
基于迭代训练和集成学习的图像分类方法
2020-05-22 12:32罗会兰
计算机工程与设计 2020年5期
罗会兰,易 慧
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
传统的图像分类算法首先对图像进行特征提取,然后将获取到的特征描述符来充分描述图像的完整信息。即将原始图像包含的一些特定信息充分提取,进而用来表示图像的结构化特征数据,然后将图像的结构化特征数据传输到可进行网络模型训练的分类器,最终得到图像分类结果。该方法得到的图像分类准确度取决于手工提取特征的充分性。
卷积神经网络主要由若干层不同尺寸大小的卷积层和池化层组成,前一卷积层的输出特征图作为后一卷积层的输入。其中卷积层主要由一个大小固定的卷积核与输入进行卷积运算,正好对应模拟了生物视觉系统中的简单细胞,而池化层则是一种下采样操作,用来扩大感受野(receptive fields),并且获得一定的不变性,例如旋转不变性,尺度不变性。若干卷积层和池化层的组合,其功能相当于一个特征提取器;随后的若干层由全连接层构成,其作用相当于一个分类器。一般情况下,特征信息提取越完整,越能有效改善分类精度,但是没有区分度的特征信息通常会对分类结果产生不好的影响。在当前图像数据集庞大的情况下,随着卷积神经网络模型深度的不断加深,宽度不断加宽,这种特征算法耗费大量人力物力,并且效率低下。
为了解决图像特征信息提取不完整的问题,本文将迭代训练卷积神经网络模型和集成学习分类器两者相结合,提出一种使用迭代训练卷积神经网络模型和集成学习相结合的图像分类算法,旨在提升图像分类精度,使卷积神经网络模型训练效率更高。通过构建三流卷积神经网络模型,然后对3个网络流采用迭代训练的方式训练卷积神经网络,这样便可以提取到完整的能够描述图像的特征信息。最后采用集成学习的思想,根据各网络流基分类器的表现性能,赋予分类器不同权重,能力越强的分类器权重越大。
1 相关研究
卷积神经网络发展已经日趋完善,从近几年ImageNet竞赛图像分类中表现出色的队伍中我们不难发现,由于当前庞大的训练数据和多并行GPU加速运算效率带来的便利,当前该领域已经采取了多种不同的方法来提高图像分类精度。例如,Zhang等[6]提出了一个Maxout Network模型,相当于卷积神经网络的激活函数层,替换了之前卷积神经网络模型常用的Sigmod,Relu,Tanh等函数,但又不同于这些激活函数,它是一个可学习的激活函数,网络中的参数都是可学习变化的,并且可以拟合任意的凸函数。因为Maxout是一个分段线性函数,然而任意一个凸函数都可由线性分段函数以任意精度进行拟合,即可以拟合上述3种常用的激活函数。但是这种方法的不足之处在于新的激活函数的提出会导致网络参数个数比原始网络参数成倍的增加,在数据量较大的情况下,会对网络模型带来巨大负荷,造成“维数灾难”[7]。因此这种方法并不适合数据集较大的情况。
