
基于深度强化学习的三维路径规划算法
2020-08-03 10:05黄东晋蒋晨凤韩凯丽
计算机工程与应用 2020年15期
黄东晋 ,蒋晨凤 ,韩凯丽
1.上海大学 上海电影学院,上海 200072
2.上海电影特效工程技术研究中心,上海 200072
1 引言
三维路径规划算法是人工智能领域的一个极其重要的研究内容,该算法被应用到许多领域,包括:移动机器人导航、车辆导航以及3D游戏。三维路径规划是指智能体在具有障碍物的虚拟环境中,按照预定义的评价指标,找到一条从起点到目标点无碰撞的较优路线。在虚拟环境中进行路径规划是十分必要的,对于机器人导航及车辆导航领域,可以降低后期真正投入使用的风险;对于3D游戏开发领域,可以进一步提高智能体模拟人类的决策行为从而增加可玩性。
现有的路径规划方法有基于采样的算法、基于节点的算法、基于数学模型的算法、基于生物启发式的算法等。这些算法在已知的静态环境中都具有较强的搜索能力,但不能很好地适应复杂未知的三维环境。针对这一问题,研究人员将深度学习(DL)与强化学习(RL)进行融合,提出了深度强化学习(DRL)[1-3]。其中,深度学习主要通过损失函数增强对环境状态的感知,强化学习主要通过奖励函数完成决策实现状态到动作的映射,从而实现智能体在复杂环境中不依赖地图信息进行运动的需求。
本文针对三维环境的复杂特点和深度强化学习算法的优势,将长短时记忆网络(Long Short-Term Memory,LSTM)引入近端策略优化算法(Proximal Policy Optimization algorithm,PPO)[4-5]并应用于三维路径规划中。为了评估本文方法的有效性,搭建了包含静态和动态的多类型障碍物的三维仿真环境进行实验,通过与传统算法对比进一步验证了本文方法在路线选择上更智能更合理。
2 相关工作
2.1 传统的三维路径规划算法
近些年,由于各领域对三维路径规划的虚拟仿真测试需求迫切,越来越多的研究人员开始研究三维路径规划算法。A*算法[6]被认为是二维路径规划技术中最高效的一种算法,但它不能很好地适用于三维场景,因为其计算量非常大,效率较低。
目前主流的路径规划研究方法有:D*算法[7]、人工势场法[8]、遗传算法[9]、RRT 算法[10]、蚁群算法[11]等,也有研究人员从图形学的角度[12]更改空间搜索的方法来完成三维路径规划。但是,这些方法都有一定的局限性,例如D*算法是一种适合动态求解最短路径的方法,但是在场景大距离远的环境下效果较差;人工势场法计算量较小且路径平滑,但是存在易于陷入局部最优解或震荡导致智能体不能到达目标点的问题;遗传算法的单一编码不能完整地表达环境约束,不适宜规模较大的三维路径规划问题;RRT算法的复杂度与空间维数和环境大小基本无关比较适合高维空间,但是它存在狭长处难采样,轨迹曲折等缺点;蚁群算法虽然提高了全局搜索的能力但是存在收敛速度慢的缺点。
