
译者视野三角形下译本词汇秩频分布的复杂动态自适应过程∗
2020-08-24 07:37蒋跃王乐韬马瑞敏
外语学刊 2020年1期
蒋跃 王乐韬 马瑞敏
(西安交通大学,西安710049;长安大学,西安710054;西安交通大学,西安710049)
提 要:本研究将计量语言学领域的作者视角三角形、词汇秩频分布及h 点的理念应用于4 位译者32 个译本片段的翻译对比研究中,考察不同译本在基于h 点上的译者视野三角形上和词汇秩频分布的差异。 研究发现,(1)译本的译者视野和功能词视角的变化主要受原文本的影响,不同译者的译本在词汇层面的差异主要集中在实词视角,即实词丰富度上;(2)母语译者的实词丰富度明显高于非母语译者;(3)译者视野三角形3 个视角的指标之间具有协同关系,因而从回顾角度客观折射出翻译过程的复杂动态属性和自适应属性。 研究证明,基于译者视野三角形可以观察各个译本之间的词汇秩频动态分布,尤其是可以倒推出翻译过程中译者在词汇使用上有意识和无意识的调控过程。 因此,词汇秩频分布和译者视野三角形对于译本对比和翻译过程研究具有一定的理论和实用价值。
1 引言
从理论上讲,但凡有交流,必会有翻译(宋以丰2019:103)。 译本对比一直是译学界关注的话题,但如何客观和科学地对比译本却一直没有完满的解答。 传统的译本对比研究以内省式的定性研究为主,因缺乏实证和数据支撑而缺少科学性和可解释性。 自上世纪末以来,Baker 等将语料库用于研究译本对比、译者风格对比和译者识别,等等,取得一些成就(王克非2012:84),使译本对比逐渐具有一些科学的范式和方法。
然而,基于语料库的译本对比研究也存在一些不足。 比如,在哪些计量指标可以全面有效地反映译本的语言风格这个问题上,迄今尚无一致的看法。 其次,仅依靠从翻译语料库中提取的统计数据,如标准类形比、平均句长、词汇密度等,并不能有效地将一个译本的语言特征与另一个译本的区分开。 并且,尽管不同译者在某些指标上具有显著差异,但并不足以说明这些译者之间风格上的整体差异,以此确认不同译者风格并不十分可靠,因为这些数据只是相对抽象的指标的数字集合,单个的计量指标只能反映部分而非译本整体的语言特征(黄立波 朱志瑜2012:67)。 另外,这些常规方法只能提供语料具体层面的有关数据,却不能解释这些数据的意义与内涵,也不能解释相关的翻译现象、翻译本质以及翻译过程中译者的心理活动(胡开宝2011:196),因而,很难系统、深入和客观地反映译本之间的本质性区别。因此必须探索新的视角,才会找到能够系统、深入和客观地反映译本语言特征的计量指标。