而针对数据量少或包含罕见类的数据集的分类问题,将先验知识添加到决策树的结构中,同时将这些先验知识应用于网络模型的最后一层网络层,根据加入的先验知识得出的图像分类性能差异模型,将得到的图像分类性能较强的网络模型赋予较大的权重,可以改善深度卷积神经网络的性能。Lin等[8]提出的NIN网络模型,将多个感知卷积层替换了传统的卷积层,以此来提升网络泛化能力和增强抽象特征信息的提取能力;同时利用全局平均池化层替换了网络模型中的全连接层,并且最后加上Softmax层用作分类。Xiao等[9]提出将先验知识添加到决策树的结构中,同时将这些先验知识应用于网络模型的最后一层网络层,根据加入的先验知识得出的图像分类性能差异模型,将得到的图像分类性能较强的网络模型赋予较大的权重,最后运用类继承的图像分类方法来达到相同类别间的图像特征信息共享。这种方法从一定程度上扩充了训练的数据集,并且能够解决图像数据样本量不足的问题以及罕见图像类别数据集的分类问题。Lee等[10]利用了一个先验经验,如果能够让图像特征具有区分性,则分类性能就会比较优越。文中在卷积神经网络的基础上对隐藏层进行监督学习。即对卷积神经网络的隐藏层采用Squared Hinge Loss,使得卷积神经网络的隐藏层具有区分性。但是文中并没有对这种先验经验方法是否真实有效进行验证说明。Agostinelli等[11]提出了一个自适应分段线性激活函数,每个神经元能够使用梯度下降算法独立学习。Yan等[12]通过将深度卷积神经网络模型添加到具有两级分类层次的卷积神经网络结构中,以此进一步加深卷积神经网络的网络层深度。通过粗略调节网络参数和加载预训练模型来微调网络参数相结合的方法,并以此改善网络性能。Murthy等[13]通过运用决策树理论和将不同类型的图像样本划分成多个区域子块的方法构建了深度决策网络,达到不同类别样本分区域分别聚类的目的。上述这些方法均是从网络模型结构,激活函数,以及将传统机器学习与深度学习结合的几个方面进行模型的改进创新,并且取得了性能的改进。
2 卷积神经网络迭代训练和集成学习用于图像分类
2.1 网络结构
卷积神经网络是一个由卷积层与降采样层交替出现的多层神经网络,每个网络层由多个二维特征平面组成。CNN首先通过反向传播算法 (backpropagation algorithm,BP)来预测输入图像的分类结果,然后将实际得到的正确图像标签和预测的正确图像标签进行比较,以此得到分类误差,最后利用梯度下降算法将网络权值更新。卷积层是模型的重要网络层,而特征提取则是计算机视觉任务中至关重要的问题。以CaffeNet网络模型为例,本文的网络模型结构如图1所示,主要由特征提取部分,分类器和融合分类器3部分组成。其中图1中只画出了3个子网络流所对应的分类器。在训练分类器阶段,本文利用集成学习训练了多个分类器,鉴于文章篇幅大小有限,图1中只画出了其中3个。网络框架中的3个子网络S1,S2和S3均可以设计成NIN[8],ResNet[14],VGGNet[15]等其它常用的卷积神经网络模型。
