
面向事件时序与因果关系的联合识别方法
2020-07-17 07:35张义杰李培峰朱巧明
计算机工程 2020年7期
张义杰,李培峰,朱巧明
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006; 2.江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
0 概述
事件是一种描述特定人、物、事在特定时间和地点相互作用的客观事实,文本信息中的事件则是将这一客观事实诉诸文字的独特语言形式。事件研究的核心为识别不同事件之间的关系[1],其广泛应用于自动问答、文本摘要和时间线构建等自然语言处理(Natural Language Processing,NLP)任务中。在事件之间可能存在多种关系类型,早期对于事件关系的研究多数是针对单一的关系类型,且许多提出方法是用于提升对应关系的识别性能,然而NLP领域对于事件关系进行联合识别的研究却相对较少。
事件的时序关系表示事件发生的先后顺序,描述某话题下事件的发生及演变过程,而因果关系描述原因事件与结果事件之间的因果关联。由于时序关系和因果关系之间存在密切的逻辑关联,因此在多数情况下其中的一种关系通常受另一种关系的影响,并且一般情况下存在因果关系的事件对在发生顺序上存在先后或重叠关系。本文提出基于神经网络的联合识别方法,并设计共享辅助任务中编码层、解码层和编解码层的联合识别模型。
1 相关工作
在时序关系识别方面,早期的研究工作专注于提取文本中的单一特征。文献[2-3]在标注语料的基础上利用事件属性构造特征向量,包括事件类型、体态、形态、极性、时态等,并使用最大熵分类器进行时序关系识别。文献[4]在此基础上进一步结合词性、句法树结构等语义特征,从WordNet中提取词汇和形态学特征,使得特征空间得到极大扩展。文献[5]利用篇章级的特征以及VerbOcean中的语义关系,进一步提升事件时序关系的识别性能。文献[6]在英文研究工作的基础上,针对中文语句的特点,提出多种适用于中文语料的新型特征,识别中文事件时序关系。随着深度学习技术的发展,神经网络方法被引入到时序关系识别任务中。文献[7]采取最短依存路径作为输入,构造一种基于RNN的神经网络模型,其在不使用任何显性特征和外部知识库的情况下识别效果显著。文献[8]提出基于LSTM的网络结构,利用句法依赖关系识别文本中的时序关系。文献[9]通过双通道LSTM学习两个事件词上下文的句法和语义表示,用于识别相同句子间的事件时序关系。
