
基于工控系统功能码特征的同源攻击分析
2020-07-17 07:35王建华陈永乐张壮壮连晓伟陈俊杰
计算机工程 2020年7期
王建华,陈永乐,张壮壮,连晓伟,陈俊杰
(太原理工大学 信息与计算机学院,太原 030024)
0 概述
随着工业互联网技术的推广普及,工业控制系统(Industrial Control System,ICS)安全为国家安全和社会经济发展提供重要保障。然而,网络环境下的不安全因素对ICS构成极大威胁,2010年的“震网病毒”事件以及2015年的“波兰航空公司黑客攻击”事件等,充分显示出ICS遭遇攻击后的严重危害性。因此,如何保障ICS安全是当今网络安全领域广泛关注的问题。攻击者溯源能够为ICS安全提供主动防护,蜜罐技术是实现攻击者溯源追踪的手段之一[1-2],通过蜜罐技术收集攻击者信息,分析攻击者的攻击行为、攻击特征等,能够对工控网络的组织和安全态势进行更准确的分析。目前,IP溯源技术是攻击者溯源的主要手段,但是,IP溯源需要对路由设备进行更改,存在资源开销大、识别精度低以及有效验证难等问题。此外,现有的攻击手段多数采用攻击代理来实施攻击行为[3],提高了IP溯源的难度。事实上,目前多数工控系统攻击是有组织、有规模的攻击行为,攻击者并非单一个体,对恶意组织进行全面溯源更有实际价值。然而,IP溯源往往针对单个IP进行溯源,对于恶意IP所属组织的识别效率较低。
本文借鉴恶意代码常用的家族同源判断分析方法[4-5],将具有相同攻击者信息或相似攻击特征的攻击定义为同源攻击。使用基于粗、细粒度功能码特征结合的特征提取和建模方法来判定具有攻击特征的攻击者是否属于同一恶意组织,从而实现攻击者溯源。此外,针对蜜罐数据同一攻击源判定验证较难的问题,使用开源威胁情报库验证恶意IP所属组织[6-7]。
1 相关工作
攻击者溯源的研究主要依赖于IP溯源技术,IP溯源技术作为网络安全主动防护的关键手段,主要包括概率包标记溯源法和日志溯源法2类。概率包分组标记技术[8]将标识信息(如IP地址)写入转发分组的头域,也即标记域中,然后受害者从收到的分组中找回标记信息,最终确定攻击路径。日志溯源法[9]是路由器在转发分组前记录下分组相关的信息并进行重构。然而,设备的修改以及日志格式的不统一,使得传统IP溯源技术成本开销高、误报率高、可操作性低,在工控领域难以实现。
