
基于万有引力改进的TextRank关键词提取算法
2020-07-13 12:56孙福权张静静刘冰玉姜玉山多允慧
计算机应用与软件 2020年7期
孙福权 张静静 刘冰玉* 姜玉山 多允慧
1(东北大学秦皇岛分校 河北 秦皇岛 066004)2(东北大学 辽宁 沈阳 110819)
0 引 言
文本文档可以由一个或多个简单而有意义的关键词来表示,通过关键词可以了解作者的写作意图。关键词提取技术在文本分类、文本摘要提取、文本聚类、情感分析、信息检索等领域发挥重要作用[1],且关键词提取在新闻以及其他领域均得到了较为广泛的应用。为此众多学者致力于关键词提取的研究[2-4]。Shrawankar等[4]结合自然语言处理的解析技术,采用关键字和关键短语组合的方法构造出合适标题,从而有助于读者减少阅读时间以获取完整想法。
现有的关键词提取算法主要包括基于无监督的学习模式和有监督的学习模式[5]。但是基于有监督的学习需要大量的、高质量的标注语料,耗费大量的人力物力。因此,目前无监督提取关键词的方法仍为主流方法,无监督方法是将提取任务转化为一个排序问题,从而克服训练语料库和领域偏差的关键挑战。其中基于词图模型、主题模型和TF-IDF词频统计的算法为关键词提取的主要算法。其中基于TF-IDF统计关键词简单易行[6],但是这种方法忽略了低频词、词语内部之间的语义关系和文本中主题关系的影响。TextRank算法[7]利用词语构成图模型,并根据词语之间的共现频率迭代计算得到关键词。该方法利用文本自身信息就可以获取候选关键词,具有简洁性,故本文采用该算法作为研究的基础算法。
