
基于行为分析的学习资源个性化推荐
2020-07-15 05:01聂黎生
计算机技术与发展 2020年7期
聂黎生
(江苏师范大学 计算机科学与技术学院,江苏 徐州 221116)
0 引 言
随着网络技术的飞速发展,良好的交互技术和丰富的在线资源使学习变得更加便捷、自由、开放,彻底改变了传统的学习方式,实现了教育领域的颠覆性创新。不同的学习者知识结构、知识能力、学习能力和兴趣偏好千差万别。通过挖掘学习者的学习偏好,在线学习系统可以准确推荐符合学习者学习需求的个性化学习资源,从而为其提供及时的资源推荐服务[1-2]。为了提高学习资源个性化推荐精度,众多学者进行了深入研究。文献[3]分析在线学习的行为特征,挖掘学习者的性格特征与学习效率的关系,实现个性化学习方法推荐。文献[4-5]认为用户之间的相似关系对于发现利益重叠的群体至关重要,可以产生多重相似关系和利益集群的形成。基于此开发了一种层次兴趣重叠检测方法,并提出了个性化推荐模式。文献[6-7]通过利用知识图谱构建知识点体系,提出了知识表示-协同过滤相结合的方式推荐有效资源,解决在线学习导航问题。文献[8]采用聚类算法将具有相同兴趣的用户聚集到同一个集群中为用户推荐可能喜欢的项目,从而提高推荐效率和精度。文献[9]基于本体和顺序模式挖掘的混合知识对电子资源进行有效推荐。文献[10]则将地理位置近邻的用户具有更为相似的访问服务作为预测依据。文中基于学习者的学习行为和兴趣偏好,采用改进的协同过滤个性化推荐算法,从学习者自主学习的角度实现学习资源个性化推荐,有效缓解传统协同过滤推荐算法存在的冷启动和矩阵稀疏性等问题。
1 个性化资源推荐系统模型
数字化时代在线学习产生的行为数据凸显重要,通过挖掘其背后隐含的重要信息,能够得到更加丰富的内容甚至超出人们的期望。文中基于“学习者-资源”二元网络,依据学习者在线学习生成的学习行为,以协同过滤技术算法为核心,构建学习资源个性化推荐系统模型,如图1所示。该模型的关键是通过个性化主动推荐服务,实现推送符合学习者本身知识水平和学习偏好的学习资源,达到与原有知识主动、快速的衔接,提高学习者的学习效率。
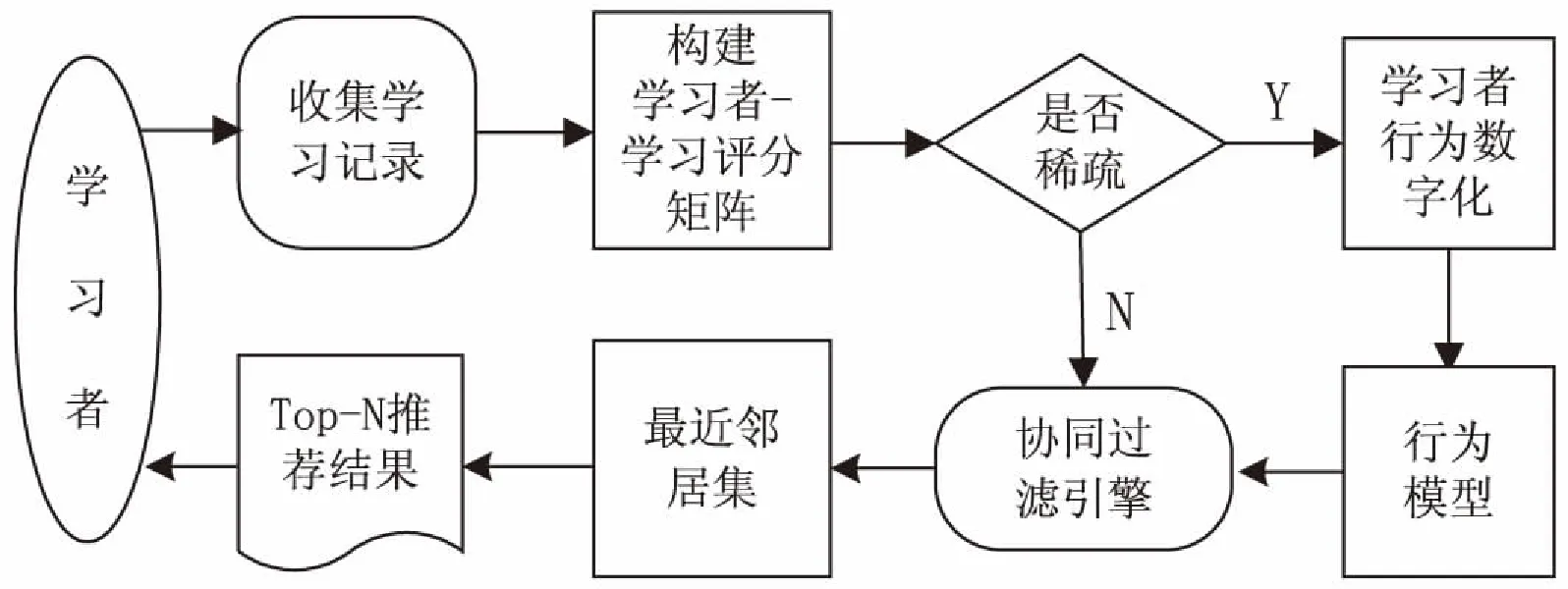
图1 个性化资源推荐系统模型
1.1 学习者行为采集
学习行为是个性化推荐系统的依据。学习者在线学习过程中会产生大量的学习行为直接或间接地反映了学习者的学习偏好。通过收集和记录学习者的学习行为,进一步挖掘学习过程中产生的浏览、收藏、分享、评论等学习行为数据进行量化分析处理,并建立学习者行为模型,清楚地了解学习者的学习偏好。
1.2 学习资源库
学习资源是个性化推荐系统的基础。学习资源库支持文本、音频和视频等多种媒体类型,为学习者提供全面、完善且有助于提高认知水平的学习资源。为了方便对学习资源内容进行分类,实现资源的统一管理和高度共享,学习资源库将所有资源都加入了知识点属性标签。