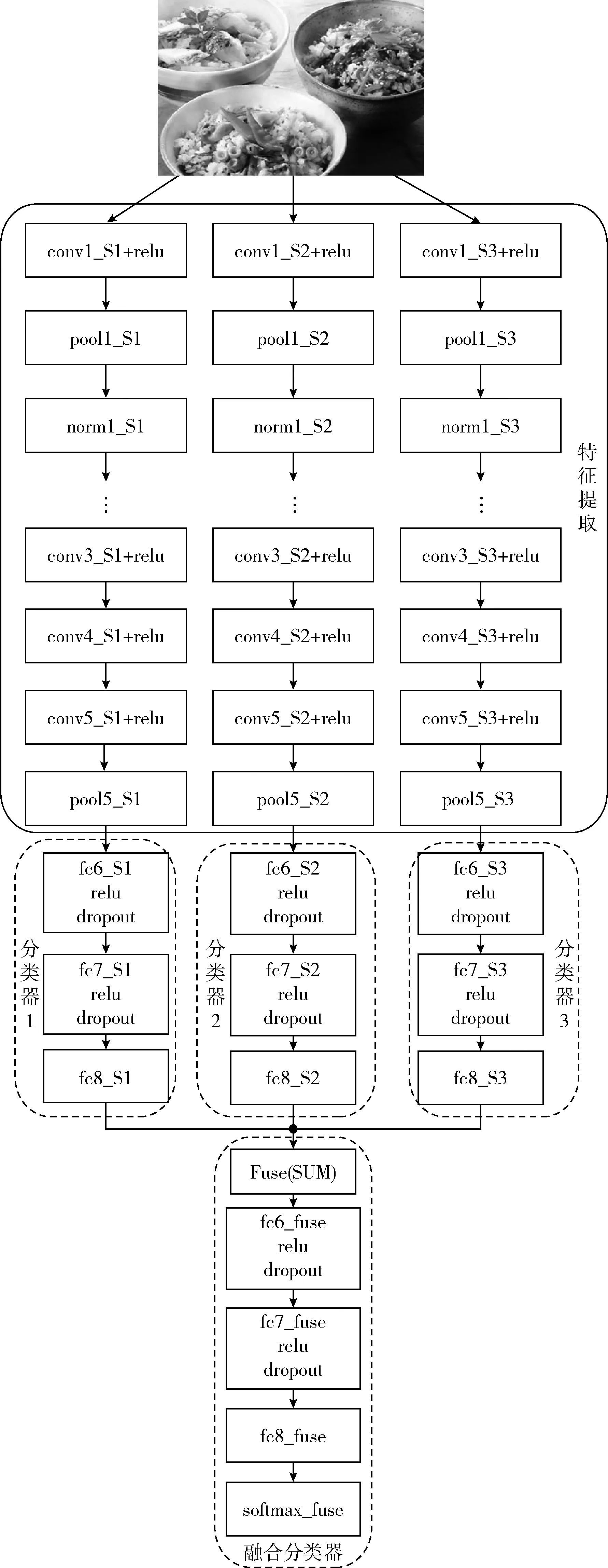
图1 网络结构
2.2 迭代训练特征提取方法
对网络模型进行迭代训练,主要是对网络框架中的3个子网络S1,S2和S3之间,固定其中两个子网络的模型参数,以迭代训练的方式微调另外一个子网络。一方面,这样做主要是考虑到GPU内存限制和减少网络模型过拟合的问题。另一方面,相对于另外两个特征提取部分,这样提取到的图像特征更详细丰富且具有区分性。Hou等[16]提出了一种新颖高效率的卷积神经网络模型训练方法——迭代交替训练。这种训练方法主要以单个卷积神经网络模型为基础,从网络框架的形式上构建一个孪生卷积神经网络模型;然后分别对两个具有相同网络参数的网络模型进行训练,迭代训练多次后,最后微调迭代训练成功的孪生网络(即识别率较高的网络模型),以此来得到两个具有相同网络结构模型的互补特征,提升分类准确率。本文受到此文献迭代交替训练方法的启发,文中的3个子网络也采用这种迭代交替训练的方法来充分提取不同类别图像的具有区分性质的图像特征,从而提升网络模型的分类准确率。
在单个卷积神经网络模型中,首先对单个卷积神经网络模型进行训练,根据单个卷积神经网络模型的分类性能表征的强弱,持续对表征分类性能良好的卷积神经网络模型进行迭代交替训练。在训练过程中,由单流网络变成孪生双流网络,通过训练双流网络得到的互为补充的图像特征信息实现图像充分有效的提取。本文的方法以迭代交替训练双流网络结构为基础,在首迭代训练双流卷积神经网络模型的时候,三流结构的子网络S1的网络参数设定为初始参数(即对应最原始的卷积神经网络模型参数),只训练三流网络结构的子网络S2和S3,此时的损失函数为
Loss1=λs2loss_S2+λs3loss_S3
(1)
然后在第二次迭代的时候,固定S2,训练子网络S1和S3,此时的损失函数为
Loss2=λs1loss_S1+λs3loss_S3
(2)
最后在第三次迭代的时候,固定S3,训练子网络S1和S2,此时的损失函数为
D.若A是应用最广泛的金属,反应④用到A,反应②⑤均用到同一种气态非金属单质,实验室保存D溶液的方法是加入适量铁粉与稀盐酸
Loss3=λs1loss_S1+λs2loss_S2
(3)
3个子网络重复迭代交替多次训练,直到Loss1,Loss2和Loss3这3个损失函数的数值都趋于稳定,然后在以图像分类性能表征较强的3个子网络流S1,S2和S3网络为基础,对3个子网络流进行微调,此时的损失函数为