在因果关系识别方面,早期的研究工作主要使用模板匹配方法。文献[10]通过从句法分析的结果中提取具有因果关系的词及短语结构来构建因果关系模板,从而识别医疗文本中的因果关系。文献[11-12]在语料库中同时标注时序和因果关系,将人工标注的时序关系类型作为因果关系分类器的补充特征。文献[13]将篇章关系预测和分布相似性方法归纳在一个全局推理过程中,对识别事件因果关系具有重要作用。文献[14]提出一个新的语义标注框架CaTeRS,对时序关系和因果关系进行联合识别。文献[15]通过使用因果关系的预测结果对时序关系进行分析,研究两种事件关系之间的相互作用。文献[16]利用时序和因果关系之间存在的约束条件和语言学规则,将联合识别任务转化为一个整数线性规划问题。
2 基于神经网络的联合识别方法
2.1 最短依存路径
基于依存路径的神经网络模型在时序关系识别任务中的性能表现较好[7-9]。本文基于该思想,以事件句的依存解析树为基础,生成两个最短依存路径分支序列,其中左分支形成从源事件词结点到最近公共祖先结点的依存路径,而右分支形成从目标事件词结点到最近公共祖先结点的依存路径。为简化网络结构,本文将两个最短依存路径分支进行拼接,形成一个完整的依存路径序列作为模型输入。对于句内事件对,直接将依存解析树中源事件词结点到目标事件词结点的依存路径作为序列输入;对于句间事件对,本文假设对应的两颗依存解析树共享一个“公共根结点”,并以该结点为中心,将左右两条依存路径拼接为完整的依存路径序列。
对于依存路径序列中的每一个单词,首先将词(W)、词性(P)和该词结点在依存解析树中与其父结点的依存关系(D)映射到低维实值向量空间中,其中词通过使用Word2Vec[17]预训练词向量的方式进行查表映射,词性与依存关系通过随机初始化的方法进行映射,然后分别获得词向量xw、词性向量xp和依存向量xd,并将其进行拼接形成每个单词的向量表示xi:
xi=xw⊕xp⊕xd
(1)
该序列的矩阵化表示为X={x1,x2,…,xs},其中s表示序列长度。
2.2 神经网络编解码层
目前,主流的事件关系识别方法主要为基于神经网络的识别方法。此类方法通常包含两个组成部分,即编码(Encoding)层和解码(Decoding)层。
2.2.1 编码层
在形式上,使用X表示输入序列,该序列通过编码层进行传播得到中间表示h,即:
h=Encoding(X)
(2)
近年来,多种神经网络被作为事件关系识别模型的编码层。本文采用两个最具代表性的编码层,具体为:
1)Bi-LSTM编码层