而新兴的学科交叉深入的计量语言学以及与之相关联的协同语言学和复杂系统理论或许能弥补上述译本研究中的一些缺陷。 语言是人类存在的家园,人类通过语言构建并拥有世界(冯全功胡本真2019:98)。 协同语言学认为,语言是一个自组织和自调节的系统,是一个特殊的动态适应系统(刘海涛 黄伟2012:185)。 韩红建和蒋跃在Köhler(1986:45)的协同语言学及Holland(1995:73)的复杂适应系统理论的基础上提出,翻译也是一个动态复杂的自适应系统,译者个人翻译能力的发展、翻译过程和翻译研究都具有复杂性和动态性的特点(韩红建 蒋跃2017:25),而传统的语言风格特征指标并不能体现翻译作为一个复杂的自适应系统的特点。 在一定程度上,对这些语言风格特征的考察是孤立和片面的,彼此之间没有联系,缺乏系统的考量。 这些指标所显示的规律更像是翻译文本表现出的一种共性,只能反映译本的一些表层特征,而非译本内部深层的特征(黄立波 朱志瑜2012:70)。
本研究尝试从计量语言学领域引入词汇秩频分布(rank⁃frequency distribution)相关指标作为研究方法。 词汇秩频分布是指文本中词汇的词频(frequency)按照频序(rank)的分布。 词频最高的词频序为1,次高的频序为2,以此类推就得到文本的词汇秩频分布。 如此做法原因有三:第一,词汇秩频分布是对文本全体词汇的考察,所以,相对传统的语料库方法,能够比较全面地反映整个文本在词汇使用上的特点;第二,它是对文本的动态反映,每个词的词频变化都会引起整个词汇秩频分布曲线的变化;第三,它是基于数学模型的文本研究,是将文本词汇层面特征进行量化的一种手段,因而能够精确地反映整个文本的词汇特征。文本秩频分布作为计量语言学的研究范畴,充分体现计量语言学“精确、真实、动态”的特点(刘海涛2017:1)。 基于词汇秩频分布的研究是计量语言学对文本中词汇丰富度和文本产生过程研究的一个重要方法。 借鉴该方法,或许能够帮助我们更客观地观察对比译本的语言风格,了解译本词汇丰富度变化的动态过程,并且保证研究结果的可解释性。
1935 年,Zipf 提出词汇秩频分布研究中最著名的定律——齐普夫定律(Zipf's Law)(Andrade 1935:93)。 2006 年,基于该定律,Popescu 首次将科学计量学中h 点(h⁃point)的概念引入词汇秩频分布研究中,并证明h 点作为实词与功能词模糊界限的作用(Popescu, Altmann 2006:24)。 所谓“h 点”是文本中词汇秩频分布中的一个临界点,其前多为功能词(synsemantics),其后多为实词(autosemantics)。 因此,h 点的取值反映文本中的词汇丰富度,可用于诸如语言类型特征和文体特征的计量研究(刘海涛2017:134)。 2007 年,在h点的基础上,Popescu 和Altmann 又拓展出弧长和作者视野(Popescu, Altmann 2007:71)等指标用于区分不同语言和文体。 这几种指标的结合使用或许可以动态地反映文本中作者视野对文本实词和功能词秩频分布的动态变化和词汇丰富度的影响及协同作用。