Loss3=λs1loss_S1+λs2loss_S2+λs3loss_S3
(4)
以上4个损失函数中的λ都参照文献[16]中的设置取0.3,其中loss_S1, loss_S2和 loss_S3用的都是softmax损失函数。
2.3 数据增强
在训练参数复杂的神经网络时,如果没有足够大的训练数据集,模型极有可能陷入过拟合的状态。为了解决网络模型过拟合的问题,同时增加足够的图像数据,更有效提取到图像中有区分度的特征,并且减少图像中特征数据的冗余,提高模型的分类精度。文中在图像预处理阶段,采用了数据增强的操作方法,一方面扩充了数据集,另一方面可以得到不同类别图像更丰富有效的图像特征。例如:将原始图像旋转一个小角度,添加随机噪声,带弹性的形变和截取原始图像的一部分等方法。
图像增强的具体操作为:图像平移,目的是让网络模型学习到图像的平移不变性;图像旋转,旨在让网络模型学习图像的旋转不变性特征;并且调节图像不同亮度和对比度,可以得到不同光照条件下图像的不同特征。
2.4 集成学习的分类器融合方法
集成学习(ensemble learning)在计算机视觉领域应用较为广泛。近年来该方法是各个领域的研究重点,并且该方法在图像识别领域对图像分类精度的提升有着很大的潜力,具有其独特的优势。
集成学习的主要思想是将不同分类器进行集合,根据各分类器的表征性能进行合理选择并且重组,旨在获得比单个表征性能最好的分类器还要优秀的分类精度[17]。在图像分类问题上,单个分类器的性能表现出来的随机性较大,并且不稳定。但是通过引入集成学习的思想,某一个网络模型在学习某些图像特征方面,能够得到良好的结果。因此,选取训练得到的表征性能较强的不同网络模型集成,得到的网络模型泛化能力更强,在不同的情况下均能得到一个良好的分类结果。
本文在经过多次迭代训练后,得到多个分类器,本文中集成学习分类器的示意图,如图2所示。
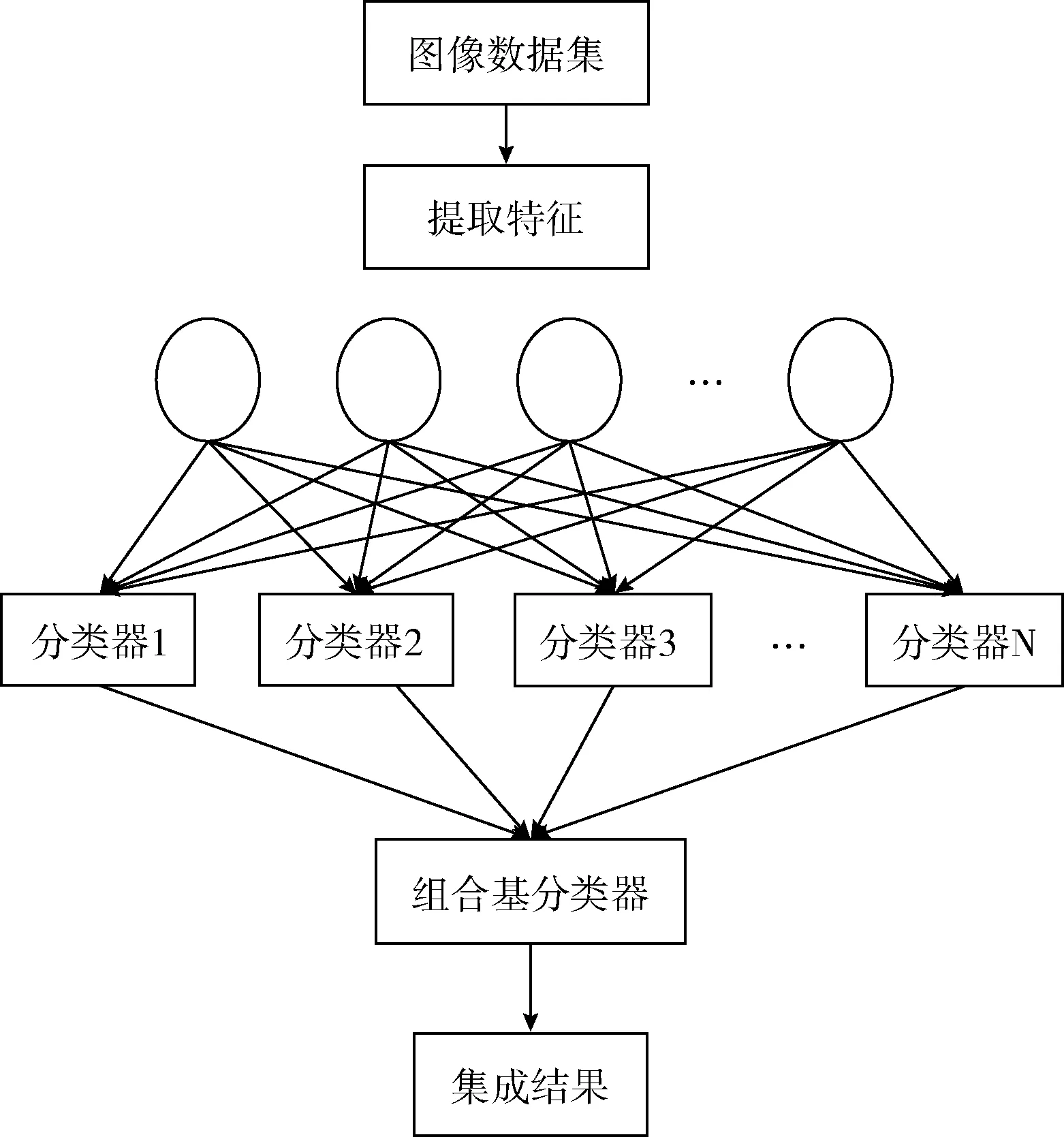
图2 分类器融合结构
如图2 所示,采用文献[18]中的直接平均法对分类器进行多网络模型集成训练,直接平均法通过对不同模型产生的类别置信度求平均值而得到最终的分类结果。假设共有N个模型待集成,对测试样本D,其测试结果为N个C维(C为数据的标记空间大小)向量q1,q2,…,qN。 直接平均法对应的公式如下
(5)
对于加权平均法中网络层权值大小的设定,根据不同网络模型在训练集上单独表征的图像分类性能来确定。因此图像分类性能准确率较高的网络模型权值较大,图像分类性能准确率低的网络模型的权值较小。
3 实验与分析
3.1 实验设置