文献[7]使用双通道LSTM(Bi-LSTM)对依存路径输入进行编码,在时序关系识别任务中效果显著。Bi-LSTM用于解决传统RNN中长期依赖的学习问题,是事件关系识别任务中最常见的神经网络编码层。由于其具有较好的文本建模能力,在自然语言处理领域得到广泛应用,因此本文使用Bi-LSTM作为编码层。
2)Self-Att编码层
Self-Att编码层采用一种融合自注意力(Self-Attention)机制的神经网络模型。Google于2017年提出基于Self-Attention机制的Transformer模型[18],在机器翻译任务中效果显著。Self-Attention机制直接捕获输入序列的全局依赖关系,从而加强语义信息的编码能力。与传统RNN相比,该机制的主要优势在于其能够在句子中任意两个词例之间建立直接的语义关联。因此,句子中相离的元素之间能够在更短的路径上产生相互作用,使信息在网络中实现畅通无阻的传输。并且,Self-Attention机制提供了更加灵活的方式对序列中的信息进行选择、表示以及合成,并且可作为非线性网络模型的补充形式。由于Self-Attention机制使用加权求和的方法计算输出向量,对特征的表示能力相对有限,因此为进一步提高其表征能力,本文使用双通道GRU网络子层[19]对序列输入进行初步编码。
2.2.2 解码层
解码层将经由编码层得到的中间表示h转换成一个隐层表示r,即:
r=Decoding(h)
(3)
在基于序列到序列学习的自然语言处理任务中,如神经机器翻译,解码层通常将源序列经由编码层进行非线性转换得到的作为中间表示的上下文向量再转化为相应的目标序列。与这些成分较为复杂的解码层不同,事件关系识别中的解码层结构相对简单,因为模型的最终输出只是基于所有标签的概率得分。
本文将一层全连接层(Fully Connected Layer)作为解码层,其中使用ReLU函数[20]作为激活函数,此解码层的目的是将从编码层学习到的分布式特征表示映射到样本标签空间,计算公式为:
r=ReLU(Wh+b)
(4)
其中,W表示权重参数矩阵,b为偏置量。
2.3 联合识别模型
联合识别模型将时序关系识别作为主任务(Main Task),因果关系识别作为辅助任务(Auxiliary Task)。
2.3.1 主任务
联合识别模型通过从辅助任务中学习特征表示来促进并提升主任务的识别性能。
1)共享辅助任务中编码层的联合识别模型。图1描述了通过共享辅助任务中的编码层来实现时序和因果关系联合识别的模型架构。