工控蜜罐技术通过搜集信息来分析工控系统攻击者的行为,包括攻击方式、攻击手段等。Glastopf项目发布了第一个开源工控蜜罐框架Conpot[10],其实现了协议栈上的请求-应答交互。文献[11]提出了一种基于物联网设备的蜜网系统,提升了蜜罐的交互能力和仿真度。对蜜罐数据中攻击者行为进行分析依赖于攻击特征的提取,Honeycomb[12]作为Honeyd蜜罐的扩展模块,其提出了利用蜜罐捕获数据进行攻击特征提取的基础方法。Nemean系统[13]改进了Honeycomb,其将原始数据包转换为会话树,生成基于语义特征最后转换为入侵检测系统的特征规则格式。但是,上述特征提取技术多数没有基于工控协议数据特性的攻击特征提取方法。
攻击行为的相似性分析有助于更加全面地对攻击者进行溯源。文献[14]将一个攻击源发送的有效载荷转换为字符串并进行连接生成攻击指纹,然后通过简单的字符串距离度量比较指纹,从而分析攻击源。文献[15]使用Micro-Honeypot框架内浏览器指纹来追踪攻击者,并提出一种指纹关联算法,将浏览器中cookie、IP信息和指纹进行关联,生成字符串并作比较,从而确定同源攻击者。然而,上述同源攻击者判断方法仍无法直接应用于工控网络。文献[16]部署分布式蜜罐系统来收集威胁数据库,根据3种不同的工控协议蜜罐数据对攻击方法、攻击模式和攻击源进行分析,提出一种针对攻击组织的聚类算法。然而,人工划分攻击模式无法分析大规模数据,且该算法识别的攻击源组织并未进行结果验证。网络攻击同源性是指不同的网络攻击事件具有内在相似性,源自同一个人或同一组织等[4]。现有同源攻击的分析主要集中在恶意代码家族判定方面,此外,也有部分针对蜜罐数据进行组织判定的研究[16-17]。针对工控协议进行同源判定及组织分析的研究较少,且结果验证不足,为此,本文依据工控蜜罐数据进行同源攻击分析,并重点研究同一组织的判定问题。
2 工控攻击行为特征提取
2.1 工控功能码
根据工控协议规约,功能码用于标明一个信息帧的用途,当主设备向从设备发送信息时,功能码将通知从设备需要执行哪些行为。文献[18]使用Modbus功能码来界定某一攻击者对于设备的请求,根据请求报文中的意图进行分类并总结出攻击方法。然而,在真实情况下,单一功能码无法较好地体现整个攻击序列的企图。文献[18]将连续的Modbus TCP数据包抽象简化为Modbus功能码序列,利用序列顺序进行系统异常检测。wireshark为常用的网络封包分析软件,图1所示为wireshark解析器下工控协议Modbus蜜罐数据流PCAP文件的各字段解析示例。其中,加框字段为功能码字段。基于Modbus协议报文格式,利用python脚本对蜜罐数据流PCAP文件进行处理,提取出Modbus TCP数据包中的初始数据包特征以便进行后续处理。对PCAP数据流进行处理后的工控信息库示例如表1所示。