原始的TextRank算法借助于转移概率对词语在文档中的权重进行测算,导致了将高频词汇作为关键词行为的发生。因此Biswas等[8]利用影响节点权重的不同参数,如词语的频率、位置、相邻关键词字的强度等,提出了一种新的基于无监督图的关键词提取方法,结果表明根据词语频率、位置等信息可以提升关键词的提取效果。Figueroa等[9]通过应用类似于反向传播概念的错误反馈机制,增强了基于图的关键词提取方法。然而,单纯地考虑文档外部结构无法完成对关键词的精准提取,还需要考虑文档内部的语义关系对文档的影响。Liu等[10]将传统的随机游走分解为针对不同主题的多组随机游走,并构建特定词图模型,以衡量不同主题下词语的重要性结合文档的主题分布,提取排名靠前的词语作为关键词。顾益军等[11]利用主题模型计算词语在文档中的主题影响度,将候选关键词的重要性按照主题影响力和邻接关系进行非均匀传递,构建词图模型。Wen等[12]对新闻稿件的关键词提取方法进行了研究,利用Word2Vec计算词语之间的相似度作为节点权重的转移概率,简单而有效地改善TextRank算法的性能。Qiu等[13]应用地质本身特性对基于深度学习的词分布模型Word2vec进行了更新,将领域背景信息进行了链接,识别了不常见但具有代表性的关键短语。以上文献在对关键词进行提取时仅考虑了词语的语义关系或者LDA主题影响度单一方面。为了更准确地对关键词进行提取,充分利用文档语义信息及结构信息,本文利用牛顿提出的万有引力公式对TextRank算法进行改进。通过计算词语之间的吸引力作为节点权重的转移概率,迭代计算得到文档中词语的排序,实现关键词的提取。
1 相关理论
1.1 Word2vec模型
