
基于改进区域卷积神经网络的安全帽佩戴检测
2020-05-22 12:33徐守坤王雅如顾玉宛
计算机工程与设计 2020年5期
徐守坤,王雅如,顾玉宛
(常州大学 信息科学与工程学院,江苏 常州 213164)
0 引 言
安全帽佩戴检测早期研究主要是基于传统的机器学习方法,如Rubaiya等[1]提取头部区域霍夫变换特征输入SVM进行检测。这类方法要求针对不同的检测任务,研究设计出特定的适应性好的特征。近年来,深度学习方法广泛应用于各个领域,从图像分类[2]到目标检测[3]和语义分割[4]等。Vishnu等[5]分别使用两个不同的深度卷积神经网络分别检测工人和安全帽,方法过程复杂。
目前,在深度学习领域用于目标检测的主要有基于区域的目标检测和基于回归的目标检测。Fast RCNN[6]、Faster RCNN[7]和R-FCN[8]等属于区域目标检测,特点是高精度、低速度;YOLO[9]、SSD[10]等是采用回归的检测方法,这类算法检测精度较低。Faster RCNN使用RPN产生候选区域,完全实现了端到端的检测。所以,本文选取Faster RCNN作为安全帽佩戴检测的基础网络。但是,Faster RCNN直接应用于安全帽佩戴检测会出现网络训练过程中正负样本失衡和对小目标和遮挡目标检测效果不佳等问题。
因此,本文在Faster RCNN基础上引入在线困难样本挖掘[11]和多层卷积特征融合技术[12],解决了网络训练过程中负样本空间过大问题,提高了网络对小目标和遮挡目标特征敏感度。
1 安全帽佩戴检测
本文设计的安全帽佩戴检测系统的框架如图1所示。首先对收集的图片中佩戴安全帽人员进行信息标注,转换成VOC2007格式。然后将数据样本输入到CNN中进行特征提取。接着将卷积层的特征进行融合输入到RPN网络中提取候选区域。最后将候选区域特征图输入到嵌入OHEM机制的ROIs网络中挑选困难样本并进行目标分类和回归操作。
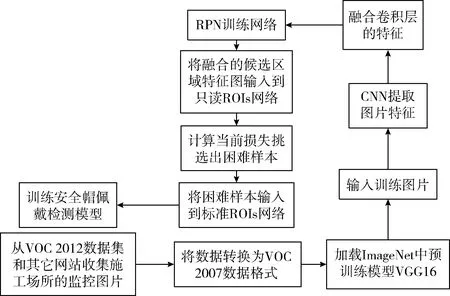
图1 安全帽佩戴检测系统整体框架
1.1 基Faster RCNN简介
Faster RCNN是Rens等提出的基于区域卷积神经网络的通用目标检测网络框架,在VOC2007数据集上的平均准确率(mean average precision,mAP)[13]达到了73%。Faster RCNN网络主要包含生成候选区域的区域建议网络(region proposal network,RPN)和进行分类回归的Fast RCNN网络。
RPN是以原始图像提取的卷积特征图作为输入,输出一系列目标候选框,它的结构如图2所示。RPN利用滑动窗口机制,每滑动一次产生一个特征向量,特征向量输入到全连接层中用于判断目标的位置和类别,每个滑动窗口可预测多个候选区域。滑动窗口映射的低维的短向量,输入到两个并行的全连接层中,一个网络层输出所属类别和概率,另一个网络层输出候选框位置的坐标回归值。

图2 RPN网络
RPN训练过程中,每个候选框都有一个二值标签,与某个真实目标区域框的IoU(intersection-over-union)大于0.7的是正标签,小于0.3的候选框是负标签。图像的损失函数定义如式(1)所示[7],定义(1)~定义(3)请参考文献[7]

(1)

分类的损失函数Lcls定义如下
(2)
回归的损失函数Lreg定义如下
(3)
其中,R是smoothL1函数,smoothL1函数如式(4)所示
(4)
Faster RCNN将原始图片和RPN产生的对应目标候选区域框作为Fast RCNN的输入来检测佩戴安全帽人员。在进行Faster RCNN网络训练时,将标注有佩戴安全帽人员等相关信息的数据集作为输入,通过卷积池化等操作获得感兴趣区域的特征向量,然后输入到Softmax和目标框回归中,产生所属类别概率和区域坐标。
1.2 改进的Faster RCNN
Faster RCNN网络在训练阶段,由于训练数据集中佩戴安全帽人员占整张图片区域比例可能较小,造成RPN产生的候选区域前景和背景比例失衡,且存在较多无效的候选区域,不利于网络参数的更新。在检测阶段,会受到佩戴安全帽人员目标尺度的影响,对小目标和遮挡的目标检测效果不佳。因此,本文在Faster RCNN算法基础上引入多层卷积特征融合技术和在线困难样本挖掘策略。改进后的Faster RCNN网络框架如图3所示。