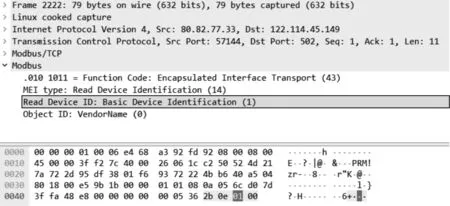
图1 Modbus蜜罐数据流PCAP文件

表1 工控信息库示例
2.2 基于统计信息的功能码粗粒度特征
根据文献[19]提出的249个基于流量的特征,结合所搜集的工控蜜罐中Modbus TCP数据包信息特征,本文提出一种基于统计信息的功能码粗粒度特征,其中包括功能码类型占比、攻击频率和稀有评级占比。攻击频率属于数据流特征,其余属于数据包内功能码信息特征。图2所示为Modbus协议的报文格式以及功能码在整个报文中的位置。
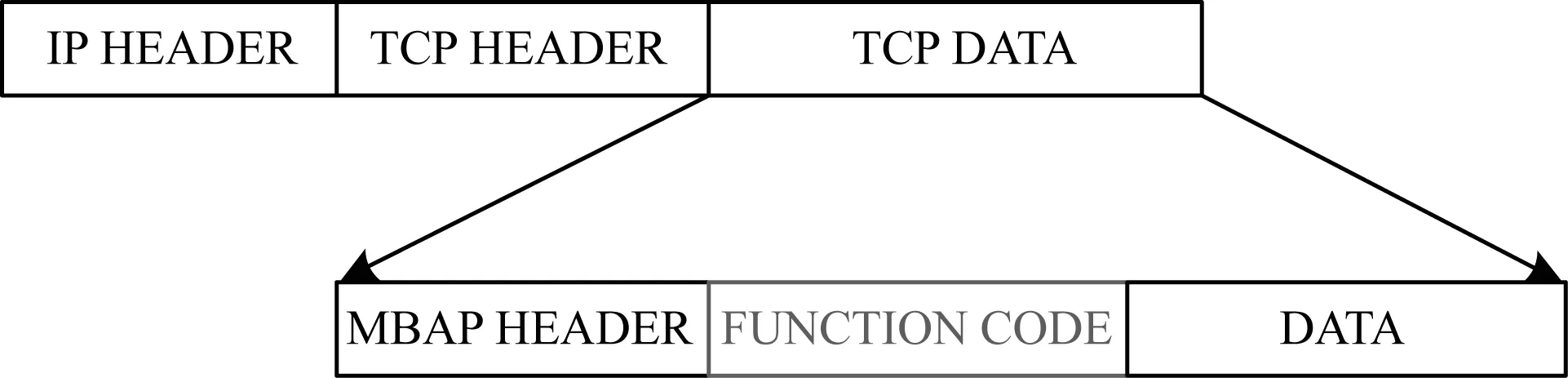
图2 Modbus协议报文格式
功能码类型占比是功能码序列的功能码类型占整体功能码的比例。功能码类型占比表示为Ti=Tf/T,其中,Tf为功能码序列中功能码类型个数,T为蜜罐数据中功能码类型个数。
攻击频率体现功能码序列中的时间特征,其值为功能码数量与交互总时长的比例,即Fi=Num/Time,其中,Num代表序列中功能码数量,Time代表序列交互总时长。由于存在自动化攻击单位时间内发包数大于1的情况,因此本文对攻击频率进行0-1标准归一化处理。
稀有评级可以反映功能码序列在蜜罐数据中的特殊程度。以Modbus协议数据为例,在超过1.7万条Modbus数据包中,0x2b、0x11出现频率最高,将其分别划为1、2级,其余按表2所示进行评级。稀有评级占比为Ri=Di/Dmax,其中,Ri表示稀有评级占比,Di为功能码序列i中的最高稀有评级,Dmax表示整体数据中的最高评级5。表3所示为基于wireshark解析器的报文解析样例,其中包括2个Modbus TCP粗粒度特征提取过程。从表2可以看出,蜜罐中的功能码类型数为5,因此,计算出这一组Modbus TCP功能码类型占比为0.4。出现功能码的稀有评级最高为2,即其稀有评级占比为0.4。攻击频率则根据时间戳进行计算,值为3.876 8,后续再依据所有蜜罐数据整合进行归一化处理。
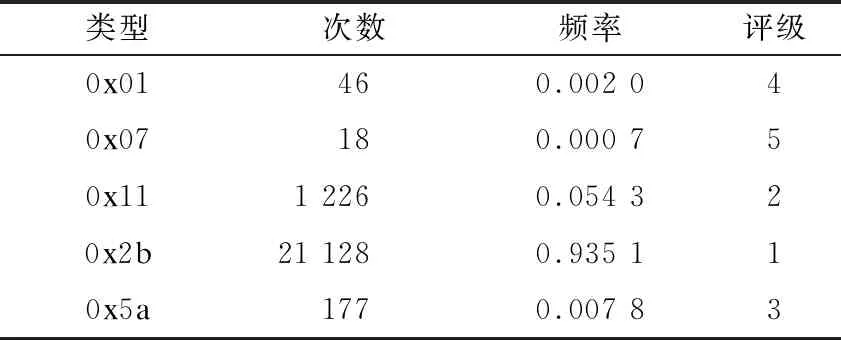
表2 功能码稀有评级

表3 基于wireshark解析器的报文解析样例
2.3 基于功能码序列的细粒度特征