2.2 基于深度强化学习的路径规划算法
强化学习是一种通过奖惩来学习正确行为的机制,不需要环境和智能体自身的先验知识,按照学习方法可以分成两类:基于价值和基于策略。传统的基于价值的强化学习算法有:Q-Learning和Sarsa,这两个算法都局限于离散的较小的动作和样本空间,不适合连续控制任务。将传统的Q-Learning结合深度学习产生Deep Q Network(DQN),通过经验回放池与目标网络成功将深度学习算法与强化学习算法相结合,改进了Q-Learning依靠表格存储状态导致内存不够及不适宜在连续空间学习的问题。除了DQN算法,具有代表性的深度强化学习方法还有Policy Gradient。研究人员又结合DQN和Policy Gradient各自的优势提出了经典的Actor-Critic算法。之后,通过不断改进Actor-Critic算法不能很好地预测连续动作的问题,提出了DDPG、A3C、TRPO以及PPO等算法。其中PPO算法是现在OpenAI默认的方法,效果较优。
目前深度强化学习受到国内外广泛的关注,出现大量与之相关的路径规划的研究成果:
在机器人导航领域,Tai等人[13]通过训练DQN,让移动机器人在虚拟环境中不断试错,最终能够在未知环境下获得较好的路径结果;Zhu等人[14]通过Actor-Critic模型解决了DRL缺乏对新目标的泛化能力并且提出AI2-THOR框架,改善了DRL无法从模拟环境转移到真实世界的问题,实现了移动机器人在房间中自行找到指定物品;王珂等人[15]提出基于最小深度信息有选择的训练模式,并结合A3C算法对机器人进行训练,提高了机器人在未知复杂环境下的寻路能力。
在车辆导航领域,Wulfmeier等人[16]提出一个基于最大熵的非线性逆强化学习(IRL)框架,更准确地处理环境中的拐角情况,如楼梯、斜坡和地下通道;徐国艳等人[17]提出了一种基于改进DDPG算法的无人车智能避障方法,实现转向盘转角和加速度的连续输出,最终在TORCS平台进行驾驶模拟。
在3D游戏领域,Mnih等人[3]首次提出了端到端的深度学习模型,训练智能体玩Atari2600游戏,算法有效且智能体玩游戏的能力甚至超越人类。Zambaldi等人[18]使用自注意力来推断环境中各实体间的关系,最终成功运用深度强化学习方法完成了“方块世界”的路线探索任务。
但是目前基于深度强化学习的三维路径规划的研究主要集中在避障策略,对于各类障碍物均采用相同的方式进行避让,与实际路线选择仍有偏差。
3 近端策略优化算法
近端策略优化算法[4]是2017年由OpenAI提出的一种较好的深度强化学习算法。同年,Deepmind通过训练PPO实现了智能体在没有特殊指示的情况下探索出复杂技能[5],进一步证明PPO算法可以较好地应用于连续控制及连续性情节的任务上。