图3 改进的Faster RCNN框架
1.2.1 多层卷积特征融合
Faster RCNN在进行网络训练时主要包含两个步骤:RPN产生目标候选区域和候选区域的分类回归。其中,RPN产生的候选区域质量对后续网络进行目标检测至关重要。RPN使用特征提取网络最后一层的特征图作为输入,对特征图进行池化,产生固定大小的特征图,送入后续网络中进行分类回归操作,通常对小目标检测效果不佳。这是因为进行ROI池化操作的时候只有一个层级的特征图,例如,VGG-16模型从“conv5”层进行ROI池化,该层的步长为16,当目标尺寸小于16像素时,即使候选区域是正确的,在conv5层中投影的ROI池化区域也小于1像素。因此,基于一个像素的信息,分类器很难预测目标类别和区域位置。而且随着卷积层变深,相应特征图中的每个像素在候选区域外收集越来越多的卷积信息。因此,如果ROI非常小,提取到的ROI区域之外信息占较高比例。所以,仅使用最后一个卷积层的特征图并不适用于区域面积较小的ROI。
卷积神经网络中深层特征具有较强的语义特征,感受野也较大,是一种全局信息。浅层特征拥有更强的像素细节信息,是一种局部信息。本文将多层卷积特征融合技术引入Faster RCNN中,将浅层和深层的卷积特征进行融合,使得产生的候选区域特征同时具备像素信息和语义信息。具体实现过程如图4所示。首先,将RPN产生的候选区域同时映射到conv3层、conv4层和conv5层,得到位于这3层的区域特征图。然后,将3个层级的特征图分别进行L2正则化并送入后续网络中实现安全帽佩戴检测和位置回归。
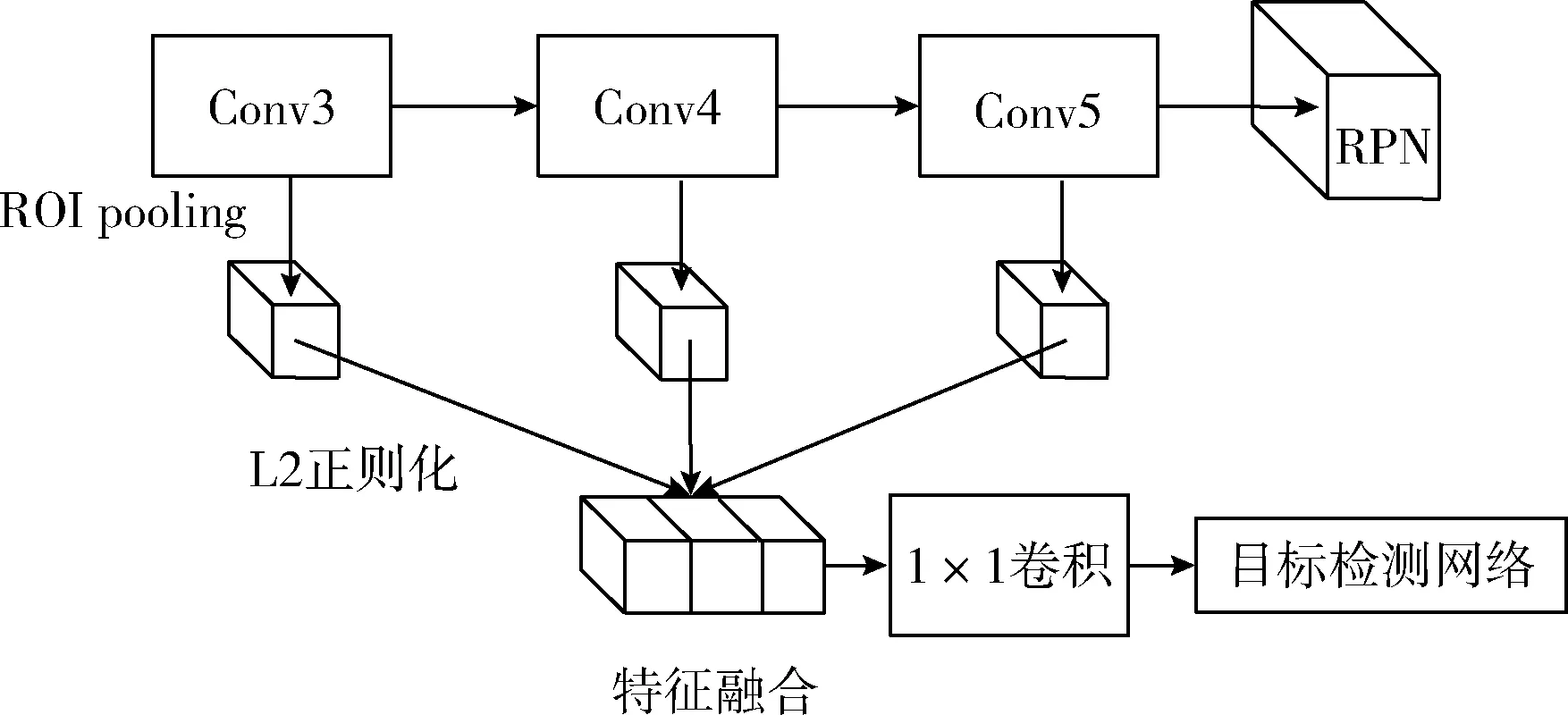
图4 特征融合
为了在多个尺度上扩展目标区域的深度特征,需要在ROI池化之后组合3个特征。实际上,每一层特征图通道数和特征映射像素的范数通常是不同的。所以,不能直接地连接3层ROI池化张量,因为特征图规模差异对于以下层中的权重来说太大而无法重新调整和微调。因此,本文在特征连接之前对每个ROI池张量使用L2正则化。
1.2.2 在线困难样本挖掘策略
Faster RCNN在训练过程中RPN会产生一系列目标候选区域,这些候选区域会存在正负样本不均衡问题,这导致输入到后续目标检测网络的前景和背景比例失衡,因此原始Faster RCNN随机从产生的候选区域中随机挑选正负样本并设置比例为1∶3来克服比例失衡对网络性能带来的影响。但是,随机挑选的样本中包含了大量无效的正负样本,使得模型参数更新缓慢,大大降低了检测效率。
正负样本数量的不均衡和样本的随机挑选造成网络的特征表达能力差和对小目标的检测性能不佳。因此,本文将OHEM引入到Faster RCNN中,在保证实时性的同时,不需人为设定正负样本比例,可自动挑选具有多样性和高损耗的困难样本,提高网络检测效果。将ROI池化层后面网络部分称为ROI网络,引入在线困难样本挖掘方法后的Faster RCNN将原始的一个ROI网络扩展为两个共享网络参数的ROI网络(一个是只读ROI网络,一个是标准ROI网络)。主要传递过程为:对于一个输入图像的第t次的SGD迭代,首先使用卷积网络计算一个卷积特征图,然后ROI网络使用这个特征图和所有的输入ROIs代替了挑选的小批量输入,做一个前向传播,输入到只读ROI网络中。然后,计算当前网络损失,损失较大的样本被挑选出来,构建困难样本批次。然后将困难样本输入到标准ROI网络(图3虚线部分)进行目标分类和位置回归并进行网络参数的更新。由于只有少量的ROIs被选择用于更新模型,后向传播的消耗较小。引入在线困难样本挖掘方法后的Faster RCNN在进行网络训练的过程中实现了自动对困难样本的挖掘,不需要设置正负样本数量比例,更有针对性。通过实验发现,在线困难样本挖掘策略可以增强算法的判别能力,提高网络检测精度。
2 实 验
实验所用数据集是来自VOC2012数据集[14]、互联网和实际施工场景,共计7000张,包含各种环境条件下的施工场所工人的监控图片,如图5所示。并根据实验要求转换成VOC2007数据集格式进行训练。实验环境:GPU:GeForce GTX 1080Ti,CUDA8.0,Ubuntu16.04,内存12 GB。网络部分选择主流的深度学习框架caffe作为实验平台。

