
基于参数迁移的蒙汉神经机器翻译模型
2020-09-09 03:09王宇飞苏依拉赵亚平孙晓骞仁庆道尔吉
计算机应用与软件 2020年9期
王宇飞 苏依拉 赵亚平 孙晓骞 仁庆道尔吉
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
机器翻译是自然语言处理中的一个最早的研究分支,从1946年第一台计算机诞生之日起,机器翻译就作为计算机自然语言处理的一个重要研究领域受到了人们的广泛关注[1]。
机器翻译的发展历程主要经历了基于规则的机器翻译[2]、基于实例的机器翻译[3]和基于统计的机器翻译[4]。20世纪90年代初,随着互联网的兴起,统计机器翻译在自然语言处理领域取得了较为理想的结果,基于统计的机器翻译方法逐渐成为主流。之后随着深度学习的兴起及其在计算机视觉等领域取得了不错的进展,深度学习[5]在自然语言处理中得到了广泛的关注,为解决自然语言处理中稀疏特征容易拟合、对语言结构缺乏描述能力等问题提出新的思路。2014年以来,端到端的神经网络机器翻译[6-7]得到了迅速发展,基于神经网络技术的机器翻译方法在多个平行语言对中表现显著超过了传统的统计机器翻译[8]。
端到端神经机器翻译应用一种“编码器-解码器”的框架,它的核心思想是通过训练神经网络,找到源语言文本和目标语言文本之间的一种映射关系,直接将源语言映射到目标语言。“编码器-解码器”方法简化了传统的机器翻译方法的过程。同时神经网络机器翻译很好地缓解了机器翻译中存在的长距离依赖问题。对于不同种类的语言而言,可能存在独有的语法和语言规则,其中最明显的区别之一就是不同语言之间的句子、词语顺序存在的差异,由此带来了将源语言映射为目标语言时的长距离调序问题。神经网络机器翻译通过引入长短时记忆LSTM(Long Short Term Memory)循环神经网络和注意力机制[9]来捕获长距离依赖[10],从而显著提高了机器翻译译文的流畅性和可读性。
内蒙古地区和蒙古国的官方用语为蒙古语,但是由于地域、经济和技术发展等各方面因素的制约,蒙古语相关的自然语言处理研究起步较晚、蒙古语语法特殊性以及蒙古语形态变化相对复杂使得蒙汉翻译的研究进展相对缓慢[11]。目前相关的蒙汉机器翻译取得了一定的研究成果,但无论是传统的基于统计的机器翻译还是基于神经网络的机器翻译方法,其得到较好的翻译模型通常都需要大量的、高质量的以及包含各个领域文本内容的双语平行语料库作为神经网络的训练数据。