为了测试该网络模型的有效性和泛化性能,选取了CaffeNet[19],VGGNet[15],NIN[8]和ResNet[14]这4个常用的网络模型,分别在CIFAR-100[20],Stanford Dogs[21]和UEC FOOD-100[22]这3个广泛使用的数据集上进行实验测试。
本文进行实验操作的硬件配置为:CPU为Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz,内存512GB,4块16GB的NVIDIA Tesla P100-PCIE,系统类型为64位Win10操作系统。本文实验结果采用平均精度均值(mean average precision,mAP)[23]来评价卷积神经网络性能的表现差异。mAP算法不仅考虑了图像分类的召回率,而且考虑了图像分类性能好坏的排名分布情况,可以较为全面地反应网络性能。
3.2 实验数据集
CIFAR-100数据集由60 000张彩色图像组成,包括100种不同的图像类别,其中每个图像类别分别有6000张图像,图像像素尺寸大小为32×32。在本文实验中,随机的选取50 000(即每类100张图像)张图像用来作为训练数据集,剩下的10 000张图像作为测试数据集使用。
Stanford Dogs数据集是一个主要用于图像细粒度分类的数据集,合计20 580张图像,由120种不同品种的狗组成,每个品种的狗的图像数量为148张~252张。本文将该数据集划分为训练集和测试集两大类:12 000张图像用作训练集,8580张图像用作测试集[24]。
UEC FOOD-100数据集是一个主要用来识别不同种日本食品的数据集,合计14 461张图像。包含了100个不同食物类别,每个类的图像数目为101到729不等,本文将该数据集划分为训练集和测试集两大类:10 000张图像用作训练集,4461张图像用作测试集[25]。
3.3 实验结果
为了验证本文提出的基于卷积神经网络迭代训练和集成学习的图像分类方法具有良好的分类性能,本文在上述3个数据集上分别和前期不同研究者的实验结果进行了分类性能比较。
3.3.1 CIFAR-100数据集上分类性能对比
本文方法在CIFAR-100数据集上的实验结果见表1。表1中的基础网络NIN和ResNet-20的分类结果来源文献[16],其中,DNI和DNR分别是文献[16]中以NIN-3和ResNet-20为基础卷积神经网络模型搭建的双流卷积神经网络模型。从表1的实验结果可以观察到,本文的方法在NIN和ResNet-20两个网络模型上均取得了良好的性能。其中,在NIN网络模型上,本文的方法比文献[16]中的单个网络模型准确率提高了4.58%,比文献[16]中的双流NIN网络DNI准确率提高了1.73%。在ResNet-20网络模型上,本文的方法较文献[16]中单个网络模型提高了6.15%,比文献[16]中的双流网络DNR准确率提高了2.81%。并且,CIFAR-100数据集在本文提出的方法上均取得了较好的结果。实验结果表明,本文提出的三流卷积神经网络迭代训练和集成学习的算法能够充分完整地提取到图像的充分有效特征信息,使得图像分类性能有比较显著的提升。