细粒度特征即功能码序列特征,十六进制Modbus功能码序列为07、01、01、11、2b、11、2b。由于Modbus功能码序列的有序性,本文使用窗口滑动的方法,通过一个大小为2的窗口对整个功能码序列进行截取,通过计算该功能码组合在整个序列各项组合中出现的概率,对vector内的相同功能码组合进行概率值填充,进而得到所有蜜罐数据中攻击IP的细粒度特征向量。
图3所示为细粒度特征提取方法示意图,其中,左半部分为样例功能码序列的处理过程,其得到对应攻击者IP和所有攻击者IP的向量值。功能码序列特征划分如表4所示,其中,n=2,n代表维度。

图3 细粒度特征提取方法示意图
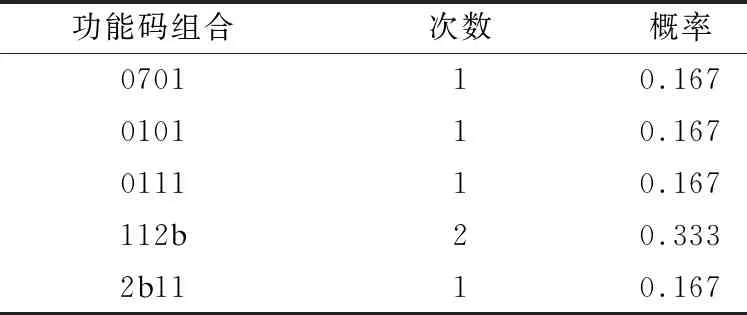
表4 功能码序列特征划分样例
在表4中,功能码组合表示当窗口长度n=2时得到的十六进制值,次数表示功能码组合出现的次数,概率表示某二元功能码出现的几率。
将功能码组合进行功能码排序,得到有关功能码序列的多维向量。根据蜜罐数据以及功能码序列的有序性,向量种类表示为(0101,0107,0111,…,5a5a),特征向量为vector=(P0101,P0107,P0111,…,P5a5a)。
3 工控攻击行为特征建模
3.1 基于粗糙集思想的粗粒度特征聚类
2.2节介绍了功能码类型占比、攻击频率和稀有评级占比3个粗粒度行为特征。基于粗糙集思想的粗粒度特征建模方法,使用Canopy聚类算法将这3个行为特征转换为(Ti,Fi,Ri)三维向量。文献[20]实现了传统的Canopy算法,其具有快捷、简单等特点,为后续聚类算法消除了K值的不确定性,以便合理地使用初始聚类中心。
3.2 基于功能码序列的聚类模型
在机器学习中有一些基于标识数据的有监督机器学习算法,如SVM、KNN和决策树等。对于组织溯源领域,除一部分公开的设备扫描安全厂商外,其余攻击者的IP均没有样例标识。因此,需要通过无监督或半监督的机器学习算法来进行聚类分析。本文提出基于K-Medoids的改进围绕中心点划分(Partitioning Around Medoid,PAM)聚类算法,建立基于攻击行为的聚类模型,并使用基于密度的离群点检测方法对离群点进行检测和处理。
引入轮廓系数(Silhouette coefficient,S)来体现簇内数据的紧凑程度和簇间距离的分离程度。设数据集中的每个对象为O,对象O与O所属的簇内其他对象之间的平均距离为A(O),B(O)指对象O到不包含O的所有簇的最小平均距离。所有点的轮廓系数平均值越接近1,则显示聚类模型内聚度和外分离度越好,模型性能越优。轮廓系数的计算如式(1)所示:
(1)
本文使用改进的PAM聚类算法对攻击行为向量进行聚类并对攻击行为实现建模,流程如图4所示。