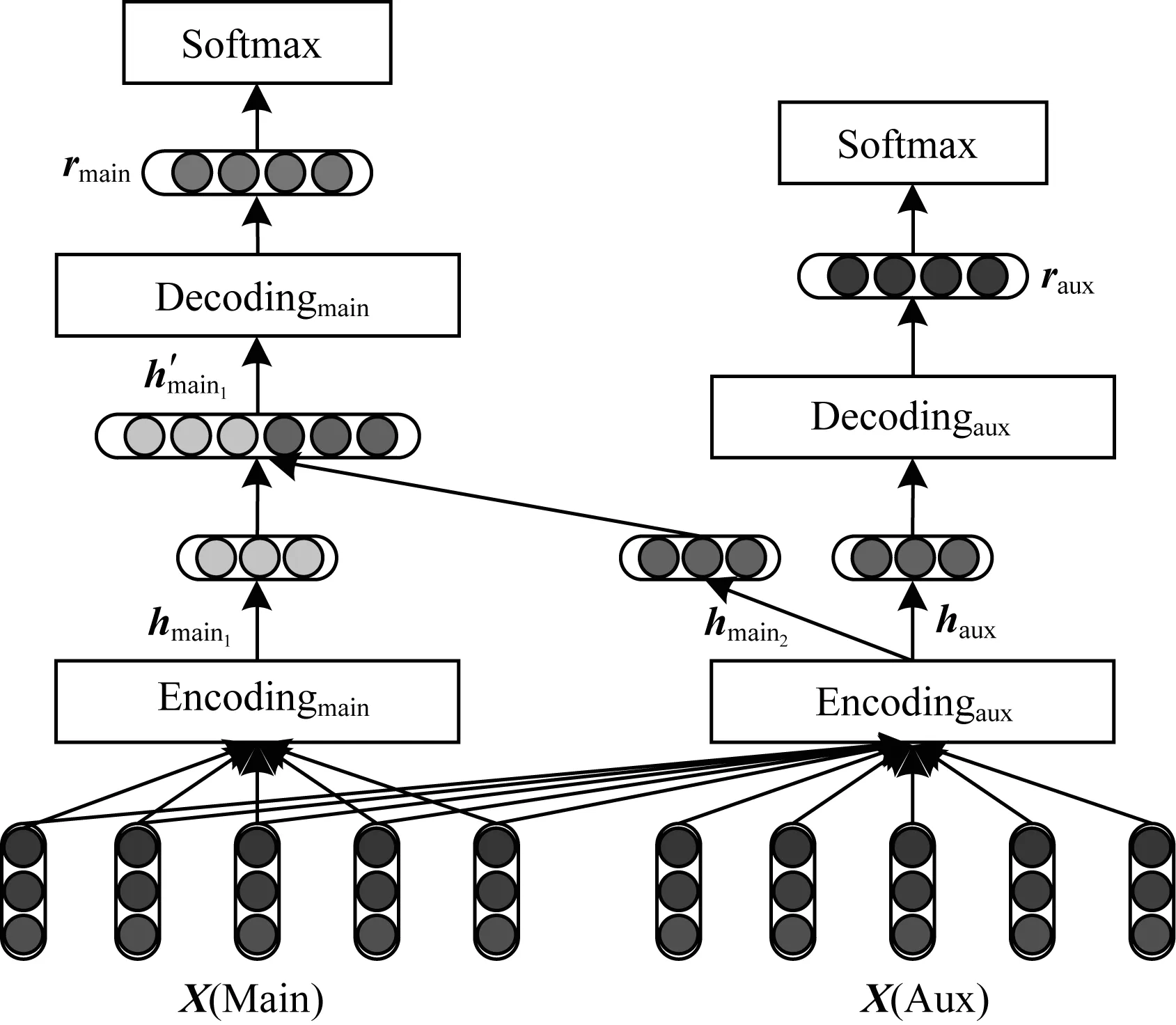
图1 共享辅助任务中编码层的联合识别模型
在一般情况下,主任务的编码层和辅助任务的编码层对生成主任务中间表示的贡献相等,即:
hmain1=Encodingmain(X)
(5)
hmain2=Encodingaux(X)
(6)
通过将两个任务的中间表示向量hmain1和hmain2进行拼接来更新主任务的中间表示h′main,并得到解码后的隐层表示,即:
h′main=hmain1⊕hmain2
(7)
rmain=Decodingmain(h′main)
(8)
2)共享辅助任务中解码层的联合识别模型。图2描述了通过共享辅助任务中的解码层来实现时序和因果关系联合识别的模型架构。
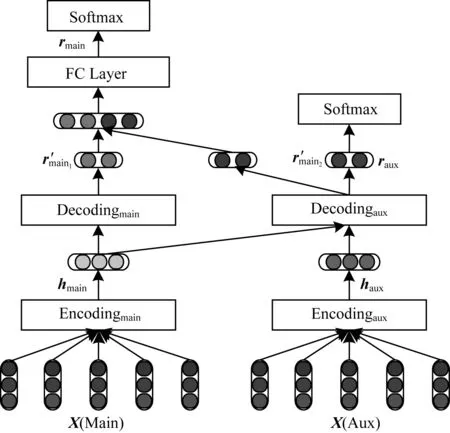
图2 共享辅助任务中解码层的联合识别模型
同样地,主任务的解码层和辅助任务的解码层对生成主任务隐层表示的贡献相等,即:
r′main1=Decodingmain(hmain)
(9)
r′main2=Decodingaux(hmain)
(10)
将主任务的两个输出r′main1和r′main2进行拼接,并通过一个非线性全连接层重新学习到一个新的结果rmain,即:
rmain=ReLU(W′[r′main1,r′main2]+b′)
(11)
其中,W′表示权重参数矩阵,b′表示偏置量。
3)共享辅助任务中编解码层的联合识别模型。图3描述了通过同时共享辅助任务中的编码层和解码层来实现时序和因果关系联合识别的模型架构。
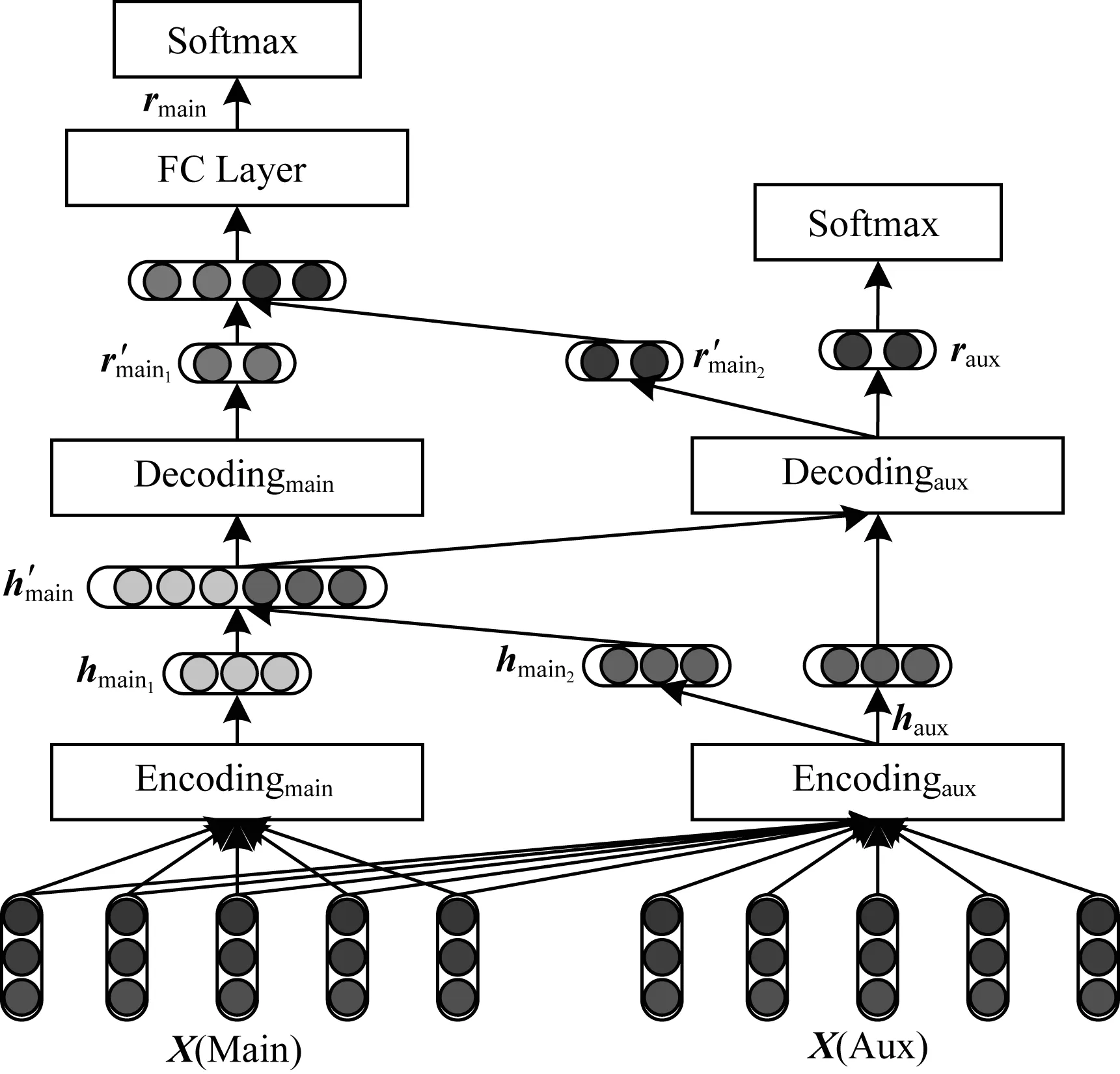
图3 共享辅助任务中编解码层的联合识别模型
模型3是模型1和模型2的融合。在形式上,与模型2不同的是,辅助任务的输出学习自中间表示的拼接结果,即:
r′main2=Decodingaux(h′main)
(12)
其中,h′main表示模型1的中间表示向量的拼接结果。
2.3.2 辅助任务
辅助任务模型采用标准的神经网络方法进行因果关系识别,其包含一个编码层和一个解码层,即:
haux=Encodingaux(X)
(13)
raux=Decodingaux(haux)
(14)
其中,haux表示辅助任务的中间表示向量,raux表示解码层输出的隐层结果。主任务可共享辅助任务的编码层和解码层。
2.4 关系分类
主任务和辅助任务分别采用一个Softmax层作为模型的输出层来获得其关系标签的预测结果:
