
基于概率包络的轮对轴承故障诊断方法
2020-05-29 10:17丁家满
铁道学报 2020年4期
丁家满,原 琦,李 川
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
在城市轨道交通迅速发展的今天,轮对轴承作为列车运行的核心部件,因为长期处在高速运转的工作环境下,导致轮对轴承极易产生损坏。在列车高速运行情况下,一旦轴承发生故障将造成车辆延误,若对故障发现不及时并且没有采取相应有效措施,容易引起重大事故,甚至造成严重人员伤亡。因此,开展列车轮对轴承状态监测和故障诊断方面的研究尤为重要,而且十分必要[1-3]。
常见的列车轮对轴承状态监测与故障诊断方法有共振解调方法、冲击脉冲方法、小波分析等[4-6],这些方法在早期轮对轴承故障诊断中应用较为广泛,在单一故障诊断方面取得较好的诊断效果,近些年涌现出了诸如基于模糊理论、知识推理、遗传算法和人工神经网络等具有智能特点的故障诊断方法[7-11]。文献[12]采用高斯RBF神经网络建立智能故障诊断系统用于机械齿轮箱故障诊断。文献[13]结合小波分解和集合经验模态分解来提取信号故障特征,利用能量判别法和搜索算法进行故障模式识别。文献[14]利用局部均值分解对信号进行分解,从中提取时域统计量和能量等特征参数作为神经网络的输入参数,训练故障诊断模型。然而,在现实中,随着轮对轴承之间的耦合性越来越高,造成故障的原因大多数是多重原因,轮对轴承信号的采集也是多方面的,采集到的故障信号信息也存在不确定性,即便符合某种分布,很可能也存在波动情况。例如轴承振动信号基本符合正态分布,但信号均值在[a,b]之间,方差在[c,d]之间漂移。另外,在对原始信号进行特征提取会带来特征以外的信息缺失问题。对于这种情况,采用传统方法,简单使用分布函数来代替或者用区间来表达都不合适,都存在无法完整描述、信息丢失的问题。
针对上述问题,本文引入概率包络理论,以SVM为分类模型,提出一种基于概率包络的轮对轴承故障诊断方法(PE-SVM)。在对原始轮对轴承信号分布类型检验的基础上,建立概率包络模型,提取其几何形状特征作为SVM的输入,训练并得到诊断模型。诊断结果表明该方法较好地包容了轮对轴承故障诊断中存在的不确定性问题,提高了诊断精度。
1 概率包络基础理论
1.1 概率包络定义
概率包络(Probability Envelope,PE)结合概率论和区间理论,通过计算随机变量的累计概率函数(Cumulative Probability Distribution Function,CDF)积分面积变化范围,将不确定性变量的波动漂移包裹在一个具有上下边界的区域内,防止信息丢失。概率包络同时考虑了不确定参数固有的随机性和不精确性。

(1)
(2)
则CDF函数的范围为PE,可表示为
(3)
利用PE将变量X的累积概率函数限制在一个范围内,即有
(4)


图1 概率包络示意
1.2 证据结构体
证据结构体(Dempster-Shafer Structure,DSS)由有限个焦元组成,每个焦元由一个区间和区间信度组成,即
{([x1,y1],m1),([x2,y2],m2),…,([xn,yn],mn)}
所有焦元对应的信度之和为1,即∑mi=1。
假若样本空间为R,则处于这个邻域R的证据结构体m即mass函数可以表示为
2R→[0,1]
则置信函数为
(5)
似然函数为
(6)
1.3 概率包络与证据结构体
概率包络的核心是由多个DSS构成,与证据结构体之间可以相互转化。
由DSS可以绘制出概率包络下边界为
(7)
概率包络上边界为
(8)
如果将概率包络看成整体,那么证据结构体就是它的组成部分。将所有证据结构体xi值按mi间隙纵向排列并将其连接成线可以得到概率包络上边界。同理,将所有证据结构体yi值按mi间隙纵向排列并将其连接成线可以得到概率包络下边界。反之,将概率包络水平均匀切成n片,可以近似得到多个证据结构体,切线两个端点组成证据结构体的区间,切片的高度为其信度(均匀切片,故所有证据结构体的信度相等,为n分之一),如图2所示。