本研究尝试通过将词汇秩频分布和作者视野及相关指标引入译本对比研究,用以描述和比较不同译者的译本在实词和功能词及词汇丰富度上的差异和调控过程,并尝试从协同语言学的角度对这些差异进行解释。 本研究拟解答如下问题:
(1)基于h 点的相关指标能够得出不同译本在词汇秩频分布上有哪些不同;
(2)译者视野如何影响译本中的实词与功能词之间的秩频分布关系;
(3)译者视野构成的h 点三角关系与翻译过程中词汇丰富度的变化有何关系。
2 语料与方法
2.1 语料提取与加工
本研究使用的语料为鲁迅的5 部中短篇小说的20 个不同的英译本,共4 位译者。 作为一位伟大的文体家,鲁迅的作品具有语言凝练、简洁而又富有回味的独特的风格,极具中国现代文学语言和风格的代表性。 其小说在海外颇具影响,译本众多,是译本对比理想的语料来源。 选取同一个作家的原文本和不同的译本可保证原文本风格一致而增强译本间的可比性,比较适合本研究的目的。 原文小说分别为《阿Q 正传》《风波》《故乡》《孤独者》和《在酒楼上》。 语料都经过数字化加工和人工清理降噪,译本总词数302,307,语料情况见表1。
h 点的位置会受到文本总长度N 的影响。 不同原文的译本在字数上差别较大,也就会相应地导致各译本h 点距离的不同。 为最大程度地保证译自不同原文本和文本长度不一的译文之间的可比性,本研究从20 个译本中截取出32 个2500 字左右的文本片段,且确保截取的译本片段与原文片段对应。
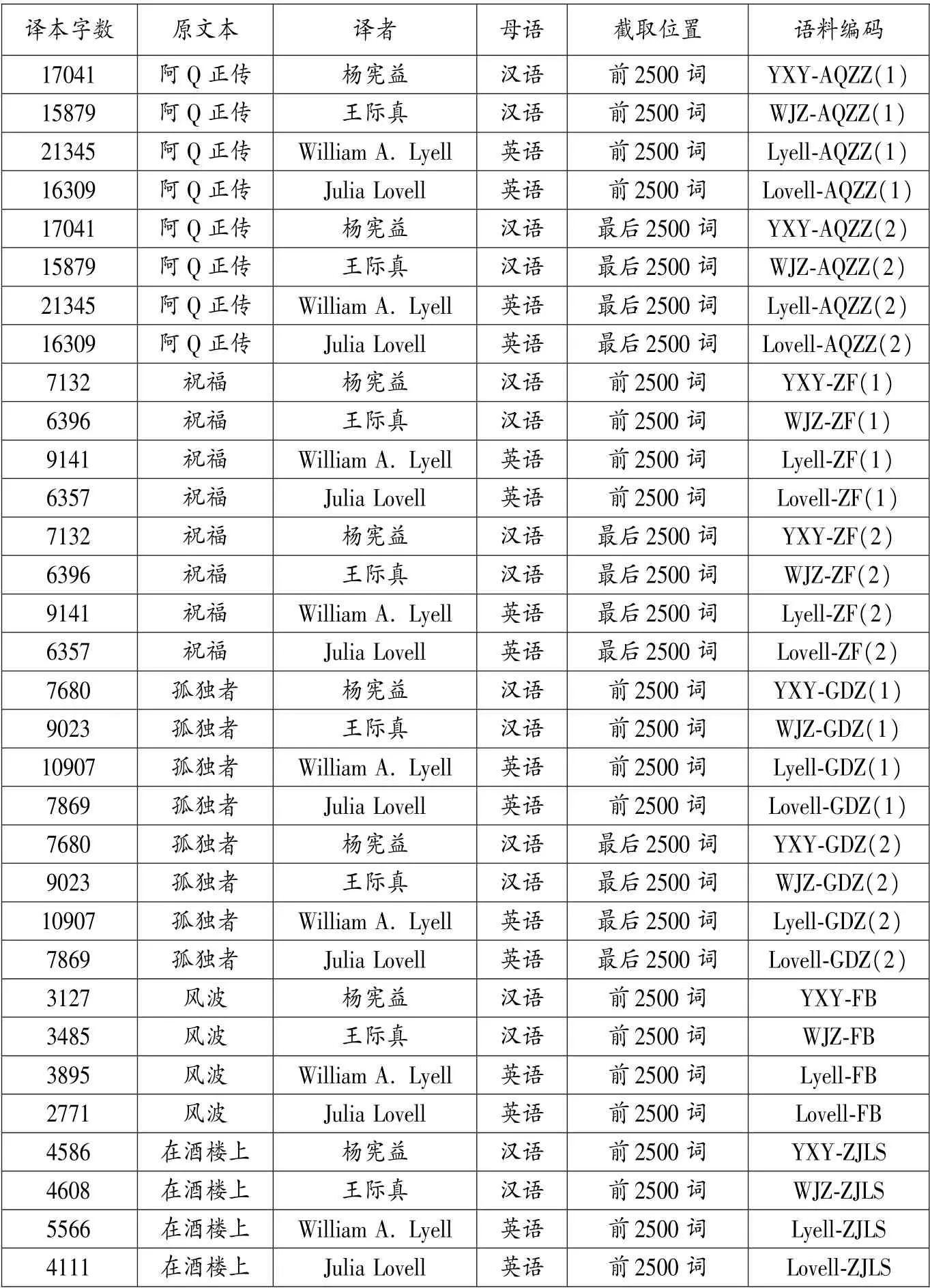
表1 语料情况
2.2 词汇秩频分布与h 点相关指标的选取
计量语言学认为,词汇秩频分布与h 点相关指标可以精确代表文本中的词汇丰富度(vocabu⁃lary richness),即可以用于诸如语言类型特征和文体特征的计量研究(Popescu, Altmann 2006:26)。 因此,这些指标也适合本研究译本对比的目的。
文本的词汇秩频分布就是每个词按照出现次数的多少从大到小进行排序的分布(f(r))。 根据齐普夫定律,它应该是一种幂率分布,也叫“长尾分布”。 Popescu 指出,h 点是实词与功能词的模糊分界线(同上:79),他在译本文本中的实验也得出类似的结果(同上2007b:80),说明我们可以借鉴它并应用于译本对比研究中。 如图1所示,h点是直线y =x 与词汇秩频分布曲线的焦点,其公式为:

图1中h 点以上大部分词汇为功能词。 在非小说文体中,h 点以上的实词为主题词,在小说文体中,h 点以上的实词除主题词之外还包括人名、地名等。 h 点以下的词汇大多为实词(Popescu et al. 2009:23)。

图1 h 点示意图