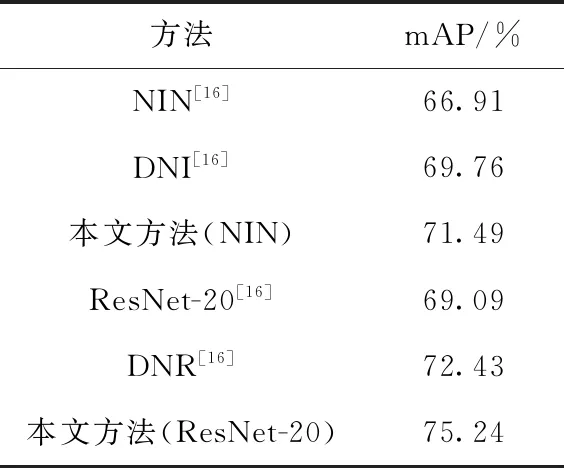
表1 CIFAR-100数据集上本文方法的mAP(%)比较
表2所示的是本文方法与当前一些主流方法[8,10-13,16]在CIFAR-100数据集上的分类性能的比较。其中文献[8]利用多层感知卷积层来替代传统卷积网络层,本文的方法较文献[8]中的方法提高了10.92%。文献[10]对卷积网络模型的隐藏层进一步运用监督学习的方法来获得充分有效的图像特征信息,实验结果得到的准确率为65.43%,本文的方法较文献[10]中的方法提高了9.81%。文献[11]提出了一个自适应分段线性激活函数,并利用该激活函数来替换卷积神经网络中的Softmax函数,进行图像特征提取。本文的方法较文献[11]中的方法提高了9.64%。文献[12]通过将卷积神经网络层数较多的深度CNN添加到两级类别层次结构中来获取图像充分有效的特征信息,使用粗类别图像分类器来得到图像特征信息简单的简单图像类别,精细类别分类器来获取图像特征多而复杂的图像类别,并且通过运用粗类别图像分类器与精细类别分类器相结合的方法,得到的图像分类准确率为67.38%,本文的方法较文献[12]中的方法提高了7.86%。文献[13]提出深度决策网络DDN,得到的图像分类准确率为68.35%,本文的方法较文献[13]中的方法提高了6.89%。本文方法在ResNet-20方法的图像分类准确率分别比文献[16]中的DNI,DNR提高了5.48%,2.81%。由表2实验结果可以看出,本文方法相较于当前一些数据集在不同卷积神经网络模型上的方法准确率均有一定提升,具有较好的分类性能。
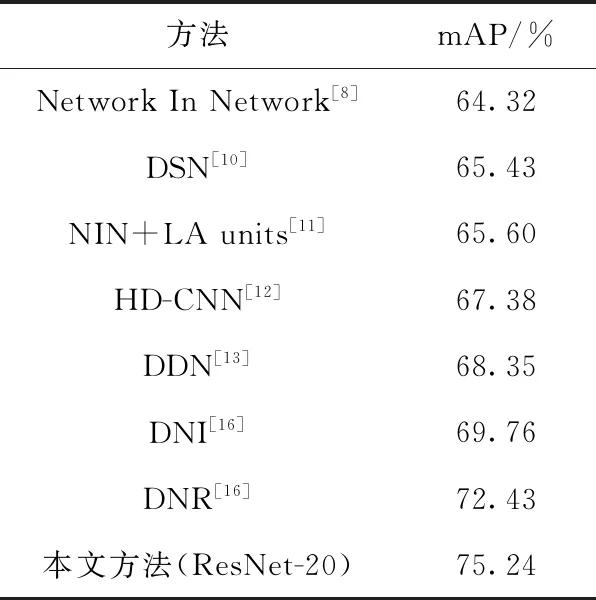
表2 各主流方法与本文方法的mAP(%)比较
3.3.2 Stanford Dogs数据集上分类性能对比
因为CIFAR-100(32×32)数据集比CaffeNet(227×227)和VGGNet(224×224)两个网络模型的输入尺寸要小很多,如果增大CIFAR-100中的图像尺寸,会导致图像模糊不清,在一定程度上给实验结果带来影响。所以,本文选择了另外一个数据集Stanford Dogs用来验证本文方法在CaffeNet和VGGNet网络模型上性能。表3中展示了Stanford Dogs数据集利用本文方法在CaffeNet和VGGNet两个网络上的实验结果。