
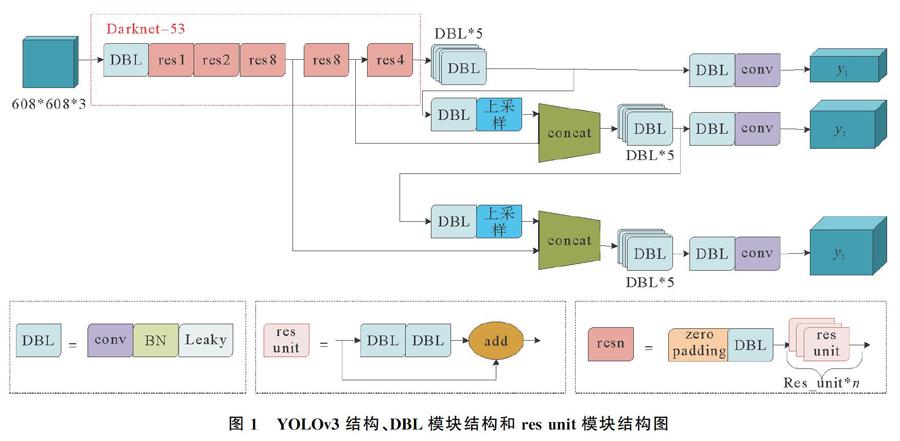
0~74层是YOLOv3主结构,其含有53层卷积层,故叫做Darknet53。YOLOv3结构、DBL模块结构和res unit模块结构如图1所示。Darknet53是由多个残差层组成,残差模块和残差层见图1中的res unit和res n,并用卷积层替代池化层,控制梯度的传播,在训练过程中,有效解决了迭代次数增多而产生的梯度消失或爆炸问题。
1.1.2多尺度训练
75~105层是3个尺度的特征层,在每个尺度中,通过卷积操作和上采样操作,将相同尺寸的特征图合成一个特征图,经过卷积处理得到新的特征图。在原YOLOv3中,归一化尺度为416×416,在darknet53之后,进行卷积操作得到13×13特征图,作为最小尺度y1。将79层的13×13特征图进行卷积和上采样操作,得到的特征图与61层的26×26特征图合并,得到中尺度y2。将91层的26×26特征图进行卷积和上采样操作,得到的特征图与36层的52×52特征图合并,得到最大尺度y3(见图1)。多尺度训练[10]可以更好地识别大小不一的目标,提高目标识别率,小尺度可检测小目标,大尺度可检测大目标,可以提高网络精度。本文中的样本缩放比例太大,会造成图片像素重叠,进而识别不出目标。因此,将归一化尺度更改为608×608,3个尺度设置为19×19,38×38,76×76。
1.2回归及改进
1.2.1分类方法
YOLOv3的分类方法,由单标签多分类的Softmax函数更换为多标签多分类的逻辑回归。逻辑回归分类步骤分为3步,分别是线性函数、数值到概率的转换及概率到标签的转换。
输入为X,逻辑回归采用sigmoid函数,将决策边界转换成值,保持在0~1之间的概率函数,用概率确定样本标签是某一类别的可能性。
为防止概率函数hθX过拟合,需在损失函数后加一项,则损失函数为
式中,m是样本个数;y是真实值;λ是正则化公式强度参数;hθX是输出结果。
损失函数梯度为
其中,λ为正则化的强度。
通过学习率对特征系数的迭代,得出某一值,就可算出特征向量系数θ。
1.2.2边框预测
边框预测是YOLOv3的方法,使用先验框的定义,即用Kmeans++算法对训练集上的目标尺寸大小进行聚类分析,使之有相似特征目标归为一类,并根据尺寸大小确定anchor box的维度。
YOLOv3运用与特征金字塔网络[11](feature pyramid networks,FPN)相近的上采样和融合思想,将输入图像分为多个尺寸不同的特征图,然后进行检测。YOLOv3中分成3个尺度,并将每个尺度输入图像的网格单元(grid cell)中,预测3个bounding box,且每个bounding box有5个基本参数,分别是x,y,w,h,confidence。预测得到的中心横坐标、纵坐标、宽和高、物体的置信度分别为
bx=σtx+cx, by=σty+cy, bw=pwetw, bh=pheth, probject*IOUb,object=σto(5)
式中,tx,ty是预测的坐标偏移值;cx和cy是单个网络单元的横坐标和纵坐标;pw,ph为anchor box的宽和高;bx,by,bw,bh是预测得到的中心横坐标、纵坐标、宽和高;probject是代表存不存在目标物体;IOUb,object是bounding box和目标标注框之间的交并比;σto是物体的置信度,是确定为该物体的几率。
在YOLOv3对bounding box进行校对时,采用逻辑回归分析。网络在预测中得到tx,ty,tw,th这4个参数,并按照式(5)来得到需要的bx,by,bw,bh这4个参数。
每个网格单元都有3个bounding box,但不是所有的bounding box都参与预测过程。在预测前,对bounding box的confidence参数进行计算,并使之超过预设阈值才可进行预测,这样既保持了准确性,又减少了计算量,提高了速度。