图2 概率盒的等信度离散化
2 基于概率包络的轮对轴承诊断方法
2.1 概率包络建模
针对故障信号出现的各类不确定性问题,利用概率包络建模将采集到的不确定信号绘制在一个包络结构体内。在分析轴承故障信号分布特点的基础上,采用3种建模方法,其建模过程分为以下几个步骤:
step1对采集到的原始信号进行时频域概率分布比对,判断其分布类型。
step2若原始信号基本遵循某种概率分布规律,则利用原始参数概率包络建模方法(the Probability Envelope Modeling Method Based on Original Parameters,OPPEM)进行概率包络建模。
step3若原始信号不遵循某种概率分布规律时,提取其无量纲特征并分析其分布特点,判断是否遵循某种概率分布规律,若满足则采用特征参数概率包络建模方法(the Probability Envelope Modeling Method Based on Characteristic Parameters,CPPEM)。
step4若所提取的特征信息无法确定概率分布类型时,则采用概率包络定义建模方法(the Probability Envelope Modeling Method Based on Definition,DPEM)。
建模流程如图3所示。

图3 建模流程
2.2 概率包络特征提取
在针对不同的分布采用不同的建模方法对信号进行概率包络建模后,提取出概率包络的特征量作为后续诊断的特征不仅可以增加诊断精度而且可以降低因为数据规模增大带来的时间消耗问题。本文通过提取概率包络的几何形状构成特征向量。
(1)累积包络宽度
累积包络宽度主要是为了描述信号数据的不确定的范围,其计算公式为
(9)
(2)对数累积包络宽度
其本质是对累积包络宽度取对数运算,在压缩不确定范围的同时,消除模型的异方差等特性,其计算公式为
(10)
(3)累积区间宽度
累积区间宽度主要是为了描述不确定性信号的取值平均范围,其计算公式为
(11)
(4)边界值
其本质是获取PE的累积置信区间,即PE上下界的各自加和,计算公式为
(12)
(5)矛盾区间统计
矛盾区间统计本质是计算DSS的上界值大于下界值的特殊信号点的个数,其计算公式为
(13)
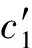
(6)权重区间
其本质是计算对数累积包络宽度之外的焦元权重区间,其计算公式为
(14)
2.3 基于概率包络的故障诊断
基于概率包络的故障诊断方法的主要思想是将提取到的概率包络的几何形状作为特征向量输入到支持向量机SVM,训练得到分类器,进行故障诊断。
基于概率包络故障诊断算法如下:
Input: 信号数据{x1,x2,…,xm}
Output: 故障分类诊断结果
Step1forn=1 tom
Step2概率包络建模
Step3提取特征向量{y1,y2,…,yn}
Step4end
Step5将特征数据切分为训练集{a1,a2,…as}和测试集{b1,b2,…bt}
Step6初始化参数K(K折交叉验证)
Step7forj=1 toK
Step8选取径向核函数
Step9确定参数惩罚因子C和σ
Step10end
Step11fori=1 toS
Step12确定松弛变量和权重系数:ε,w
Step13训练模型

yi(wTxi+b)≥1-εi(i=1,2,…,n;εi≥0)
Step14end
Step15测试数据测试模型得出分类精度
3 实验结果与分析
本文分别选用了公共数据集和实测数据进行了3次实验,实验一主要验证本文提出基于概率包络的特征提取方法的有效性,实验二和实验三分别从公共数据集和实测数据进一步说明本文方法的有效性及泛化能力。其中滚动轴承振动数据选用NSFI/UCR智能维护系统中心的公共数据集(IMS-www.imscenter.net)。实验装置如图4所示,其中安装了4个轴承,旋转速度为2 000 r/min,采样频率为1 024 Hz,轴和轴承上施加了6 000磅(约2.78 kN)的径向载荷。