Word2vec模型[14]是Mikolov等于2013年提出的,该模型可以通过浅层神经网络对语料进行训练,不需要人为干涉就可以把文档中的词语映射到向量空间,从而将每个词表征为K维的实数向量。这种方式得到的词向量具有语义关系,经典的式子就是king-man+woman=queen。Word2vec中的Skip-gram模型没有考虑到中文的语法,忽略了词的顺序。本文通过建立CBOW(continuous bag-of-words)模型,实现对词向量的获取。
CBOW模型根据词语所在文档的前后文内容,对当前词语的出现概率进行预测,当上下文出现时,对应的词w出现的概率应越大越好。在CBOW模型中,词向量属于附加物,词语的向量值处于循环往复的更新迭代过程中。CBOW模型包括输入层、投影层和输出层三个部分,如图1所示。
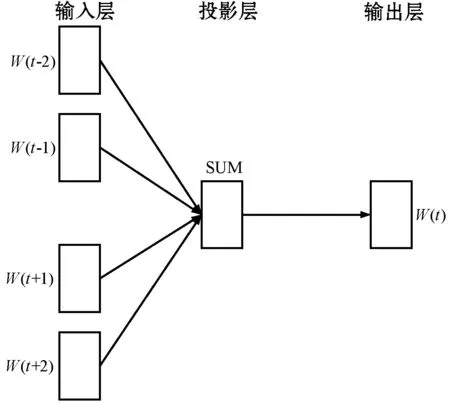
图1 CBOW模型
输入层为当前训练词语周围的词语对应的词向量,对应的词向量是通过对训练文档中所有词语去重后得到词语表,利用词语表获得的词语对应的one-hot编码。投影层对输入层中的词向量进行简单的求和操作。输出层对获取到的词向量,利用Softmax函数将输出层的神经元的值转化为概率,得到词语w。
1.2 计算词语的主题影响度
Blei等[15]提出了LDA主题模型,该模型属于无监督的贝叶斯模型,它可以将文档集中的每篇文档按照概率分布的形式给出。在LDA主题模型中,不同的文档具有K个隐含主题,隐含主题又由多个词语的多项式构成。在文档生成的过程中,能以一定概率获取不同的主题,从所获取的主题中,能够以一定概率提取到某个特征词[16]。隐含主题模型的概率图如图2所示。

图2 隐含主题模型LDA的概率图表示
图2中:φ(z)表示文档主题下词语概率分布;θ(d)表示文档主题的分布;α表示θ(d)的超参;β表示φ(z)的超参。假设一篇文档d由K个隐含主题的多项式表示,每个主题又由词w的多项式分布表示,则可以通过θ(d)和φ(z)来计算每篇文档中词语w的主题影响力[11],且w出现在主题下的概率越大说明其在该文档中更重要。文档d中词w的主题影响力为:
(1)
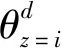
(2)
(3)
式中:num(d,z)表示文档d分配给主题z的频数;num(z,w)表示主题z分配给词的频数。
结合式(1)-式(3)可以得到词w在文档d下的主题影响力。
1.3 构建词的图模型
设图G=(V,E),V是顶点集合,E是边的集合。将文档词集合中的每个词看作图中的顶点V={w1,w2,…,wn}。图模型中的边是由文档中词语之间的共现关系得到。首先将新闻文档利用句号、问号、叹号等符号分句,然后对每句以特定窗口的大小滑动,计算词语与词语之间的共现频率。其公式如下:
(4)
式中:freq(i,j)是词语i、j在每句以特定窗口滑动时共现的次数;freq(i)、freq(j)分别是词语i、j在每句以特定窗口滑动时出现的次数。
2 基于万有引力的关键词提取算法
牛顿提出,任何物体之间都有相互吸引力,这个力的大小与各物体的质量成正比例,与它们之间的距离的平方成反比[17]。本文利用万有引力模型对TextRank算法进行改进,融合文档中词语的内部结构信息和词语之间的语义信息提出了GTextRank算法。该算法的核心思想是具有较强吸引力的词语可以对文本大致内容进行概括。
本文将文档中的词语象征性地表示为具有质量的物质,词语与词语之间具有相互吸引力,吸引力的大小用F表示。F与词语质量以及万有引力常数成正比,与词语之间的距离成反比,因此合理地表示词语的质量、万有引力常数和恰当的距离对准确刻画词语之间的吸引力具有重要作用。