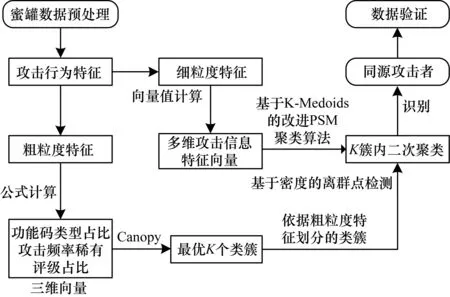
图4 改进的PAM聚类算法流程
本文算法具体步骤如下:
1)根据粗粒度、细粒度特征对数据集数据进行预处理。
2)使用基于粗糙集思想的粗粒度特征处理方法将粗粒度特征转换为三维向量,使用Canopy聚类算法计算最优类簇数量并进行第一次聚类。
3)使用基于功能码序列的细粒度特征处理方法将细粒度特征转换为攻击行为特征向量,并通过改进的PAM聚类算法对K簇进行聚类。基于K-Medoids改进的PAM聚类算法的基本思想为:
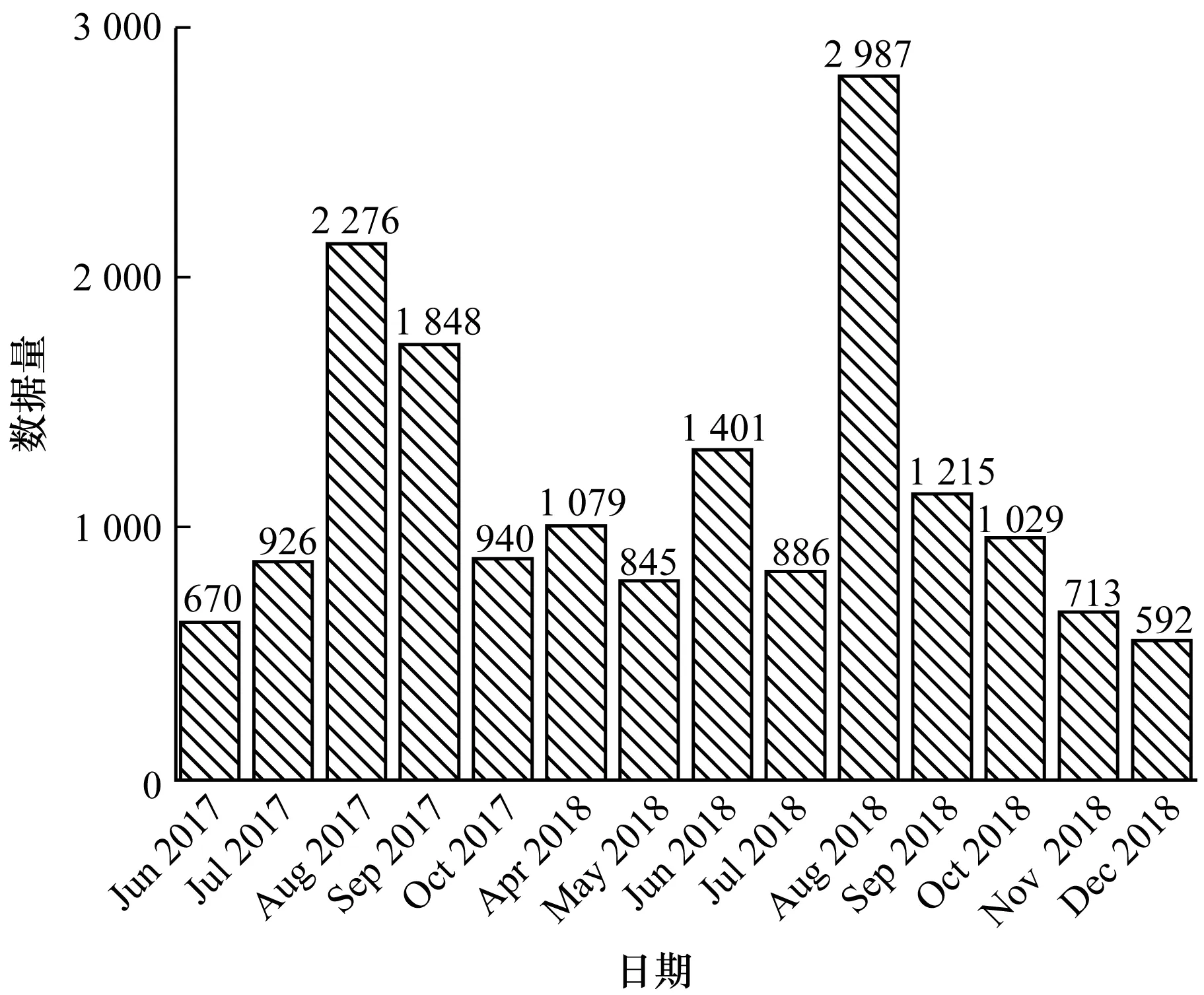
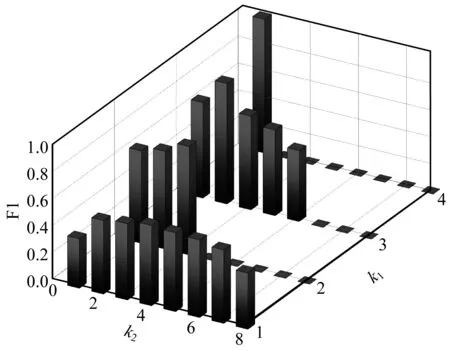
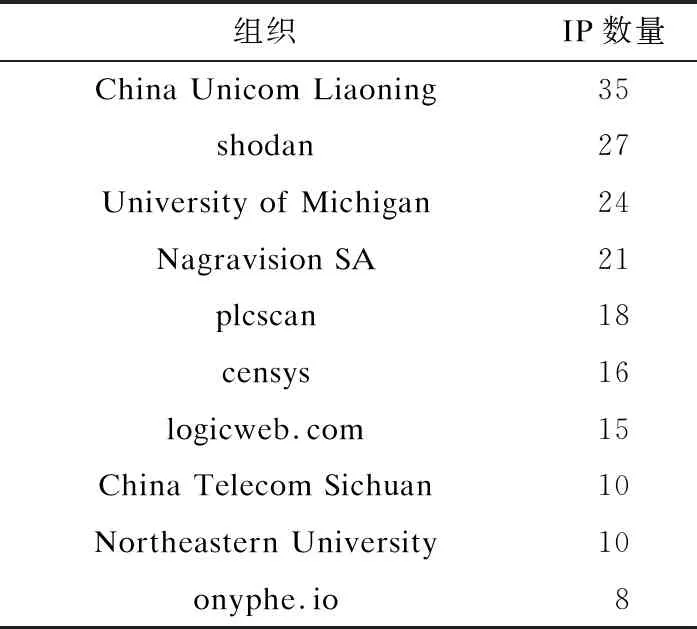
(1)任选k (2)迭代使用Medoids外的其余非代表对象点来代替初始点进行聚类,找出更好的中心点,并根据部分已知组织信息,用半监督的方式取得更好的轮廓系数和聚类性能。 (3)由于相同IP可能有几种不同的扫描方式,因此引入惩罚因子ξ用于减小相同IP的不同向量间欧式距离的差异值。惩罚因子ξ计算公式如式(2)所示: (2) 其中,N为集合{IPs}中相同IP攻击信息向量的个数,EDvector(i,i+1)表示2个向量的欧式距离差异值。 (3) 4)使用基于密度的离群点检测方法对离群点进行检测和处理,并根据半监督标识实现迭代学习,迭代轮廓系数S(O),直到得到更好的聚类精度。 5)使用本文提出的验证方法并应用第三方恶意IP库进行数据验证,计算精度和召回率,得到聚类结果。 (4) 则局部离群因子LOF计算如式(5)所示: (5) 通过已有方法找出聚类模型中的离群点因子,为了得到更好的轮廓系数、聚类性能和结果,本文提出收缩因子α(0≤α≤1)进行离群点处理,α的迭代取值遵循α=arctanx+1,以降低生成粗糙集时随机质心对离群点的判断误差并迭代出更优的轮廓系数S(O)。聚类精确度不再提高时收缩停止。 本文数据来源于文献[16]收集到的分布式工控协议蜜罐数据,时间跨度超过12个月。实验及数据验证部分使用Modbus协议蜜罐数据,该协议是工控系统中常用的具有公开协议规约的通信协议。图5记录了Modbus蜜罐在一段时间期间的数据收集情况,其中,在2018年8月收集到了2 987条数据包,总数据包数量超过1.7万条。 图5 Modbus协议数据量 文献[16]指出,由于没有相似性实验,工控蜜罐数据攻击源分析后很难进行结果对比与验证。