
基于工作者多属性特征模型的任务分配方法
2020-05-23 10:06原博洋王丽清
计算机工程与设计 2020年5期
原博洋,王丽清
(云南大学 信息学院,云南 昆明 650091)
0 引 言
众包(crowdsourcing)作为一种依托互联网受众实现任务分配和协同工作的方法,随着任务需求的复杂和深化,已逐渐向多学科、多领域技术融合的方向发展。依托信息技术强大的计算和分析能力,在众包的任务分配、过程控制、激励和结果评价反馈等多个方面实现了技术融合和突破。对于众包的任务分配来说,任务得以有效完成并取得高质量任务结果的关键是如何从众包工作者中筛选出最合适的参与者。
为此,一方面可以从定义一个更完整和精准的工作者特征的角度,来达到提升众包任务和工作者之间匹配度的目的。包括基于Argo+框架技术按工作者特征和任务属性匹配,再利用机器学习技术辅助的方法[1],以及基于工作者信誉值进行模型构建或分配的方法[2,3];还有学者采用基于滑动窗口的方法,提出专业准确率的定义,衡量工作者的专业水平[4];建立扩展模型评估工作者能力,对工作者属性进行深层次的描述[5];或者通过对工作者历史信息的分析,从兴趣、专长、活跃度等方面构建不同的任务分配方法[6-8]。
另一方面是分析任务需求,给出更详细的任务描述的方法。例如定义任务的成本边界值,增加任务质量要求的方法[9];针对不同的任务分配环境,结合人工智能或基于历史数据的在线学习进行筛选的方法[10,11];或者借助数据库支撑任务匹配和完成[12];还有从任务内容角度和任务可靠性要求的分配方式[13,14]。
随着任务需求复杂性、难度的逐渐提高,对工作者特征模型的建立和任务分配,提出了更全面、更灵活、更精准和更高效的要求[15]。不论是单方面从工作者的角度还是从任务定义的角度,都难以完整、准确地描述双方的特征,从而带来任务匹配效果不佳的问题。
为此,本文以中泰的众包协同翻译作为实例,根据非通用语语言翻译任务的具体要求,分析对于承担该任务,并尽可能取得较好任务结果的工作者,应该具备的典型特征。然后,基于层次分析法(analytic hierarchy process,AHP)构建工作者的多属性特征模型,实现对任务需求和工作者特征的多点匹配,最后据此完成任务分配。这样,既避免了任务需求和工作者素质脱节的问题,又有效地提高了众包任务分配的准确性,提高了任务完成的质量和效率。此外,对于在任务分配中由于对新任工作者缺乏历史数据描述而造成的“冷启动”问题,也可以在提取少量初始信息的基础上,得到该工作者的特征描述,进而对其完成初期任务的高质量匹配,取得较好的任务效果。
1 多属性特征模型构建
针对非通用语言众包协同翻译任务,需要工作者在语言的专业翻译能力、工作者的积极性和工作态度,甚至在当下的工作状态上具有良好的表现,才能在参与任务中取得满意的结果,进而提升任务完成效率和质量,降低任务成本。
因此,用评价指标的设计将任务需求和工作者的特征描述紧密结合起来,再进行权重和量化计算,给出每个指标的权重系数,以便筛选出最佳工作者。
根据以上分析,在任务分配中,根据层次分析方法原理和步骤,从评价指标定义、构造多因素判断矩阵、权重向量计算来构建工作者的多属性特征模型。
1.1 评价指标定义
在对模型进行指标定义时,本文结合要解决的具体任务和工作者的特征建立自上而下的三层结构模型,将决策目标定义为翻译能力指标A,并据此筛选出不同翻译水平的工作者。
准则层包括专业语言能力评价B1,其下包括翻译结果接受次数、翻译结果质量加权分、综合成绩排名、语言证书等级、学历共5个方案层指标[16];
参与度评价B2,包括任务响应速度、任务主动参与数、任务接受次数、在线时长、近3个月参与次数[16];
工作态度评价B3,包括任务完成率、完成时间效率、黄金检测通过次数、责任心参数[16]。完整的模型指标体系结构见表1。

