
基于多粒度视频信息和注意力机制的视频场景识别①
2020-05-22 04:48袁韶祖王雷全吴春雷
计算机系统应用 2020年5期
袁韶祖,王雷全,吴春雷
(中国石油大学(华东)计算机科学与技术学院,青岛 266580)
1 引言
近年来,随着深度学习技术的发展,大量针对物体、人脸、动作等维度的识别技术涌现出来.而随着监控技术和短视频APP 的广泛应用,视频场景识别已成为一项极具科研价值和应用价值的技术.它的具体任务是给定一个特定的视频进行镜头分割,通过提取关键帧,输出场景的类别.目前主流的算法是使用视频级别的特征直接进行场景分类.然而这种方法只考虑到了视频级的全局特征,却忽略了富含更多信息的局部特征以及其中存在的关联.针对以上问题,本文提出了一种新的模型,该模型利用视频级别的全局信息和物体级别的局部信息,提供更加丰富的推断信息.同时,本文采用了注意力机制来筛选对于视频场景识别重要程度高的特征,这一过程既增强了全局信息和局部信息的关联,同时也实现了对于特征的降维,有效地加速了模型的收敛.与官方开源的模型相比,本文提出的模型在准确率上取得了非常大的提升,这进一步说明了该模型的有效性.
本文中,创新点可以总结归纳为如下3 点:
1)本文在视频场景分类中构造了全局和局部的多粒度的特征.
2)本文提出全新的注意力机制的场景分类模型,该模型可以很好的通过注意力机制将两种粒度的特征融合,并对结果进行降维.
3)新模型准确率比官方发布的基于CNN 网络的模型提高了12.42%,这进一步证明我们的模型的有效性和优越性.
2 相关工作
2.1 视频级特征和物体级特征
特征在计算机视觉领域中扮演着重要的角色,选择合适的特征可以极大的提升模型的性能.早期视频特征主要使用VGG 特征,该模型由Simonyan K 等提出,也大量应用在图像识别领域.后来何凯明通过残差的思想实现了101 层的CNN 模型,得到了拟合更强的网络[1].Resnet 作为特征提取网络被广泛应用于视频识别和图像描述等领域[2].Jiang YG 等使用resnet 作为视频级特征实现了视频场景分类的基础模型[3].使用Resnet 提取的视频级特征也被称作RGB 特征.然而视频帧之间是存在时空关系的,采用RGB 特征无法表征出这种时序关系[4].为了解决这一问题,Tran D 等提出了空间卷积(C3D)的网络来获取时空的信息[5].Sun DQ 等提出利用帧之间的差异性计算时空信息的“光流法”[6].这两种跨时空特征被广泛的应用于视频是被,动作识别等领域[7].以上特征都可以被视作视频级别的特征,未从更细的粒度考虑视频内部的语义特征联系.Ren SQ 等认为,细粒度的特征有利于增强模型对于视觉信息的理解,为了得到这种信息,他们在较大的视觉检测数据集上训了Faster-RCNN[8]用于识别目标图像中的物体,同时提出检测模型标识每个物体的中间特征,并将所有特征级联起来作为图像的总体特征[9].该模型首次提出后被应用于图像描述和图像问答领域,并取得了不错的成绩.我们认为,该特征同样可以应用于视频理解领域.
