
基于SVM与Inception-v3的手势识别①
2020-05-22 04:47吴斌方肖书浩
计算机系统应用 2020年5期
吴斌方,陈 涵,肖书浩
1(湖北工业大学 机械工程学院,武汉 430068)
2(武昌首义学院 机电工程研究所,武汉 430064)
引言
近年来,机器学习(machine learning)领域快速发展,图像识别技术日益成熟,人机交互方式也随之改变.手势识别是人机交互中最简单、最直观的一种交互方式.该方式摆脱键盘、鼠标、按键等硬件束缚,具有简单易学、操作方便、动作直观等特点,极大增加用户体验感和人机互动性.
手势识别技术可分为两种:基于数据手套技术和基于机器视觉技术[1].国内外学者针对机器视觉手势识别技术都有相应的研究与发展,Mahmoud 等[2]利用YCbCr 颜色空间和深度信息结合高斯混合概率模型(GMM)计算手部区域,利用隐马尔可夫模型(HMM)进行手势识别.Saha 等[3]利用Kinect 传感器采集数据和隐马尔可夫模型(HMM)进行手势识别;隐马尔可夫模型(HMM)是手势识别领域常用的方法,该方法需要大量参数,对识别时间和效率有一定影响.Tusor 等[4]利用模糊神经网络(FNN)根据预处理后的手势数据建立手势特征模型,用模糊推理进行手势识别;该方法网络层数浅,学习能力较弱,训练过程容易出现过拟合,识别效果不好.Marin 等[5]利用Leap motion 传感器和深度相机提取指尖间角度、距离和空间坐标等参数作为手部特征,将特征馈送到SVM 和随机森林进行手势识别,该方法对硬件的要求高,样本预处理较为复杂.任彧等[6]运用方向梯度直方图(Histograms of Oriented Gradient,HOG)提取手势特征,利用SVM 学习识别手势,消除了光照和手部旋转对手势识别的影响,但背景要求单一,识别准确率不高.朱越等[7]利用HSV 和RGB 颜色空间联合进行手势分割,根据手势轮廓像素变化判断手势,该模型对肤色的抗干扰能力较差,适应面窄,识别种类局限.操小文等[8]利用8 层的卷积神经网络对手势样本进行训练和识别,该方法需花费长时间设计定义网络模型,且样本背景需单一,抗干扰能力差.
本文针对手势识别提出了一种SVM 手势分割与迁移学习相结合的方法,利用SVM 对样本进行手势分割,采用迁移学习方法将Inception-v3 模型进行finetuning,通过实验对比获得最优性能的超参数,得到新的手势识别网络模型.本文使用SVM 对样本手势分割增加了手势分割的鲁棒性和强适应性,消除了肤色、光照、旋转和背景等因素的干扰,运用迁移学习简化定义和设计CNN 的工作,节省大量网络设计和网络训练时间,构建的模型在识别准确率和识别效率上均有一定提升.
1 卷积神经网络与迁移学习
卷积神经网络是一种深度前馈神经网络,是深度学习领域的一个重要分支[9],它在图像处理领域表现出优越的性能.卷积神经网络将原始图像信息分块处理,能适应图像特征的平移旋转,且分块处理特征信息后参数明显减少,对提高模型学习效率有显著影响.
传统机器学习方法学习训练的过程需要庞大的训练数据集,且测试数据集的数据分布需与训练数据集相同.在大数据时代背景下,轻松获取所需领域且满足工作任务需求的庞大数据集仍存在一定的难度.另一方面,在监督学习完成学习任务时,需要大量的人工将训练数据集进行逐一对应的标注,耗费大量的人力物力,对于一般的高校的机器学习研究或者小型公司的机器学习技术开发都有极大的障碍.测试数据集的数据分布亦常难以与训练数据集的数据分布一致,给传统的机器学习方法带来一定的难度.