表1 各级评价指标定义
针对相应的指标,研究并定义了其具体的量化计算方法或计算公式。
(1)专业语言能力评价
目的是描述工作者的专业能力和水平。其中:
C1翻译结果接受次数是该工作者被任务发起者所接受的任务累计数量。
C2翻译结果质量加权分是任务发起者对工作者完成任务的满意度(cs)评价,用数值表示,从不满意(值为0)到很满意(值为5),然后通过计算式(1)计算得到加权分AR[16]
(1)
式中:rei表示第i个任务的评测结果,csj表示第j级满意度。
其它专业能力评价指标也分别根据不同能力和水平用分值进行量化描述。
(2)参与度评价
该指标用于描述工作者参与任务的积极性和活跃度。其中任务响应速度(RS)的计算公式如式(2)所示[16]
RS=(Te-Ta)/(Te-Ts)
(2)
式中:Te为任务执行截止时间,Ta为任务接受时间,Ts为任务发布时间[16]。
C9在线时长(OT)计算公式如式(3)所示
OT=Tl-Te
(3)
Tl和Te分别代表工作者登录和注销的时间。
其它参与度指标根据工作者参与任务的实际数据统计得出。
(3)工作态度评价
该指标描述了工作者近期的工作状态和工作态度。其中任务完成率(TC)的计算公式如式(4)所示[16]
TC=Nc/Na
(4)
式中:Nc为完成的任务数;Na为接受任务数。
完成时间效率(TE)的计算公式如式(5)所示
TE=Tf-Ta/Te-Ts
(5)
式中:Tf为任务的完成时间,Ts和Te分别表示任务的发布时间和截止时间,Ta为任务接受时间。
1.2 构建多因素判断矩阵
层次指标和模型构建完毕后,构建判断矩阵。根据运筹学家Satty提出的层次分析法中对于两两因素的比较关系量化表(表2)[17],本文对各个指标的重要性要求使用7分位比率计算量化结果,构造出A、B1、B2、B3判断矩阵。

表2 关系量化分析

1.3 特征权重计算
(1)一致性检验
构建了判断矩阵后,需要对判断矩阵进行一致性检验。对于一致性检验不通过的矩阵,需要重新构造,直至达成矩阵一致性为止。根据参考文献[17]的定义,一致性检验根据判断矩阵的最大特征值,通过按如下公式计算一致性指标CI和一致性比率CR完成
(6)
CR=CI/RI
(7)
当CR<0.1时,则表示CI在允许范围内,矩阵满足一致性。其中RI取值见表3。

表3 RI取值
(2)计算特征权重
根据以上方法,得到判断矩阵A的最大特征值λ=3.0536,CR=0.0268/0.58= 0.046,CR值小于0.1,因此矩阵A满足一致性检验。
计算A特征向量并归一化处理后为:δ=[0.6441,0.2706,0.0976],即为准则层各个评价指标的权重,见表4。权重从高到低,可以看出各个评价指标对A翻译能力的影响程度。
按照上述方法求出矩阵B1、B2和B3的归一化特征向量,即得到各级指标的权重值计算结果见表4[16]。

表4 各级指标权重对照
根据表4按式(8)即可计算出各个工作者的翻译能力评价指标A
(8)
其中,Bi的计算公式为
(9)
式中:Bi、Cj分别表示准则层和方案层指标值,Wbi、Wcj分别表示Bi和Cj的指标权重[16]。
2 任务分配
通过上述方法建立的工作者特征模型,即可在协同翻译任务的分配中提取出综合工作能力更优秀的工作者,完成对应的翻译工作。工作者筛选和任务分配的流程如图1所示。
首先采集工作者初始数据,并存储到数据库,完成模型初始化和对工作者的量化指标计算,对计算结果排序后即筛选出满足任务需求的能力优异的工作者,对其进行任务分配。