图4 轴承故障测试实验装置
本实验选取数据集1中的第三个轴承的数据,其中正常与内圈故障数据各60 000条。
对原始信号进行频谱分析,其时域波形和频谱如图5所示。

图5 轴承时域波形图和频谱图
由图5可知,因为各传感器检测信号较为复杂,采集到的信号中常包含背景噪声和其他不确定性,假如无法完整、准确地提取故障特征,将影响甚至导致故障诊断精度的下降。
针对以上存在的问题,采用本文方法对原始信号建立概率包络模型,其正常轴承和内圈故障的概率包络图如图6所示。

图6 概率包络建模
由图6可知,当轴承出现故障时,所构建的概率包络模型与正常轴承信号所建光滑曲线包络相比,既有趋势的相似,又有形状特征的区别。如此,将所有信息包裹在概率包络中,经过概率包络建模后的原始信号降低了因噪声干扰和数据不确定性带来的问题。
经过概率包络建模后的信号,分别对正常轴承和内圈故障轴承采用概率包络的特征提取方法得到特征向量,见表1、表2。
本实验选取累积包络宽度、矛盾区间统计和累积区间宽度为三类特征向量。当利用SVM故障诊断时,为了避免因参数选取不当造成模型的不准确,采用k折交叉验证(k-fold Cross Validation)的方法寻求出最恰当的参数值,其中k设为5,最终确认SVM参数C和σ值分别为100和0.01。本实验分别从正常轴承和内圈故障轴承数据中抽取,每300条数据为一组共200组,每组分别提取概率包络特征,其中2/3用于训练SVM生成分类模型,用剩余1/3测试数据进行故障诊断,并给出诊断结果及其分析。
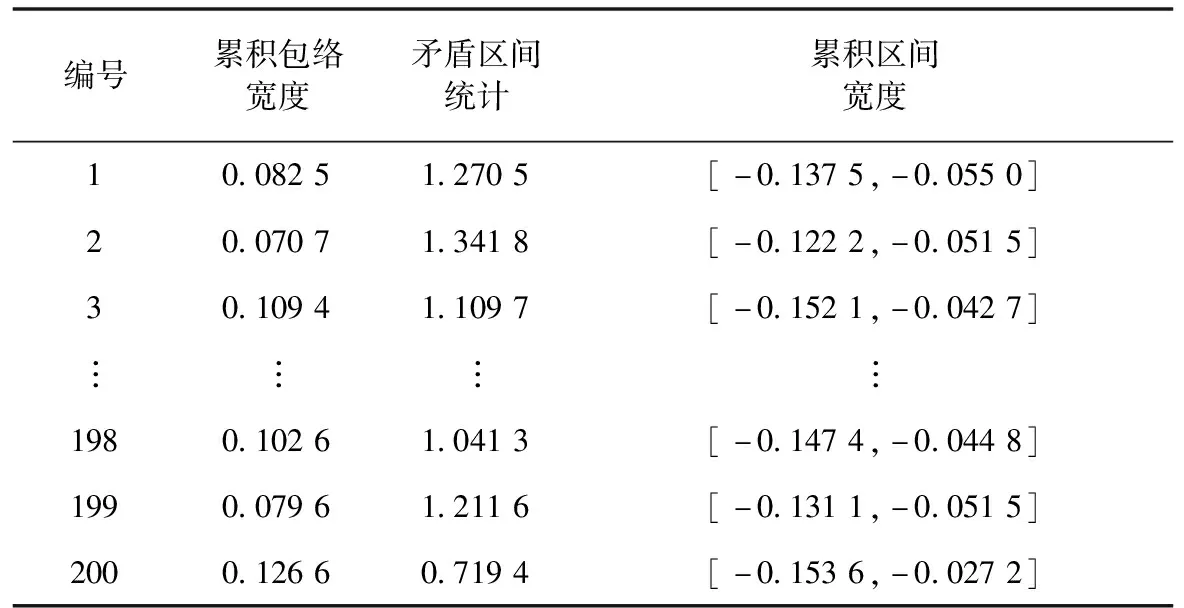
表1 正常轴承特征向量