1.3 协同过滤引擎
协同过滤是个性化推荐系统的核心。文中通过挖掘和分析学习者的历史学习行为,准确预测学习者潜在的学习偏好,进而向其推送适合的学习资源,实现个性化推荐服务,优化学习者的学习体验。传统的协同过滤推荐算法存在冷启动和矩阵稀疏性等问题,其过分依赖学习者对资源的评分导致推荐结果精度受到影响。文中将学习行为融入到协同过滤算法并对其做出改进,在矩阵初始化时,如果学习者对某学习资源评价较少,则挖掘学习者对资源的其他行为并且将学习者行为模型数字化为学习权重加入到相似性计算中,有效地缓解矩阵的稀疏性问题,使推荐精度大幅提高。
2 学习资源个性化推荐过程
学习者模型构建过程其实质就是学习者-学习资源评分矩阵的形成过程,在推荐过程中若计算出的矩阵过于稀疏,该算法通过挖掘学习者隐式学习行为并融入到推荐系统,避免矩阵稀疏对推荐结果造成的不利影响。通过充分利用与其相似学习者信息进行学习者聚类分析,基于相似学习者的学习偏好预测目标学习者的学习需求,实现学习资源个性化推荐,提高学习效率。
2.1 学习者偏好矩阵构建
系统采用知识结构对学习资源建立知识体系。首先将学习者对学习资源的评价转化为n*m阶矩阵:
(1)
该矩阵由n个学习者参与对m个学习资源的评分构成,式中Rij(i∈[1,n],j∈[1,m])代表了学习者i对学习资源j的评分。
2.2 计算学习者-学习资源矩阵稀疏性
一方面由于学习者之间选择的差异性,导致学习者的评分差别非常大;另一方面学习资源和学习者数量的增长,必然存在有些学习资源没有经过学习者的评价,同时由于系统无法获取新进入学习者的学习偏好,从而导致新增的学习者和学习资源无法获得推荐。为了缓解上述数据稀疏性和冷启动带来的问题,可以为矩阵稀疏性设置一个临界阈值x,并通过式(2)初步判别矩阵是否稀疏:
(2)
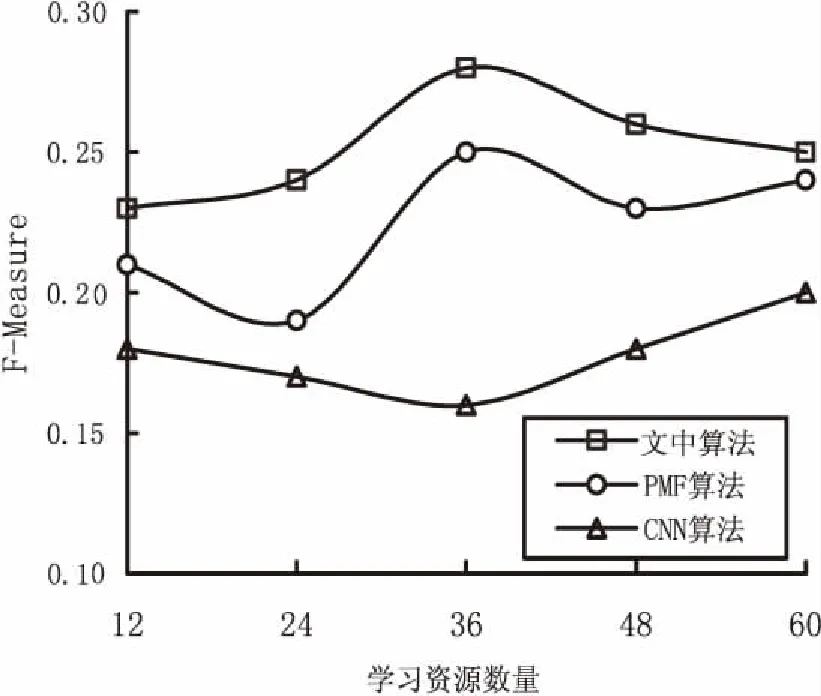
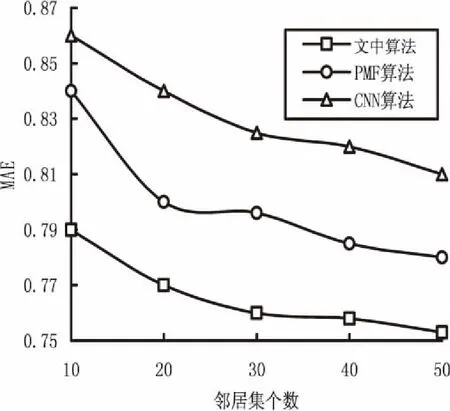
其中,NumEval为学习者对学习资源的评价数量,NumLearner、NumRes分别为学习者和学习资源数量。当Sparsity S(Learner)=1*B+2*F+3*S+5*C (3) 其中,对不同行为赋予的分数为1,2,3,5,但这个值应该不断调整。当学习者数量少的时候,各项事件都小,此时需要提高每个事件的行为分值来提升学习者行为的影响力[11];当学习者规模变大时,行为分值也应该逐渐降低。考虑到学习者数量的动态变化,采用自适应调整行为权重得分φ: (4) 其中,S(Learner)i表示第i个学习者行为得分,n表示学习者总数。这样就保证了在学习者规模的动态变化情况下仍能产生基本稳定的行为得分,然后将格式化学习者权重值φ,添加到评价矩阵中。 