图1 基于特征模型的任务分配流程
3 实验与结果分析
3.1 实验数据
在实验中,由于需要具备中泰两种语言的工作者,标准数据难以取得,因此依托高校外语学院相关专业通过征集志愿者,获取了志愿者包括专业、成绩等在内的初始数据,建立了工作者属性表。其中,对于成绩排名、证书等级、学历等级等难以量化的信息,采用预定义量值的方式解决。数据经处理后存储到数据库,作为工作者初始特征数据。
对于任务内容,从经专业翻译审核完成的中泰标准平行译文知识库中抽取固定数量的短译文作为待翻译的任务实验数据。中文提交给工作者作为任务完成翻译,对应泰文作为标准译文,用于评测工作者翻译质量。
3.2 实验结果与分析
为比较任务分配的执行效果,采用随机分配工作者和对工作者首先进行翻译测试,然后根据测试结果分配任务的方法作为对比,对3种不同分配方法最后取得的翻译结果与标准译文基于BLEU评估方法进行质量对比,来完成对本文研究结果的分析。
实验结果见表5~表7。

表5 基于翻译测试评测分配的实验结果

表6 基于随机分配方法的实验结果

表7 基于工作者特征分配模型的译文评测
使用散点图直观表示如图2所示。
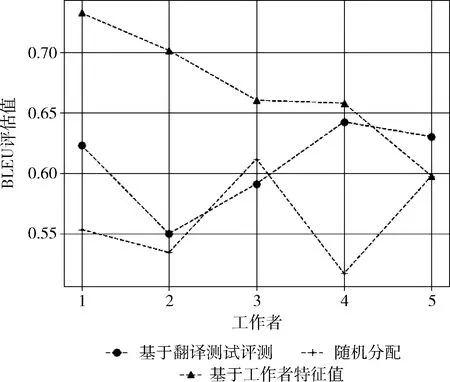
图2 3种分配模型BLEU质量对比
从实验结果可知,采用本文提出的方法取得的译文平均质量要高于按照随机分配和基于测试的分配方法所最终得到的译文。
在翻译结果中,存在基于翻译测试评测方式筛选出的某工作者所提交译文质量比本模型筛选工作者高的情况(例如表6中的工作者5)。分析其原因,一是对于翻译质量,一方面很大程度依赖于翻译者的综合水平,但另一方面也会受到翻译中是否有外来因素影响,造成翻译结果波动的问题;二是对于本研究的译文质量评价,主要基于BLEU评价方法,为更全面、客观地对译文质量进行综合评定,还可以引入其它评价指标,甚至主观评定来完成一个更准确的评估。
4 结束语
本文所提出的面向具体任务需求的多属性工作者特征模型分配算法,主要以中泰语言的众包协同翻译作为任务需求,基于层次分析法,通过对任务工作者的需求特征分析,建立多因素的评价指标体系,并据此完成基于工作者特征的筛选模型构建和任务分配算法设计。
该方法在研究中依托层次分析法在面对复杂和缺少数据的多因素影响问题中能够定性和定量结合进行分析的优势,对语言翻译工作者进行基于需求特征的评价指标定义,并提出指标量化方法,为快速计算和筛选出最优工作者提供了方法。
根据实验,采用该模型和方法,可以更精准、更快速地筛选出任务的最佳工作者群体,并取得更好质量的任务结果。对于其它任务需求的模型构建,同样可以采用该方法进行特征模型的建立,主要区别在于评价指标的设计。该模型的部分指标(包括参与度、工作任务完成率和完成质量等)随着工作者对于任务的不断参与,在取得工作者累积历史数据的情况下,将会获得更好的任务分配效果。
为进一步提高对结果质量的控制,今后考虑在任务执行过程中增加对工作者的监督,避免不可预见因素影响对工作结果带来的波动。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
音乐天地(音乐创作版)(2021年8期)2021-12-01
纺织科学研究(2021年6期)2021-07-15
——致敬殡葬工作者
黄河之声(2021年2期)2021-03-29
水利经济(2020年3期)2020-02-22
人民调解(2019年1期)2019-03-15
小学生学习指导(低年级)(2017年6期)2017-02-16
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