以秩频分布曲线的起点(P2),h 点(H)与秩频分布曲线的终点(P1)为顶点构造出一个三角形。 P2点的纵坐标f(1)即频序为1 的词的词频,P1点的横坐标V 是最后一个词频为1 的词的词序,即文本的类符总数。 可以想象,作者以h 点为基点有意识或无意识地调控文本的实词与功能词之间的平衡(同上2007,2009)。 虽然García 和Martín(2007:49)通过测算译本的功能词密度(functional density)来区分译本,但没有基于词汇秩频分布,所以看不出译者对两类词的调控情况。从叙事学的角度,这也可以理解为由于译者从自己的叙事角度(α 角)在翻译过程中有意识或无意识地调整功能词与实词的比例,从而造成译本词汇丰富度的变化。 此外,功能词密度及词汇丰富度一直是译本语言风格的一种常用的计量特征。 同样地,P1和P2点也可以视为是作者分别调控功能词与实词数量的基点。 以这3 个点为顶点的角α,β和γ分别代表作者视野(writer's view)、实词视角(autosemantic view)和功能词视角(syn⁃semantic view)(Popescu,Altmann 2006:26)。 鉴于翻译文本从本质上等同于文本,加之Popescu和Best 等人也用译本对writer's view 做过相应的实验(Popescu et al. 2007a:58;Popescu, Altmann 2007b:71),作者视野的概念也适用于译本研究。在对译本的对比研究中,译者视野α角的变化,也会影响译者基于h 点在翻译过程中对译文的实词与功能词的调控,故以下我们将其称为“译者视野”(translator's view)。
α,β和γ角的角度可以通过计算其余弦值获得。 我们以HP2为向量a,HP1为向量b,P2P1为向量c,译者视野α 的余弦值为:
由于直接比较不同文本的词汇秩频分布曲线难度较大,Popescu 等(同上:88)引入词汇秩频分布三角形来简化对分布曲线的描述(参见图2)。


图2 词汇秩频分布三角形
将H 点与P2 点坐标带入(2.2)得到:
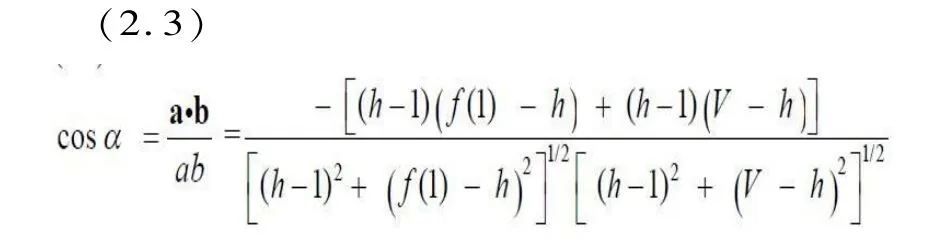
同样地,实词视角β 的余弦值为:
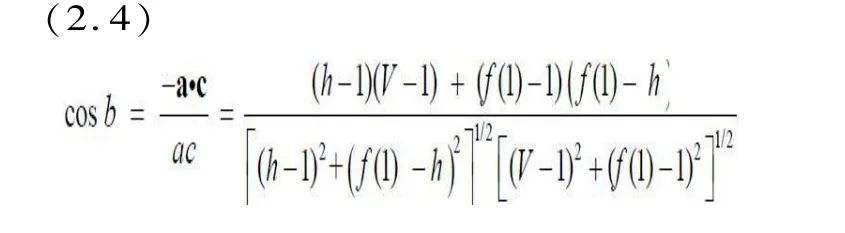
功能词视角γ 的余弦值为:

由cosα,cosβ和cosγ可以推算出三个角的弧度值,且α+β+γ=π。α,β和γ角的弧度值也可作为语言和文本类型相关研究的参数(Popescu,Altmann 2007b:81)。
3 结果与讨论
用Wordsmith 生成每个文本的wordlist,据此得出相应的词汇秩频分布。 后用Excel 算出相应的角度余弦值及α,β和γ的弧度值(arc length),生成数据集。 最后,用SPSS 对得出的数据进行统计分析和方差检验,从而判断每个译本在词汇秩频分布上的异同。
3.1 三角形的构建与相关指标的计算