omain=Softmax(Womianrmian+bomian)
(15)
oaux=Softmax(Woauxraux+baux)
(16)
其中,rmain和raux表示主任务和辅助任务中解码层的输出向量,Womian和Woaux表示对应的权重参数矩阵,bomian和boaux表示偏置量参数。
3 联合识别模型训练
联合识别模型通过最小化负对数似然函数进行训练。为学习模型参数,本文将两个关系识别任务的损失函数进行线性组合得到一个新的损失函数,具体为:
(17)
其中,(xi,yi)表示训练样本中第i个样本对应的关系类型标签,T表示训练样本个数,θ表示模型训练参数集合,λ表示保持主任务和辅助任务之间损失平衡的权重参数,在本文实验中设置为0.6。
在训练过程中,本文采用L2正则化方法对网络参数进行约束,并使用Adam方法对模型进行优化。所有参数均以均匀分布的方式进行初始化。
4 实验结果与分析
4.1 数据集设置
RED数据集由95篇涵盖新闻专线、论坛日志和叙述性文本等体裁的文档组成。RED标注模式不仅需要理解不同事件的相对顺序,而且需要标注一个事件导致(CAUSE)或预设(PRECONDITION)另一个事件的关系。标注人员通过对之前(BEFORE)事件链和重叠(OVERLAP)事件链进行子类型标注来构造结果(EFFECT)事件链。CAUSE和PRECONDITION本质上是存在时序链的:先决条件必须发生在它所作用的事件之前。CAUSE或PRECONDITION将先于EFFECT发生,但它们与结果最终可能重叠,比如“跑步”和“流汗”事件。然而,CAUSE关系表明原因先于结果发生。因此,对于CAUSE和PRECONDITION总存在时序关系。根据两个事件之间的时序和因果关系,对因果关联事件使用4种标注类型:BEFORE/CAUSES,OVERLAP/CAUSES,BEFORE/PRECONDITIONS和OVERLAP/PRECONDITIONS。
由于CAUSE和PRECONDITION都属于因果关系范畴,本文将其融合统称为CAUSE。表1展示了RED数据集的事件关系类型。

表1 RED数据集事件关系类型
本文实验采用句子级的五折交叉验证方式对实验结果进行评估,并且以15%的比例从训练集中随机抽样得到验证集。
4.2 超参数设置
将模型输入中事件词、词性、依存关系的词嵌入向量维度分别设为300、50、50。模型中隐藏单元数量设为200。在输入层和解码层后采用Dropout策略防止模型过拟合,其保留率设为0.5;并在训练时使用早停法(Early Stopping)保存验证集上的最优模型,置信度设为10,具体超参数设置如表2所示。