蒙汉平行语料库相较于大语种例如英汉(英语和汉语)、英德(英语和德语)等而言,目前还处于较为匮乏的阶段,而平行语料库规模的不足直接影响到神经网络训练模型的结果,在这种情况下的蒙汉机器翻译的译文质量依然有待提高。因此,如何利用目前数量、规模有限的平行语料得到效果较为理想的机器翻译模型已经成为一个十分重要的研究方向和内容。蒙古语属于乏资源语言,因此本文将迁移学习策略引入到蒙汉神经机器翻译中来缓解平行语料库缺乏的问题。首先利用大规模的英汉平行语料库进行训练,得到质量较高的翻译模型后将其参数迁移至蒙汉神经机器翻译的过程中,即使在蒙汉平行语料库规模较小的条件下,相较于之前直接训练的结果,迁移策略对最终的翻译译文质量也有一定提升。同时为缓解未登录词的影响,进一步提高翻译效果,本文对汉语语料进行分词,对蒙古语语料进行BPE分词预处理,对蒙汉平行语料使用Word2vec预训练词向量。
1 相关技术
1.1 语料库的预处理
向量化单词或词语是将语料输入神经网络的首要工作,英语文本中单词之间本身存在空格作为分隔符,因此无须再进行基础的分词处理。而汉语并没有天然的标志将词语分隔开来,大部分是短语或者整个句子之间才有标点符号。如果把整个短语或句子直接转化为一个固定维度向量的表现形式,这会降低句子的语言表达力,加大神经网络学习语言模型的难度,所以汉语语料库的预处理是必要的。
本文采用基于统计的分词方法,其方法为在给定大量已经分词的文本的前提下,利用统计机器学习模型来学习语言的词语切分规律,以此来实现对未知文本的切分。本文采用jieba分词对汉语语料进行处理。
蒙古语在构词上属于黏着语并且形态丰富[12],黏着语的一个特点是通过在词根的前缀、中缀和后缀接其他构词成分作为派生新词的手段。所以在蒙汉机器翻译的实践中,未登录词的问题也不容忽视。针对该问题,本文采用字节对编码(Byte Pair Encoding,BPE)技术对蒙古语语料库进行预处理操作,只对语料库中低频词进行分词操作,从而提高低频词的子词的共现次数,这样对蒙汉翻译中的未登录词问题达到一定的缓解作用。本文以5 000操作数对蒙古语语料进行了BPE的预处理,图1为未进行分词处理的蒙古语,图2是经过BPE分词处理后的蒙古语语料。

图1 未经过分词的蒙古语语料

图2 经过BPE处理的蒙古语语料
目前很多自然语言处理任务中常用单词作为词汇单元。但对于蒙古语而言这种方法是有很大缺陷的,蒙古语可能组合的单词形式的数量非常多,所以翻译结果中出现未登录词的情况较多。很多的机器翻译模型系统用
1.2 Word2vec
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元,同时是自然语言用来表达含义的基本单元。机器学习使用向量来表示词,即词向量。要将符号形式的词语转化为数值形式,需要进行词嵌入。Word2vec就是词嵌入(word embedding)方法的一种。该方法由谷歌提出,不需要大量的人工标记样本就可以得到质量较为理想的词向量。