在一篇文档中的词语的主题影响度越大则该词语在文档中相对越重要,文档中词语之间的关联度可以通过词向量之间的距离和词语的共现频率体现。词向量之间的距离越大,词语之间关联度越小;词语之间的共现频率越大,词语之间的关联度越大。因此,本文将词语在文档中的主题影响力作为词的质量,词向量的距离作为词语之间的距离,共现频率作为万有引力模型中的万有引力常数,则词语之间的引力公式为:
(5)
式中:Gc(i,j)表示词语之间的共现频率;M(wi|d)和M(wj|d)分别表示词语在文档下主题影响力;di,j表示词语i、j之间的词语之间的距离。
利用式(5)计算得出的词语之间的吸引力F作为词图模型中的转移概率,通过原始的TextRank算法迭代计算各图模型节点的权重。对应节点上的词语权重越大,词语越重要,从而得到有序的关键词序列。根据排序好的关键词序列得到指定数量的关键词。
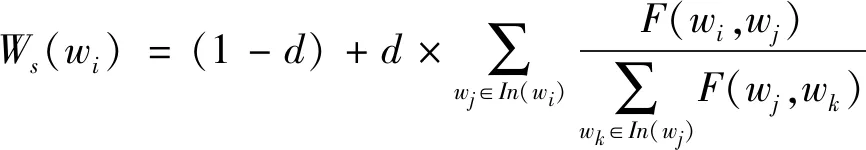
(6)
式中:Ws(wi)为词语wi的权重得分;In(wi)表示词语wi的共现词语集合;In(wj)表示词语wj的共现词语集合;d为阻尼系数,0≤d≤1,通常取值为0.85。
综上,该算法关键词的提取分为3步:(1) 对测试文档预处理(分词、去停用词等);(2) 基于万有引力模型对测试文档建模,计算两词之间的引力大小;(3) 通过式(6)迭代计算得到指定数量的关键词。提取步骤如图3所示。
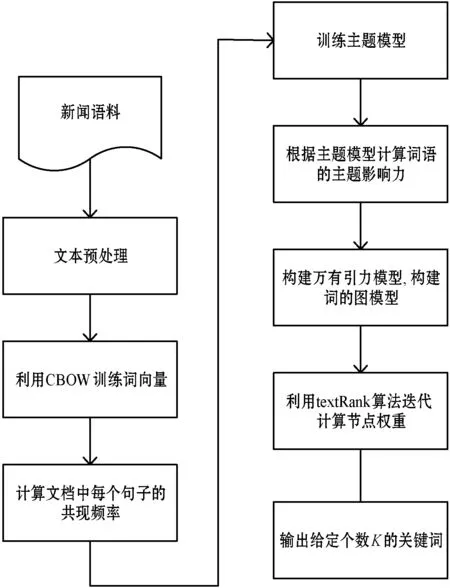
图3 关键词提取步骤
3 实 验
3.1 实验数据及评价指标
