
多指标核心作者识别方法研究
2020-07-09 03:40张子婷郑彦宁袁芳
现代情报 2020年7期
关键词:熵值法
张子婷 郑彦宁 袁芳
摘 要:[目的/意义]将无偏指标引入评价体系对某一研究领域的核心作者进行准确识别。本文构建了一个研究领域规范化的引文影响力指标,提出了综合多指标的核心作者识别方法。[方法/过程]本研究基于Web of Science数据库,以某一研究领域的学术论文为数据基础,利用普赖斯定律确定核心作者候选人,综合发文量、被引频次、h指数以及研究领域规范化后的引文影响力4个指标,利用综合指数法和熵值法确定每位学者的最后得分,将高于100分的学者确定为该研究领域内的核心作者。[结果/结论]最后,利用上述方法在DNA计算领域进行了应用分析,按照综合得分k>100的标准遴选出DNA计算领域的32位核心作者。
关键词:核心作者;识别方法;引文影响力;综合指数法;熵值法
DOI:10.3969/j.issn.1008-0821.2020.07.015
〔中图分类号〕G250.252 〔文献标识码〕A 〔文章编号〕1008-0821(2020)07-0144-08
Research on Multiple-Indicators Method on Identifying the Core Authors
Zhang Ziting Zheng Yanning* Yuan Fang
(Institute of Scientific and Technical Information of China,Beijing 100038,China)
Abstract:[Purpose/Significance]An unbiased index was introduced into the evaluation system to accurately identify the core authors in a research field.This paper constructed a research field normalized citation impact index,and proposed a multiple-indicators method on identifying the core author.[Method/Process]Based on the Web of Science Core database this research,used articles of a research field as data basis.This paper used Price law to determine core author candidates.Based on the statistic data of quantity,cited frequency of papers,h-index and research field normalized citation impact,the core authors were evaluated by comprehensive index method.And scholars whose scores were higher than 100 were determined as the core authors in this field.[Result/Conclusion]Finally,the above method was used to identify the core authors in the field of DNA computing,and 32 core authors in this field were selected according to the criteria of comprehensive score k>100.
Key words:core author;identifying method;citation impact;comprehensive index method;entropy method
作者是科學研究工作的主体,其科研能力直接决定着科研产出的数量和质量[1]。核心作者是指那些在各学科领域造诣较高、学术活动较频繁、发表论文较多且影响较大的作者。他们在学科中发挥着导向作用,不断将学科研究推向新的纵深[2]。对于领域内的研究人员,关注高水平学者的科研成果是快速把握前沿研究内容的重要方法之一。对于领域内的期刊,也可面向核心作者组约优秀稿件,提高期刊的学术水平。另外,对在某一研究方向上潜心科研多年的学者们的研究成果进行分析,可以发现该研究领域在某一研究方向上的主题演变过程。在这些过程中,准确识别研究领域内的核心作者显得尤为重要。需要特别指出的是,本文研究的核心作者是识别某一研究领域内有一定学术造诣及研究影响力的作者,并非确定某篇文章的多个作者中贡献较大的作者。
