
基于MIV-MEA-Elman神经网络的核桃果实膨大期需水量预测
2020-05-28 07:15李文竹刘婧然
节水灌溉 2020年4期
邓 皓,李文竹,刘婧然,刘 心
(河北工程大学 信息与电气工程学院,河北 邯郸 056038)
0 引 言
我国的核桃种植面积和产量在世界处于领先地位[1]。对其需水量大小进行精确的判断对制定合理的灌溉用水计划有着深远的影响。影响核桃需水的因素具有高维、非线性等特点,模型中不考虑或考虑的因素过少都难以诠释核桃生长需水的规律,导致预测结果通常会缺乏合理性,所以对影响因素进行有效的筛选具有很大的必要。核桃果实迅速膨大的时间段是核桃需水的重要时期[2],建立一个合理的预测模型对该时期进行需水量预测十分重要。
国内外关于农作物需水量的预测和农业灌溉的研究很多种,比较常见的有:李志新等[3]把日序数等因素作为模型的输入,通过遗传算法对Elman神经网络的优化,针对参考作物的需水量构建了GA-Elman预测模型。夏泽豪等[4]结合神经网络和灰色理论,考虑到了多种气象因素的影响,确立了模型拓扑结构。赵桂生等[5]构建了GM(1,1)模型对我国农业灌溉方面的用水量进行预测。江显群等[6]用彭曼公式得出玉米的需水量数据,将此作为预测模型的基础,得出此模型在玉米需水量预测中的优势。而关于影响因素筛选的方面,董健卫等[7]通过几种方法进行了分析比较,分析了各个指标间的关系和对PM2.5的影响程度。关于复杂的非线性问题用神经网络模型进行预测有一定的局限性,徐朗等[8]利用思维进化算法的全局寻优能力建立MEA-BP预测模型,结果表明此模型的预测精度有所提升。
本文利用核桃果实膨大期的数据,以核桃的日平均需水量做出准确的预测为目标,提出MIV-MEA-Elman模型。MIV算法可以有效地消除影响因素的信息重叠,筛选出较优的指标,找到对核桃需水量有较大影响的因素,然后利用思维进化算法具有良好的全局搜索性能,解决了单纯的人工神经网络受制于初始权值和阈值的随机选择问题,提升模型的预测精度。
1 数据来源及研究方法
1.1 数据来源
核桃灌水的关键时期在7月份,需要充分考虑这段时间内核桃的需水情况。本次实验对象为河北省邯郸市河北工程大学试验田中的核桃作物。自动气象站设在实验田中,气象数据均是由离地面2 h处测得,数据自动记录在数据采集器中,以天为单位采集了河北省邯郸市2015-2017年每年7月1日-31日的气象数据资料,其中包括:平均气温(℃)、平均气压(hPa)、相对湿度(%)、日照时数(h)和风速(m/s)。
该核桃试验田在邯郸西部,土壤pH值为7. 25。实验过程中分别测出了1.0 m以上的各层土壤干容重及田间持水量,田间持水量(占干土质量)为26.3%。土层厚度在1.0 m以上,其中核桃树根系在1.1 m以上。
1.2 研究方法
根据气象资料以及逐日核桃作物需水量数据,建立了MIV-MEA-Elman神经网络的核桃果实膨大期需水量预测模型。在得到的93组数据中,前62组数据作为训练集训练模型,其余31组数据作为测试集用于测试与验证。
本模型所考虑的输入变量由MIV算法筛选出来,对各影响因素计算出平均影响值,进行变量筛选,找到影响核桃需水量的主要因素,将其作为输入层,输入到经过思维进化算法优化后的神经网络模型中,进行核桃的需水量预测。
1.2.1 MIV(平均影响值)算法筛选影响核桃需水量因素
气象条件对核桃的生长发育和对水分需求大小影响很大,与核桃需水量之间的联系错综复杂,因此要对各因素进行一个筛选,找到对核桃需水量有较大影响的输入变量。MIV算法可以分析各个指标对输出变量的重要性,可对影响核桃需水的因素进行合理有效的筛选。
对于n个影响因素,设为n维向量x,进行次观测,得到向量空间X=[x1,x2,…,xm]T,其所对应的核桃需水向量空间Y写为Y=[y1,y2,…,ym]T。X作为网络模型的输入指标,而Y作为神经网络的输出。将X中每一列分别进行如下变换[9]:
(1)
(2)
重新将式(1)和(2)作为神经网络模型输入,其输出为样本点中第i(i=1,2,…,n)个影响因素指标改变时所对应的输出向量:
(3)
(4)