2.2 注意力机制
注意力机制在深度学习领域有着极为重要和深远的影响,被广泛应用各个领域中.在机器翻译领域,早期的Encode-Decoder 模型不能很好的解码源语言中的重点信息,为了解决这一问题,Bahdanau 等将注意力机制最早应用于机器翻译的解码阶段[10].受到这种思维的启发,Xu K 等意识到图像领域也存在需要重点关注的区域,于是他们将注意力机制引入到图像描述中来,并创造性的提出了两种注意力机制:软注意力和基于强化学习的硬注意力[11].在这之后注意力机制在各个领域大放异彩,陆续出现了很多新式的注意力机制.在图像描述领域,Lu JS 等提出了when to look 注意力,去决定在图像描述过程中应该注意图像还是注意文本[12].在图像问答中,Lu JS 等 提出公用注意力机制,从理论层面将注意力矩阵逆置之后用于两种模态[13],Kim JH 提出双线性注意力[14],相当于给注意力矩阵降维,但是最终的结果不变,两种注意力都可以降低运算复杂度,有利于采用更深的注意力网络,从而提升效果.在对抗生成领域,Kim J 将注意力机制引入到了生成对抗网络,通过网络自适用的决定应该更注重哪一区域的生成,用来生成更高质量的图[15].即便是在最新谷歌提出的Transfromer 和Bert 中,也采用了自注意力机制,用来解决自然语言中超远距离词的依赖问题,该模型在自然语言界引起了极大轰动[16].由于注意力机制在人工智能领域的出色表现,因此在实验中也会用注意力机制来提升本文所提出模型的能力.
3 视频场景识别方法模块介绍
3.1 基于Resnet 和Faster-RCNN 的多粒度特征构造
Resnet 是深度卷积神经网络的一种,它在原有的较浅层次的卷积神经网络的基础上添加了“残差”机制,因此再反向传播的过程中可以保证导数不为0,从而避免了深层网络出现梯度弥散的现象,有效的增加了卷积的拟合性.Resnet 的残差过程可由式(1)表示:

其中,x是输入的特征图,F代表卷积,W是用来调整x的channel 维度的,y是当前残差的输出.
由于Resnet 的输出可以作为对图片信息的一个较强的表征,本文采用这种特征作为视频场景的一个全局表示,即粗粒度特征.
Faster-RCNN 是一种比较新且准确率较高的检测模型,其原理和SPPnet[6]和Fast-RCNN[17]这些模型有很大差别,这些模型虽然减少了检测网络运行的时间,但是计算区域建议依然耗时依然比较大.Faster-RCNN采用了区域建议网络(region proposal network)用来提取检测物体的区域,它和整个检测网络共享全图的卷积特征,极大的降低区域建议网络所花时间,从而提升了检测的效率和质量.
在本文中,Faster-RCNN 作为检测器标识出视频图片中的物体信息,每一个物体区域分别作为改物体的特征表示,这种检测得到的特征作为细粒度的特征表示.
3.2 多粒度特征的注意力融合模型
图1是本文所提出的场景识别模型,这里所采用的的注意力机制是一种典型的注意力架构[10],并在此基础上设计了多粒度特征的注意力融合模型.在3.1 中检测模型Faster-RCNN 提取提取到的检测特征S是一个n×D维的向量,即对应于n个不同物体的子区域,每个区域都是一个D维的向量,可由如下字母表示:
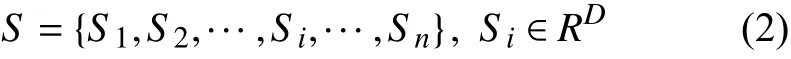
其中,RD表示属于D维度,Si表示第i个物体的图像区域.对于每个物体的特征表示,式(3)中本文借鉴注意力分配函数 ∅[18]根据细粒度检测特征Si和全局特征Ii生成一个权重分布αi:
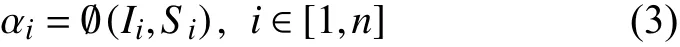
这里的分配函数是一种映射关系,它将两种粒度的视觉信息通过单层神经元映射到同一个维度空间,再相加得到权重,这个权重分布就包含了两种粒度特征的融合信息.同时,该权重分布和Si的维度是一致的,通过后续的加权操作,既实现了对于多个物体特征的降维,又得到两种信息融合的一个强表征信息.