在协同过滤算法中,最近邻居表示是最为关键的一步,决定着学习资源个性化推荐的精度。依据学习者之间相似度的计算值,发现相似度较高的目标学习者并且根据其学习行为信息,预测与学习者兴趣偏好相匹配的学习资源并推荐[12]。根据式1,取出n个学习者对m个学习资源的评分,计算学习者之间的相似度。由于不同评价算法之间存在差异性,为了降低学习者主观性评分对研究结果的不利影响,通过对余弦相似度算法进行修正,在相似度计算时将每个资源的评分减去该学习者对所有资源的平均评分[13]。该算法将学习者对资源的评分看作是m维的向量,假设i和j分别代表两个不同的学习者,采用修正后余弦相似度算法计算两者间的相似度Sim(i,j)。具体计算方法为: (5) 文中对式(5)相似性计算方法进行了改进,将计算的学习行为权重φ融入到相似性计算中。改进后的计算方法为: Sim(i,j)= (6) 相似度计算完成后,按照目标学习者a和其他学习者的相似度,选择相似度最为接近的n个学习者构成待推荐近邻集Z={Ld,d∈[1,n]}。余弦值越接近1,表明两个向量越相似;反之越接近0,表明两个向量越不相似。 根据式(6),基于生成的目标学习者a的近邻集,在包含学习者a的全部学习者评分集合中除去目标学习者的所有已评分学习资源,可得目标学习者的待预测评分资源Sa。计算目标学习者a对每一学习资源t∈Sa的预测评分,降序排序选取评分最高的前N项作为Top-N推荐给目标学习者。由于不同学习者评价存在差异性,推荐结果采用以下方式: (7) 为验证文中个性化推荐方法的有效性,实验数据集来源于“LiveCourse在线课程平台”,利用MySQL数据库存储领域专家对课程学习资源标注了90个知识点以及知识点之间的关联关系和相应的学习资源。数据集由65名学习者在4个月内对900个学习资源,包含138个视频、287个幻灯片、475个文本资源的21 738条学习行为数据构成。实验主要提取浏览(B)、收藏(F)、分享(S)、评论(C)这四种学习行为数据,按照1∶4分成训练集和测试集两部分。 依据学习者在训练集中的学习行为,通过文中算法与基于矩阵分解的协同过滤算法(probabilistic matrix factorization,PMF)、基于卷积神经网络的推荐算法(convolutional neural networks,CNN)分别向学习者推荐学习资源,评估算法的性能。精确率和召回率通常用来反映推荐算法性能,精确率反映推荐的精度,召回率衡量推荐系统的查全率。但也有可能出现推荐系统具有较高的精确率而召回率却很低的矛盾状况,因此单一的指标不能较为全面地评价推荐算法的好坏[14]。为了平衡二者之间的影响,通过引入了综合评价指标F-Measure和MAE评价各算法性能。F-measure值越高表明实验结果越好,其计算公式如下: (8) 平均绝对误差(MAE)用于计算预测评分和实际评分之间的差异,是评判推荐系统结果精准与否的重要指标。