1.2.3Anchor Box
YOLOv3使用了anchor box。anchor box是由Kmeans++算法[1215]得出的寬高固定先验框,其个数自己设置,设定维度和个数与精度和速度相关。在进行网络训练时,随着训练次数的更新,bounding box的参数慢慢地接近ground truth。对于刀枪瓶罐数据集,其目标在图片中的形态和大小各不相同。为了能使网络更精准地检测到目标物体,本文采用改进的Kmeans++算法,对数据集下标注的边框进行聚类分析,得到先验框的维度。传统的Kmeans算法采用欧式距离公式会产生较大的误差,所以Kmeans++算法采用新的距离,首先计算预测框与真实框交并比,然后用1减去交并比,得到距离Disbox,centroid。IOUtruthpred是预测框和实际框之间的交集比预测框和实际框之间的并集,IOUbox,centroid是样本框与质心框之间的交并比,Disbox,centroid则是Kmeans++中尽可能远的选择质心的距离公式,即
式中,boxpred是预测框;boxtruth是标注框;area是面积。
K值是先验框的数量,针对改进的YOLOv3[1618],则使用K=9进行聚类,得到先验框。在检测过程中,用3种尺度进行检测,且每个网格单元需要预测3个bounding box,且需要9个先验框来确保网络的准确性。所有的bounding box都会生成,用confidence的数值与特定阈值结果进行比较大小,得出bounding box是否参加预测。
2网络训练
2.1参数设置
在进行网络训练之前,需要调整网络参数,以开源Darknet[1920]为框架,设置网络参数,网络参数如表1所示。
设置各类参数,防止训练过程中出现过拟合的情况,并通过饱和度、曝光率和色调的改变来增加训练样本的数量,从而使识别精度更加精确。
2.2数据处理
对数据集进行汇总之后,用LabelImg软件进行标记,将所需目标选中,并确定好标签名称,依次进行标记,同时选用YOLO格式,保存为TXT格式文件。LabelImg标记画面如图2所示。
2.3数据样本
在进行网格训练前,先制作训练所需样本。首先从COCO数据集中下载部分数据集作为第1次数据集,其次截取特定安检图像作为第2次数据集,其有5 000张图像,包含刀目标2 694个,枪目标1 369个,罐状目标1 134个,样本展示如图3所示。最后改变输入图像的大小,使其在归一化处理时产生不同的分辨率,提高识别精度,并作为第3次数据集。
3.1实验平台配置
配置工作站实验平台,采用中央处理器(central processing unit,CPU)和图像处理器(graphics processing unit,GPU)等操作系统,实验平台配置列表如表2所示。
3.2性能测试
3.2.1候选框生成对比
用Kmeans++聚类算法对样本的目标框进行分析,得到合适的anchor维度,和原YOLOv3的anchor维度进行比较,候选框生成对比结果如表3所示。由此可得改进的YOLOv3[21]的先验框,提高了平均重叠率,大大提升了检测目标的精度。
3.2.2多尺度训练与单尺度训练对比
利用多尺度进行训练,得到的特征图像更多,能更好的检测图像中的目标。使用不同大小的图像作为样本集时,在单尺度和多尺度训练下得到的结果不同,多尺度与单尺度网络性能对比结果如表4所示。单一尺度训练是将输入尺寸为608×608的数据集通过网络不增加合并特征图的过程,而多尺度是将输入尺寸为608×608的数据集通过网络增加合并特征图的过程,从而使模型更能精准地识别测试集里的目标。
在电脑上对改进的YOLOv3结构进行测试,俯视图测试结果如图4所示。