迁移学习可以很好的解决上述问题,迁移学习是运用已存有的知识对不同但相关的领域的问题求解的一种新的机器学习方法[10].迁移学习在源领域模型上仅需少量的训练数据集便可以建立一个针对目标领域的新模型,对数据分布不同的目标领域进行预测和分析.
2 实验数据准备与预处理
2.1 样本采集
网络上的手势数据集较匮乏且不满足实际需求,遂利用实验室设备采集手势数据集,采集10 类不同手势各250 张,共2500 张手势样本,取出每种手势样本中的25 张作为验证数据集.采集到的2500 张样本进行尺寸归一化处理,得到2500 张640×360 像素的手势样本,提高手势识别准确率.部分样本如图1所示.
2.2 样本增强处理
将2500 张样本随机高斯模糊化处理,将样本与二维的高斯分布的概率密度函数作卷积,随机模糊样本.
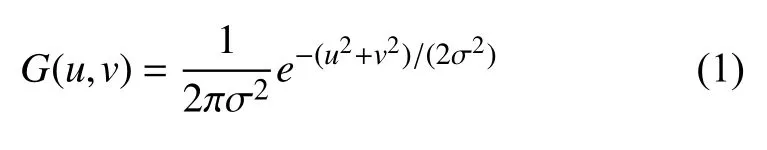
其中,σ为正态分布的标准偏差,(u2+v2)为模糊半径r的平方.
对样本进行旋转偏移处理,随机对样本添加少量噪声,增强网络识别的鲁棒性,防止网络产生过拟合现象对测试结果造成影响.
2.3 SVM 手势分割
手势识别的重要的一个步骤是对样本中的手势进行分割,提取重要的感兴趣区域信息,剔除多余背景和环境对识别准确率造成的干扰.传统的通过肤色阈值对手势进行分割的方法一般有2 种,在RGB 空间肤色阈值分割、HSV 空间肤色检测.
RGB 空间肤色阈值分割中R(0~255),G(0~255),B(0~255)3 种像素值同时满足式(2),式(3)则为肤色.
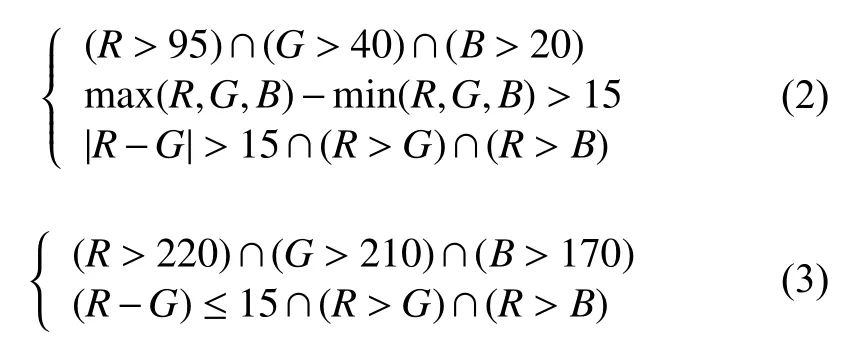

图1 样本采集
当背景颜色与肤色相同或相似时,会对肤色分割造成一定干扰,对背景要求较高.
HSV 空间肤色建模要求H(色调Hue),S(饱和度Saturation),V(亮度Value)满足式(4)则为肤色.
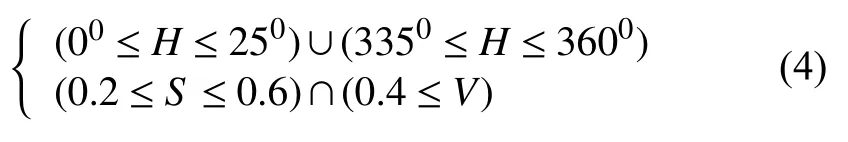
H、S、V三通道的值对应HSV 空间中的某一点,实际环境中光照的亮度会带来色调的改变,对光照强度的强适应性给肤色检测带来一定噪声.
