
面向短文本情感分析的多特征融合方法研究
2020-06-05 12:17陶永才张鑫倩
小型微型计算机系统 2020年6期
陶永才,张鑫倩,石 磊,卫 琳
1(郑州大学信息工程学院,郑州450001)
2(郑州大学软件技术学院,郑州450002)
1 引 言
随着社交网络的兴起,越来越多的用户通过社交媒体以短文本的形式发表评论,情感分析用于分析用户评论中包含的态度或意见.如何将深度学习技术应用到情感分析领域受到了研究者的重点关注,是自然语言处理领域的研究热点[1].此外,由于微博和Twitter 等评论文本较短并且没有严格的规范性,所以短文本情感分析相比于普通文本情感分析具有更大的挑战和分析难度.
由于深度学习模型在自然语言处理领域的成功应用,越来越多的研究将深度学习技术应用到情感分类任务中[2],并取得了很大的进展.Blunsom 等人[3]使用 CNN 判断 Twitter文本的情感极性;Wang 等人[4]采用LSTM(长短期记忆神经网络)分析文本的情感类别.上述研究初步探索了深度学习在情感分析中的应用,在无需人工提取特征的基础上取得了比传统分类器更好的分类性能.随着深度学习技术的快速发展,一些研究者针对短文本的特性,提出使用多样化的特征来构建分类模型.Vo 等人[5]提出使用多样化特征信息提升Twitter 文本情感分类的准确率;刘秋慧等人[6]考虑到微博数据的口语化和不规范性等特点对词向量训练模型CBOW 进行拓展;陈珂等人[7]提出使用多通道卷积神经网络完成对多种情感特征组合的学习.这些方法使用神经网络结构提取多种情感特征用来学习短文本中隐藏的情感信息.然而,这类方法没有考虑到文本中富含的情感符号以及情感标签在分类中起到的作用.
针对上述问题,本文在文本词向量特征的基础上,增加了三种情感特征信息:词性特征、情感符号特征和情感标签特征.词性特征将情感词典中的词语重新标注,使神经网络增加对情感词的注意和学习;由于情感符号比情感词具有更强的情感指示作用,因此情感符号特征在情感分类中能够提高情感分类的结果;已有方法很少考虑到情感标签在分类中的作用,增加情感标签特征加强了文本和标签之间的联系.将多种组合特征映射为分布式词向量输入到多通道卷积神经网络中,更加全面的学习到句子中包含的情感特征.
本文提出基于多特征融合的短文本情感分析模型,具体为多特征融合的多通道卷积神经网络(Multi-feature Fusion based on multi-channel convolutional neural networks,MF-MCNN).MF-MCNN 可以同时完成对不同特征的提取和学习.最后在SemEval2017 数据集(英文)和NLPCC2014 数据集(中文)上完成了与传统分类器以及目前先进的模型共7 种模型的对比,实验结果证明本文模型具有更好的分类结果和较低的训练时间代价.
本文的主要贡献有以下三个方面:
1)提出了一种MF-MCNN 模型,该模型在情感分类任务中将不同特征的组合信息和CNN 结合,在不同语言的数据集上有效识别文本的情感极性.另外与以lstm 作为核心网络相比,MF-MCNN 网络以多通道卷积神经网络平行接收文本句子的多输入,大大提高了模型的训练速度和降低了模型的训练时间;
2)将情感符号作为句子的重要组成部分,并通过emoji2vec 映射为分布式词向量,将情感符号的词性重新标注为pos 和neg,通过和词特征、词性特征的组合,可以使文本的情感信息得到更有效的表示;
3)本文提出将情感标签映射为分布式词向量,并作为一种情感特征,和从文本中提取的词特征、词性特征、情感符号特征建立联系,可以让情感标签发挥在情感分类中的辅助作用.
2 相关工作
2.1 情感分析
在情感分析任务中,有三种广泛使用的研究方法:基于词典的方法、基于机器学习的方法、基于深度学习的方法.