PPO是一种新型的策略梯度算法(Policy Gradient,PG)。PG算法的主要思想是使用梯度提升的方法更新策略π从而最大化期望奖励。在PG算法中,网络参数θ更新的目标函数为:
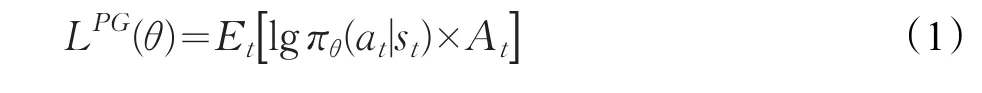
PG算法的最大优势是可以在连续空间中选择动作,缺点是它对步长敏感却很难选择合适的步长。为了改进该缺点,首先采用当前策略下的行动概率πθ(a|s)与上一个策略的行动概率πθold(a|s)比来观察智能体行动的效果,即新旧策略的比值记为:

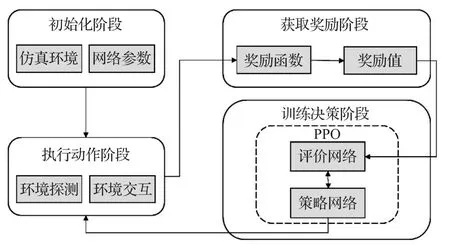
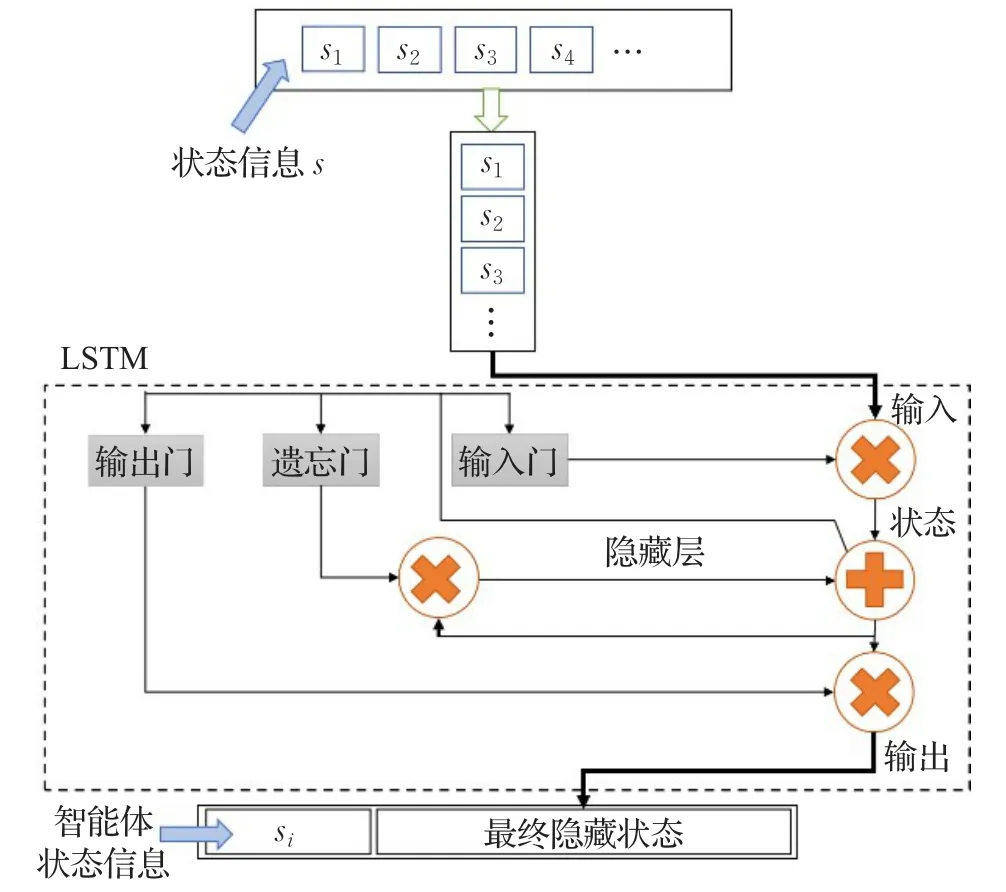
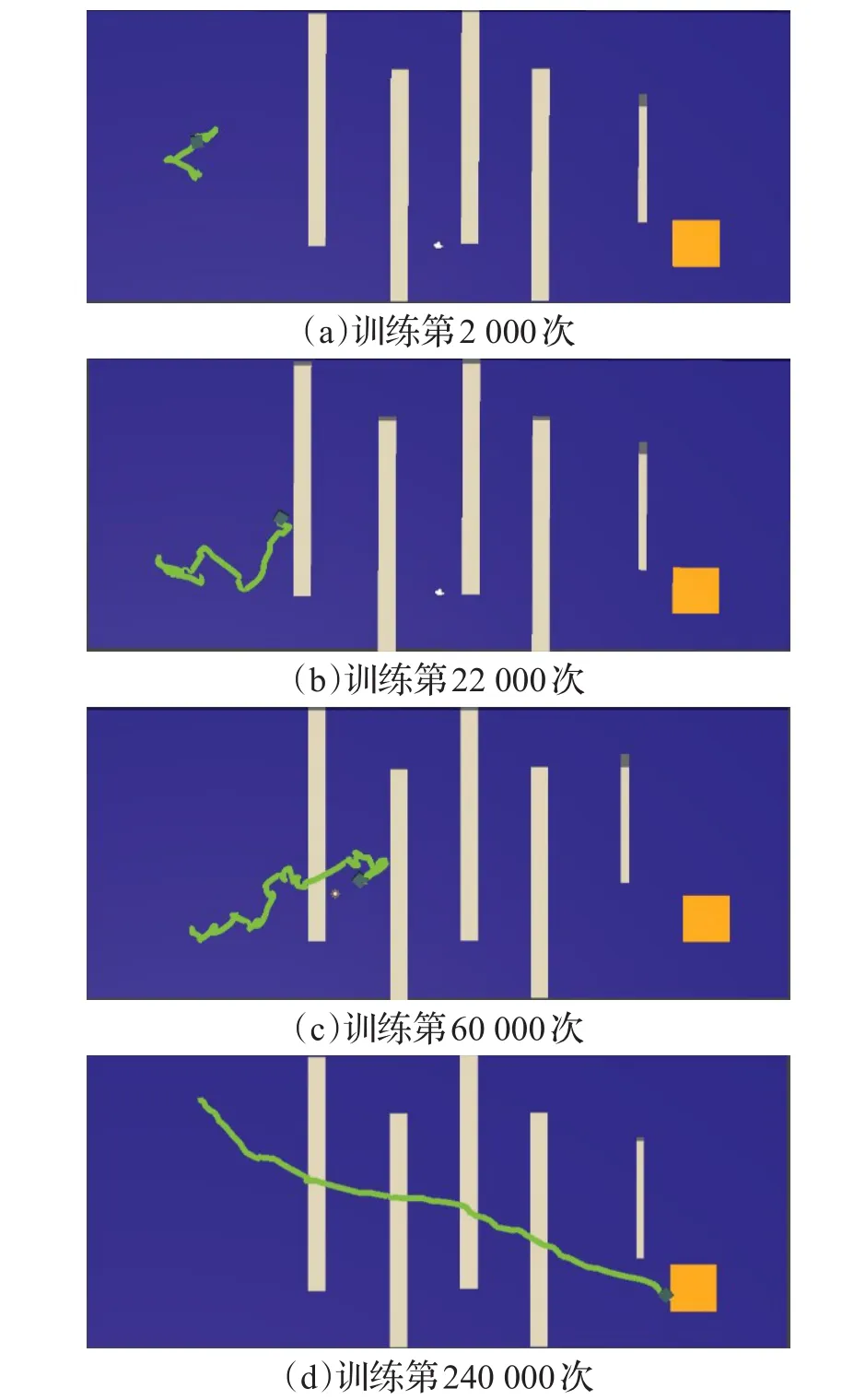
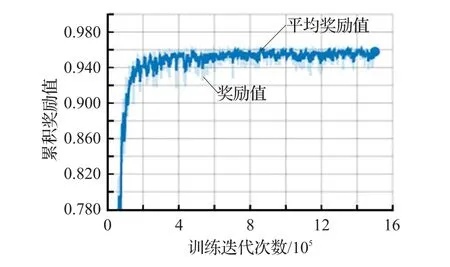
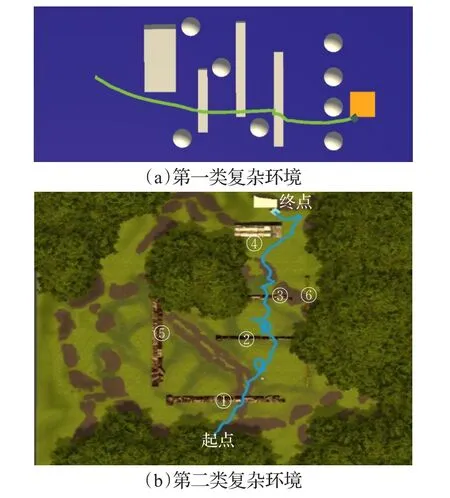
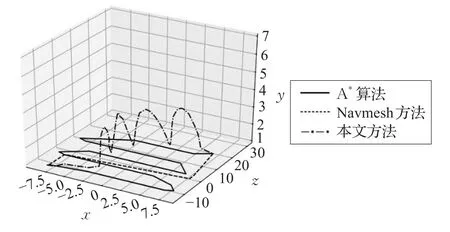
若奖励函数rt(θ)>1,表明在该策略下动作发生的概率高于先前策略,若0 其次,为了避免在参数更新的过程中出现策略突变的情况,则需对目标函数(公式(3))进行约束。PPO算法通过将策略更新约束在小范围内来提高训练智能体行为时的稳定性。PPO算法采用的约束方式有两种:限制KL散度或截断。在实际应用中,研究人员发现使用截断的方法效果更好,则PPO的目标函数优化为: 其中,ε为截断常数用来辅助设定策略更新的范围,通常设置为0.1或0.2;clip函数为截断函数,将新旧策略参数rt(θ)的值限定在[ ]1-ε,1+ε区间,如图1所示。目标函数使用min函数表示选取新旧策略概率比与截断函数中较小的值。 当优势函数A为正时,表示当前行动对优化目标有积极效果,则应增加其出现的概率,但同时要限制其更新范围在1+ε以下。当A为负时,表示当前行为是消极的,则应被阻止同时降低其概率到1-ε。 PPO算法的核心思想是避免采用大的策略更新,解决PG算法中步长难以确定和数据效率低的问题,并且大大降低研究人员调试的难度。 本文主要目标是:智能体在规定步长内找到到达目标位置的合理路径。所谓合理是指区别处理不同高度的障碍物,使得智能体行为路径趋近现实。对于高度小于阈值的障碍物(即低矮障碍)视为可通行的并采用跳跃的形式通过,对于高度大于阈值的障碍视为需避开并采用绕行的方式通过。 本文将PPO算法用于多障碍未知环境下的三维路径规划任务。训练过程由初始化、执行动作、获取奖励和训练决策四个阶段构成,如图2所示。 图2 智能体训练过程示意图 首先,设计了合理的环境状态及动作状态,智能体利用激光探测环境信息并收集数据,然后将这些数据作为特征向量结合奖励函数输入至神经网络中进行训练,最后根据探索策略选择最优动作并输出到达下一个可视的观察。