(5)
式中:IVi(j)代表向量IVi中第j(j=1,2,…,m)个元素;MIVi为核桃数据样本中第i(i=1,2,…,n)个影响因素指标对核桃需水量输出结果的平均影响值,它的符号代表该影响因素与核桃需水量相关的方向,绝对值大小代表该影响因素对核桃需水量影响的重要程度。
1.2.2 Elman神经网络对核桃需水量的预测
核桃需水存在不确定和多输入等复杂的非线性特性,每个影响因素和核桃需水量之间存在非常复杂的非线性关系。神经网络本身具有的具有非线性、高维性等一系列特点,可以解决线性模型受限制的问题,有效地针对核桃需水这种错综复杂的情况。
Elman神经网络具有训练速度快和动态记忆性强等突出优点[10,11]。四层结构如图1所示。输入层的神经元个数根据影响核桃需水的因素来决定,隐含层单元用线性或非线性激活函数表示,承接层和输出层分别起到提高处理动态信息和线性加权输出的作用,将核桃需水的影响因素作为输入,经过四层结构,各层神经元对影响因素的数值作用后,生成核桃需水量的预测结果。

图1 Elman神经网络结构图
该网络状态空间的表达式如下:
v(k)=g[w3r(k)]
(6)
r(k)=f{w1re(k)+w2[o(k-1)]}
(7)
re(k)=r(k-1)
(8)
式中:k为目前状态的时刻;v为输出节点向量;r为隐含层节点单元向量;o为输入的节点向量;re为反馈状态向量;w3、w2、w1分别为承接层至隐含层、输入层至隐含层和隐含层至输出层的连接权值;g代表输出层节点激活函数;f为隐含层节点激活函数。
1.2.3 MEA(思维进化算法)对神经网络的优化
神经网络进行求解时会存在早熟和陷入局部极小值等问题,思维进化算法具有良好的全局搜索性,在解决这些问题上反映出了明显的优势[13,14]。其过程首先在解空间得到得分高的优胜和临时个体,以这些个体为中心生成新的个体形成优胜和临时子种群,子群体内的趋同操作使其成熟,将成熟后的得分在公告板上张贴,子群体间再进行异化操作找出全局最优个体,经过不断迭代后最优个体的得分不变或者迭代结束,输出最优个体,其系统框架图如图2所示。
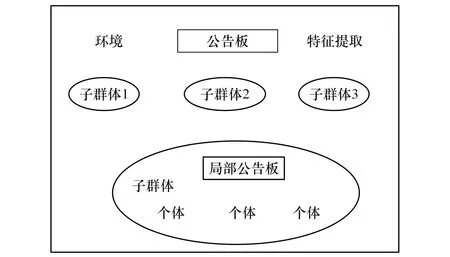
图2 MEA系统框架图
1.3 核桃需水预测模型设计
经过MIV算法筛选出影响核桃需水量的主要因素,然后将其作为建立好的MEA-Elman神经网络模型的输入层,可以得出预测核桃需水量的结果,流程如图3所示。

图3 核桃需水预测流程图
具体流程如下:
(1)将核桃需水量和采集到的气象等因素样本输入模型中进行训练。
(2)样本中的每一个影响因素根据MIV算法的计算规则,得出对应的平均影响值。
(3)按照各影响因素平均影响值的绝对值大小排序,进行变量筛选,筛选出影响核桃需水量的主要因素。
(4)筛选后的数据重新组成新的样本,根据Elman神经网络的拓扑结构, 将解空间映射到编码空间,每个编码对应问题的一个解,形成初始种群、优胜子子种群和临时子种群。
(5)通过思维进化算法中的趋同、异化等操作,不断进行迭代逼近最优路径,满足成熟准则时全局的最优解搜索过程结束,输出最优个体,作为Elman神经网络最优的初始权值和阈值。
(6)计算网络误差反馈给网络,判断是否完成训练。
(7)完成训练,进行仿真预测,输出预测结果,得到核桃需水量预测数值。
2 仿真及结果分析
2.1 核桃需水特点
图4为2015和2016两年7月份1号至31号的核桃需水量变化规律折线图。
根据此图我们很容易看出前十天核桃需水量变化较为平稳,从第十天开始上升,此时核桃需水量变大,待达到了峰值后开始迅速下降,总体来看在7月份核桃需水量呈周期规律性变化。