首先,基于词典的方法使用已有的情感词典对文本中含有的情感词汇进行得分加和的方式来判断文本的情感极性[8].该类方法的缺点是对情感词典的依赖性很高,然而由于互联网词汇发展迅速,情感词典不能完全包含文本中的情感词,大大降低了该类方法的分类性能;其次,基于机器学习模型的方法使用文本分析技术抽取文本中的特征并利用这些特征完成情感分类.具有里程碑意义的是2002 年Pang 等人[9]首次使用机器学习模型进行情感分析,应用三个代表性分类器(支持向量机SVM,朴素贝叶斯NB 和最大熵ME)对文本情感分类任务进行实验研究;Wan 等[10]提出基于KNN 和支持向量机的文本分类方法,提高了分类的准确率.该类方法的缺点是特征构造是否合适严重影响机器学习分类的效果.
然而,上述两种方法都过度依赖词典或特征工程的构建,近年来兴起的深度学习技术较好地解决了上述方法的缺陷,深度神经网络摆脱了词典和特征工程的束缚,使用多层神经网络将低层词向量合成高层文本情感语义特征向量,从而得到文本最终的情感语义表示,并进一步使用神经网络模型识别文本中包含的情感,加速了情感分析领域的快速发展.Kim等[11]使用卷积神经网络(CNN)对短文本进行建模,完成句子级别的文本情感分类.在情感分析中常用的深度学习模型还有 RNN(recurrent neural network)[12]和 LSTM(long shortterm memory)[13].
2.2 卷积神经网络(CNN)
CNN 是深度学习中的核心技术之一,它通过卷积层和池化层自动提取文本中的特征,无需对数据进行复杂的预处理.CNN 目前被广泛应用于情感分析研究中,Kim 等人[11]提出的MCNN 模型对多个窗口内的词向量提取语义特征,结果表明MCNN 在多个不同的数据集上都具有较好地分类性能;何炎祥等人[14]提出了一种情感语义增强的深度学习模型(EMCNN),该模型通过将情感符号空间映射和MCNN 相结合,有效增强了MCNN 捕捉情感语义的能力;陈珂等人[7]提出的MCCNN 模型使用多通道卷积神经网络完成对四种特征组合的学习,四个通道充分提取了四种特征的情感信息,取得了比普通CNN 更好的性能.由于CNN 模型能够自动提取文本中的关键特征信息,并且训练速度较快,因此成为本文情感分析方法的核心模型.
2.3 情感符号
由于情感符号具有强烈的情感表达能力,越来越多的用户在评论中增加情感符号来加强自己的情感倾向.Liu 等人[15]提出一种新的表情符号平滑语言模型(ESLAM),ESLAM 利用情感符号平滑的方法无缝集成了手动标记的数据和有噪声标签的数据,实验表明该模型优于仅使用其中一种数据的方法.在ESLAM 模型的基础上,Jiang 等人[16]将情感符号映射到分布式词向量空间中,构建了情感符号空间模型(ESM),该模型将词语和情感符号映射到相同的向量空间中,接着使用SVM 完成有监督的情感分类,有效地证明了情感符号在情感分类中的重要作用.ESM 被提出之后,越来越多的研究将情感符号看作重要的情感特征,为了加强情感语义的捕获能力,何炎祥等人[14]提出将情感符号作为一种情感特征输入到多通道卷积神经网络中,加强了卷积神经网络提取情感特征的能力.受到何炎祥等人的影响,为了注意到更多的情感符号信息,张仰森等人[17]构建了微博情感符号库,该符号库包含了情感词、否定词、情感符号、程度副词和常用网络用语,证明了丰富的情感符号信息对情感分类具有更大的帮助.
2.4 标签向量
大多数研究工作将标签向量转化为稀疏的、独立地和无意义的0-1 向量,这种方式导致了标签潜在信息的丢失.在不同领域和任务中已经显示出标签向量的有效性.在自然语言处理领域,Tang 等人[18]在异构网络的上下文中采用标签向量用于文本分类.考虑到标签的重要性,Zhang 等人[19]在文本多标签文本分类任务中将标签和单词转化为分布式词向量,最终将文本分类任务转化为向量匹配任务并成功应用到情感分析任务中.Wang 等人[20]提出将LEAM 模型应用在文本分类任务中,其中标签以不同注意力分数的形式添加到文本分类的过程中,在训练时间和分类结果上得到了很大的提升.
