
基于BLSTM网络的改进EAST文本检测算法
2020-07-15 05:03邱晓晖
计算机技术与发展 2020年7期
郭 闯,邱晓晖
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
自然场景中包含丰富的文本信息,这些信息在工业自动化、智能图像检索、机器人导航、无人汽车等众多领域有着重要的意义,因而高效准确的文本检测方法成为计算机视觉领域备受关注的研究内容。但是自然场景中的文本在尺度、方向、光照、字体、颜色等方面严重影响了文本检测的准确率。所以自然场景文本检测被认为是在文本分析领域中最有价值的挑战之一,受到了广泛的关注[1-3]。尽管前人在文本检测和文本识别的工作中取得了不错的进展,但是由于文本模式的差异和背景的高度复杂性,文本识别仍然是一个巨大的挑战。
现在一般将场景文本阅读分为文本检测和文本识别两部分,分别作为两个独立的任务进行研究处理[4-5]。在文本检测中,通常使用卷积神经网络从场景图像中[6-8]提取特征,然后使用不同的解码器对区域进行解码[9]。文本检测作为文本识别的前提,在整个文本信息提取和理解过程中起着重要的作用。文本检测的核心是设计文本与背景的特征区分,传统基于深度学习的算法大致分为三类,第一类是直接从训练数据中学习有效的特征[10-12],第二类是根据像素连通域分类学习[13-14],第三类是特征融合进行学习[15-16]。虽然这些方法很优秀,但是在某些特定的场景下,对于感受野不都长的文本检测,效果不是很好。为解决感受野不足的问题,文中选取目前检测效果较为优秀的EAST算法作为基础算法,改进网络结构,增大感受野,从而改进文本检测算法的性能。
1 改进EAST算法
1.1 EAST算法介绍
EAST不同于传统的文本检测方法[10]和一些基于深度学习的文本检测方法,它的贡献在于提出了端到端的文本定位方法,消除了中间多个stage,直接预测文本行。EAST只有两个阶段。该算法使用全卷积网络(FCN)模型[17]直接生成单词或文本行级别预测,剔除冗余和慢速中间步骤。生成的文本预测(可以是旋转的矩形或四边形)被送到非最大抑制算法(NMS)[18]中以产生最终结果。根据标准基准的定性和定量实验,与现有的方法相比,该算法显著增强了性能,同时运行速度更快。
EAST网络可以分解为三个部分(如图1所示):特征提取、特征合并和输出层。
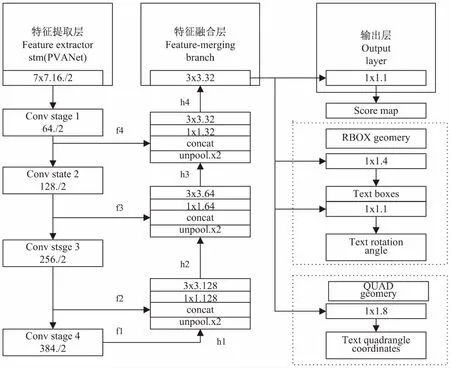
图1 算法流程
特征合并:
(1)
(2)
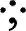
输出层:包含若干个conv1×1操作,以将32个通道的特征图投影到一个通道的分数特征图Fs和一个多通道几何特征图Fg。
几何形状图可以是RBOX或QUAD中的任意一种,如表1所示。

表1 输出几何设计
其中,RBOX的几何形状由4个通道的水平边界框(AABB)R和一个通道的旋转角度θ表示;AABB4个通道分别表示像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离;QUAD使用8个数字来表示从矩形的四个顶点到像素位置的坐标偏移,由于每个距离偏移量都包含两个数字(Δxi;Δyi),因此几何形状输出包含8个通道。损失函数公式为Loss:
L=Ls+Lgλg
(3)
其中,Ls和Lg分别表示该像素是否存在文字(score map)以及IoU和角度(genmetry map)的损失,λg表示两个损失之间的重要性。原文的实验中将λg设置为1。