由图4可以看出,改进结构对行李箱或包裹物体的检测整体效果比较好,能够精准地定位到危险物品。在遮挡且不影响物体轮廓的情况下,可以检测出目标物体(见图4b);若是出现偏角度或遮挡物体轮廓的情况下,检测不出目标(见图4e)。
经过安检设备的行李箱或包裹,从两个方向进行拍摄,得出X光图像,并以两个识别结果来检验俯视图下未被检测到的目标物体。俯视图和侧视图测试结果如图5所示。
由图5可以看出,在图5a中未检测出的物体,根据侧视图目标标记的位置来确定是否存在目标物体,运用2个进程从2个方向对输入图像进行检测,既确保了精度,又降低了漏检率。由于一些角度问题或遮挡问题,在俯视图下可能不能完全的检测出所有目标,在图5b中检测出了图5a中未检测出的瓶子,说明侧视图可以对俯视图的检测进行补充,能更好的检测目标物体,达到所需要求。
4结束语
本系统使用了开源框架Darknet和YOLOv3算法的目标识别方法,对样本图进行处理,利用多尺度训练,得到大小不一的特征模型,使模型具有更高的可信度,更能很好的检测目标。与原目标算法相比较,对样本重新进行了维度聚类,在检测过程中减少了计算量,加快了检测速度,达到了实时检测的要求。但本文所涉及的内容仍具有需要完善的地方,比如在目标物体相互遮挡或目标物体与背景材质相同时而产生轻微的边缘信息的情况,则难以检测出目标物体,在此方面还有很大的提升空间,对检测算法进行优化,处理目标物体遮挡和边缘信息的情况,提高检测精度是将要研究的课题方向。
参考文献:
[1]徐草草, 杨启明, 张双. 基于人脸识别技术的自动安检系统设计[J]. 计算机与数字工程, 2019, 47(8): 19091911, 1925.
[2]徐一鹤, 何林锋, 叶东胜, 等. X射线行李安检相的植测及其重要性[J]. 上海计量测试, 2010, 37(1): 4345, 50.
[3]Redmon J, Divvala S, Girshick R, et al. You only look once: unified, realtime object detection[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2015.
[4]Ke TW, Maire M, Yu S X. Multigrid neural architectures[C]∥Computer Vision and Pattern Recognition. Colombia: IEEE, 2016.
[5]Redmon J, Farhadi A. YOLOv3: An incremental improvement[C]∥2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake: IEEE, 2018.
[6]Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multi box detector[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2015.
[7]陈冠琪, 胡国清, Jahangir Alam S M, 等. 基于改进SSD的多目标零件识别系统研究[J]. 新技术新工艺, 2019(8): 7276.
[8]Girshick R, Donahue J, Darrelland T, et al. Rich feature hierarchies for object detection and semantic segmentation[C]∥2014 IEEE Conference on Computer Vision and Pattern Recognition. Colombia: IEEE, 2014.