在(4)式中,Softmax 函数对权重分布αi作归一化处理得到注意力权重ai,这时ai介于0 到1 之间:
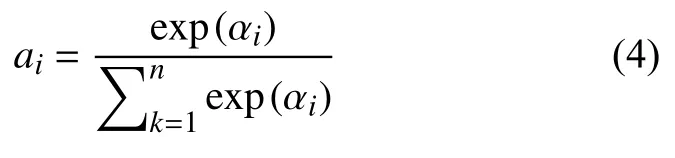
其中,ai表示视觉注意力模型中第i个物体的图像对应区域的权重.
最后,将注意力权重和相对应的视频图像区域加权求和,得到该视频场景的最终表示att,如式(5)表示:

式中,Si为视频图像的区域,αi为式(4)中attention学习得到的权重,这个权重是神经网络根据当前输入视觉信息自动生成的.

图1 我们的模型架构
3.3 新模型整体架构
在视频场景识别中,首先将给定的视频切割成一个视频帧序列Ti(i=1,2,···,m),模型要对这m个特定视频帧进行场景分类的pi(i=1,2,···,m).接下来两种特征的提取:我们使用深度卷积神经网络Resnet 提取视频帧全局的视觉特征Ii(i=1,2,···,m),这同时也是即将进行场景分类的帧的粗粒度的表示,该表示是一个D(2048)维的向量;同样的,通过预训练的Faster-RCNN 提取视频场景中的物体区域,也就是检测特征,该特征是物体级别的细粒度信息,可以表示为S={S1,S2,···,SN},其中n代表检测模型提取的物体区域个数,实践中n被设置为36.这个过程可用下面两个公式表示:

为了示意方便,这里f代表深度卷积网络Resnet,g代表检测网络Faster-RCNN.
得到多粒度的视觉特征后,新模型使用全局特征作为注意力机制的键值,通过注意力单元的计算得到n个注意力权重α.这里的权重α是由注意力模型根据不同物体重要程度学习得到的:物体重要程度越大,其权重值约接近于1;如果物体对于场景推断越不重要要甚至起到干扰作用,其权重越接近于0.最后通过物体特征和注意力机制生成的权重加权计算得到融合多粒度信息表示的视觉特征att,这同时也实现了对于细粒度特征的降维,即从n×D维降维成D,所以att是一个D维的向量.这部分流程图如图1所示,可以由式(8)、式(9)概括:
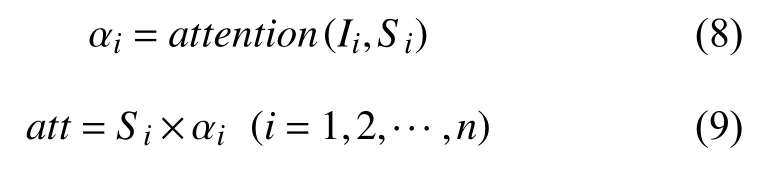
最终,融合多粒度信息表示的视觉特征被输入到一个分类器中.该分类器由一个两层的神经网络,和一个激活函数构成,它的作用是将D维表示向量映射为d,d代表了场景分类的总数,选取其中值对应的最大的索引,该索引所对应的场景表示就是最后输出的场景分类的结果.分类器部分可以用式(6),式(7)表示:
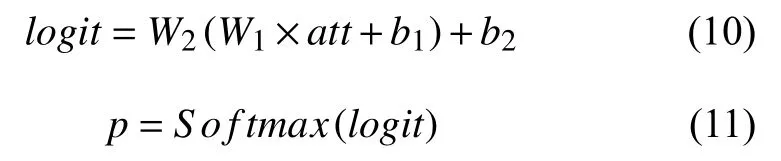
式中,W1,W2代表两层神经网络的可学习权重,logit是未经过激活函数的值,p为最终的分类概率,概率最大的索引所对应的场景即为神经网络的输出结果.
3.4 总结
和已有的方法[3]相比,本文摒除了只采用单维度的CNN 特征或者将几种CNN 特征简单连接的方法.本模型通过已有的深度卷积和检测的方法构建了两种不同粒度的特征.特别的,本文采用注意架构将两种粒度的信息巧妙融合在了一起,既实现了对信息的降维,同时增强了全局信息和局部信息的关联.