本文利用SVM 将手部区域与背景区分开,形成手势分割.SVM 在对图像的二分类处理问题有出色的表现,泛化能力较强.其基本的思想是将在低维空间非线性可分的两类映射到高维空间,求解出一个超平面(hyper lane)在高维空间线性可分的两类数据完成分类.本次实验采用线性(liner)核函数(kernel):K(x,y)=xT·y,目标函数惩罚系数C=1.0.利用Python 的Tkinter 模块编写可视化界面对样本进行标记,将手部区域与背景区域区分开,如图2所示,其中红色标记为手部区域,绿色点标记为背景区域.
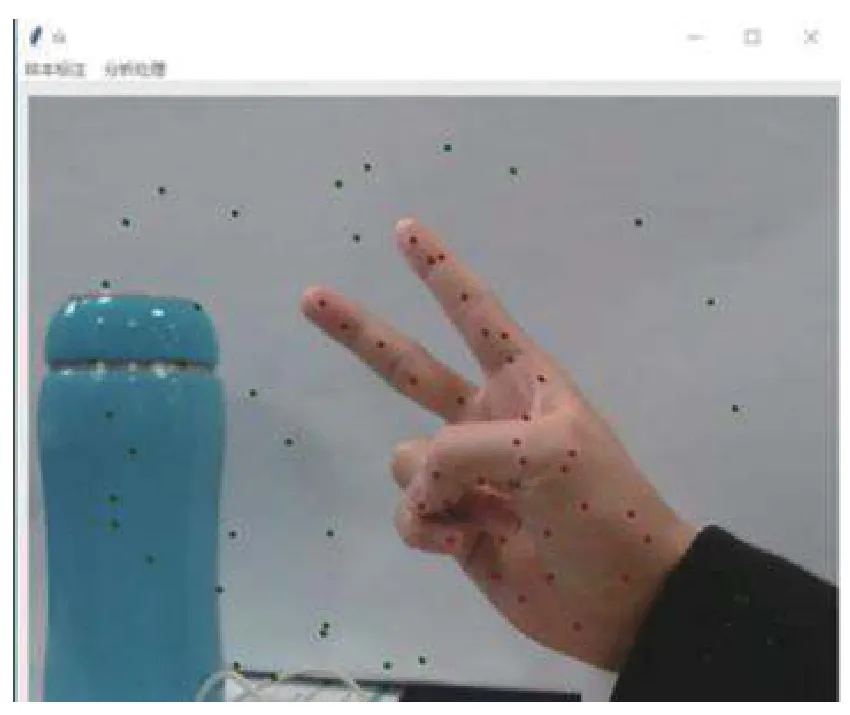
图2 SVM 样本标记
标记完成后利用SVM 学习并显示结果,各手势分割方法分割结果如图3所示.通过对比实验效果,上述前两种方法都有一定局限性,RGB 空间肤色阈值分割只有在背景单一和光照稳定的条件下肤色分割效果较好,有一定的局限性,如图3(b)所示;HSV 空间肤色建模对光线的鲁棒性较强,但分割离散,肤色区域不连续,无法分割出完整手势,如图3(c)所示.利用SVM 学习后对手势进行分割的效果明显优于基于RGB 和HSV肤色分割的方法,如图3(d)所示,不仅在手部区域连续性较好,对环境的要求也较低,且该方法鲁棒性和灵活性将强,对于肤色区别较大的实验者只需重新学习即可得到满足需求的手势样本.
利用训练好的SVM 模型对2500 张样本进行批量手势分割处理,最后将手势分割后的样本选取适当的全局阈值,经过全局二值化处理,得到2500 张手势二值样本,如图4所示.