1 相关研究
目前已有一些利用综合指标确定核心学者的研究,主要应用于期刊层面。陈涛[3]从普赖斯定律、h指数和总被引频次3个方面来确定出《档案学研究》的核心作者。赵基明等[4]从作者单篇论文被引情况和作者全部论文被引次数两个角度测定《中国图书馆学报》的核心作者。钟文娟[5]利用普赖斯定律确定核心作者候选人并结合作者发文量和被引量两个指标运用综合指数法测定出《图书馆建设》的核心作者。胡臻等[1]运用普赖斯定律、综合指数法和期刊h指数等方法对《四川图书馆学报》2006-2015年核心与扩展核心作者进行分析。李智毅等[6]综合运用发文量、第一作者发文量、综合贡献度、高引作者、高被引论文等多重方法,系统分析了文献作者的影响力及其合作关系,从中识别出一批核心学者群体。许晶晶[7]利用CNKI 2004-2009年6年间建筑类图书所涉及的作者及其发文量、h指数、主题连续研究数,根据指标的重要性确定权重,最终遴选出Top100作为核心作者。此外,还有一部分研究着重对某一学科领域的核心学者进行挖掘,并基于此识别研究主题。Chien T W等[8]探讨作者的研究领域及个人影响因素与作者姓名排序之间的关系,利用基尼指数进行评价。Wang Q等[9]利用Insight软件进行作者网络分析,进一步解释了核心作者的贡献和趋势。支凤稳等[10]利用主观提取法确定国外馆藏数字资源语义化领域的核心作者列表和作者合著网络。徐健等[11]、江文华等[12]通过普赖斯定律分别识别情报学领域和图书馆学领域的核心作者,在此基础上进行社群划分并分别识别各社群研究主题。田文灿等[13]遴选出Altmetrics领域的23名核心作者,从微观层面上对这些核心作者的研究主题和方向进行演变分析。
研究指标选取方面,主要依赖发文量、总被引次数、篇均被引次数、h指数等,这些指标均未考虑文章发表年份、文献类型、学科领域等影响。例如,在某一研究領域内有两篇分别发表于2009年与2019年的文章,其被引频次均为10,但其引文影响力并不能简单等同。由于受到出版年的影响,出现两篇文章出现被引频次相同但引文影响力明显不相同的情况。目前已有的无偏指标主要有基于爱思唯尔Scopus数据库的学科规范化的论文影响力(Field-Weighted Citation Inpact,FWCI)和基于汤森路透Web of Science数据库的学科规范化的论文影响力(Category Normalized Citation Impact,CNCI)。这两种指标较可以排除出版年、学科领域与文献类型的影响[14],常用于考察机构、国家、个人等的论文影响力。在应用层面,主要是为期刊刊发和约稿提供支持。目前极少有研究对某一研究领域的核心作者进行识别。
2 研究方法
2.1 研究思路
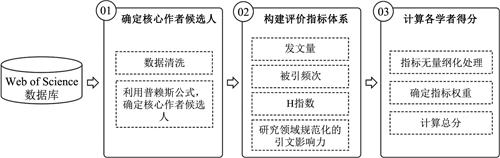
本文研究思路见图1。本文依据Web of Science数据库,以某一研究领域得到的学术论文为数据基础。对作者进行数据清洗后,利用普赖斯公式确定核心作者候选人,然后构建评价体系,最后确定权重、计算得分、遴选出研究领域内的核心作者。
在指标选取时,我们发现,被引频次虽可以衡量某篇论文的学术影响力,但是对于两篇被引频次相同的论文来说,发表年份、文献类型以及所处的学科领域不同都会导致其学术影响力并不等同。故本文除使用常用的发文量、被引频次、h指数这3个指标外,还构建了一个研究领域规范化后的引文影响力指标(Research Field Normalized Citation Impact,RFNCI),一定程度上排除出版年、文献类型、学科领域对被引频次产生的影响,具体指标定义见2.3。
在评价方法方面,本文采取综合指数法的无量纲化规则对4个指标进行无量纲化,利用熵值法确定各指标权重。得到权重后赋予每位学者一个综合评分,所得评分大于100分则表示其水平高于领域内的平均水平,确定其为核心作者。
2.2 确定核心作者候选人
为保证分析结果的准确性,本文采用DDA(Derwent Data Analyzer)软件消歧和人工校对相结合的方式对作者信息进行清洗[11]。首先将姓名相
同且作者一级单位相同的作者判定为同一作者,其次人工逐个分析姓名相同而单位不同的情况,查阅补充资料对这些作者进行处理。数据清洗完毕后,利用普赖斯公式(M=0.749Nmax)计算出核心作者候选人的最少发文量。其中M为最小论文发表数,Nmax为所数据集中最高产作者的发文量,发表论文数在M篇以上的作者即为核心作者候选人。
2.3 构建评价体系
本文选取发文量、被引频次、H指数以及研究领域规范化后的引文影响力4个指标。各指标的定义及优劣势如.:
1)发文量:指在某一特定研究领域中,某一作者的全部发文数量,记为Di。其中i为作者编号,.同。发文量体现学者在该领域的科研产出数量,但无法衡量科研成果的质量。