不断循环迭代执行动作、获取奖励和训练决策三个阶段直到训练完成。 智能体的环境模型要考虑目标位置、边界信息还要考虑障碍物的高度和所在位置才能采取合理的行为避免碰撞。本文仿真环境中设置了多种障碍物且高度在一定范围内随机变化。由于连续高维空间的状态及动作数量巨大使得算法较难收敛,因而将智能体周围障碍物等信息离散成有限个状态,合理地制定状态空间。训练中,需要观测的环境信息包括:目标点和智能体相对预设地面的空间位置,以及当前智能体是否在地面上。其次,智能体拥有n条3D测距射线,每条射线的最远测距dmax相同,通过射线感知收集障碍物信息(di,aθ,ftype,ho),其中di和aθ分别表示射线被障碍物阻挡时的长度与夹角,ftype表示射线所触障碍的类型,ho表示该障碍的高度。总的来说,环境状态应该包括智能体瞬时速度(vsx,vsy,vsz)、所在位置(psx,psy,psz)、目标点所在位置(pgx,pgy,pgz)、障碍物所在位置(pox,poy,poz)以及射线信息,则状态可以定义为: 由于智能体在仿真环境中观测的障碍物数量是未知的、非固定的,因而本文在PPO算法的基础上,向环境感知端引入长短时记忆网络,如图3所示,其中虚线框内为LSTM网络内部结构。LSTM是一种循环神经网络结构,可处理的连续数据信息。首先,智能体将每个状态向量si(公式(5))依次输入到LSTM网络,通过遗忘门选择要记忆的先前信息的数量。其次,通过输入门存储当前信息中的有效信息。然后,通过输出门输出有效信息并存储到隐藏状态中。最后,通过最终隐藏状态将智能体的整个状态编码成固定长度的向量输入至PPO网络中。 图3 环境感知模型结构 本文采用离散矢量动作空间定义了四个动作,分别是前向运动、侧向运动、旋转以及跳跃。其中,前向运动包含三种可能行为:前进、后退、无动作;侧向运动包括三种可能行为:左移、右移、无动作;旋转也包含三种可能的行为:左转、右转、无动作;跳跃则包含两种可能行为:跳跃、无动作。每次智能体决定是否跳跃时需要满足以下两个条件: (1)智能体必须靠近障碍物的前部,且障碍物的高度不得高于智能体高度的2倍。 (2)智能体在地面上或在障碍物顶面。 深度强化学习算法中,所有目标都可以通过预期累积奖励的最大化来描述。智能体可以通过与环境互动得到的反馈信号来学习正确的策略。每次实验都包含许多学习回合,当智能体出界或者在规定步长内未到达目的地时结束该回合的学习。为了避免由于稀疏奖励导致学习效率低的问题,本文在主线奖励基础上进行奖励重塑,增加外部奖励机制以及好奇心驱动[19]来提高训练效率和最终性能。 本文惩罚值在−1至0之间,奖励值在0至1之间。当智能体与障碍物发生碰撞或出界时给予惩罚,当智能体到低矮障碍前选择跳跃动作时给予奖励。本文将目标划分为三个子目标:第一、找到一条始于起点止于目标点的路线。第二、不碰撞环境中高于阈值的障碍物。