研究提取出32 个语料片段的wordlist,据此计算出词汇秩频分布曲线顶点(P2)、终点(P1)及h点(H)位置,并使用Popescu 等(2009:24-27)的公式计算出所有三角形α,β和γ角的余弦值,进而求出每个角的弧度值。 具体数据如表2所示:

表2 词汇秩频分布顶点与三角形弧度值相关数据
3.2 数据的解读与可视化
为探究翻译自不同原文本的译本在词汇秩频分布三角形方面有哪些异同,从而考察各个译本的词汇丰富度和相应的实词与功能词比例,本研究将32 个译本依据不同的原文本片段分为7 组(同上),对表2数据进行单因素方差分析(ANO⁃VA)。 结果显示,译自不同原文本的译本在译者视野(α)上具有显著差异(F =6.434,p =.000),在实词视角(β)上不具有显著差异(F =1.250, p=0.316),但在功能词视角(γ)上却具有显著差异(F =13.584,p =.000)。
另外,为探究不同译者的译本在词汇秩频分布三角形方面有哪些异同,研究将32 个译本依据4 位译者分成4 组,对表2的数据再次进行单因素方差分析。 结果显示,来自不同译者的译本在译者视野(α)上不具有显著差异(F =1. 634,p =0.204),在实词视角(β)上具有显著差异(F =8.297, p =.000),在功能词视角(γ)上不具有显著差异(F =0.646,p =0.592)。
为解释以上统计结果,基于表2的数据分别得出4 位译者词汇秩频分布三角形的平均水平(表3)。 为直观地比较不同译者在词汇秩频分布上的异同,将4 个三角形汇总于同一坐标系中进行直观比较(参见图3)。

图3 4 位译者的词汇秩频分布三角形的平均水平
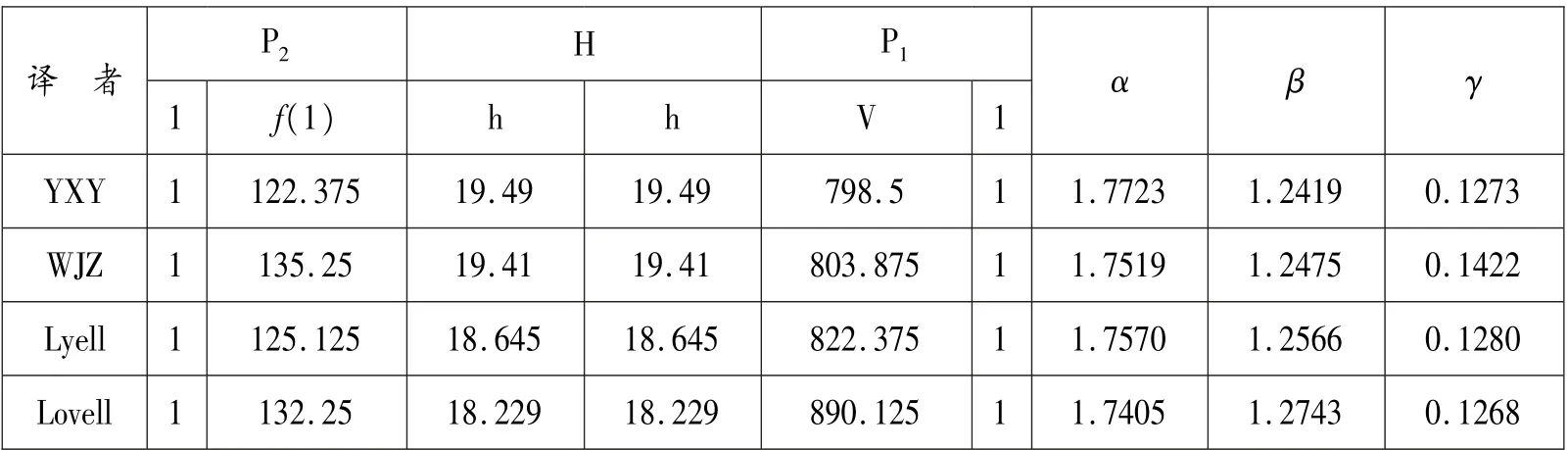
表3 4 位译者词汇秩频分布三角形的平均水平
通过以上数据分析我们发现,在原文本相同且各译本的译文字数相同的条件下,4 位译者在实词与功能词的使用方面均有不同。 表3表明,杨宪益(YXY)的P1和P2点都较低,王际真(WJZ)的P1点较高,P2点也较高,Lyell 的P1点较高,P2点较低,而Lovell 的P1和P2点都较高。 在h 点方面,英语为母语译者的h 点位置略微低于汉语为母语的译者,但无显著差异。 图3中,4 位译者的h 点位置几乎重合,说明不同译本的实词与功能词数量之间的比例并不存在显著差异,也说明原文对各译者的遣词造句(词汇丰富度)的调控作用比较大,且比较均等;从另一个角度看,4 位译者对原文都比较忠实。
虽然4 位译者的P1,P2点位置均有差异,即在实词和功能词数量等单独的指标上均存在差异,但方差分析结果显示,4 位译者的译本只在实词视角(β)上有显著差异。 而在译者视野(α)和功能词视角(γ)上不存在显著差异。 说明原文本对译文的译者视野和功能词视角具有显著影响,而实词视角主要受译者影响,与原文本之间的关系并不明显,或许说明译者译本的个体风格主要体现在实词的使用上。 那么,产生上述现象的原因是什么? 为此,我们借鉴计量语言学框架下协同语言学的相关理论对上述现象进行解释。