本文通过反向解析攻击者IP发现,只有很少一部分公开的设备扫描网站信息。在寻找公开数据集时,得知AbuseIPDB[22]和ipvoid[23]可以对滥用IP(通常包括与可疑主机公司、僵尸网络、被黑客入侵的服务器或其他由黑客控制的机器相关的IP地址)进行记录、将网络中自动化软件扫描和攻击事件进行存储,而IBM X-Force Exchange[24]公开的情报分析库甚至可以找到近5年内某一IP的活动情况,包括其何时被识别为扫描IP、何时自动运行木马以及是否运行恶意软件。本文的数据验证方式是将同源判定的结果与公开网站数据进行匹配验证。当无法在开源滥用IP数据库中找到其明显组织后,使用物理位置判定方法,在数据验证时将同一网段的攻击者默认归于同一攻击源。 文献[25]在观察大规模蜜罐攻击数据时发现,可追溯同源的类似DDOS攻击源的恶意服务器TTL值经常在某2个连续值之间波动。本次实验将对比本文同源攻击判定方法与TTL方法[22]、位置信息方法[3]的聚类性能。从图6可以看出,在Modbus协议数据集中,使用Canopy方法和PAM方法后,通过粗粒度特征向量生成k1个类簇,簇中的细粒度聚类结果随着k2值的变化而变化,其中,k2是对粗糙集中细粒度特征向量使用改进的PAM算法后的结果。当k1=1时,F1值最高的是k2=4,即k21=4,F1值为0.60,表示在类簇1中,继续细分为4个簇时精确度和召回率的综合表现最佳。在其余3组中,F1值最高的分别是类簇2k2=3,F1值为0.81;类簇3k2=2,F1值为0.90;类簇4k2=1,F1值为1.00。因此,类簇组织的最优数量为k21+k22+k23+k24=10,平均F1值为0.827 5。 图6 不同k1和k2值时算法聚类性能比较 不同的同源攻击分析方法性能对比如图7所示。图7(a)显示了不同初始簇数下方法的精确度,图7(b)为召回率,图7(c)使用F1值计算分析方法的精确率和召回率,图7(d)显示聚类模型随类簇数改变时SSE值的变化情况。从中可以看出,本文方法较其他2种方法具有更高的F1值,数据的综合精确度和查全率具有更好的表现。理论上来说,随着类簇数k的增大,样本划分会更精细,每个簇的聚合程度会逐渐提高,则SSE值会逐渐变小。实验结果也证明,当k小于某一类簇数时,由于k的增大会大幅增加每个簇的聚合程度,而当k到达某一数值时,再增加k时所得到的聚合程度反馈会迅速变小,所以SSE的下降幅度会随着k值的继续增大而趋于平缓,这意味着当k值为12时,聚类模型具有更合理的SSE值,约为7.376。