在Word2vec之前,自然语言处理通常把词语转换为离散的单独的符号,即one-hot表示。该方法为语料库中的每个词语单独地赋予一个只有一个中间值1其余值为0的向量。但是one-hot表示的词向量之间相对独立,无法体现相近词之间的关系,且词向量的维度取决于语料库中词语数量,如果语料库规模较大,包含词语数量的规模也十分可观,这样就会使得向量矩阵过于稀疏,并造成维度灾难。
Word2vec本质上是一个简化的神经网络,其输入是one-hot词向量,在隐藏层是线性单元,其输出层使用Softmax分类器,输出维度与输入维度一致。而Word2vec即隐藏层的输出,因为参与计算的one-hot向量的特点,所以Word2vec也即输入层和隐藏层之间的权重。本文使用Word2vec时选择Skip-gram词向量模型方法,图3为其基本内部结构示意图。
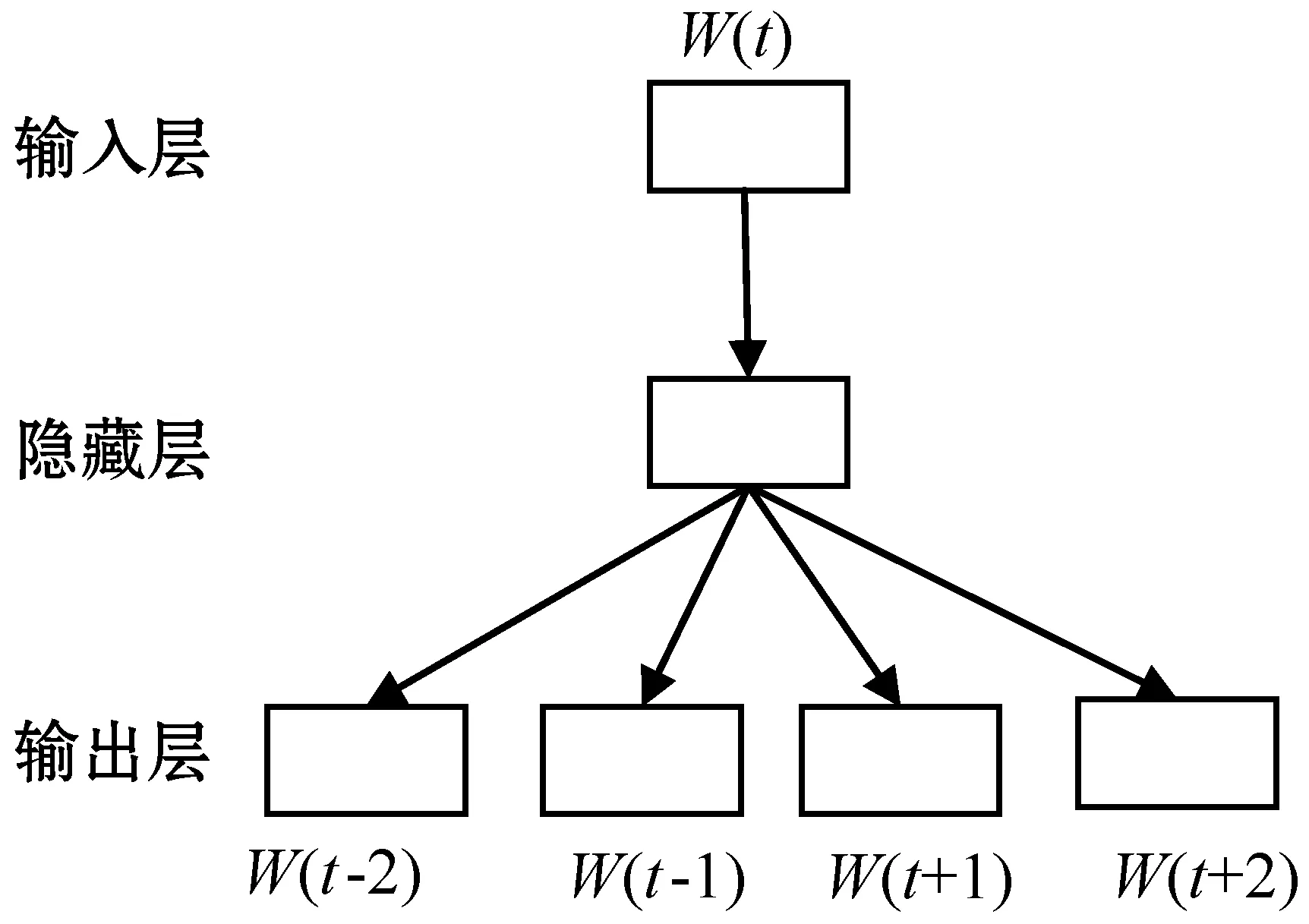
图3 Skip-gram模型结构
图3中,t为输入序列中第t个位置的词语,中心词W(t)作为神经网络的输入值,经过神经网络的隐藏层、输出层输出预测中心词前后出现若干词的相应的概率。本文采用基于层次的Softmax归一化方法进行Skip-gram词向量模型建模,Skip-gram模型需要计算出两个窗口大小的词汇也就是相对于中心词上下文2n个词汇的概率。
1.3 迁移学习策略
迁移学习一般先通过训练原任务获取一定的知识并将其记忆,然后将这些存储下来的知识迁移应用到与原任务相近的任务中。迁移学习策略允许借用大量已有的标记数据来训练网络并将其学到的知识迁移到标记数据较少的神经网络模型中,从而减少应用任务的训练数据量[16-17]。
传统自然语言处理的机器学习方法,首先针对特定的语言,通过相应的大量平行语料库进行模型的训练,然后将翻译模型应用到该特定的语言翻译任务中。而迁移学习与之相比,不再要求其基本条件,一是用来训练机器学习模型的数据和测试数据必须是同分布的并且数据间是相互独立的关系;二是用于训练的数据集必须保证一定的规模才可能得到效果理想的模型。
