
半监督元路径的异构信息网络社区发现算法
2020-06-05 12:17陈丽敏
小型微型计算机系统 2020年6期
陈丽敏,张 岩,杨 柳
(牡丹江师范学院计算机与信息技术学院,黑龙江牡丹江157011)
1 引 言
异构信息网络非常普遍,如社会信息网络、书目网络、医疗信息网络等.异构信息网络能够真实地反映现实世界,分析异构信息网络能够更好地理解网络的隐藏结构以及每个社区数据所代表的角色[1,2].
异构信息网络社区发现算法是研究异构信息网络的基础,基于语义相似性度量的异构信息网络的社区发现算法是主流[3,4],其中,语义相似性度量大多数是基于元路径计算的,比较典型的基于元路径的相似性度量有PathCount 和PathSim[5]及 JoinSim[6].但是,基于元路径的目标对象的相似性度量,其语义表达并不完整,不能真实地反映目标对象的关联,而目前又缺乏更加准确地表达目标对象相似性语义的方法.受其影响,异构信息网络社区发现的准确度不高.基于语义的异构信息网络社区发现算法往往忽略了异构信息网络复杂的拓扑结构,从拓扑结构的角度分析异构信息网络[7,8],能够掌握数据分布的整体结构.半监督方法能够提高社区发现的准确率[9,10].本文将二者有机结合,通过谱聚类分析异构信息网络的拓扑结构,半监督校正目标对象的相似性,能够有效提高异构信息网络社区发现的准确率.
因为谱聚类能够捕获数据分布的整体结构,而且非负矩阵分解NMF 方法和谱聚类方法都有可靠的理论支撑,所以本文使用这两种方法来分析异构信息网络的社区,提出半监督算法(Semi-Supervised Meta-Path-based Algorithm for Community Detection in Heterogeneous Information Networks SMpC).SMpC 算法由两部分组成.首先,使用谱聚类算法SRC[8]获得目标数据集的整体分布情况,并选取每个类中的代表对象,构建先验信息.然后,基于元路径计算目标对象的相似度,使用先验信息校正目标对象的相似度,并采用NMF 方法划分目标对象,发现合理社区.
2 基于元路径的相似性度量
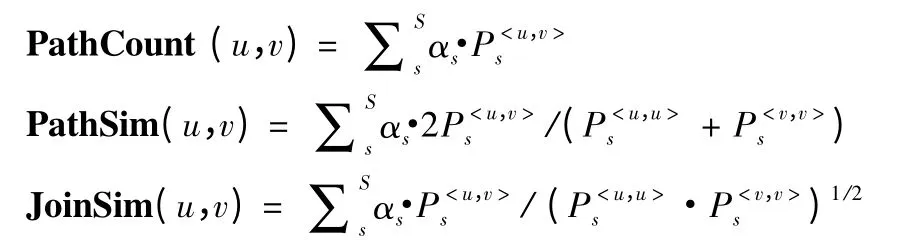
PathCount 为两个目标对象的加权路径总数,该方法偏向于高度可见对象.为了捕捉到对等对象的相似性语义,Path-Sim 使用两个目标对象的循环路径数的算数平均调整加权路径总数,JoinSim 使用两个目标对象的循环路径数的几何平均调整加权路径总数.
3 基于拓扑结构的异构信息网络划分
从拓扑结构角度,基于相容二部图的思想能够有效分析多种异构数据之间的复杂关系,其中,谱聚类算法SRC 从相容的角度解决了多种异构数据协同聚类的问题.SRC 方法给出了一个通用模型,能够处理任何结构的异构信息网络.该方法能够对各种数据对象同时聚类,把各种类型数据对象映射到低维空间,因此,各种类型数据对象隐藏的结构很容易被发现.