表2 内圈故障特征向量
在相同信号源的条件下,基于相同的SVM分类原理,采用小波变换提取特征,进行训练和故障诊断(WT-SVM),与本文方法的诊断结果对比见表3。
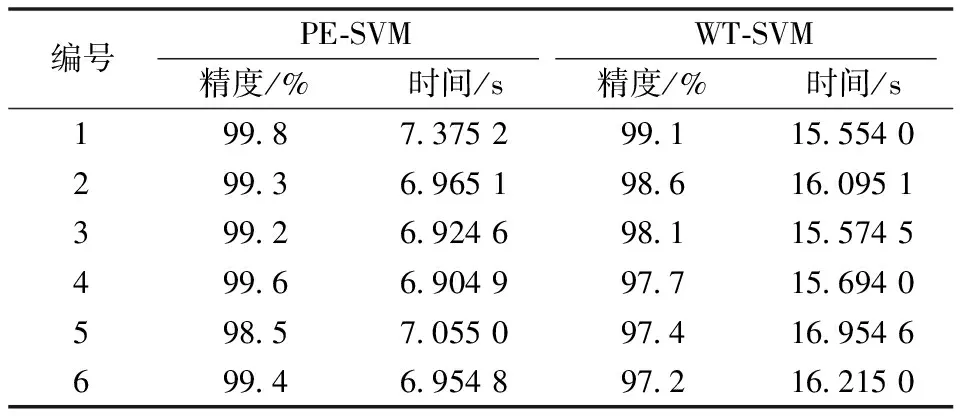
表3 PE-SVM和WT-SVM
从表3可以看出,相对于采用WT-SVM诊断方法而言,采用本文提出的PE-SVM诊断方法不仅在训练时间上具有明显的优势,而且诊断精确度较高。这种差别形成的原因一方面是本文方法使用概率盒来表达参数不确定性,使得对于振动信号不确定性的描述更加全面,提取的特征更具区分度;另一方面,本文提出的基于概率包络故障诊断算法采用k折交叉验证来寻找并确定最恰当的超参数,避免了过拟合的问题。
为更好验证本文方法的有效性,再次进行一组对比实验。重新从数据集1的轴承3中截取出60 000条数据构成新的原始数据集,部分数据见表4。
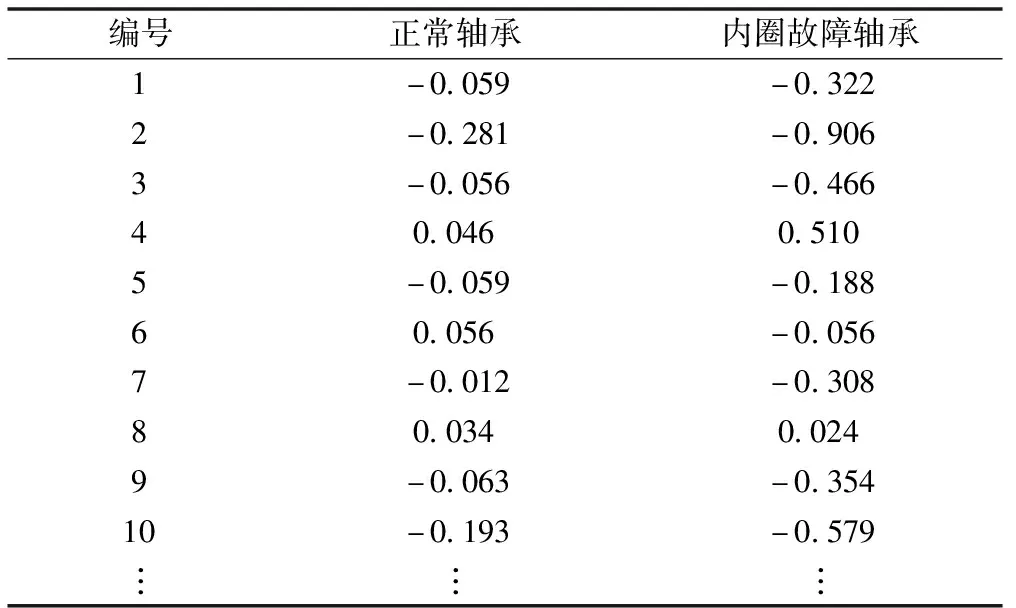
表4 原始数据
采用概率包络分别对采集到的信号数据进行建模,正常和内圈故障轴承概率包络模型如图7所示。