本文语料数据来源于搜狗实验室和复旦文本分类语料,囊括了体育、娱乐、军事和医疗等新闻数据,共1.54 GB。将以上语料作为Word2vec的训练集,选取50篇医疗新闻作为关键词提取的测试集。由于目前没有关键词的相关测试集,实验前,由多个语言学专业人员根据每篇文章内容的大小提取7~13个关键词。然后对每个人提取的关键词取交集得到文章的关键词并作为最终测试集对应关键词提取结果。实验在一台配置为Intel i5 2.27 GHz和8 GB内存的台式机进行,用Python自带的gensim中的Word2vec工具训练词向量,运行时间为14小时。实验的评价结果采用自然语言常用的评价指标:精确度(P)、召回率(R)和F。三种指标的计算公式如下:
(7)
(8)
(9)
式中:np表示抽取出正确关键词的个数;ne表示抽取出关键词的个数;nd表示文档中包含关键词的个数。
3.2 实验结果与分析
关键词提取准确度产生影响的参数主要为主题模型中拟主题个数以及关键词的个数。本文首先通过改变拟主题的个数,分析不同拟主题个数对关键词提取准确度的影响。同时,针对不同的关键词提取算法,通过改变关键词的个数,实现对关键词提取算法优劣性的对比,并总结拟主题的个数和关键词提取数量对GTextRank算法产生的影响。
首先改变拟主题个数对算法性能进行分析。实验中d取固定值0.85,其α=50/K(K为主题个数),β=0.01,迭代次数5 000次,提取关键词的个数为10。当TextRank算法中的差异值等于0.005时迭代停止。分别选取拟主题个数为5、10、15、20和25,对应的P、R和F的曲线如图4所示。
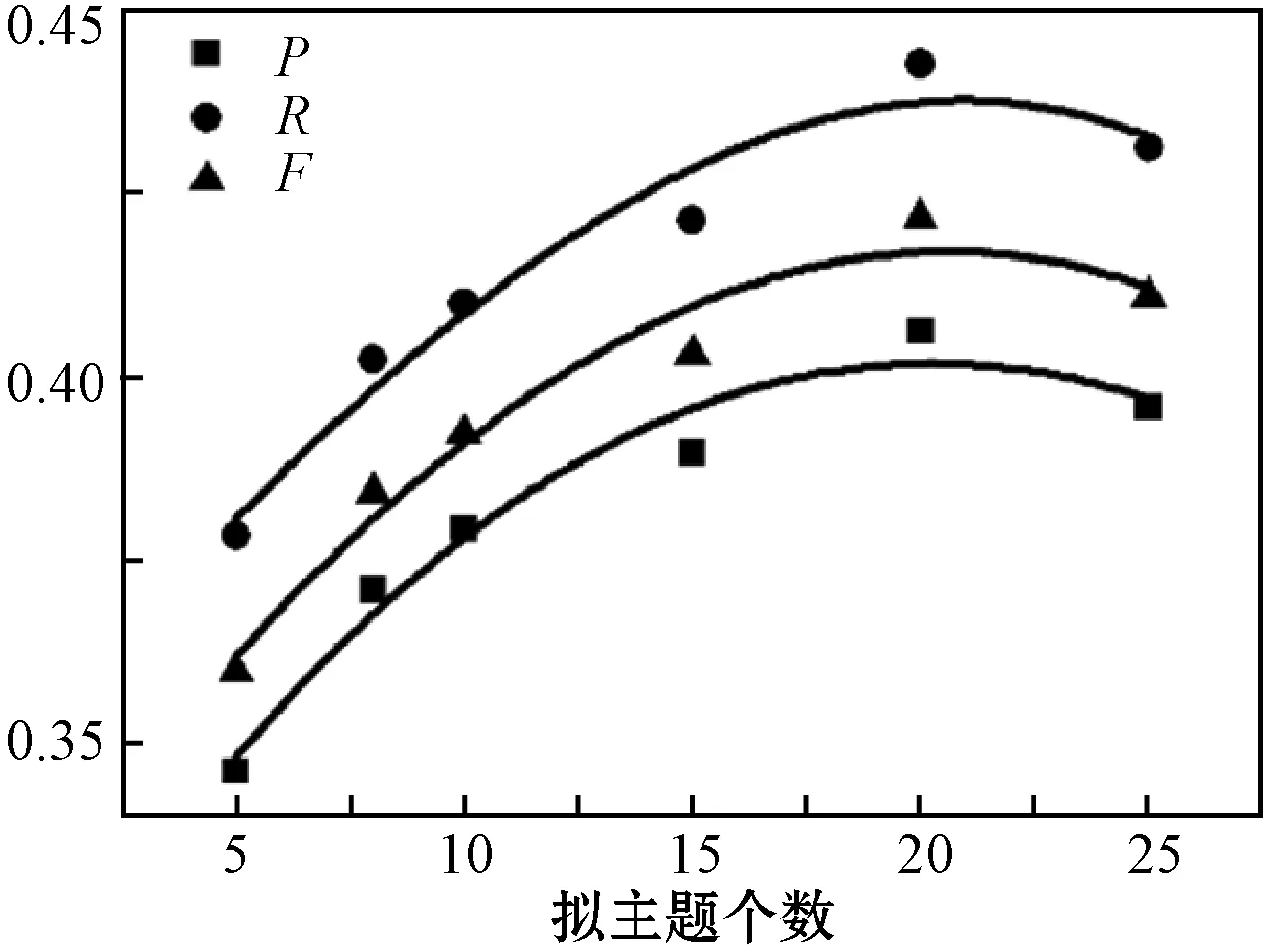
图4 不同个数拟主题P、R、F变化曲线图
可以看出,当主题个数较少时,效果较差,但是随着拟主题个数的增加,其关键词提取的准确度增加,当拟主题个数为20时结果最佳。实验结果表明,选取较为准确的主题个数是提高提取关键词的准确度的关键。由于实验数据集的主题性较强,本实验选取的都是医疗相关新闻,所以当拟主题个数较少时,也可以得到较好的结果。