第三、判断障碍物类型,会跳跃通过低矮障碍。由此,外部奖惩函数设计如公式(6)所示,第1行针对主线奖励,第2、3行针对子目标1,第4行针对子目标2,最后以后针对子目标3。除此之外,为了加快智能体训练速度则给智能体每一步的移动一个负奖励,本文设置为−0.000 2。 内在奖励机制则是促进智能体更加积极地探索环境以寻找下一个外在奖励,从而降低因稀疏奖励带来的学习效率低下的问题。 训练决策阶段主要由策略网络和评价网络组成。图4展示了PPO的网络结构,策略网络主要作用是决定策略πθ,它包含新旧神经网络并周期性地更改旧神经网络,本文策略网络设计了3个隐层,每个隐层的神经元是128个,状态s输入到网络中,通过不同的激活函数预测合适的均值和方差,确定正态分布,通过该分布选择智能体即将采取的动作。评价网络根据以往数据评价策略网络的性能指导策略网络更新参数,本文评价网络同样设计了3个隐层,每个隐层有128个节点,状态s输入到网络中后输出状态值函数v,其中状态值函数表示在当前状态下执行该策略获得的累计奖励。 图4 PPO网络结构 本文在Unity3D引擎上进行仿真实验。进行智能体训练的电脑配置如下:硬件环境为Intel®Xeon®CPU E5-2620 v4@2.10 GHz的处理器,内存64 GB,显卡NVIDIA TITAN Xp,软件环境为Unity 2018.3.1f1。 本文设计了两个实验来验证算法的有效性: 实验1基于LSTM-PPO算法的三维路径规划仿真实验。 实验2本文算法与传统算法的对比实验。 5.1.1 环境模型与训练参数 本文设计的基础训练仿真环境具有一定的代表性,如图5所示。整体实验环境为2.5 m×6.0 m,其中障碍物类型 ftype包括2种:低矮障碍以及可移动墙体,4个低矮障碍高度在(0 m,0.25 m)内随机产生,可移动墙体高度为1.2 m,训练中随机进行前后左右移动,移动距离不超过0.15 m。实验将地面中心定为原点(0,0,0),智能体相对地面的起点坐标(−8.2,1,−20.1),目标点为(0.7,1,20)。本实验中智能体是边长0.1 m的立方体,质量25 kg,跳跃阻力3 N,初始移动速度为1.5 m/s,每次跳跃状态持续时间为0.2 s,最大跳跃高度为0.375 m。 图5 单个智能体的基础训练环境 实验采用连续观察向量空间,利用特征向量表示智能体在每一步的观察结果。训练中,需要观察目标点和智能体相对地面的位置。设置射线角度为{0,20,45,70,90,110,135,160,180},射线的最远测距 dmax=1.5 m ,通过两组射线收集障碍信息,获取附近障碍相对智能体的距离、夹角以及该障碍的种类和高度。本文实验观测记录的空间大小为112个。 每个智能体都按照本文所提出的方法不断地学习探索,训练过程中,始终遵循公式(6)进行一定的奖惩。