3 情感分析模型
在情感分类任务中,情感特征的提取对分类的结果尤为重要,本文提取了四种特征:词特征、词性特征、情感符号特征和情感标签特征,将四种特征组合变换构建三个新的组合特征,并输入到多通道卷积神经网络中,最终提出了一种基于多特征融合的MF-MCNN 模型,该模型将不同的特征进行组合作为卷积神经网络的多输入,从而使模型获取更加全面的情感信息,取得更好的情感分类结果.
3.1 特征构建
3.1.1 词特征
本文以句子的词为单位,将每个词映射为分布式词向量,在词向量词典中由两列组成,一列是词语,一列是词语对应的分布式词向量表示.假设词典中元素个数为N,每个词向量维度为d,则M∈Rd×N是整个词向量词典的表示矩阵.
对于一个句子序列 S={w1,w2,…,wn},通过在 Rd×N这个词向量矩阵中查找每个词wi对应的词向量,将每个句子序列中每个词语对应的词向量依次拼接起来,即可得到整个句子序列的词向量矩阵,如式(1)所示.
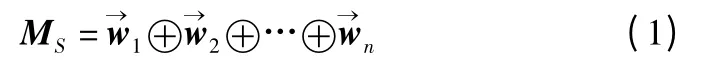
3.1.2 词性特征
本文使用Hownet1情感词集合更新句子中特殊词语的词性标注.如表1 所示,对句子中特殊词进行特定的词性标注,在特征提取过程中能够保留对情感分类有重要作用的词语的特征信息.

表1 词性标注Table 1 POS tagging
对词性标注进行向量化操作,将其映射为分布式词向量tagi∈Rk,k 表示词性向量的维度,如式(2 )所示.
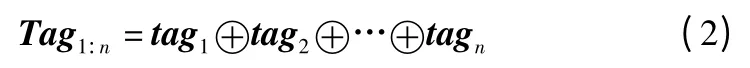
其中,tag 表示词性向量.
3.1.3 情感符号特征
带有情感符号的句子更容易判断情感倾向,情感符号具有比情感词更强的情感指示作用,在微博数据集中表情符号以alt 标签的形式存在,例如,以[哈哈]的形式存在,以[哭]的形式存在.对于每一个句子,如果存在表情符号,将表情符号转化为分布式向量[24],并在Hownet 中找到其对应的情感极性:积极或消极,如果属于积极情感符号,将其词性重新标注为pos,如果属于消极情感符号,将其词性重新标注为neg.若在Hownet 中未找到对应的情感极性,则无需重新标注.如式(3)所示.
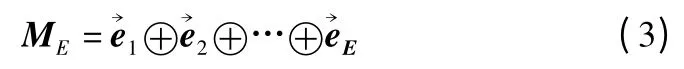
3.1.4 情感标签特征
在词性特征中,将积极和消极情感词分别标记为pos 和neg,为了充分利用标签表达的情感信息,将积极标签、消极标签和无情感标签分别转为positive、negative 和neutral 对应的分布式向量.向量化的标签用 L 表示,L={l1,l2,…,lm},其中m 是标签的类别数,li为标签yi的向量.
3.2 多通道卷积神经网络
如图1 所示,结合词特征、词性特征、情感符号特征和情感标签特征的多通道卷积神经网络MF-MCNN 模型主要由六部分构成.

图1 MF-MCNN 模型的整体架构Fig.1 General architecture of MF-MCNN model
3.2.1 输入层
输入层是网络结构的始端,本文使用三个通道来接收句子的不同特征组合:词特征+情感符号特征+词性特征、词特征+情感符号特征、情感标签特征,并将不同特征映射为分布式向量的形式,不同的通道使得模型获取更加丰富的特征信息.将式(1)中的词向量,式(3)中的情感符号向量和式(2)对应的词性向量进行拼接操作,形成第一个特征矩阵V1∈Rd+k,如式(4)所示;将式(1)中的词向量和式(3)中的情感符号向量进行拼接操作,形成第二个特征矩阵V2∈Rd,如式(5)所示;第三个特征矩阵V3∈Rd,由标签向量表示,如式(6)所示.