实验中对比了4种不同的算法,分别是经典的TF-IDF算法、原始的TextRank算法、基于词向量改进的TextRank算法以及本文算法(GTextRank)。在不同提取关键词数量下对这4种方法进行比较,每种方法分别抽取权重最大的前5个词、8个词和10个词作对比。GTextRank算法中的主题数目为20,其他参数设置与不同个数据拟主题实验参数相同。对比结果如图5-图8所示。
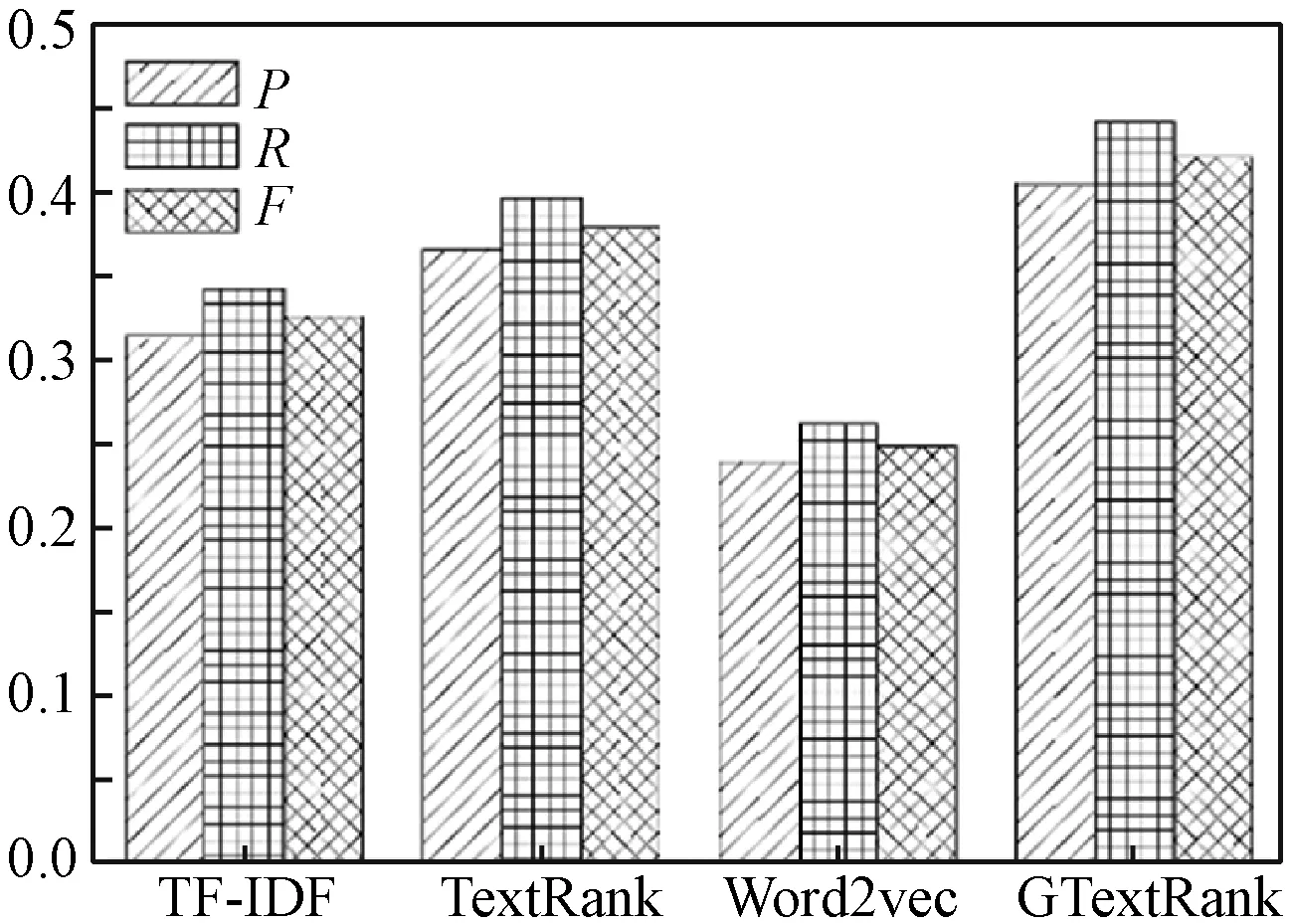
图5 关键词个数为5,不同算法的P、R、F
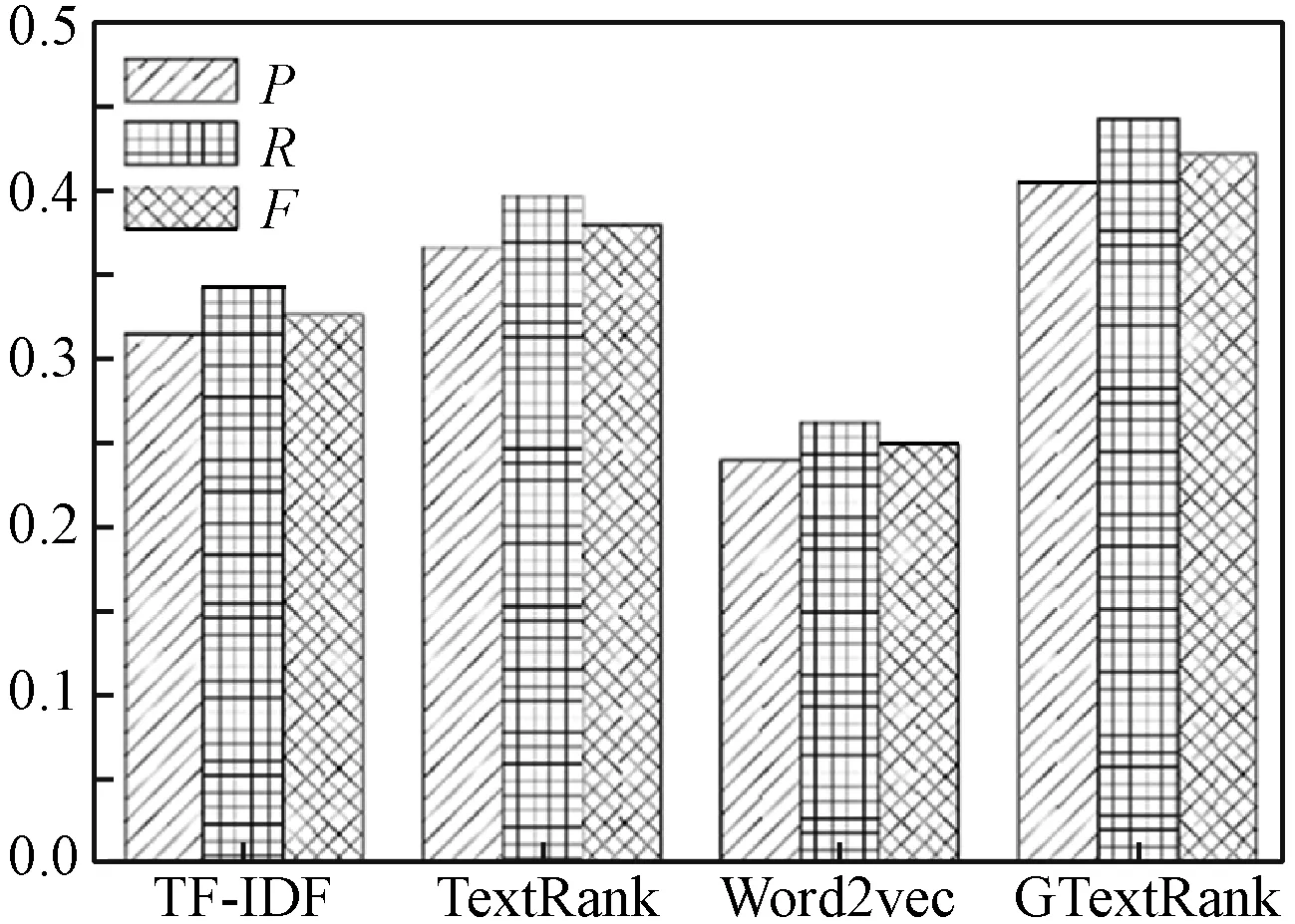
图6 关键词个数8,不同算法的P、R、F
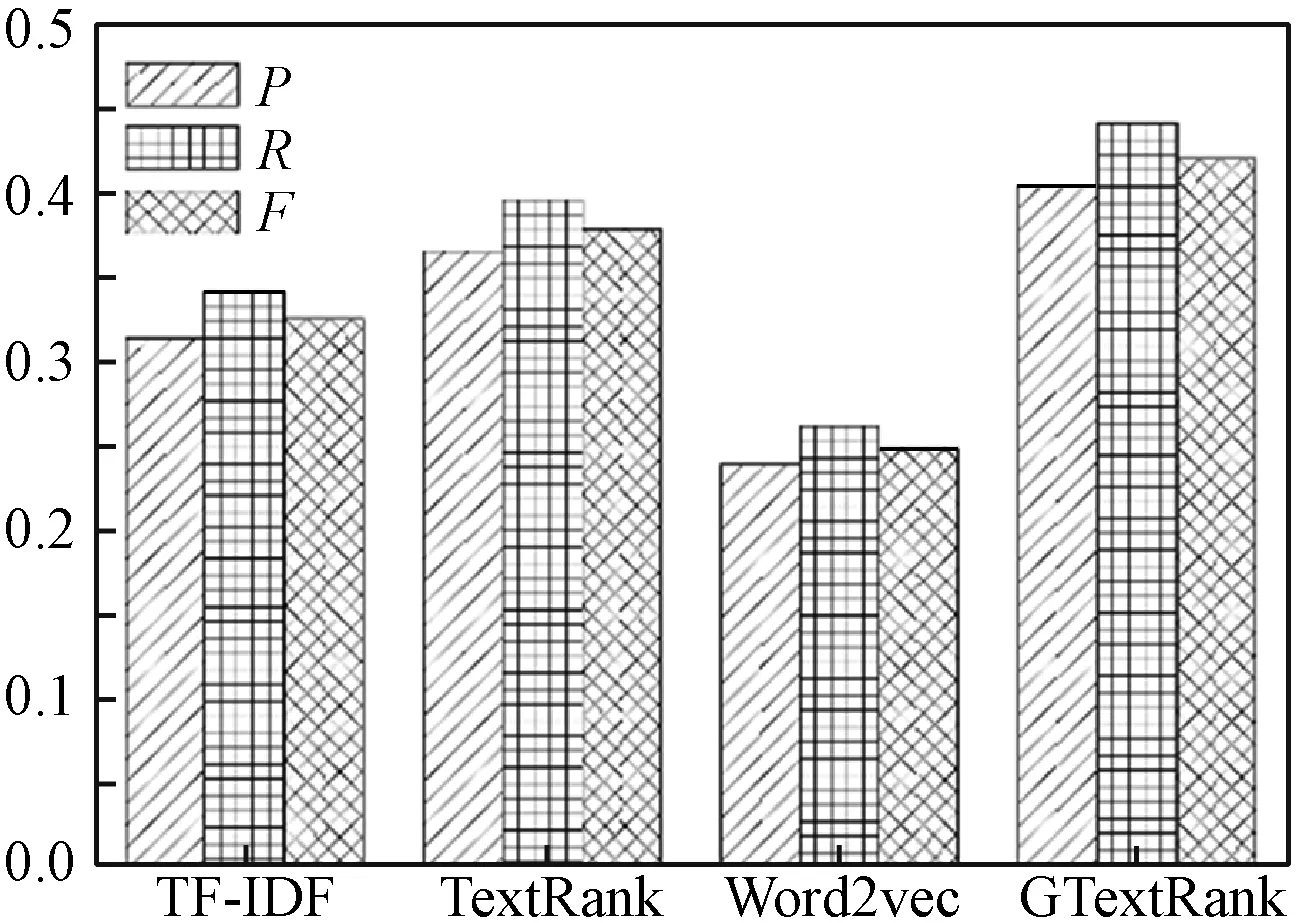
图7 关键词个数10,不同算法的P、R、F
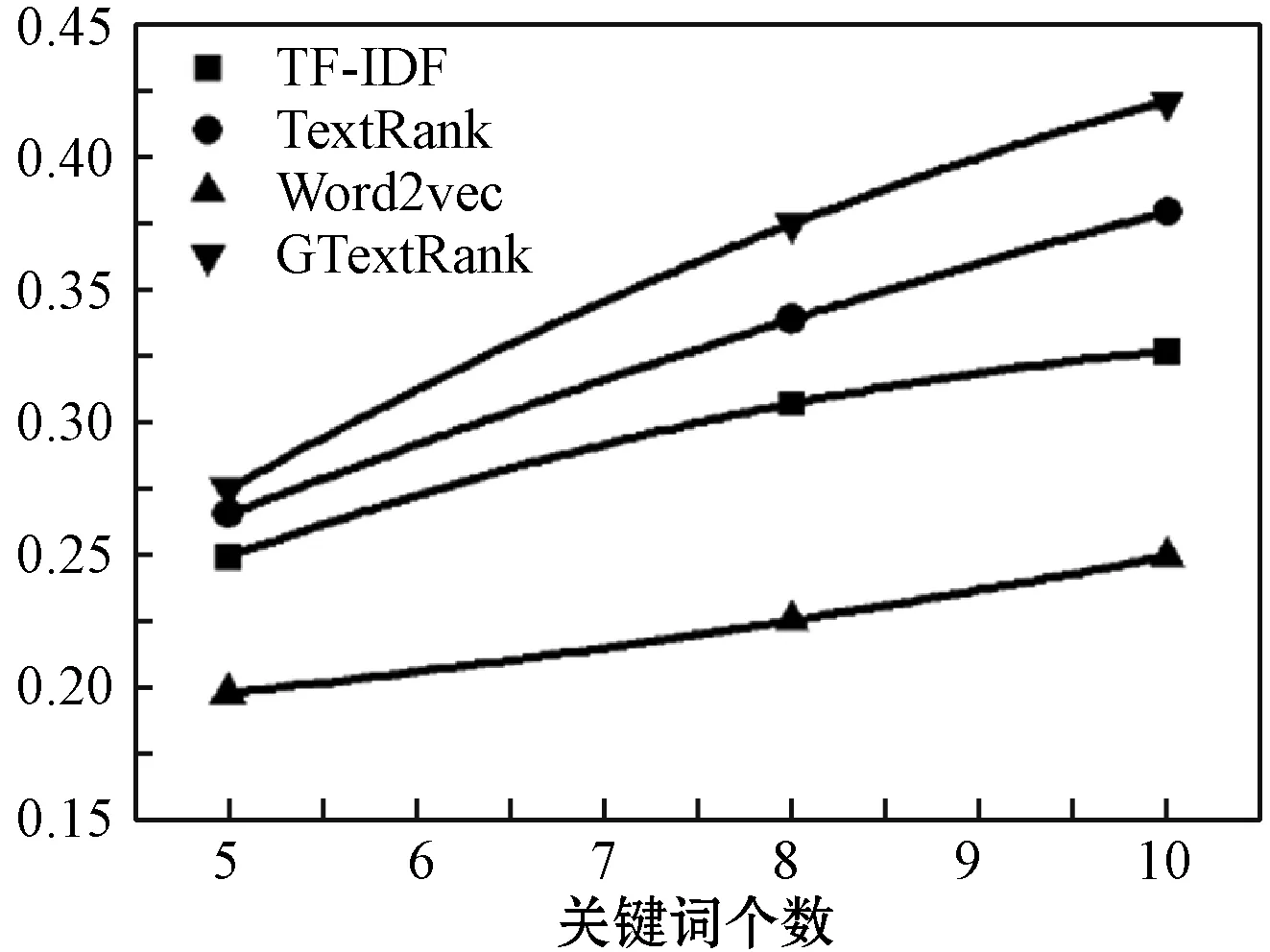
图8 F随关键词个数变化趋势图
可以看出,随着关键词个数的增加,所有方法的P、R和F都呈现上升趋势。相对其他方法,本文算法的提升效果较大。当关键词提取数量相同时,由于基于Word2vec改进的TextRank算法的实验效果取决于训练的词向量的好坏,所以该算法在这4种方法中表现最差。而本文算法的P、R和F均高于其他方法,结果最优。为了较好地观察本文算法的提取效果,将不同文档中的提取结果列于表1。
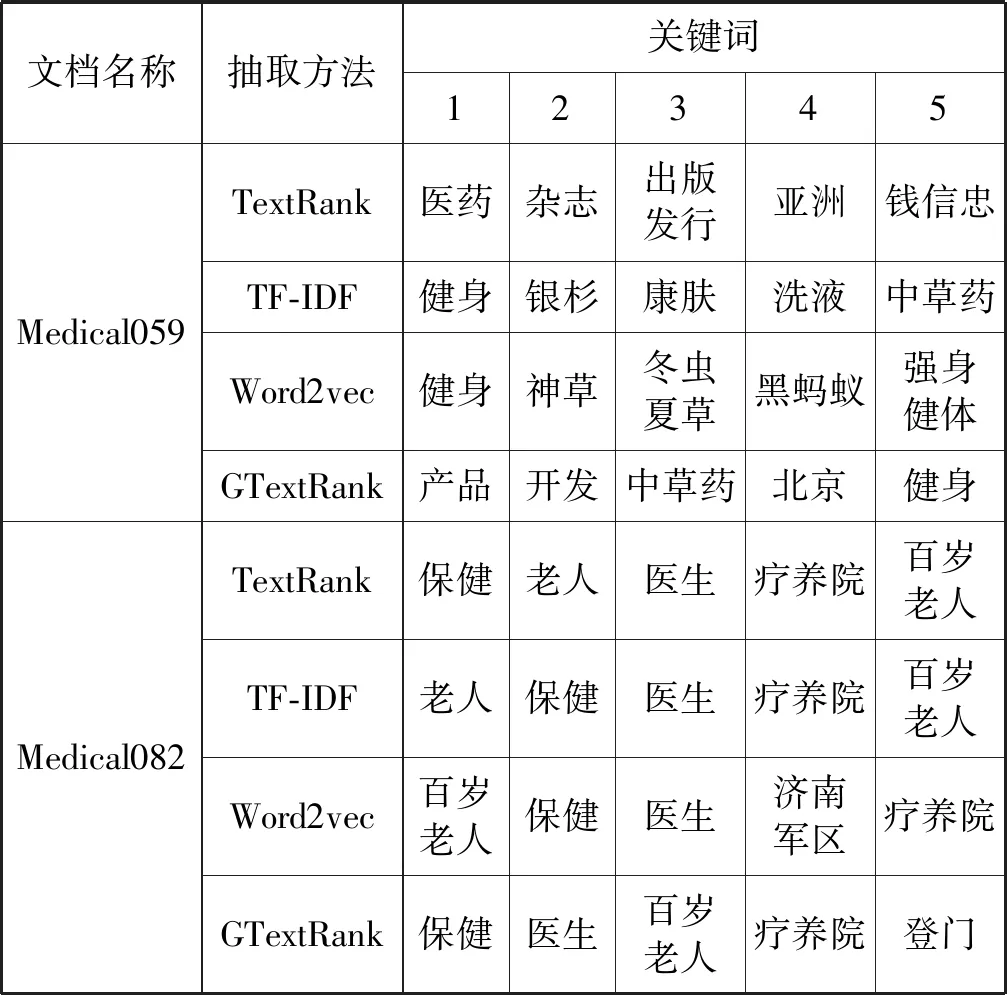
表1 不同方法提取的关键词