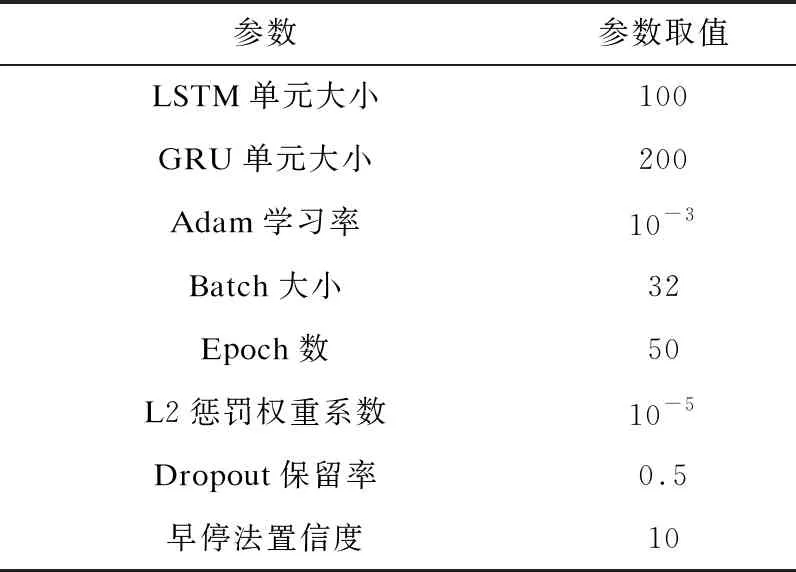
表2 超参数设置
4.3 结果分析
4.3.1 时序关系单任务识别实验结果分析
本文通过3种方法进行时序关系单任务识别实验:
1)基于LR的时序关系单任务识别方法。LR是一种基于特征工程的统计机器学习方法。本文使用带L2正则化的Logistic回归模型构建分类器,其中使用的特征来自文献[21]。
2)基于Bi-LSTM的时序关系单任务识别方法。Bi-LSTM是一种对依存路径进行编码的方法,其采用Bi-LSTM网络层作为编码层,非线性全连接层作为解码层。
3)基于Self-Att的时序关系单任务识别方法。Self-Att是一种融合Self-Attention机制的神经网络方法,其编码层由GRU网络子层和自注意力网络层两部分组成,采用非线性全连接层作为解码层。
表3给出了上述3种方法在RED数据集上的时序关系单任务识别性能对比结果,其中,加粗数据表示最优结果,“—”表示SIMULTANEOUS类型的样例数过于稀少,因此导致上述3种方法都无法对其进行识别。可以看出,基于Bi-LSTM和Self-Att的时序关系单任务识别方法通常优于基于LR的时序关系单任务识别方法。因此,下文实验中使用Bi-LSTM编码层和Self-Att编码层实现联合识别。

表3 在RED数据集上的时序关系单任务识别F1值对比
4.3.2 时序关系和因果关系联合识别实验结果分析
本文通过共享Bi-LSTM编码层和Self-Att编码层实现联合识别,其识别方法具体如下:
1)基于Encoding Sharing的联合识别方法:通过共享辅助任务(因果关系识别)的编码层来实现时序关系和因果关系的联合识别,Encoding Sharing的具体模型架构如图1所示。
2)基于Decoding Sharing的联合识别方法:通过共享辅助任务(因果关系识别)的解码层来实现时序关系和因果关系的联合识别,Decoding Sharing的具体模型架构如图2所示。
3)基于BOTH Sharing的联合识别方法:通过对辅助任务(因果关系识别)的编码层与解码层同时进行共享来实现联合识别,BOTH Sharing的具体模型架构如图3所示。