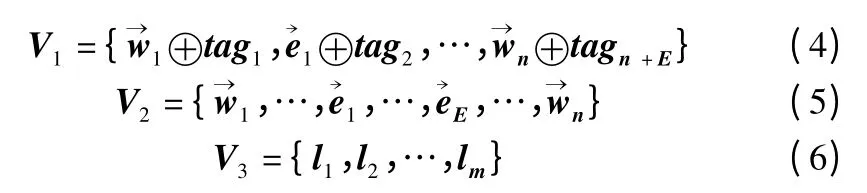
3.2.2 卷积层
本文对于不同的通道使用不同尺寸的卷积核对输入的特征进行卷积运算,提取出句子中更丰富的抽象特征.提取的特征如式(7)所示.
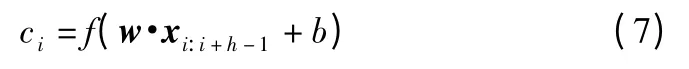
其中w∈Rh×m表示卷积核的权重,h×m 代表卷积核窗口的大小,高度是h,维度是m,卷积核每扫描过一个高度为h,维度为m 的词序列便得到一个特征值;b 表示偏置值;f 表示激活函数,本文使用Relu 函数作为卷积层的激活函数;xi:i+h-1表示句子序列中第i 个词到第i+h-1 个词的词向量矩阵;ci表示经过卷积运算得到的第i 个特征值.
经过卷积操作之后,每个句子可以得到一个特征图c,如式(8)所示.
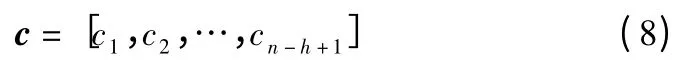
其中,n 代表句子序列的长度.
3.2.3 池化层
池化层通过设定池化区域固定的步长进行采样操作,本文使用最大池化的方式对不同通道中卷积后的特征图c 执行下采样操作,提取每个通道中最重要的特征,即获取每个卷积算子对整个句子操作后的最强情感信号.如式(9)所示.


其中,m 是卷积核的数量.
3.2.4 合并层
3 个通道的特征经过卷积和池化后分别用X1,X2,Yj表示,对它们进行合并,本文使用的是一种简单的拼接操作,组成最终的向量并输入到全连接层.
3.2.5 全连接层
最后,将上一层输出的向量输入到一个全连接层M3m×1,从局部特征向量提取特征信息,并通过权重矩阵学习不同通道之间的联系.
3.2.6 输出层
本文采用Sigmoid 函数输出待分类句子的情感分类结果,非线性函数变换后,文本和每一个情感标签产生一个匹配分数,在0-1 之间,值越大,表明文本的情感类别越接近该情感标签,如式(11)所示.训练过程中,模型通过最小交叉熵损失函数l 来调整模型参数,提升分类性能,如式(12)所示.
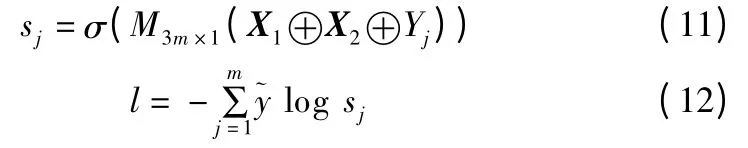
4 实验与分析
4.1 实验环境
本文的实验环境及配置如表2 所示.

表2 实验环境配置Table 2 Experimental environment configuration
4.2 数据集
本文采用英文和中文两种语言中公开评测的情感分析数据集:1)SemEval20173http://alt.qcri.org/semeval2017/task4/index.php?id=data-and-tools#是SemEval 在2017 年语义评测比赛任务4 中子任务A 的数据集(英文),共有20632 条数据,包含三种情感极性:neutral、negative、positive;2)NLPCC20144http://tcci.ccf.org.cn/conference/2014/dldoc/evsam2.zip,5http://tcci.ccf.org.cn/conference/2014/dldoc/evtestdata2.zip是NLPCC 在2014 年情感评测任务中的公开数据集(中文),来自新浪微博,每条微博都对应一个情感标签,共有8 类标签,将情感标签 none 视为 neural;happiness 和 like 视为 positive;其余五类视为negative,将8 类标签分成3 类:中性、积极、消极.删除其中为空的两条内容,最终有13998 条数据.数据集中三个情感类别的统计信息如表3 所示.