3 实验方法
本次实验采用迁移学习方法将Inception-v3[11]模型结构作为训练模型的结构基础.Inception-v3 模型由谷歌提出,其网络思想与其他深度网络主要有几点不同,一方面网络使用更小的卷积核代替尺寸相对较大的卷积核,例如将两个3×3 的卷积核代替一个5×5 的卷积核.另一方面网络将n×n例如3×3,7×7 的二维卷积拆分成两个1×n,n×1 例如3×1,1×3 和7×1,1×7 的二维卷积,这种方式让网络参数量大大减少,在加快运算速度的同时也减少了过拟合的情况,且这种对卷积结构的不对称拆分使特征空间保留完整,网络非线性表达的能力也更强.网络使用Batch Nomalization(BN)算法[12],通过规范化方法将输入分配到均值为0 方差为1 的正态分布,有效解决深层网络的梯度消失问题,大幅增加训练效率和收敛后的样本分类的准确率.

图3 各方法手势分割结果

图4 二值化处理样本
将Inception-v3 中Softmax 回归层一维输出大小从1000 类定义为所需识别手势的10 类,保留除Softmax层外所有层的参数,将网络的底层作为一个特征提取器,只训练最后一层参数达到模型能够识别10 类手势的目的.模型通过标签平滑方式进行模型正则化,首先对于输入的手势样本x,使用式(5)计算对应标签的概率.
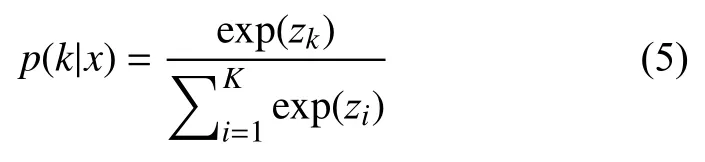
其中,k为手势标签类别,Zi为尚未归一化的对数概率.手势样本在对应标签上在分布为q(k|x),将样本损失定义为交叉熵损失函数:
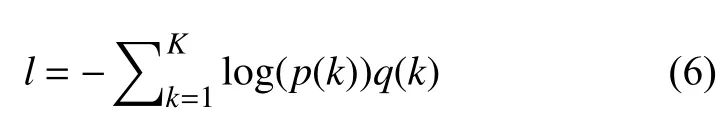
最小化交叉熵等价于最大化标签对数似然期望,其梯度为:
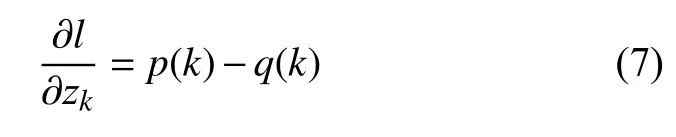
用q’(k|x)代替标签分布q(k|x)=δk,y:
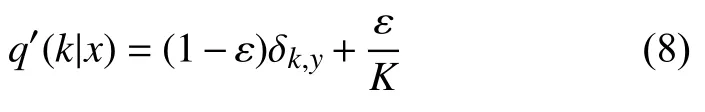
其中,δk,y为狄拉克δ函数,(1–ε)与ε分别为实际分布和固定分布的权重.
Fine-tuning 微调是训练深度卷积神经网络的技巧之一,原理是采用模型原有参数作为网络的初始化参数,冻结部分网络层,降低学习效率,以目标数据作为输入在原有参数基础上训练参数.Fine-tuning 后的网络模型更易训练,节省大量训练时间,精度会相较直接随机初始化参数的网络有所提高.
完成定义网络模型后将手势分割后的二值化样本导入模型训练,冻结网络175 层参数,调整网络超参数得到不同准确率和交叉熵损失函数曲线.
4 实验与结果
4.1 实验
本次实验环境为Windows 10 操作系统,采用GTX1060 显卡在Tensorflow 深度学习框架下完成实验.
为增强模型性能,快速达到收敛,让网络具有较好的识别效果和节省适当的训练、识别时间,调整网络模型的一系列超参数作纵向对比实验.训练集训练与测试集测试均在GPU 加速环境下运行.模型采用RMSPro[13]梯度下降算法,设置衰减值为0.9,ε=1.0.