产生上述看似矛盾的现象的原因在于3 个视角存在协同关系。 译者视野、实词视角和功能词视角的弧度值大小同时与三角形3 个顶点的位置有关。 如β角由P2点的位置和HP1间的距离共同决定,γ角由P1点的位置和HP2间的距离共同决定,而α角则由H 点位置和HP1与HP2的比例共同决定。 而且,由于α+β+γ=π,致使每个角的弧度都受到另外两个角的影响和制约,且每个角度的变化并不只体现单一自变量的作用,而是体现不同因素的协同作用。 这与Köhler(1986:45)提出的协同语言学主要观点和韩红建与蒋跃(2017:19)关于翻译作为动态复杂自适应系统的主张相符,即翻译语言各类特征的相互作用表现为3 个角的弧度值与3 个顶点之间的协同关系。因此,不同于传统的语言特征计量指标,α,β和γ角共同构成一个相对复杂的动态自适应系统。 在这样的动态自适应系统中,每个指标之间相互影响和相互制衡。 译本中词频的微小变化都会使这个系统发生整体的改变,起到牵一发而动全身的效果。 以上指标表现的这些特征与协同语言学和复杂动态系统理论不谋而合,本文通过对译者视野三角形下译本词汇秩频分布和变化的研究,反过来通过译本分析和研究翻译过程中译者对实词和功能词比例(即词汇密度)的有意识和无意识的调控。 对这个过程的回顾可以反映出翻译作为一个动态复杂自适应系统的诸多特点。 所以,与基于语料库的传统语言计量指标相比,这些指标不仅能够更加全面和系统地反映译文的词汇使用状况,提供比传统指标更大的信息量,而且还可以从宏观和动态的角度反映不同译本的语言风格和译者在词汇密度调控的动态过程。
3.21 在译者视野(α)方面
译自不同原文本的译文在译者视野上有显著差异,而不同译者的平均译者视野大小没有显著差异,说明译者视野大小主要受到原文本的制约。不同原文本小说的不同主题会导致作者视野的不同,译者在翻译时基本遵循原文的叙事结构和叙事角度,因此很容易理解不同原文本的译者视野有所区别。 而在对同一原文本进行翻译时,4 位译者的译者视野大小基本相同,说明其对实词和功能词的调控作用不存在显著区别。 这一现象反映出,不同译者的翻译风格和语言特征并不会对小说在词汇层面的整体风格造成影响。
3.22 在功能词视角(γ)方面
译自不同原文本的译文在功能词视角上有显著差异,而不同译者的平均功能词视角大小没有显著差异,说明功能词视角大小主要受到原文本的制约。 这种现象一方面由原文本的叙事结构决定,另一方面又由语言内部的自组织与自适应的特性决定。 Popescu 等提出,每种语言的α,β和γ角的弧度值都有特定的变化范围,超出规定范围的文本将难以被该语言的使用者所接受(Popescu et al. 2009:33)。 所以,在译文实词视角因译者不同而变化的同时,受到目标语句法的限制和影响,功能词视角也在随之变化,以适应目标语的词汇分布体系,使功能词视角的大小保持在合理的范围内。 只有这样产出的译文才能在完整传达原文本信息的同时,被目标语读者所接受。 因此,4位译者的译本在功能词视角上不存在显著差异这一现象实际上是词汇秩频分布作为一个动态复杂自适应系统自我调节和自我平衡的结果。