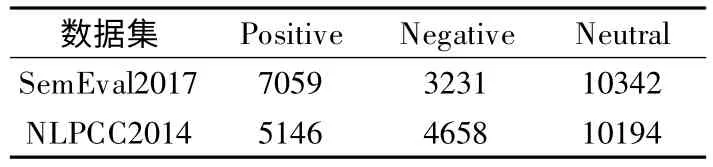
表3 数据集的统计信息Table 3 Statistics of the datasets
4.3 实验步骤
4.3.1 预处理
1)使用正则表达式去除 http 链接、@+用户名、#+主题;
2)分词及词性标注:英文数据集使用自带的Tokenizer进行分词,并使用NLTK 工具包进行词性标注;中文数据集使用jieba 分词工具对文本进行分词及词性标注;
3)去除停用词:英文数据集采用NLTK 工具包自带的停用词表去除文本中的停用词,并将英文数据集中的单词统一转为小写;中文数据集采用哈工大停用词表去除文本中的停用词.
4.3.2 向量化
1)英文词向量采用Pennington等人[21]提出的Glove词向量,词典大小是1.9MB,其中每个单词对应一个向量,向量大小为300 维;
2)中文词向量采用Chinese Word Vectors6https://github.com/Embedding/Chinese-Word-Vectors.[22]在大型微博语料库上使用Word2vec 进行训练而得到的分布式词向量,向量大小为300 维;
3)在Glove 词向量中根据词性名称找到词性对应的向量,向量大小为100 维;
4)根据emoji2vec7https://github.com/uclmr/emoji2vec.[23]中的方式得到每个情感符号对应的向量,向量大小为300 维;
5)将积极标签、消极标签和无情感标签分别转为positive、negative 和neutral 对应的分布式向量,向量大小为300 维.
6)对于以上未找到的词向量、词性向量和表情符号向量,采用均匀分布U(-0.01,0.01)来随机初始化词向量.
4.3.3 超参数设置
本文实验采用十折交叉验证,并采用网格搜索对不同的参数组合进行验证,根据评价指标选择最好的超参数取值,如表4 所示.

表4 实验参数设置Table 4 Hyper parameters of experiment
4.4 模型对比
将本文提出的模型和以下7 种对比模型分别在中文和英文数据集上进行实验,验证本文模型的有效性和鲁棒性.
1)MNB 模型(multinomial naive Bayes,MNB)[24]:作为传统机器学习的代表,MNB 在短文本情感分析中取得较好的分类结果.
2)CNN 模型:基于 Kim[11]提出的 CNN 模型,是最基础的卷积神经网络.
3)LSTM 模型[4]:使用最简单的 LSTM 模型,用于与CNN 在分类性能和训练时间上进行对比.
4)EMCNN 模型[14]:EMCNN 将基于表情符号的情感空间映射与多通道CNN 结合,对多个窗口大小内的词向量执行语义合成操作,增强了捕捉情感语义的能力,在多个不同的情感数据集上都取得了很好地分类性能.
5)MCCNN 模型:文献[5]提出多通道卷积神经网络模型,该模型利用词特征、词性特征、位置特征构建四种特征组合以形成不同的网络输入通道,取得了比普通CNN 更好的分类结果.
6)DC-CNN(Double-channelCNN)模型:只考虑词特征和词性特征,将词特征、词特征+词性特征两种特征输入到双通道卷积神经网络中,与本文的MF-MCNN 模型对比,同时检验情感符号和情感标签特征在情感分类中起到的作用.
7)EDC-CNN(Emoticons enhanced DC-CNN)模型:在本文提出的模型MF-MCNN 中去除标签向量特征,与DC-CNN模型对比检验情感标签特征在分类结果中起到的作用,与MF-MCNN 对比检验情感标签特征在分类结果中起到的作用.