设定默认批次大小(batch size)为64,学习效率(learning rate)为0.045,迭代次数(epoches)为2000,得到迭代次数与准确率和损失函数的关系.由图5看出,模型在1000 次迭代后基本趋于稳定,准确率随迭代次数增长的波动较小,损失函数也基本趋于稳定,考虑迭代次数增加对网络模型产生过拟合情况的影响,迭代次数恒定设置为1000.

图5 迭代次数对模型的影响
对比学习效率对模型识别准确率和损失函数的影响,学习效率对模型训练起至关重要的作用,较低的学习效率导致模型收敛速度较慢,训练时间较长;而较高的学习效率则可能会导致模型不收敛,损失函数值波动较大.因此设定4 种分别为0.001,0.015,0.045,0.080 不同的学习效率对模型进行训练,对比结果如图6所示.
从图6可以看出,图6(a)中损失函数和准确率函数图像震动剧烈,准确率较低,损失函数值始终高于0.5,网络模型收敛情况较差;图6(b)中图像震动有些许减少,相较图6(c)、6(d)波动任较大.图6(c)、6(d)在迭代初期损失函数值较大,迭代后期收敛明显且图像震动幅度较小,适宜训练模型,对比图6(c)、6(d)对训练集的平均准确率和损失函数值,选择图6(c)学习效率0.045作为最终模型学习效率.
最后探究每次迭代样本批次大小(batch size)的选择,不同的批次大小会对网络模型的准确率和训练效率产生影响,选择过小的批次会导致准确率震荡较大,模型无法收敛;选择较大的批次会导致内存容量不足,参数更新缓慢,降低运行速度,徒增训练时间.实验选择批次大小为32、64、128 和256 等4 种不同批次大小作对比,得到结果如表1.
从表1得出,批次大小为32 和64 的模型在训练时间上与大批次模型相比有一定的优势,准确率与批次大小为128 的模型相比有略微差距,综合考虑选择批次大小为128 个样本导入网络模型完成训练.
4.2 实验结果
网络模型训练完成后对实时拍摄不同测试者手势样本进行预测,选取3 位测试者10 种不同手势各50 张共1500 张样本,收集手势识别预测结果,如表2所示,可知,本文利用迁移学习训练卷积神经网络模型对实时获取的静态手势识别准确率较理想,平均准确率达到96.3%,平均识别时间达到39.2 ms,在识别速度上基本满足实际应用需求.
4.3 方法对比与分析
将本文方法与传统的手势识别方法做对比,验证本文提出算法模型性能,对比结果如表3所示.
文献[2]中方法参数量大,计算速度慢导致模型识别速度慢效率低.文献[6]中方法对于手势区域在整体图像所占比例的干扰较大.文献[7]识别速度快,无法排除手指并拢的手势干扰,识别准确率较低.文献[8]中能排除一定噪声干扰,网络结构较简单泛化性能较差.本文方法在识别准确率突出,识别反馈速度较快,内因在于采用SVM 进行手势分割后得到的二值化样本纯净,特征利于网络学习,迁移学习方式构建的网络模型层数深,对特征的学习能力强,善于分类,在模型设计和参数训练的时间上相较传统卷积神经网络花费少,泛化性能强.