4 实验
4.1 数据集和评估方法
本文采用了在ChinaMM 大会上极链科技与复旦大学联合推出全新视频数据集VideoNet.该数据集具备规模大、维度多、标注细三大特点.VideoNet 包含近9 万段视频,总时长达4000 余小时.VideoNet 数据集对视频进行了事件分类标注,并针对每个镜头的关键帧进行了场景和物体两个维度的共同标注.考虑到算力等因素,该实验从中抽取了100 000 个视频样本的镜头分割和关键帧结果,推断每个镜头的关键帧对应的场景类别.为了保证模型的训练和测试效果,本实验按照6:2:2 的比例切随机分数据集,即使用60 000 数据训练,20 000 用于验证,20 000 用于测试.
4.2 评估方法
模型的目标是对给定的测试视频样本和镜头关键帧结果,推断每个镜头的关键帧对应的场景类别.因此可以通过以下公式判读模型是否分类正确:
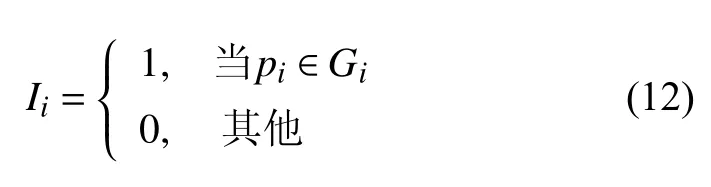
其中,G为关键帧场景类别的ground-truth,pi为场景预测输出.如果该关键帧未出现训练集中任何一类场景,则Gi=–1.因此,准确率公式可以定义为:
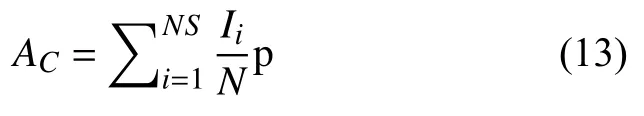
训练过程中该模型使用了交叉熵[19]作为损失,因此也可以通过交叉熵损失的变化判断模型的优化程度和模型训练是否收敛.损失函数可用公式表示为:
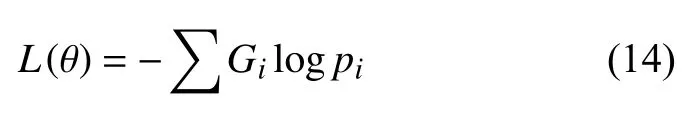
4.3 实验分析
本文采用了准确率和log 损失来评测模型的质量和训练情况.在图2中,我们绘制了测试损失和迭代次数的相关折线图,不难看出本文提出的方法可以快速的收敛,loss 值在训练的过程中稳定的下降,最终迭代次数为20 时得到最好的效果.结合图3的准确率曲线,通过观察可以看出随着训练损失的下降,模型的测试准确率也在不断提升,最高可以达到67.71%.由于模型训练了25 个迭代,通过图3表所示,在超过20 个迭代次数的时候,模型的测试准确率会有小幅度的下降,说明模型出现了过拟合现象.在表1中,我们列举了模型迭代次数19 到迭代次数25 之间的准确率,通过对比发现,迭代次数为23 的时候模型得到最好的效果,准确率为67.71%.