图7 概率包络建模
在建模后分别采用PE-SVM诊断方法和基于朴素贝叶斯网络的概率包络方法(PE-BN)进行诊断对比分析,即先利用概率包络对数据进行特征提取,然后分别基于SVM和朴素贝叶斯网络进行训练和测试对比。利用概率包络提取出的正常和内圈故障轴承特征,见表5、表6。
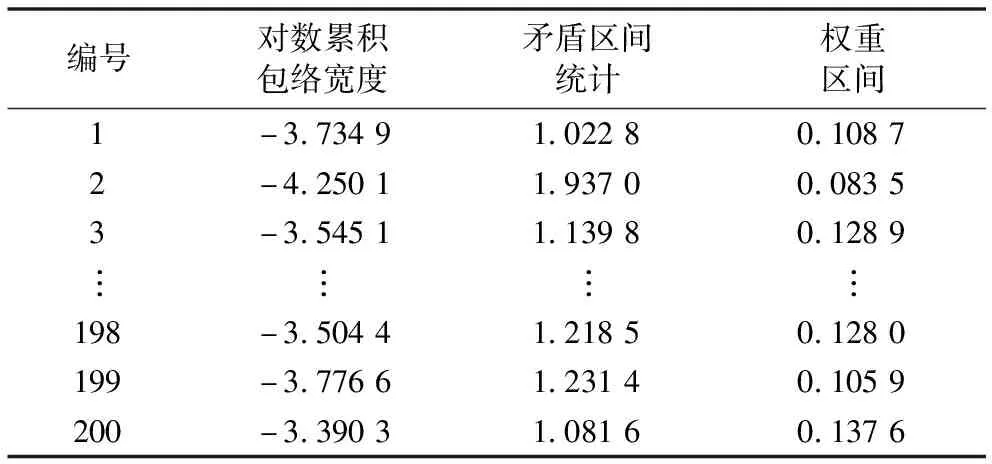
表5 正常轴承特征向量
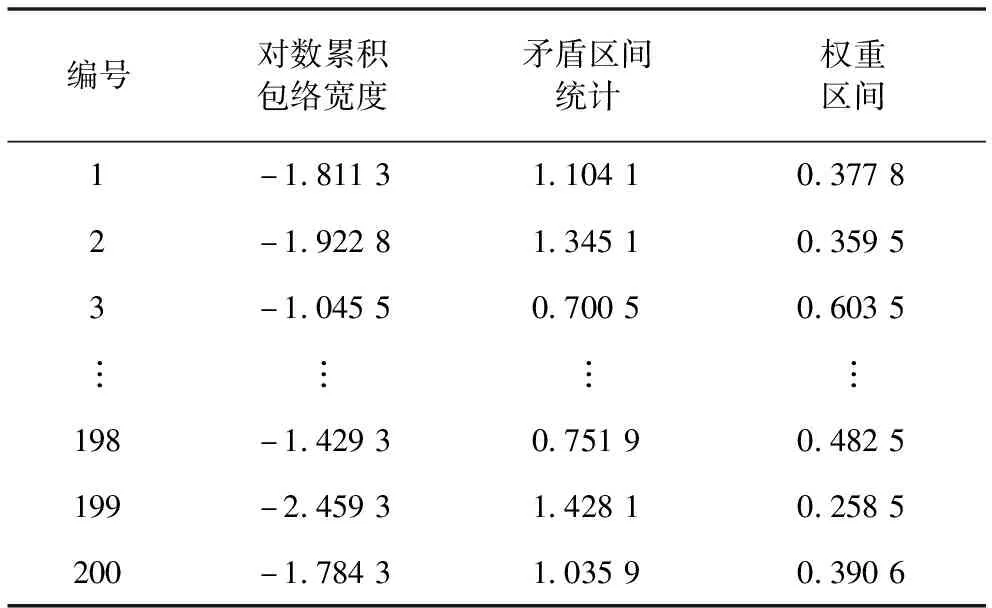
表6 内圈故障特征向量
此次实验选取对数累积包络宽度、矛盾区间统计和权重区间为特征向量作为SVM和朴素贝叶斯网络的输入进行故障分类诊断。SVM参数设定采用k折交叉验证的方法确定出参数值,其中k设为5,最终选取出SVM参数C和的σ值分别为10和0.5,同时将特征值按6∶4随机分为训练数据和测试数据,将其分别传入SVM和朴素贝叶斯网络中进行故障分类诊断。对比结果见表7。
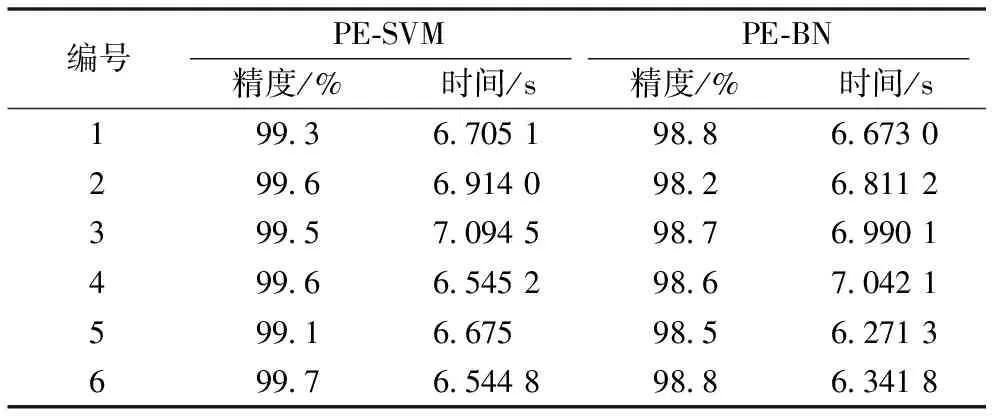
表7 PE-SVM和PE-BN
表7结果是在采用概率包络提取到相同特征向量的基础上两种方法的对比。一方面,表明采用本文提出的PE-SVM方法在训练时间上与PE-BN方法相当,但是在诊断精确度上优于PE-BN方法。另一方面,两种方法的诊断精确度综合平均为99.03%,进一步突显本文采用概率包络进行不确性建模和故障特征提取的方法有效性。