8)MF-MCNN 模型:本文提出多特征融合的多通道卷积神经网络模型.
4.5 实验结果与分析
4.5.1 情感三分类任务
本文使用8 组模型在SemEval 2017 和NLPCC 2014 数据集上进行实验,分析文本的情感极性,由表3 可知,三种情感类别的数量不均衡,为了不影响最终的分类结果,本文选择数据集中每种类别最少的数量作为每个类别参与实验的数量,如表5 所示.

表5 平衡数据集统计信息Table 5 Statistics of balanced datasets
表6 给出了8 组模型在2 个数据集上的对比结果.实验采用准确率Accuracy 作为评价指标.
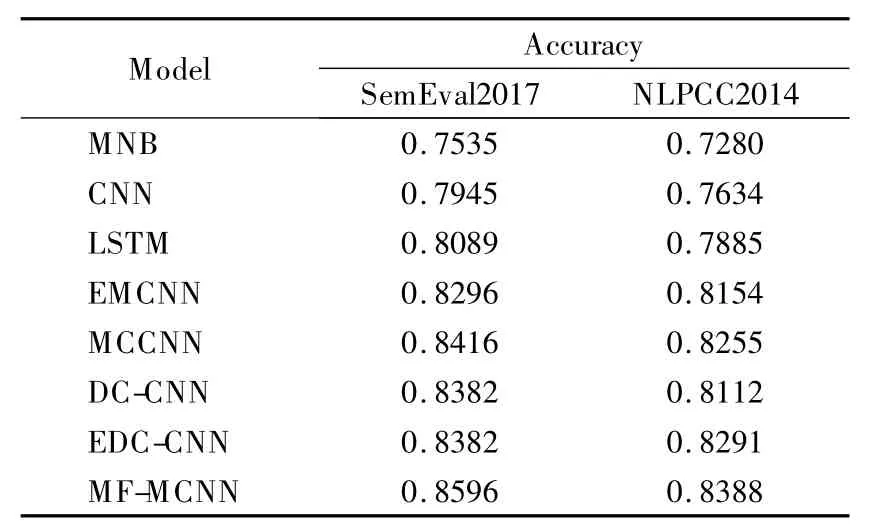
表6 不同模型在2 个数据集上的实验结果对比Table 6 Accuracy comparison of different models in two datasets
由表6 可知,本文提出的MF-MCNN 模型在中文和英文数据集都取得了最好的情感分类准确率.很显然,各个模型中英文数据集比中文数据集的分类效果都要好,说明英文文本比中文文本更易于进行情感分类.另外,本文选取的英文数据集不含表情符号,由于表情符号以词语的形式包含在句子中,当短文本中不含情感符号时,模型只是没有提取到表情符号,并不需要修改模型,验证了本文模型的灵活性,便于在实际场景中使用.
在SemEval 2017 数据集中,MF-MCNN 模型比最好的MCCNN 模型提高了1.8%,由于该数据集中没有表情符号,所以DC-CNN 和EDC-CNN 相当于一个模型,它们提取的特征少于MCNN,导致分类结果低于MCNN,由于都少了情感符号的特征信息,EMCNN 此时的特征提取能力也有所下降,低于DC-CNN 和EDC-CNN 模型的分类性能.MF-MCNN 与DC-CNN 和EDC-CNN 高2%,验证了情感标签特征起到了比MCCNN 中位置特征更加重要的作用.
在NLPCC2014 数据集中,MF-MCNN 模型比最好的MCCNN 模型提高了1.33%,该数据集中含有表情符号,EDC-CNN 的分类结果优于 DC-CNN、EMCNN 和 MCCNN 模型,说明本文提取的情感符号特征增强了情感分类的性能.MF-MCNN 与DC-CNN 和EDC-CNN 的对比验证了同时添加情感符号特征和情感标签特征比单独采用两者之一在分类结果上作用更大.验证了本文方法在短文本情感分类任务中的有效性.
4.5.2 情感二分类任务
为了进一步验证本文模型的分类效果,接下来只保留表5 中SemEval2017 和NLPCC2014 中的积极和消极样本,在8个模型上的实验结果如表7 所示.实验采用准确率Accuracy作为评价指标.