2)被引频次:某作者的全部发文的被引你频次总数,记为Ci。被引频次体现科研成果质量,反应论文的被使用和受重视的程度[15],但受发文量及高被引论文影响。
3)h指数:一位作者的h指数等于当且仅当其有h篇引文次数至少为h的论文,同时其余论文的引文数都小于h时的h值,记为hi[15]。h指数结合数量和质量两个方面综合分析学者的个人学术成就,用以评价学者的持续绩效。但是h指数仍存在以.局限:一是对低被引论文和高被引论文缺乏灵敏度;二是缺乏区分度;三是h值只升不降,无法反映学者的持续表现[3]。
(4)研究领域规范化的引文影响力(Research Field Normalized Citation Impact,RFNCI):该研究领域中的一篇文献的研究领域规范化的引文影响力(RFCNI)是通过其实际被引次数除以同文献类型、同出版年、同研究领域文献的期望被引次数获得的。其中,同文献类型、同出版年、同研究领域文献的期望被引次数(记为e)为该研究领域某一年所有的研究论文(Articles)总被引次数除以论文总数。
RFNCI是一个相对无偏的影响力指标,排除了出版年、学科领域与文献类型的影响。在某一研究领域中,如果RFNCI的值等于1,说明该(组)论文的被引表现与全球水平相当,如果RFNCI大于1表明该(组)论文的被引表现高于全球水平,否则低于全球平均水平。
2.4 指标无量纲化处理及权重确定
多指标系统的每一种评价方法,都面临着两个问题:一是按何种规则将每个指标无量纲化;二是以何种方式区分各指标的相对重要性[16]。本文采取综合指数法的无量纲化规则对4个指标进行无量纲化,利用熵值法确定各指标权重。
2.4.1 综合指数法
综合指数评价法是运用数学方法处理多重相关指标而得到的一个综合性指标的方法,用以较全面地反映事物总体变动方向和变动程度。综合指数法可以将多个不能同度量现象的数值,分别变换为能同度量数值。由于各评价指标的量纲、数量级及指标优劣的取向存在较大差异,在对这些指标进行合成之前必须进行标准化处理。采用统计学方法对指标进行处理,以消除多指标综合评价中计量单位差异和指标数量级、相对数形式差别[17-18]。
2.4.2 熵值法
熵是系统不确定性的度量,可以用于度量已知数据所包含的有效信息量和确定权重[19]。熵值法是一种客观赋权法,其根据各项指标观测值所提供的信息的大小来确定指标权重。在计算指标权重时,若某个指标中的各个数值之间变化不大,则该指标在综合分析中的贡献小,即权小,反之则权大[20]。由于该方法计算结果可信度较大,自适应功能强,故本文选取熵值法作为确定权重的方法。其主要步骤如.:
为了验证该方法的可行性,笔者利用检索式在Web of Science核心合集数据库中检索DNA计算领域的综述文章,选取了5篇综述类文章,将本文选取的核心作者名单与这5篇综述文章的参考文献作者进行匹配。这5篇综述类文章中,文献[22](2009,被引频次363)、文献[23](2019,被引频次34)、文献[24](2019,被引频次34)为领域内的高被引论文,另外选取了分别发表于2006年的文献[25](被引频次109)和2014年的文献[26](被引频次101)进行补充。经过匹配发现,32位核心作者中有26位作者的文献至少被这5篇文章中的一篇引用,一定程度上证明了本文研究方法的可行性及结果的准确性。
4 结 论
本文首先根据普赖斯定律确定核心作者候选人集合,然后构建基于某一特定研究领域的无偏评价指标RFNCI,综合发文量、总被引次数和H指数等多个指标,利用综合指数法和熵值法对学者的学术贡献进行全方位评价。无偏评价指标在一定程度上减少了出版年、文献类型和研究领域对被引次数产生的影响,从更客观角度评价论文的影响力。本文在指标选取、权重确定均较为客观、科学。之后,利用本文提出的方法在DNA计算领域进行应用分析,从102位核心作者候选人中遴选出32位核心作者,包括7位国内学者。综合得分位列前3的作者分别是Paun G、Shapiro Ehud和Adar Rivka;樊春海是国内学者中得分最高的学者;许进是发文最多的学者。结合各位作者在领域内所获得的成就,可以从侧面印证本文研究方法的可行性。
当然,本文仍存在一定的局限性。第一,对于作者的消歧目前的技术几乎无法做到完全精确,本文也不例外;第二,虽引进一定程度上消除出版年、文献类型、研究领域的影响的相对无偏的指标,但评价指标的设置方面仍未做到面面俱到。另外,检索式的制定过程虽力求完善但难免会出现部分文章未涵盖在内的情况。未来将朝着以.几个方向开展研究:1)核心作者对研究主题演化如何产生影响;2)如何在研究主题演化路径识别中体现核心作者的作用。
参考文献
[1]胡臻,龙兴跃.基于普赖斯定律与综合指数法的核心作者和扩展核心作者分析——以《四川图书馆学报》为例[J].四川图书馆学报,2016,(3):74-76.