由表3的实验结果可以看出,在CaffeNet网络模型上,本文的方法均比文献[16]中的单个CaffeNet网络模型和双流网络模型DNC的分类精度要高,分别高了2.30%,1.20%。同时,在VGGNet网络模型上,本文的方法分别比文献[16]中的单个VGGNet高了5.76%,2.31%。实验结果表明,本文提出的方法比文献[16]中的双流卷积神经网络模型分类精度更高,具有较好的分类性能。
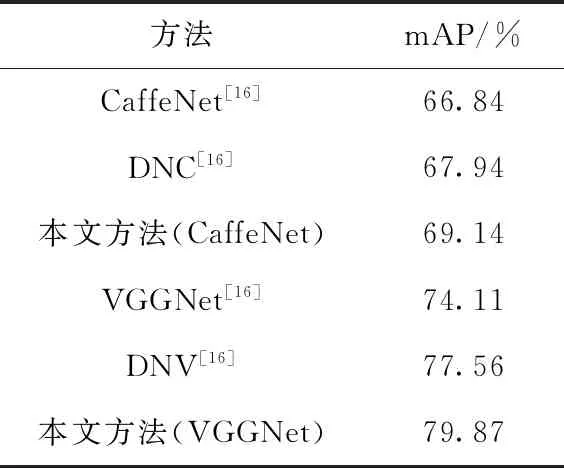
表3 Stanford Dogs数据集上的mAP(%)比较
3.3.3 UEC FOOD-100数据集上分类性能对比
表4中展示了UEC FOOD-100数据集利用本文方法在CaffeNet和VGGNet两个网络上的实验结果。由表4的实验结果可以看出,在CaffeNet网络模型上,本文的方法比文献[16]中双流网络模型DNC和双流网络模型DNV分类精度有较为明显的提升。其中,在CaffeNet网络模型上,本文方法分别比文献[16]中的单个CaffeNet网络模型和双流网络模型DNC分类精度高了3.12%,1.93%。在VGGNet网络模型上,本文方法分别比文献[16]中的单个VGGNet网络模型和双流网络模型DNV分类精度高了3.57%,1.78%。由此说明了本文提出的方法可以有效学习到图像的充分有效特征,使得图像分类精度提升较为显著。
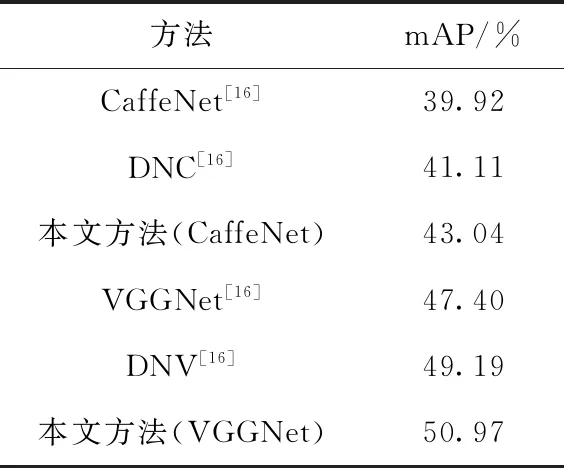
表4 UEC FOOD-100数据集上的mAP(%)比较
4 结束语
本文提出了一种基于卷积神经网络的迭代训练和集成学习的图像分类方法。该方法主要运用了迭代训练的方式,来训练3个子网络流。这种对卷积神经网络进行迭代训练的方式主要有两个优点:①训练时网络梯度回传的层数更少,所以梯度消失的问题更少;②具有更好的并行性,每一个子网络流可以进行单独训练,故可以获得更好的训练效率,并减少设备内存空间的限制。并且对图像数据预处理采用了数据增强的方式,这样不仅扩充了图像数据集,而且能有效减少网络模型过拟合。最后采用集成学习对分类器进行集成,得到分类结果。本文在Stanford Dogs,UEC FOOD-100和CIFAR-100数据集上的实验结果验证了本文提出的方法在图像分类中具有较好的性能。本文的良好性能主要是通过对3个子网络进行多次迭代训练获得的。在后续的工作中将探讨利用网络压缩模型来减少网络参数,同时在保证网络性能良好的基础上,提高模型训练效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
重型机械(2016年1期)2016-03-01
海军航空大学学报(2015年4期)2015-02-27