3.23 在实词视角(β)方面
不同译者的平均实词视角大小具有显著差异,而译自不同原文本的译文在实词视角上没有显著差异,对表3、表4和图3的定量与定性分析结果均显示,Lovell 译本的实词视角(β)弧度值在4 位译者中最大,平均为1.274268;Lyell 次之,平均为1.256593。 这表明,两位汉语母语译者的平均实词视角要小于英语为母语的译者,王际真为1.24751,杨宪益为1.241944(参见图4)。
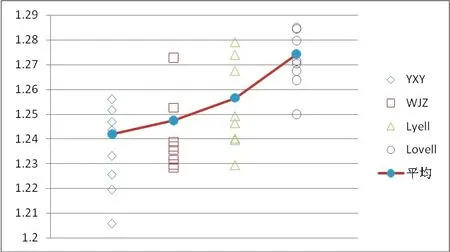
图4 4 位译者的平均实词视角比较
对译文中单现词(hapax legomena)和实词标准重复率(relative repeat rate)的考察发现,在不同译者的译文中实词的数量和重复率存在较大差异(参见表4)。 表4显示,4 位译者的平均单现词数量和实词标准重复率差异较大,且同样符合Lovell >Lyell >王际真>杨宪益的排序。 由于词汇秩频分布曲线为长尾分布,所以单现词数量对曲线的跨度有显著影响,即单现词数量越多,曲线“尾巴”越长,导致实词(β)弧度值越大。 这说明4 位译者在实词视角上表现出的差异主要归因于不同的实词数量和重复率。
统计分析结果表明,在译本字数相同的条件下,4 位译者的平均实词视角(β)有显著差异,且Lovell >Lyell >王际真>杨宪益,说明4 位译者在实词丰富度上差异显著,两位英语母语译者的单现词多,词汇重复率低,词汇丰富度显著高于汉语母语译者,似乎反映出词汇丰富度与译者不同的翻译方向有关(Lonsdale 1998:63-64)。 有研究者发现,由非母语译入母语的文本,在某些语言特征项上,确实更加靠近其母语原创文本的特征;而由母语译出到非母语的文本,具有更典型的翻译文本的特征(詹菊红 蒋跃2017:81)。 Lovell 和Lyell 乃母语为英语者,属于将汉语作品译入到自己的母语中,而杨宪益和王际真则正好相反,属于译出译者。
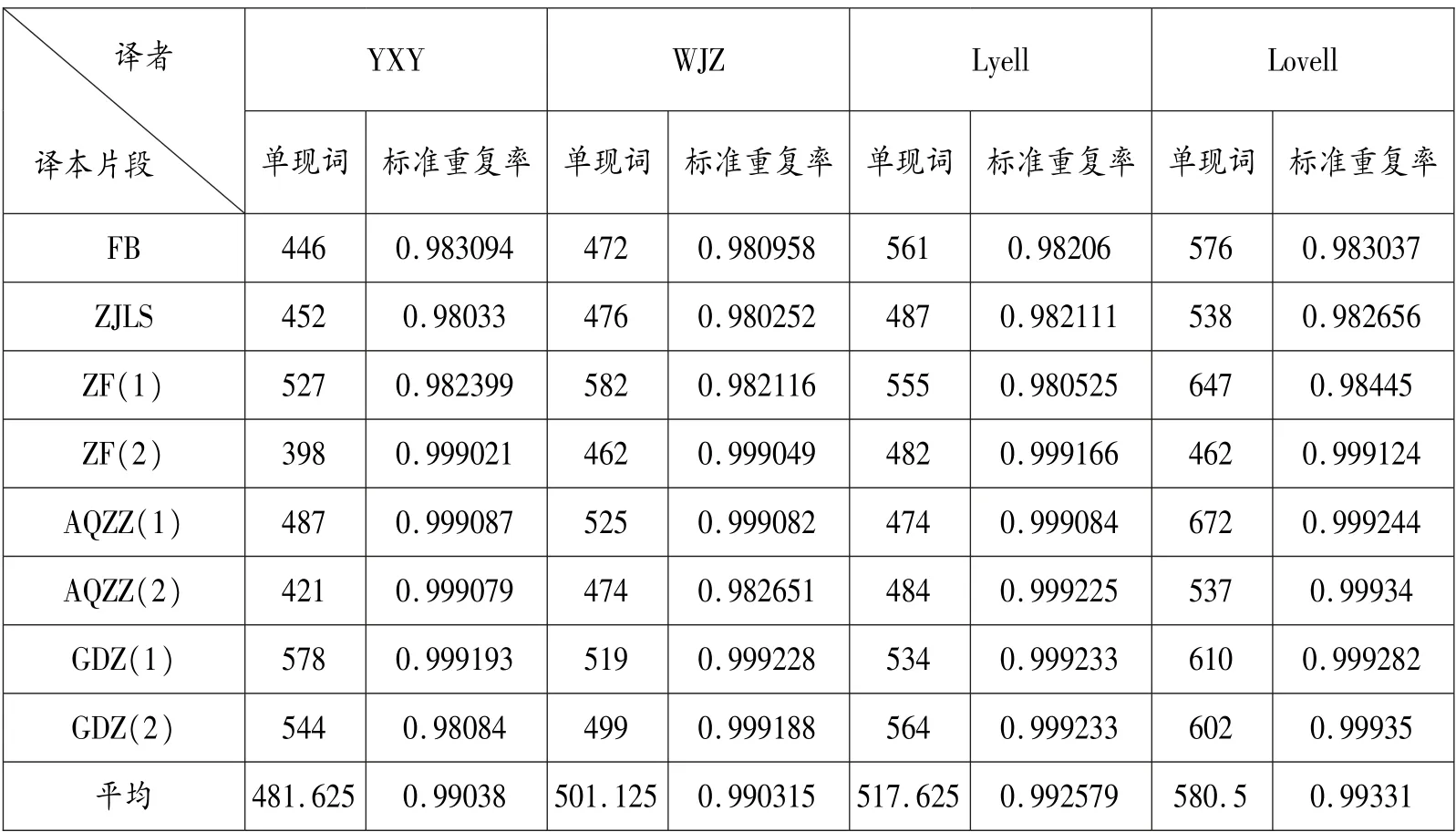
表4 32 个语料片段中的单现词与实词重复率统计
4 结束语