图4 核桃需水变化规律
2.2 数据处理
在进行仿真试验中,数据本身存在的某些问题可能会对预测结果的精度产生影响,例如数据丢失或者数据异常等。因此,我们要对其中异常数据和残缺数据进行处理,得到一组满足预测算法输入要求的完善数据。
对原始数据的缺失值进行处理的方法有很多种(极大似然估计和多重插补)等,但存在的问题是这些方法相对来说比较单一,很少或者是没有考虑到其他变量对所缺变量的影响,而EM(期望最大化)方法和回归分析方法可以很好的反应各变量之间的关系,是两种严谨的方法。利用SPSS软件中的回归分析方法分析出各因素之间的相关性,得出完整的实验数据。
2.3 MIV算法筛选结果及分析
各种影响因素对核桃需水量的重要程度如表1所示。
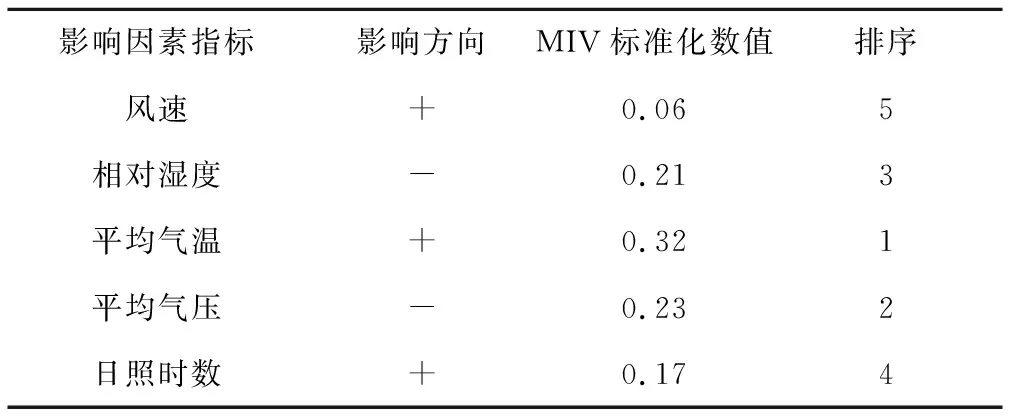
表1 MIV算法筛选影响值结果
表中符号(+、-)代表影响因素对核桃需水的影响方向,将得到的平均影响值进行标准化处理可以更直观地看出影响因素对核桃需水的重要程度。由表中可得出以下结论:
(1)对核桃需水量具有正影响的为风速、平均气温、日照时数这3个因素,具有负影响为平均气压和相对湿度两个因素。
(2)依据影响程度高低进行排序:平均气温的影响程度最大,排在第一位,其余依次为平均气压、相对湿度、日照时数和风速。其中风速对核桃成长过程中的需水量影响最小。
2.4 参数设置
经多次实验比较,模型最佳的参数如表2、3所示。

表2 Elman神经网络参数设置

表3 思维进化算法参数设置
Elman神经网络最优的初始权值和阈值由思维进化算法中优胜和临时子种群趋同异化操作后确定,其过程如图5图6所示。

图5 临时子种群趋同过程
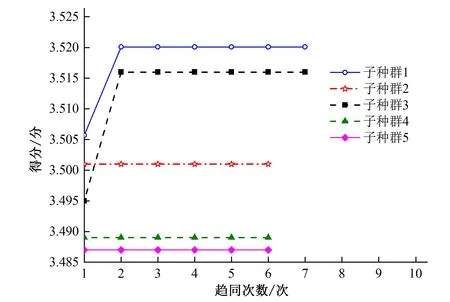
图6 优胜子种群趋同过程
根据图5和6可知, 经过多次的趋同操作,各个子种群的得分也就不再产生变化,表明此时它们都已经成熟。种群成熟后可能会出现一种情况----某个临时子种群的子种群得分可能会比优胜子种群中的某个子种群的得分高,这时候就需要执行异化操作。经过趋同和异化过程,才最终完成对神经网络初始权值和阈值的优化。
2.5 核桃需水预测结果及分析
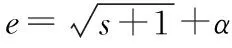
加入GA-Elman模型和Elman网络预测结果以便比较,预测结果如图7所示。

图7 预测结果和真实值曲线
2.6 误差分析
为了更好分析模型对核桃需水量进行预测时的性能,分别对思维进化算法、遗传算法优化后的以及未经优化的Elman神经网络进行分析。选用MAE(平均绝对误差)和RMSE(均方根误差)两种分析指标,MAE能很好地反映预测值误差的实际情况,其值越小,预测值产生的误差越小,RMSE用来衡量预测值与真实值之间的偏差,能够很好地反映出预测的准确度,其值越小,表示预测值与真实值的偏差越低,预测准确度越高。
式中:N为测试样本数;Pi为核桃需水预测值;P为核桃需水真实值。
MEA-Elman神经网络:MAE为0.075,RMSE为0.317
GA-Elman神经网络:MAE为0.094,RMSE为0.352
Elman神经网络:MAE为0.139,RMSE为0.517
由结果可以得出,优化后的神经网络模型比普通的Elman神经网络模型预测的结果更靠近核桃需水的实测值。而经过遗传算法优化过的神经网络模型,相比经过思维进化算法优化后的模型,预测值同真值之间的偏差偏大,能看出思维进化算法在核桃作物需水预测中的准确度和预测效果更好。
3 结 论
基于MIV-MEA-Elman神经网络的需水量预测模型,分析了核桃需水量和气象影响因素与之间的关系,找到对核桃需水量有较大影响的输入变量,思维进化算法解决了Elman神经网络求解存在的早熟和局部极小值等问题,获取了模型的最优初始权值和阈值。仿真结果验证了此模型的优势, 可以有效地进行了核桃作物需水量预测预报工作,及时合理地调整灌溉制度,有助于实现核桃作物的精准灌溉。
猜你喜欢
水土保持通报(2022年3期)2022-10-15
今日农业(2022年15期)2022-09-20
农业机械学报(2022年7期)2022-08-08
农业科技与信息(2021年24期)2021-12-05
农业灾害研究(2021年9期)2021-01-16
陕西农业科学(2020年2期)2020-04-21
种子科技(2019年11期)2019-10-21
生物学教学(2018年3期)2018-08-08
中学生物学(2018年8期)2018-03-01
安徽农业科学(2017年18期)2017-07-10