目前的方法中,多数在训练图像通过均衡采样和hard negative mining以解决目标的不均衡分布问题,这样做可能会提高网络性能。然而,使用这种技术不可避免地引入一个阶段和更多参数来调整pipeline,这与EAST算法的设计初衷相矛盾。为了简化训练过程,文中使用类平衡交叉熵(用于解决类别不平衡,β=反例样本数量/总样本数量),公式如下:
(4)
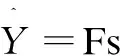
(5)
Lg几何图损失又分为两部分,一部分为IoU损失,一部分为旋转角度损失:
(6)
(7)
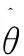
Lg=LAABB+λθLθ
(8)
1.2 优化网络结构
在卷积神经网络中,感受野的定义是卷积神经网络中的每一层输出的特征图上的像素点在输出图上映射的区域大小。EAST算法可以处理的文本实例的最大大小与网络的感受野成正比。这限制了网络预测长文本区域的能力,例如跨越图像的文本行。文本具有很强的连续字符,其中连续的上下文信息对于做出可靠决策很重要。在CPTN算法中,把一个完整的文本框拆分成多个小文本框集合,通过BLSTM[19]对过去或未来的信息进行学习和预测。因为一个小文本框,对于它的预测,文中不仅与其左边的小文本框有关系,而且还与其右边的小文本框有关系。当参考这个框的左边和右边的小框的信息后,再做预测就会大大提高准确率。所以,可以根据CPTN[20]的思想,在EAST算法中加入BLSTM网络,理论上可以扩大算法本身的感受野。
1.3 算法步骤
文中算法的主要步骤如下:
(1)在特征提取层抽出不同的特征。
(2)将抽出的特征层从后向前做上采样,然后进行特征融合。
(3)在特征融合之后加入BLSTM网络。
(4)将步骤(3)后的结果输入到输出层,最终输出一个score map和8个坐标的信息。
2 实验结果及分析
使用resnet-50网络模型作为预训练模型,使用ADAM优化器对网络进行端到端训练。为了加快学习速度,从图像中均匀采样512×512大小的特征图,经过旋转、平移等处理后,以每个batch size等于16开始训练。ADAM的学习率从1e-3开始,每10 000批次衰减十分之一,训练次数到模型较优为止。
使用的数据集是ICDAR2013和ICDAR2015数据集,以ICDAR2015为例,它是ICDAR 2015鲁棒性比赛的挑战4,该挑战通常面向自然场景的文本定位。该数据集包括1 000幅训练图片和500张测试图片。这些图片是不考虑位置任意拍摄的,其中的场景文本可以是任意方向的。它的检测难点在于它的文字旋转性。
将文中算法与其他算法在ICDAR2015数据集上进行比较,结果如表2所示。
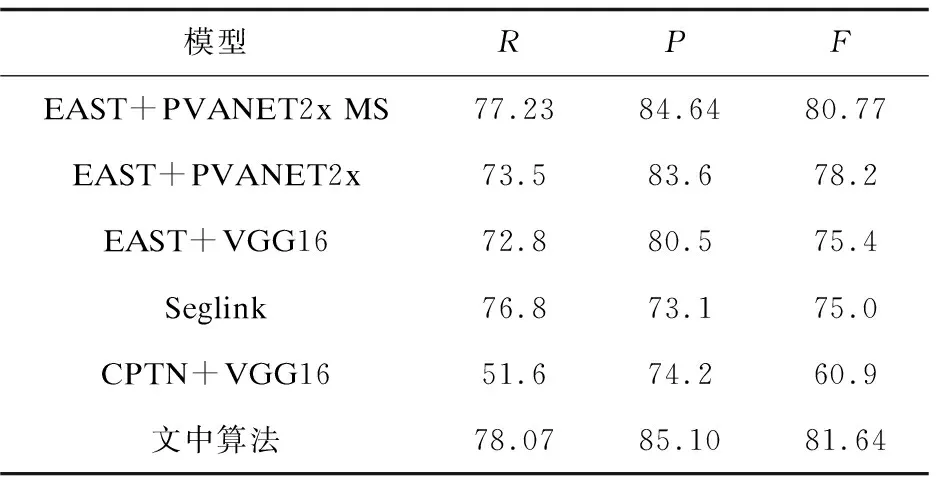
表2 文中算法与其他算法的比较
从表2中可以看出,在准确率和召回率方面,相较于原论文的结果都有一定的提高。
3 结束语
该算法在EAST的基础上引入了BLSTM网络,改善了网络感受野。和经典EAST算法相比,准确率和召回率均有提高,和其他优秀算法相比,综合性能均有提高。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电脑爱好者(2020年22期)2020-11-20
电脑爱好者(2019年10期)2019-10-30
红领巾·萌芽(2019年8期)2019-08-27
电脑爱好者(2016年23期)2017-01-05
CHIP新电脑(2016年3期)2016-03-10