图5 样本数据
本文实验在收集的数据集上进行方法评估,以下实验用于验证提出方法的有效性。
(1)不同安全帽佩戴检测方法的检测效果
为了验证本文提出方法的有效性,利用实验数据分别对原始Faster RCNN和改进后的Faster RCNN进行训练,实验结果如图6所示。
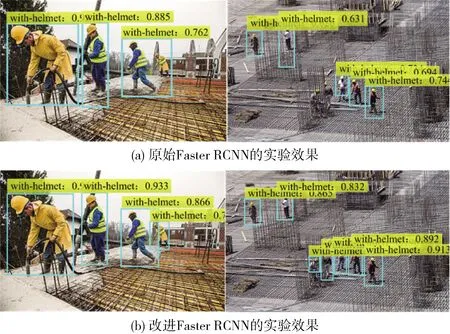
图6 两种算法的检测效果对比
图6中的图(a)、图(b)分别是原始Faster RCNN网络模型和改进后的Faster RCNN网络模型的安全帽佩戴检测的效果图。可以观察到,相对于图(a),图(b)可以很好地检测出佩戴安全帽人员,且可以检测到更多的遮挡目标和小目标,检测目标的位置准确,边界框完整。
(2)不同模型的检测结果
为了验证本文提出改进方法的有效性,在实验数据上进一步实验验证。本部分实验复现了原始的Faster RCNN网络模型、1.2.1节的多层卷积特征融合技术、1.2.2节的在线困难样本挖掘技术以及本文方法。不同改进模型在实验数据上的检测结果见表1。
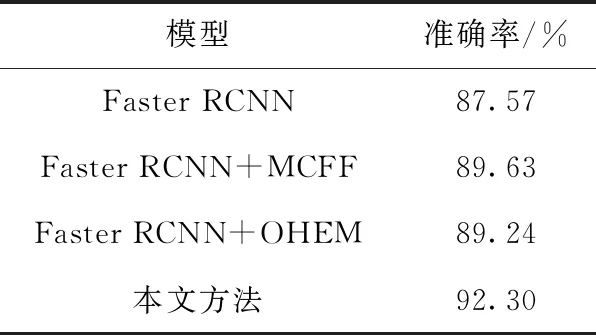
表1 不同网络模型的检测效果
从表1可以看出不同改进方法对网络检测结果的影响。原始Faster RCNN网络模型的安全帽佩戴检测准确率为87.57%,使用多层卷积特征融合技术后的Faster RCNN网络的检测准确率提高了2.06%,这是因为通过将浅层网络像素信息和深层网络语义信息想融合,产生的候选区域特征同时具备像素信息和语义信息,特征更加全面,更能准确定位遮挡目标和小目标。在原始Faster RCNN网络中引入在线困难样本挖掘技术,检测准确率提高了1.64%,这是因为本文将在线困难样本挖掘机制嵌入到网络模型中,解决了网络在训练过程中的负样本空间过大问题,增强了网络的分辨力。而本文方法相对于原始Faster RCNN网络检测准确率提高了4.73%,达到了92.30%。实验结果显示MCFF和OHEM均能提高Faster RCNN的检测精度。
(3)采用不同方法检测单张相同图片的时间对比
实验使用YOLO、SSD、原始的Faster RCNN以及本文提出的改进Faster RCNN算法进行训练,准确率以及测试单张图片的速率见表2。