然而,观察其F1值的结果可知,当k为10或11时,达到最高F1值0.792。而且,在实验过程中,当k值大于10时,结果出现了测试集为空的情况,这显示出实验中可能存在过拟合现象。综合图6、图7,本文选取最优的类簇数为10。 图7 同源攻击分析方法性能对比结果 蜜罐数据分析的验证是一个难题,本文通过反查DNS,调用开源滥用IP库进行同源攻击者结果验证,相比于TTL值判别方法,本文方法具有更高的精确度和F1值。在判别威胁情报库中识别的shodan IP时具有100%的精确度和召回率,而对于其余恶意IP所属组织,如plcscan、censys[26]、University of Michigan等的判别,精确度达到0.91。4种协议攻击IP数前10的组织溯源结果如表5所示。其中,包括物联网设备识别企业和安全服务提供商,如shodan、plcscan和censys等。 表5 同源攻击分析结果 本文提出一种基于工控功能码序列的同源攻击分析方法,根据攻击者特征找到其物理位置特征,依据细粒度特征和粗粒度特征生成攻击行为模型。分析结果表明,该方法针对开源滥用IP库识别时具有较高的精确率,能够识别出shodan、censys和plcscan等10个组织。下一步将扩展工控蜜罐的适用协议,包括S7comm、BACnet等使用率较高的工控协议。此外,将攻击行为处理方法加入到入侵检测系统中实现一定程度的安全防护也是今后的研究方向。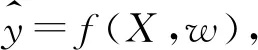
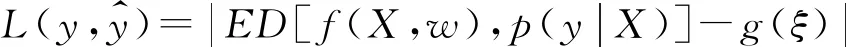
3.3 基于密度的离群点检测方法
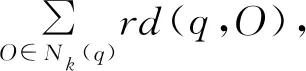
4 实验结果与分析
4.1 数据集
4.2 数据验证
4.3 结果分析

4.4 实验结论
5 结束语
猜你喜欢
红外技术(2022年11期)2022-11-25
安阳工学院学报(2020年2期)2020-06-05
中外文摘(2019年20期)2019-11-13
知识窗(2019年6期)2019-06-26
系统管理学报(2018年3期)2018-08-13
今日自动化(2018年3期)2018-05-06
电脑知识与技术(2017年26期)2017-11-20
中国三峡(2017年4期)2017-06-06
中国设备工程(2017年8期)2017-05-10
中国设备工程(2017年7期)2017-04-10