可以看出,TextRank仅仅考虑词语的共现频率,忽略了主题相关性和文本之间的语义关系,不能较好地提取出能概括出文章大意的关键词。尽管TF-IDF方法考虑到了文档中词语出现的频率,但未予以词语潜在语义关系充分的重视,导致所提取的关键词仍不甚理想。相较于以上方法,Word2vec方法考虑到了文档的内部结构即语义关系,但结果的准确度受训练词向量好坏的影响较大,存在一定限制。本文算法综合考虑了词语共现频率、词语的主题影响度和词语之间的潜在语义关系,充分利用文档中的内部结构关系和词语之间的语义关系,提取出的关键词相对其他方法效果较好。
4 结 语
关键词在一篇文档中占据重要地位,读者通过关键词,能够摸索出文档的大致主题和内容。在对关键词进行提取时需同时考虑文档的内部结构与词语之间的语义关系,仅仅考虑其中一部分,往往获取的关键词不具有代表性。本文提出的基于万有引力改进的Text-Rank算法同时把词语之间的影响力、语义关系和共现频率考虑在内,利用TextRank算法迭代计算得到词语的排列序,进而对指定数量的关键词进行提取。本文对比了基于不同算法的关键词提取方法,实验结果表明,建立在万有引力改进基础上的TextRank算法所提取的关键词较为理想,但是词语在文档中的位置也影响关键词提取效果。未来将进一步考虑词语位置的影响,并将其纳入算法中,作为本文的后续工作之一。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
小学生学习指导(低年级)(2021年9期)2021-10-14
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
电脑爱好者(2017年7期)2017-05-06
长江学术(2016年4期)2016-03-11