其中,‖·‖表示矩阵的 Frobenius 范数,C(p)∈{0,1}np×Kp,当 L 最小时,则 C 为最佳指示矩阵.通常令指示矩阵C(p)满足
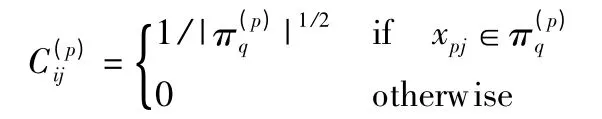
当异构信息网络结构比较复杂,不同类型的数据集之间的关系矩阵W(pq)的数量将非常多,这将导致SRC 算法的计算量过大.因此,本文选择星型模式的网络结构[7,10]来分析目标对象的整体分布.星型模式的网络结构是指目标数据集与属性数据集存在关系,而属性数据集之间不存在关系.即只分析关系矩阵{W(1q)∈Rn1×nq}1≤q≤T,则(1)式可表示为:
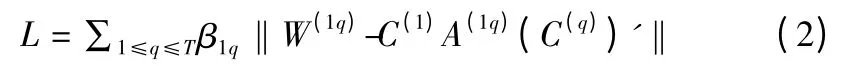
其中,β1q是关系矩阵 W(1q)的权重,∑β1q=1,β1q>0.整理(2)式,L 可表示为:

其中,tr 是矩阵的迹.L 最小,则aL/aA(1q)=0.那么,A(1q)=(C(1))'W(1q)C(q),代入(3)式,因为(C(q))'C(q)=I,tr(W(1q)(W(1q))')是常量,所以,当 min(C(q))'C(q)=IL,即
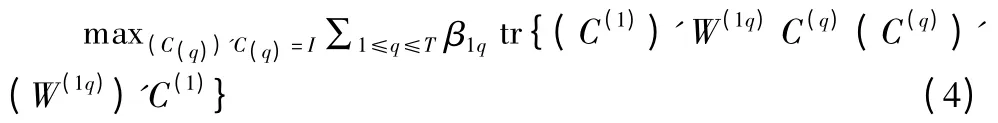
求解(4)式最大值是NP 难问题.通过迭代方法能够计算(4)式的极大值.首先给定T-1 个指示矩阵C(i),使得
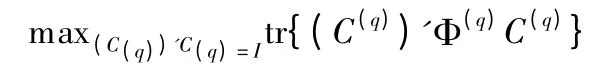
其中

从而,确定最优指示矩阵 C(q),1≤q≤T,q≠i.

4 半监督异构信息网络社区发现算法
4.1 先验信息的确定
确定先验信息就是在目标数据集中选取代表对象,并构造先验信息矩阵.因为无法直接计算异构信息网络目标对象之间的距离,所以,将目标对象映射到低维空间,计算各指示对象之间的距离.根据指示对象间的距离,则可以基于密度方式筛选代表对象.
设目标数据集X1共划分 K1个类,给定阈值 δ.首先,使用算法1 将X1映射成指示数据集C(1),并将C(1)划分为K1个类;在C(1)的第k 个类Ck(1)中随机选取一个种子cu(k),1≤k≤K1,指示对象 cu(k)对应的目标对象xu(1)作为代表对象.
令 Z∈Rn1×n1是 X1的先验信息矩阵,给定 zuv∈Z,如果目标对象xu(1)与xv(1)属于同一个类的代表对象,则zuv=1,否则zuv=0.
每个类中选择距离大于δ 的指示数据对应的目标对象作为代表对象,这些代表对象能够把拓扑结构上相关联而语义上关系较弱的数据连接起来,从而能够校正基于元路径的语义相似度的倾斜或不完整.