在每一回合规定的最大步长内未到达目的地则−0.5,到达目的地则+1.0。每一回合结束或出现出界的情况则整个场景复位。为了加快训练速度提高训练效果采用多智能体并行训练,虽然10个智能体是独立的个体,但是它们具有相似的观测和动作。本实验总训练次数为1.5×106次,PPO参数设置如表1所示。 表1 PPO算法参数 5.1.2 实验结果与分析 经过8.36 h的训练后,智能体成功从起点出发运动到目标点。图5展示了训练过程中智能体的路线图。图6展示了训练过程中奖励变化情况。 图6(a)~(d)分别为训练第2 000、22 000、60 000与240 000次的结果。图6(a)为训练初期,智能体还没有充分地学习,随机概率较大,此时累计奖励值很低,仅−0.636。图6(b)依旧处于探索阶段,智能体经常碰撞低矮障碍物而不会跳跃通过,到达目标点的次数极少,该阶段的累计奖励值仅−0.169。图6(c)中智能体成功越过第一个低矮障碍但碰撞第二个低矮障碍,该阶段的累计奖励值为0.322。随着训练次数的增加,经过大量“试错”后,智能体逐渐由探索环境的状态变为利用知识的状态,成功率迅速提高。图6(d)为训练中后期,智能体已经能够成功到达目的地,但轨迹选择不稳定,此阶段的奖励值为0.548。随着时间的增加,路径轨迹不断优化,长度缩小。 图7中浅色线条表示奖励值,深色线条表示平均奖励值。图7所示随着训练次数不断增大,智能体所获奖励值也不断增加且逐渐趋近1.0。实验结果表明智能体已经能够根据前方障碍物类型采取不同策略,成功到达终点,完成三维路径规划任务。 图6 本文算法训练过程中的智能体路线图 图7 训练过程中的奖励值 在相同实验环境中,本文将奖励函数分为三种情况进行对比:第一、仅有主线奖励,第二、主线奖励结合外部奖励,第三、在第二种基础上增加内在奖励。仅有主线奖励时,实验失败,智能体未能在规定步长内到达终点。 图8中蓝色线表示第二种仅有外部奖励的训练情况,橙色线表示第三种情况。图中可直观地看到橙色线条在更少的迭代次数达到较优的累计奖励值,在训练130 000次时累计奖励就已达到0.945,而仅有外部奖励的情况下,智能体在训练200 000次时奖励值达到0.94。实验结果表明增加内在奖励对智能体训练更有效率,加快智能体对环境的探索。 图8 基于不同奖励函数的训练情况对比 本文进一步在两类复杂环境中进行训练来验证算法的有效性,第一类由众多基本几何体组合而成,第二类仿真环境则是山地地形。障碍物包括墙壁、高度随机的低矮障碍、平滑的球体障碍、带棱角的不规则障碍及树木等。图9(a)可见智能体能够躲避大型的障碍物,越过低于阈值的障碍物。图9(b)中的树木均不可碰撞,实验结果可见对于路面崎岖不平的地形,智能体也能够成功找到目标点且整体路径较合理但是跳跃轨迹不够优化。 图9 本文方法应用于复杂环境 为了验证本文方法的合理性,将其与三维游戏引擎中最常用的NavMesh方法和二维搜索中较优的A*方法进行比较,如图10所示。