表7 不同模型在2 个数据集上的二分类实验结果对比Table 7 Accuracy comparison of different models in two datasets ignoring all neutral instances
从表7 可以看出在去除中性极性数据之后,8 组实验的情感分类正确率都有了明显的提高,同时验证了英文数据集在二分类任务中依然优于中文数据集,MF-MCNN 在英文数据集上取得了最好的结果,为89.96%.说明中性数据比正负向数据具有更大的识别难度.在SemEval2017 数据集中,MFMCNN 模型比最好的 MCCNN 模型提高了 1.73%,在NLPCC2014 数据集中,MF-MCNN 模型比最好的MCCNN 模型提高了1.14%.EDC-CNN 比 EDC-CNN 高出近2%,说明情感符号在正负极性二分类中起到了更强的分类作用.MFMCNN 与DC-CNN 和EDC-CNN 的对比验证了情感符号特征和情感标签特征在二分类中起到了更强的情感提升作用.
上述实验结果证实了多特征融合方法在英文和中文数据集的分类性能,多特征融合方法首先全面考虑到短文本中的多样化情感特征,其次采用多通道卷积神经网络充分提取并且保留了短文本的情感信息,与单一情感特征相比,情感信息的多样化能够更加全面的提取情感信息,对于判别文本的情感起到了关键作用.
4.6 训练时间分析
为了分析模型的时间性能,本文在相同的实验环境中完成所有对比实验,同时,所有实验采用相同的数据集和相同的词向量矩阵,表8 给出5 个主要模型在SemEval2017 数据集上进行正负二分类实验时完成一次迭代的训练时间对比结果.
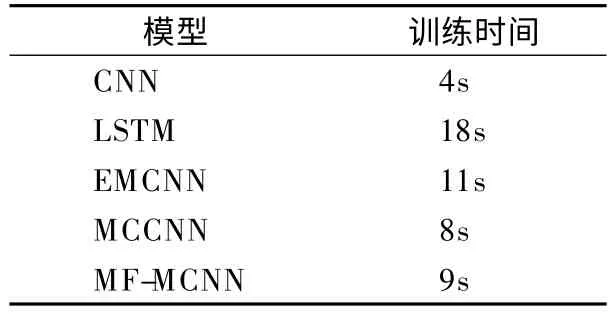
表8 完成一次迭代的训练时间Table 8 Runtime of training epoch
从表8 结果可以看出最简单的CNN 模型训练最快,完成一次迭代训练仅需4s,LSTM 网络的训练时间最久,这主要是因为CNN 能够并行输入文本数据,而LSTM 网络输入的是序列性数据,每一步都是相当复杂的运算操作,所以LSTM网络的训练时间远远大于 CNN.由于 EMCNN、MCCNN 和MF-MCNN 模型都以CNN 为核心模型,接收句子的平行化输入,所以训练时间大大缩短,另外,EMCNN 需要完成情感空间映射,增加了计算量,运行时间大于MF-MCNN 模型.MCCNN 模型与本文提出的MF-MCNN 模型都是对多个特征的并行处理,而本文模型增加了与不同情感标签结合的步骤,所以运行时间稍大于MCCNN.综上,MF-MCNN 模型有效地降低了模型训练的时间.
5 结 论
本文针对中文微博和英文Twitter 的短文本展开研究,提出一种基于多特征融合的短文本情感分析模型MF-MCNN.该模型采用多通道卷积神经网络从多输入特征中学习和提取更全面的情感语义信息,因为不同特征结合除了形成新的特征之外,也让特征之间相互联系和影响.此外,将文本特征与标签特征进行匹配,有效利用文本和标签中蕴含的情感信息以及它们之间的联系.实验结果表明,本文提出的模型在中文和英文数据集上均取得了比对比模型更好的分类性能.同时,由于本文模型的核心网络是卷积神经网络,在一次训练过程中完成对不同通道特征的学习和参数调整,大大降低了模型的训练时间.
研究发现,中文数据集的分类结果始终低于英文数据集,下一步将探究其原因以及如何改进模型以提高中文数据集的分类性能.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年11期)2015-11-09