[9]Lokanath M, Kumar K S, Keerthi E S. Accurate object classification and detection by fasterRCNN[J]. IOP Conference Series: Materials Science and Engineering, 2017, 263: 18.
[10]Zhang J, Dai Y, Porikli F, et al. Multiscale salient object detection with pyramid spatial pooling[C]∥2017 AsiaPacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). Kuala Lumpur, Malaysia: IEEE, 2017.
[11]Lin T Y, Dollár Piotr, Girshick R, et al. Feature pyramid networks for object detection[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 21172125.
[12]Zhang Z, Zhang J X, Xue H F, et al. Improved kmeans clustering algorithm[J]. Congress on Image & Signal Processing, 2008, 23: 435438.
[13]吳晓蓉. K均值聚类算法初始中心选取相关问题的研究[D]. 湖南: 湖南大学, 2008.
[14]Kanungo T, Mount D M, Netanyahu N S, et al. An efficient kmeans clustering algorithm: analysis and implementation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 881892.
[15]张素洁, 赵怀慈. 最优聚类个数和初始聚类中心点选取算法研究[J]. 计算机应用研究, 2017, 34(6): 16171620.
[16]张富凯, 杨峰, 李策. 基于改进YOLOv3的快速车辆检测方法[J]. 计算机工程与应用, 2019, 55(2): 1826.
[17]郭鸣宇, 刘实. YOLOv3图像识别跟踪算法的优化与实现[J]. 电子测试, 2019(15): 6567.
[18]文浩彬, 张国辉. 基于YOLO的驾驶视频目标检测方法[J]. 汽车科技, 2019, 269(1): 8690.
[19]刘博, 王胜正, 赵建森, 等. 基于Darknet网络和YOLOv3算法的船舶跟踪识别[J]. 计算机应用, 2019(6): 16631668.
[20]张佳康, 陈庆奎. 基于CUDA技术的卷积神经网络识别算法[J]. 计算机工程, 2010, 36(15): 179181.
[21]Tian Y N, Yang G D, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLOV3 model[J]. Computers and Electronics in Agriculture, 2019, 157: 417426. Research on Contraband Detection Based on Neural NetworkMA Zhe1, DING Junhang1, TAN Hong2
(1. School of Automation, Qingdao University, Qingdao 266071, China;2. State Grid Weifang Power Supply Company, Weifang 261021, China)
Abstract: In order to solve the problem that contraband is brought into public places, this article studies the identification of contraband. An improved YOLOv3 network detection algorithm was added to the security checker to enable it to detect contraband. On the basic network, multidimensional input maps and multiresolution input maps were introduced, which increased the diversity of samples and effectively solved the problem of poor model adaptability. On the endtoend network, layered methods are used for feature extraction and classification, and feature maps of different scales are obtained to improve the accuracy of network testing. In addition, a clustering algorithm is used to determine the target contour so that it can be accurately located. Experimental results show that the accuracy of the improved network recognition target is more than 90%, which is higher than that of the original network. The network has a good effect, has a high recognition rate, and is packaged in a module for easy operation. The study can effectively remind security inspectors to prevent contraband from being brought into public places and causing public accidents.
Key words: You Only Look Once version 3; end to end; feature extraction; clustering algorithm
收稿日期: 2019-10-31; 修回日期: 2019-12-30
基金項目:国家自然科学基金资助项目(61573203);青岛市博士后人员应用研究项目(2016021)
作者简介:马喆(1994-),男,硕士研究生,主要研究方向为模式识别。
通信作者:丁军航(1979-),男,博士,副教授,硕士生导师,主要研究方向为模式识别与图像处理。 Email: dingjunhang@163.com
猜你喜欢
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
无线互联科技(2016年14期)2017-02-06
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
科技传播(2016年19期)2016-12-27
电脑知识与技术(2016年8期)2016-05-19
科技视界(2016年8期)2016-04-05
电子技术与软件工程(2015年6期)2015-04-20