三个实验环境相同,四个低矮障碍物的高度分别是:0.05 m,0.2 m,0.1 m,0.05 m,圆球半径为0.15 m。将从路线选择及路线长度这两方面进行对比。 图10 三种路径规划方案路线选择对比 图10 (a)中黑色线条表示A*算法的路线图,A*根据障碍物分布情况全局规划了一条最短路径,避开了场景中所有的障碍物。图10(b)所示为Navmesh导航路线图。Navmesh其实是使用导航网格将3D搜索空间转换为虚拟2D平面进行路线的规划。本实验将所有区域定为可行走区域并参与导航烘焙,设置具有代表性的物体高度为0.2 m,最大可进行斜坡度为15°。图10(b)中智能体直接穿过第一个和第四个低矮障碍物,避开其余障碍物,缺陷是速度固定,避障行为单一。图10(c)所示为本文算法结果。相比前两种算法的完全性避障及速度固定,本文算法的避障行为更加智能,对于不同高度障碍采用不同避障策略,路线更加合理。图11为本次实验中三种方法的运动路径及长度的对比图,直线线条是A*算法的路径,总长度为97.85 m,虚线线条是Navmesh算法的路径总长度为46.42 m,本文算法路径长度为44.34 m。 图11 三种路径规划方案路线及长度对比 本文使用新的思路来解决避障问题,对于模拟场景中的不同类型的障碍物,针对性地采用不同的策略进行避障。由于智能体采用跳跃行为,本文算法最终计算得出的路线并不是在任意环境中都绝对最短,但始终是较为合理的路线选择。 本文提出了一种基于深度强化学习的三维路径规划算法,实现更合理地选择路线及避障方法。将改进的近端策略优化算法用于具有多类型障碍的三维未知环境中,无需任何先验知识,智能体经过反复试错找到较优的路径。本文首先采用虚拟射线获取仿真环境信息,将连续状态空间离散化输入至长短时记忆网络,其次,提供了智能体动作状态,然后,设置外部奖惩函数同时结合好奇心驱动促使智能体学会处理不同的障碍物。最后,利用PPO截断项机制优化策略更新的幅度。实验结果表明本文算法能够有效地应用在包含复杂障碍的未知环境中,学会对于不同障碍采用不同的处理方式,且路线更加符合实际情况。 下一步,将进一步完善本文算法,优化智能体跳跃轨迹减少跳跃抖动,并尝试用于类人形智能体的三维路径规划中。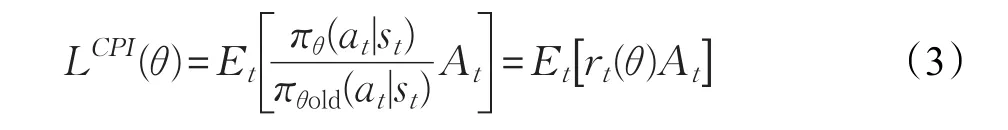

4 本文算法
4.1 状态空间与动作空间

4.2 奖惩函数

4.3 网络结构

5 实验结果与分析
5.1 仿真实验



5.2 对比实验

6 结论
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
创新作文(1-2年级)(2019年4期)2019-10-15
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