推荐算法中,设置预测推荐结果为二元值1或0,分别代表推荐资源和学习者习知识点是否一致。其计算公式如下: (9) 其中,N表示推荐的学习资源数量,Pu,i表示学习者已学习的资源,此处Pu,i的值为1,ru,i表示推荐结果是否准确的指标值,如果推荐结果和学习者学习的知识点一致,则ru,i的值为1,否则ru,i的值为0。因此,MAE值越小表示算法推荐精度越高,反之则表示推荐精度越低。 实验分别选取推荐资源数量12,24,36,48,60验证不同算法的性能,通过图2可以看出文中算法F-measure值高于其他两种算法,具有明显的优势,表明推荐结果较好;在推荐资源数量M为36左右时,可以得到较高的推荐精度,学习资源个性化推荐结果更加符合学生的实际需求。M值的选取对于推荐系统精度比较重要,但是推荐结果的精度对M值也不是非常敏感,二者之间不成线性关系,只要选择合适的范围就可以获得较高的推荐精度。 图2 不同算法F-Measure值对比 图3显示了近邻集数量分别为10,20,30,40,50,推荐学习资源数量为36的情况下不同算法的MAE值,测试结果表明文中算法的MAE值在不同近邻集数量下都明显低于其他算法,说明文中算法推荐质量最高,推荐结果符合目标学习者的学习偏好。随着近邻集数量的增加、数据的稀疏性降低,算法收敛的速度加快[15],MAE值逐渐降低最后趋于稳定。实验结果中Top-N的N值为选取的学习者相似度较大的N个学习者作为近邻集,非最终推荐列表的Top-N。 图3 不同算法MAE值对比 针对如何提高学习资源个性化推荐的精度与效率问题,通过构建学习者-学习资源的评分矩阵,综合考虑学习者的学习行为,采用改进的相似度算法实现学习资源的个性化推荐。实验结果表明该方法优化了学习资源个性化推荐过程,推荐结果精度更高,效果更好。未来将挖掘更多能反映学习偏好的行为数据,以改进和完善推荐模型,促进学习系统提供更加精准的个性化服务,并将其推广应用到其他资源推荐领域。2.3 学习者近邻集生成
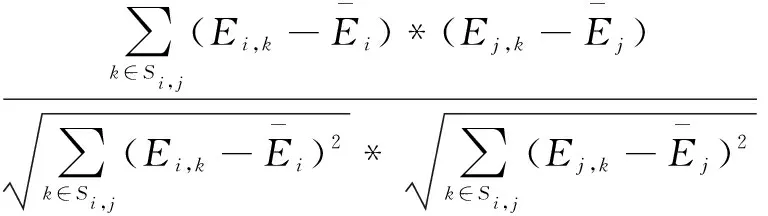
2.4 生成推荐结果
3 评价指标及结果分析
3.1 实验数据
3.2 评价指标

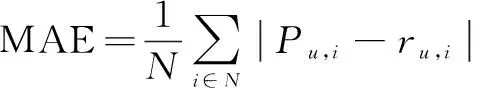
3.3 结果分析
4 结束语
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
电脑知识与技术(2022年11期)2022-05-31
意林·少年版(2020年2期)2020-02-18
知识文库(2019年24期)2019-12-30
现代职业教育·职业培训(2019年6期)2019-10-09
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