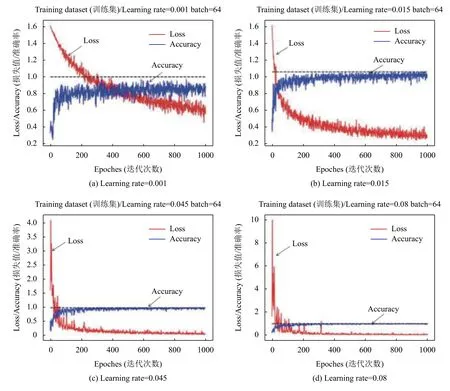
图6 学习效率对模型的影响
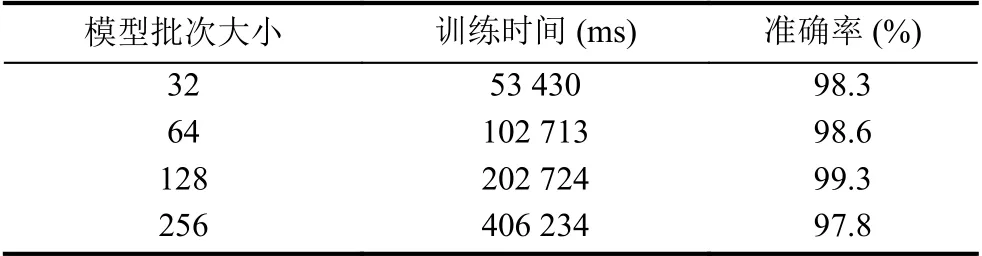
表1 不同批次大小模型训练结果
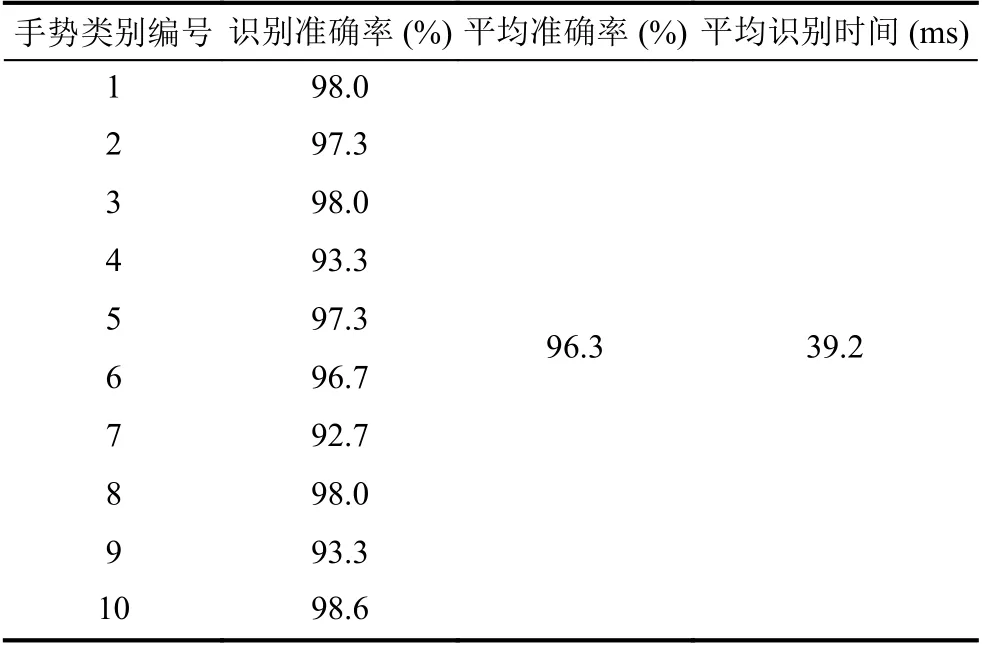
表2 测试结果

表3 各种手势识别算法对比
5 结论
本文方法将支持向量机和迁移学习相结合,利用SVM 进行手势分割取得的效果相比其他颜色空间手势分割方式的效果较好,具有较好的鲁棒性和灵活调整能力;利用迁移学习将已训练好的卷积神经网络作为基础,训练全连接层参数,需要的训练数据集较少,大量缩减卷积神经网络构建和网络的训练时间,取得96.3%的平均识别准确率和39.2 ms 的平均识别反馈时间,基本能满足实际应用需求.
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
文学港(2021年12期)2021-02-28
健康体检与管理(2021年10期)2021-01-03
好孩子画报(2020年3期)2020-05-14
小天使·四年级语数英综合(2019年9期)2019-11-09
红领巾·萌芽(2019年9期)2019-10-09
小学阅读指南·低年级版(2017年6期)2017-06-12
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