4.2 SMpC 算法
使用先验信息校正目标对象基于元路径计算的相似度,以改进目标对象语义相似性的缺失或不完整.首先,基于元路径计算目标对象的相似矩阵H,正则化相似性矩阵H 和先验信息矩阵Z.然后,使用先验信息矩阵Z 校正相似矩阵H,校验矩阵为aH+bZ,其中,a+b=1.校验矩阵能够更合理地表达目标对象的关系,在其上使用NMF 方法能够得到更加合理的社区.具体算法如下:

SMpC 算法既考虑到目标对象在拓扑结构上的相关性,又考虑到目标对象在语义上的相关性,因此,目标对象的相似性度量更合理,从而使得划分的社区更合理.而SMpC 算法的两部分采用的SRC 算法和NMF 算法都具有可靠的推理,所以使用这两种算法划分的社区准确率相对更高.另外,SMpC算法半监督过程不需要人为干预.SMpC 算法中第1 步将目标数据集X1映射成指示数据集C(1),涉及到特征向量的计算,采用近似计算矩阵特征向量方法,能够将算法复杂度从O(n3)降到近似 (n2).第2 步-第12 步确定指示数据集每个类的种子,也即目标数据集的代表对象,计算复杂度为O(n2).第13 步-第18 步计算校验矩阵aH+bZ,计算复杂度为O(n2).第19 步 NMF 分解计算复杂度为 O(n2).所以,SMpC算法的计算复杂度近似 (n2).
5 实 验
5.1 实验数据
从DBLP 选取真实数据建立实验数据集,DBLP 是一个典型的异构信息网络,其中包括4 种类型数据对象,分别命名为 papers,authors,terms 和 venues.抽取一个小数据集 Ss,即文献[11]使用的称为“four-area dataset"的数据集.小数据集Ss选取了4 个学术区域,这4 个区域为:database,data mining,information retrieval 及 machine learning.每个区域取 5 个有代表性的会议,共20 个会议,20 个会议的所有authors,papers 及出现在论文题目中的所有terms.
本文又抽取了由中国自动化研究所提供的中国DBLP 数据集作为另外一个测试数据集,这个大的数据集称为Sl.该数据集包括34 个计算机科学期刊,2,671 个 papers,4,576 个 authors 及 4,962 个 terms.
5.2 参数 b 分析
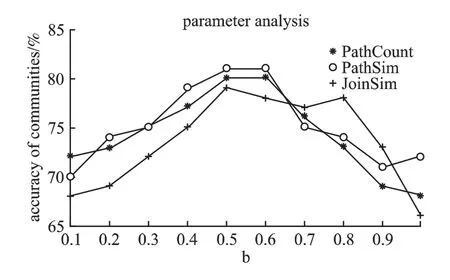
图1 以papers 为目标对象的参数b 分析Fig.1 Parameter analysis for papers in Ss
本实验分别选用 PathCount、PathSim 和 JoinSim 计算目标对象的语义相似性,构造相似矩阵H.a 是相似矩阵H 的系数,b 是先验信息矩阵 Z 的系数,且 a+b=1,0≤b≤1.b 分别取 0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0,则相应的参数 a 分别为 1.0,0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2,0.1,0.使用小数据集Ss分析参数b 对实验结果的影响.参数b 对目标对象papers 划分结果的影响如图1 所示,参数b 对目标对象authors 划分结果的影响如图2 所示.从图1 和图2 可以看出,b 取值过小或过大,社区发现的准确率都不高,当0.4≤b≤0.6 社区发现的准确率较高.图1 和图2 也说明了参数b的鲁棒性较好.以下实验参数b 均取值b=0.5.

图2 以authors 为目标对象的参数b 分析Fig.2 Parameter analysis for authors in Ss
5.3 先验信息比率分析
参数δ 的选取,直接决定代表对象的数目,也即一个类中先验信息的百分比.使用小数据集Ss分析先验信息的比率对目标对象papers 划分结果的影响,取5 个不同的δ,获得papers 先验信息的比率分别为 10.7%、22.1%、39.4%、53.4%、60.8%.取 b=0.5,结果如图3 所示.