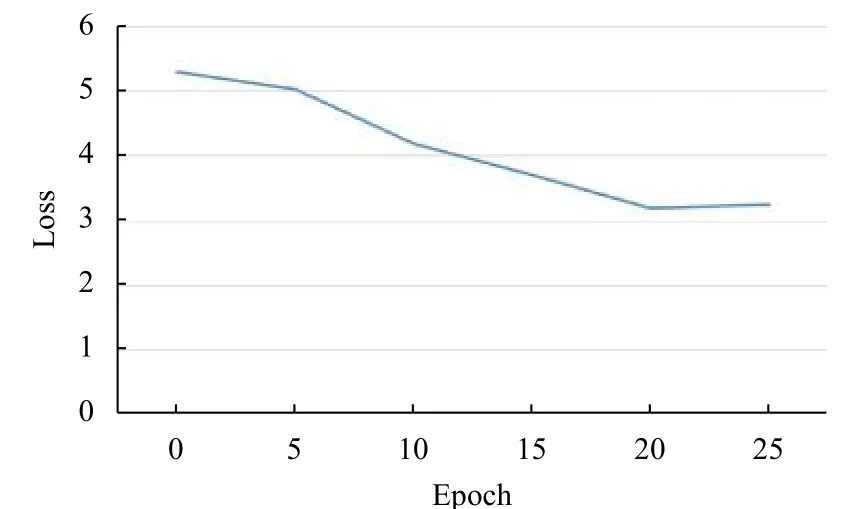
图2 交叉熵损失变化
通过表1,可以看出,本文提出的模型准确率大幅度优于VideoNet 官方开源的Baseline 模型.与我们提出模型训练取得的最好的效果相比,新模型准确率比官方baseline 提升了12.42%.这些数据证明:本文提出的模型可以在较少的训练迭代次数下收敛.基于多粒度视觉特征和注意力机制的模型有效的提升了视频场景识别的质量.相比于传统的使用C3D 特征等方法,多粒度视觉信息可以大幅度提升识别的准确率,因为不同粒度的信息不但补充了更加丰富的识别信息,同时还使用注意力机制将不同粒度的信息联系在一起,更加充分的利用了信息.
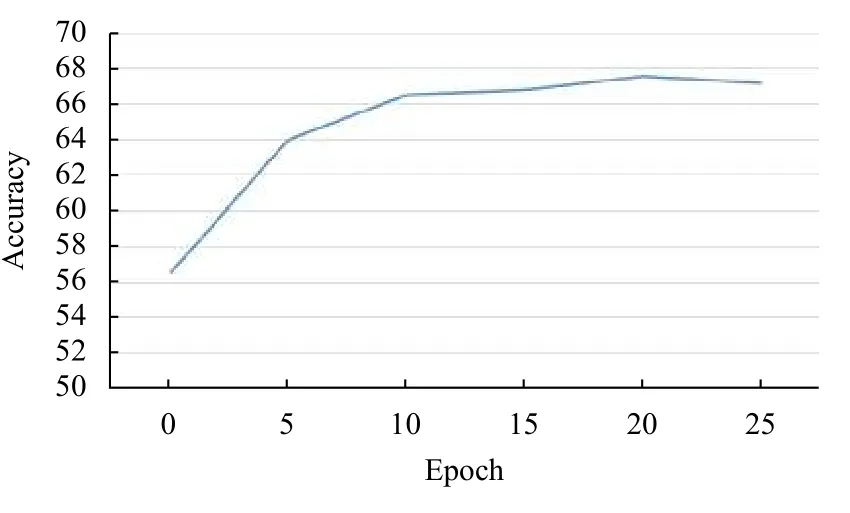
图3 准确率损失变化

表1 模型的准确率对比(%)
5 结论与展望
本文提出了使用多粒度视频特征信息基于注意力架构的视频场景检测模型,并在VideoNet 数据集上取得优异的成绩.该算法的亮点在于使用全局性的信息引导下,通过注意力机制自适应的对场景中重要的局部信息加权,从而达到更加精准的识别效果.和官方开源的模型基线相比,本文考虑了全局特征和局部特征,很好的利用了多个粒度视频信息.并且在模型中采用了注意力模型,既完成了对特征的降维,又能很好的将多个粒度的信息联系起来.在未来的工作中,我们将进一步探索多维度的视频信息和不同注意力机构对于场景识别的影响.
猜你喜欢
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
小型微型计算机系统(2020年10期)2020-10-21
新作文·高中版(2017年6期)2017-07-06
第二课堂(课外活动版)(2016年2期)2016-10-21
科技与企业(2015年12期)2015-10-21