为了更好地验证本文方法的泛化能力,进行了第三次实验,选取实测轮对轴承数据集中的外圈故障、滚动体故障和正常轴承数据各5 000条,数据采样频率为10 240 Hz。对实测信号数据建立概率包络模型,并提取累积包络宽度、矛盾区间统计和累积区间宽度为三类概率包络形状特征,采用本文PE-SVM方法进行故障诊断,其分类诊断精度和时间见表8。

表8 基于实测数据的诊断结果
由表8可以看出,由于样本数量的降低和实测平台部署环境与公开实验平台环境差异性,尤其是将外圈、滚动体故障混合在一起诊断,分类诊断精度有所下降,但故障诊断精度仍然稳定在98%以上,并且分类诊断时间大幅缩短,因而表明本文所提PE-SVM故障诊断方法具有良好的泛化能力。
4 结束语
本文针对信号不确定性问题,引入概率包络理论,将信号的不确定性包裹在概率包络中,解决了特征提取信息丢失的问题。实验表明本文方法有效可行,在兼顾诊断模型训练效率的同时,提高了故障诊断的精确度。本文方法具有较好的泛化能力,除了能用于列车轮对轴承故障诊断之外,对于其他类型的机械故障,也具备良好诊断效果。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
保定学院学报(2022年2期)2022-04-07
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
中国外汇(2019年13期)2019-10-10
数学学习与研究(2018年15期)2018-11-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