[2]苏志芳,张建中,胡惠芳.基于模糊综合评判的中文社科图书“核心作者”决策研究[J].图书情报工作,2010,54(1):42-45,41.
[3]陈涛.基于CSSCI的《档案学研究》h指数和h衍生指数研究及核心作者的测定[J].甘肃科技纵横,2010,39(5):100-102.
[4]赵基明,舒明全.基于CSSCI的《中国图书馆学报》h指数及核心作者测定[J].中国图书馆学报,2008,34(2):98-102.
[5]钟文娟.基于普赖斯定律与综合指数法的核心作者测评——以《图书馆建设》为例[J].科技管理研究,2012,32(2):57-60.
[6]李智毅,杨晓春,吴广印,等.基于文献计量的军民融合文献核心作者分析[J].情报工程,2018,4(5):105-115.
[7]许晶晶.基于引文分析的核心作者研究--以建筑类图书为例[J].图书馆,2015,(5):89-92.
[8]Chien T W,Chow J C,Chang Y,et al.Applying Gini Coefficient to Evaluate the Author Research Domains Associated with the Ordering of Author Names A Bibliometric Study[J].Medicine,2018,97(39):11.
[9]Wang Q,Li R R.Research Status of Shale Gas:A Review[J].Renewable & Sustainable Energy Reviews,2017,(74)715-720.
[10]支凤稳,郑彦宁,杜薇薇.国外馆藏数字资源语义化研究现状分析[J].现代情报,2018,38(12):126-32.
[11]徐健,毛进,叶光辉,等.基于核心作者研究兴趣相似性网络的社群隶属研究——以国内情报学领域为例[J].图书情报工作,2018,62(12):57-64.
[12]江文华,徐健,李纲,等.基于研究兴趣相似性网络的我国图书馆学研究社群分析[J].现代情报,2019,39(9):21-27.
[13]田文灿,胡志刚,王贤文.科学计量学视角.的Altmetrics发展历程分析[J].图书情报知识,2019,(2):4-11.
[14]吴伟,姜天悦,余敏杰.我国高水平大学基础研究与世界一流水平的群体性差距——基于学科规范化的引文影响力分析[J].现代教育管理,2017,(4):18-23.
[15]崔建强,刘文娟.运动人体科学领域学者学术影响力分析[J].沈阳体育学院学报,2011,30(6):27-31.
[16]秦壽康.综合评价原理与应用[M].北京:电子工业出版社,2003.
[17]韩晓明,王金国,石照耀.基于主成分分析和熵值法的高校科技创新能力评价[J].河海大学学报:哲学社会科学版,2015,17(2):
[18]陈辉,林超辉,夏承鹏,等.基于PCA和综合指数法的高水平理工科高校科技成果转化绩效评价体系构建[J].科技管理研究,2019,(22):48-54.
[19]陆添超,康凯.熵值法和层次分析法在权重确定中的应用[J].电脑编程技巧与维护,2009,(22):19-20,53.
[20]戴西超,张庆春.综合评价中权重系数确定方法的比较研究[J].煤炭经济研究,2003,(11):37.
[21]Adleman L M.Molecular Computation of Solutions to Combinatorial Problems[J].Science,1994,266(5187):1021-1024.
[22]Pepke S,Wold B,Mortazavi A.Computation for ChIP-seq and RNA-seq Studies[J].Nature Methods,2009,6(11):S22-S32.
[23]Mergny J-L,Sen D.DNA Quadruple Helices in Nanotechnology[J].Chemical Reviews,2019,119(10):6290-6325.
[24]Simmel F C,Yurke B,Singh H R.Principles and Applications of Nucleic Acid Strand Displacement Reactions[J].Chemical Reviews,2019,119(10):6326-6369.
[25]Ezziane Z.DNA computing:applications and challenges[J].Nanotechnology,2006,17(2):R27-R39.
[26]Stojanovic M N,Stefanovic D,Rudchenko S.Exercises in Molecular Computing[J].Accounts of Chemical Research,2014,47(6):1845-1852.
(责任编辑:陈 媛)