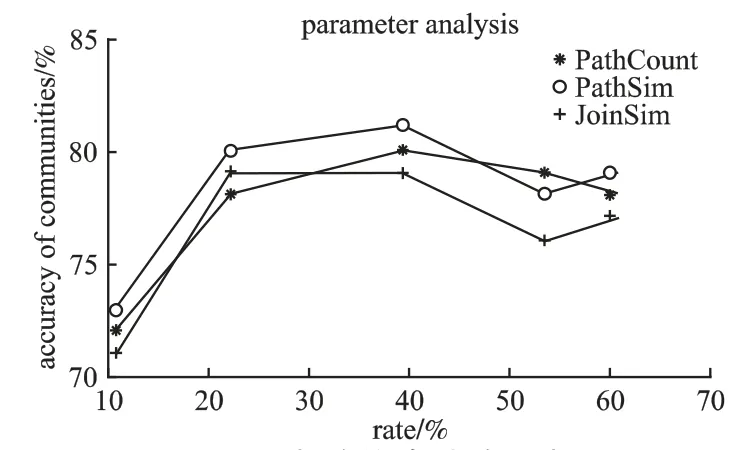
图3 先验信息比率分析Fig.3 Prior information analysis
先验信息率的选取与异构信息网络的结构关系紧密.如果代表对象能够比较好的刻画出所在类的整体结构,就能够很好地提高准确率,如果代表对象过多,则会降低语义的作用,也会降低准确率.因此,代表对象的比率20%-50%之间即可.
5.4 准确率对比
本次实验分别对数据集Ss和Sl的authors 和papers 作为目标对象进行分析.首先使用PathCount 计算目标对象相似性,使用NMF 方法对目标对象划分,社区发现的准确率如表1 中的第2 列所示;然后使用本文算法SMpC 对目标对象相似性进行校验,其相应的社区发现准确率如表1中的第3列所示.以此类推,分别使用PathSim 和JoinSim 计算目标对象相似性,使用NMF 方法对目标对象划分,社区发现的准确率如表1 中的第4 列和第6 列所示;然后使用本文算法SMpC,其相应的社区发现准确率如表1 中的第5 列和第7 列所示.表1 的实验结果说明本文算法SMpC 社区发现的准确率有明显提高.说明本文算法能够有效提高异构信息网络社区发现的准确率.
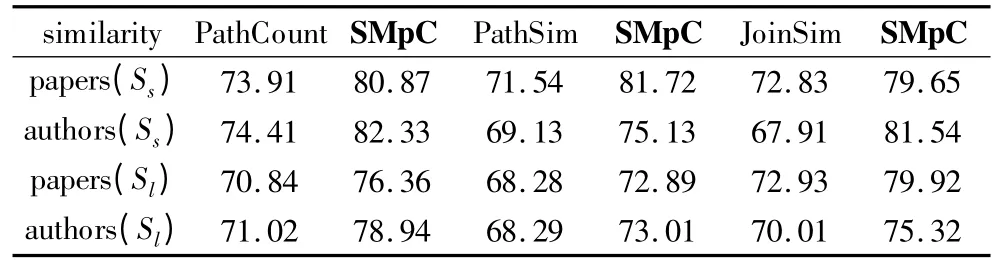
表1 社区准确率比较(%)Table 1 Comparision of community Accuracy(%)
6 结 论
由于使用了先验信息关联矩阵,有效校正了基于元路径的语义相似性缺失或不健全造成的异构网络划分的偏颇或倾斜.因此,本文SMpC 算法能够有效提高异构信息网络社区发现的准确率.而且本文的半监督算法不需要人为干预调控,提高了算法的自适应性.但是,由于需要分析异构信息网络的拓扑结构,增加了算法的计算复杂度,处理大数据的能力不足,下一步在保证社区发现准确率的前提下,研究降低算法复杂度.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
社会科学战线(2022年1期)2022-02-16
现代英语(2021年18期)2021-11-22
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
福建基础教育研究(2019年11期)2019-05-28
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