通过将h 点与词汇秩频分布相关指标应用到32 个译本的翻译对比研究中,借用作者视野构成的h 点三角关系来解释翻译过程中词汇丰富度的变化,本研究发现,译本的译者视野(α)、和功能词视角(γ)主要受到原文本的影响,与译者关系不大。 而不同译者在词汇层面的语言风格差异主要体现在实词视角(β)上,反映出不同译者的词汇丰富度与用词重复率的不同。 且4 位译者按照实词视角从大到小排序为Lovell >Lyell >王际真>杨宪益,说明两位英语母语译者(即译入译者)的词汇丰富度大于两位汉语母语译者(译出译者),在一定程度上体现出不同的翻译方向、不同语言和文化背景的译者在目标语词汇使用熟练程度和多样性上的差异,与翻译方向有关(Lonsdale 1998:63-64,詹菊红 蒋跃2017:81)。
更为重要的是,词汇秩频分布和h 点相关指标表明,译者视野、实词视角和功能词视角3 者之间呈现出一个复杂的自适应的动态过程,说明翻译过程也是各种因素和关系自我适应、自我组织和相互协同作用的动态的复杂系统(韩红建 蒋跃2017:24)。 其中,译者视野和原文本对译者视野三角关系具有决定性作用。 译者视野对译本词汇丰富度(即实词与功能词比)具有协同和调控作用,译者视野、实词和功能词形成的三角具有协同关系,从而构成一个复杂的自适应动态系统。 从译者视野三角,可以回顾性地反射各个译本之间的词汇秩频动态分布,尤其是可以观察到翻译过程中译者在词汇使用上有意识和无意识的调控活动。 根据描写翻译学理论,译本是翻译过程的终结,译本研究属于产品为导向的描述性研究(product⁃oriented)(Holmes 1988:27),在产品中很难观察到翻译的过程。 然而,本研究透过对译者视野三角形中译本词汇秩频的分布和变化,反过来分析和研究翻译过程中译者对实词和功能词比例的有意识和无意识的调控,实施对翻译过程的回顾性观察,这一点传统语料库翻译学和描写翻译学研究难以做到。
在未来的相关研究中,可以考虑将词汇秩频分布的其他相关指标和作者视野三角形与如lambda、词汇丰富度(R2)、主题集中度(thematic concentration)、重复率(repeat rate)、单现词(ha⁃pax legomana)、动词间距(verb distance)等(Po⁃pescu et al. 2009,刘海涛2017)结合起来,构成一个基于计量语言学词汇秩频分布的计量风格学模型,用于全面和系统地对比译本、考察翻译中词汇丰富度变化协同调控的动态过程,为翻译研究的科学化和为计量语言学拓展新的研究领域做出贡献。
猜你喜欢
名作欣赏(2020年24期)2020-08-20
红楼梦学刊(2019年5期)2019-04-13
红楼梦学刊(2019年4期)2019-04-13
红楼梦学刊(2018年5期)2018-11-23
读与写·下旬刊(2017年3期)2017-04-27
科学家(2015年2期)2015-04-09
语文周报·教研版(2014年11期)2015-01-17
读者(2014年18期)2014-05-14
收藏·拍卖(2009年12期)2009-12-28
试题与研究·高考语文(2009年1期)2009-04-16