另外,本文构建一个Baseline基准方法,表示在时序关系和因果关系上的单任务识别方法。表4和表5分别给出了使用Bi-LSTM和Self-Att作为模型编码层的事件时序关系和因果关系联合识别结果。可以看出,无论使用Bi-LSTM还是Self-Att作为编码层,识别效果都优于Baseline方法,该结果验证了本文提出的联合识别方法的有效性,即对于事件时序关系识别任务,可以利用因果关系识别模型学习到有效的特征,从而采用其因果信息促进时序关系识别性能的提升。特别地,在3种联合识别方法中,基于BOTH Sharing的联合识别方法在具体关系类别及整体上几乎都取得了最优的实验结果,这表明对辅助任务的编码层和解码层同时进行共享的方式最适用于事件时序关系和因果关系联合识别任务。其主要原因为当联合学习模型对辅助任务的编码层和解码层同时进行信息共享时,既充分利用了事件之间的因果信息来促进时序关系的识别,且扩充了主任务模型中编码层输出的特征向量空间,又在解码阶段使模型在进行特征压缩时最大限度地保留了网络中的有用信息。

表4 在RED数据集上的联合识别结果(Bi-LSTM编码层)

表5 在RED数据集上的联合识别结果(Self-Att编码层)
联合识别方法与时序关系单任务识别方法相比,其因果关系识别性能的提升幅度相对较小,主要原因为本文提出的联合识别方法主要是通过共享辅助任务(因果关系识别)网络中的信息来更新主任务(时序关系识别)网络中的特征向量表示,而没有将主任务中的信息向辅助任务进行反馈。可见,该结果与本文利用事件之间的因果信息来促进时序关系识别的动机相一致,验证了本文联合识别方法的正确性与有效性。
5 结束语
本文考虑到事件时序关系与因果关系之间的联系,提出3种联合识别模型,通过共享因果关系识别任务中的特征信息提升时序关系的识别性能。实验结果表明,联合识别方法的性能要优于时序关系单任务识别方法,并且共享辅助任务中编解码层的联合识别效果最佳。下一步将研究联合识别方法在事件时序关系和因果关系识别中的应用,并尝试通过其他编码层信息共享方式对主任务中的信息向辅助任务进行有效反馈,提升因果关系的识别性能。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
小猕猴智力画刊(2022年3期)2022-03-28
唐山学院学报(2021年4期)2021-11-20
南大法学(2021年6期)2021-04-19
铁道建筑技术(2020年11期)2020-05-22
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
高中生·天天向上(2018年7期)2018-07-23
电子制作(2017年13期)2017-12-15