表2 不同算法检测单张图片时间对比
YOLO的网络结构较为简单,检测速度较高,但检测精度相对其它算法较低。SSD是一个单一的回归网络,检测精度相对较高。本文提出方法在Faster RCNN基础上引入多层卷积特征融合和在线困难样本挖掘方法。从表2可以看出,本文提出方法在检测速率方面劣于基于回归网络的算法,但是精度占较大优势,达到92.30%。
(4)不同环境条件下改进的Faster RCNN的安全帽佩戴检测效果
挑选不同环境条件下图像来测试改进Faster RCNN的检测性能,检测结果如图7所示。可以看出本文提出算法对光线不佳场景如图7中的图(a),目标尺寸较小场景如图7中的图(a)、图(b),目标尺寸差距较大场景如图7中的图(a)、图(c),目标模糊场景如图7中的图(d),部分遮挡目标场景如图7中的图(d)、图(e)以及多目标检测场景如图7中的图(f)均有较好的检测效果。实验结果表明,本文提出的算法适用于不同环境条件下的安全帽佩戴检测,对小目标和遮挡目标检测具有较好的鲁棒性。

图7 改进Faster RCNN的安全帽佩戴检测效果
3 结束语
本文提出的改进Faster RCNN安全帽佩戴检测算法能有效检测小目标和部分遮挡目标,提高检测准确率。该算法在原始Faster RCNN算法基础上引入多层卷积特征融合技术,使得提取出的目标区域特征结合了高级语义特征和低级像素特征解决了目标尺度问题。在目标检测阶段,在线困难样本挖掘方法用于选择检测模型训练的有效例子。实验结果表明,本文方法对安全帽的佩戴检测精度较原始Faster RCNN有显著提高,增强了小目标和遮挡目标在不同环境条件下检测的鲁棒性。在未来的工作中,将着重研究网络的优化,检测速度和模型尺寸等。
猜你喜欢
机电安全(2022年4期)2022-08-27
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
课外生活·趣知识(2019年4期)2019-09-10
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
今古传奇·故事版(2017年5期)2017-04-08