迁移学习属于机器学习方法中的一种。迁移学习中域(Domain)是学习的主体,由数据特征和分布组成。域又分为包含已有知识的源域和将要学习的目标域。迁移学习就是研究如何把在源域中学习到的知识迁移运用于目标域中。该方法按照迁移方法不同可以分为基于实例的迁移(Instance Based Transfer Learning,IBTL)、基于特征的迁移(Feature Based Transfer Learning,FBTL)、基于模型的迁移(Parameter Based Transfer Learning,PBTL)以及基于关系的迁移(Relation Based Transfer Learning,RBTL)[18]。本文在蒙汉机器翻译中研究基于模型的迁移,又称参数迁移方法,即在源域和目标域中存在可以共享的模型参数。具体方法是,首先对源域进行训练,得到效果较好的模型后,将该模型参数记录并迁移应用到目标域中,再根据目标域继续学习新的模型。
如图4所示,在一般的监督学习中,针对不同的任务,需要收集大量与任务相关的有标记的训练数据得到各自独立的模型。相比于这种策略,迁移学习可以实现在少量的标记数据条件下得到满意的模型。迁移学习将训练模型A获取的知识存储下来,应用于新的任务/域中,这里是对模型B的训练,以达到提高模型B性能的目的,图5为迁移学习模型示意图。
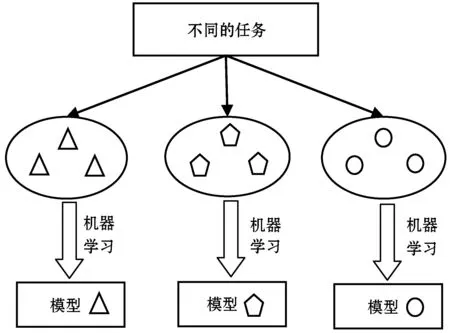
图4 传统机器学习模型示意图

图5 迁移学习模型示意图
迁移学习策略十分适用于已有标记数据缺乏的任务中,目前除了少量平行语料数据资源丰富的语言外(如英汉),很多语言对双语平行语料资源匮乏的问题普遍存在,没有足够的标记数据[19-20],迁移学习的引入将缓解这一困难。
1.4 长短时记忆网络
(1) 单向LSTM。自然语言处理是典型的序列到序列的机器学习任务,对于这种任务,使用最多的是循环神经网络(Recurrent Neural Networks,RNN)。RNN能够记忆输入网络的数据序列,通过这些信息RNN来进行一些预测。长短时记忆(Long Short-Term Memory,LSTM)是RNN的一种,它在基础的RNN上进行了改进。LSTM拥有更长时间的记忆能力,有效克服了机器翻译中存在的长距离依赖问题,显著提升机器翻译译文的流利度和可读性。
LSTM在普通RNN基础上加入判断信息是否有用的记忆单元,这个记忆单元被称为block。该block主要通过门(gate)机制进行信息的控制。一个block中放置三个门控单元以及一个记忆细胞,包括遗忘门控制单元、输入门控制单元和输出门控制单元。LSTM记忆单元结构如图6所示。
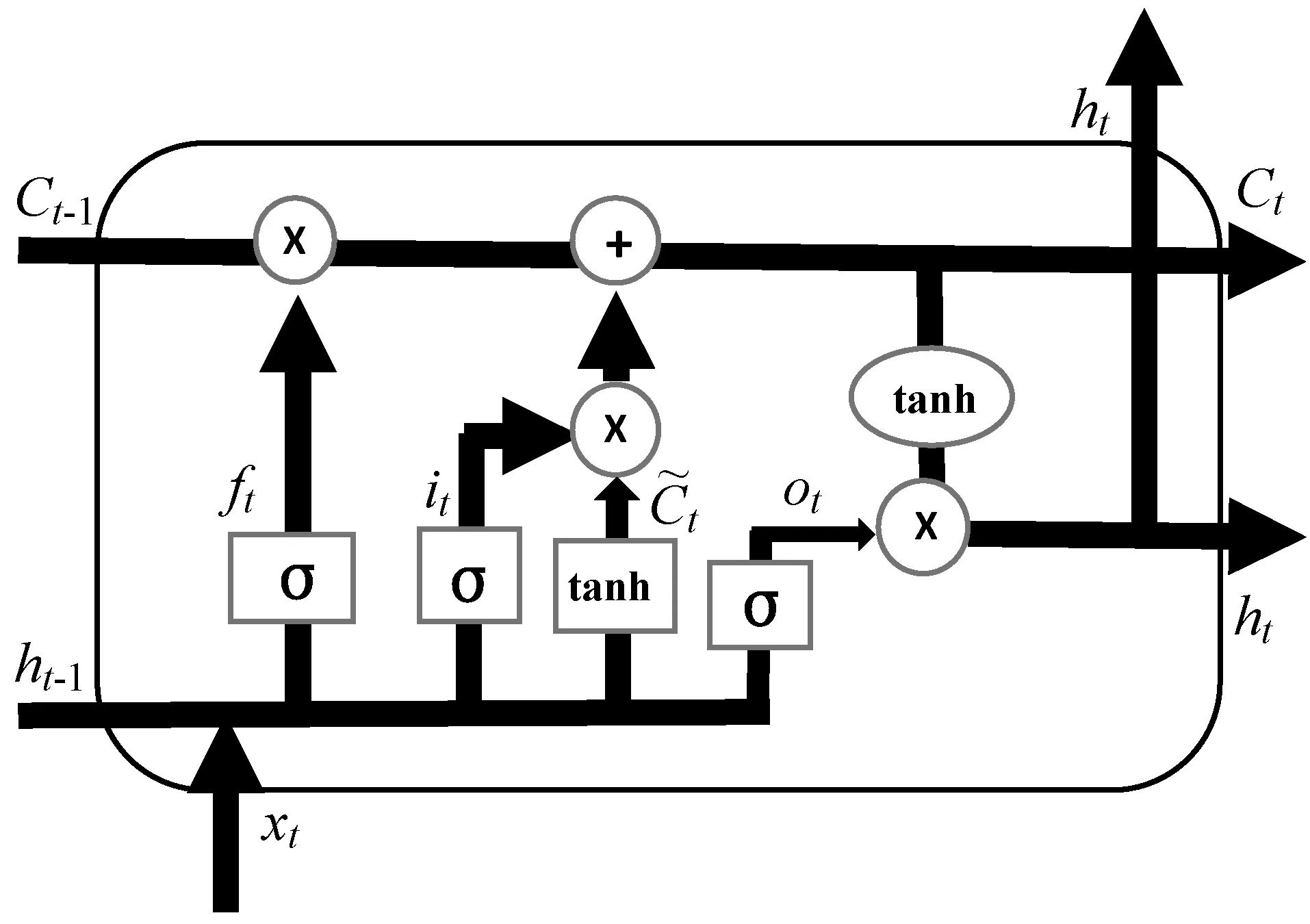
图6 LSTM结构图
图6中,ht表示t时刻block的输出,xt是当前输入的新信息。遗忘门中,ft由ht-1和xt得到,它用来计算Ct-1中信息的遗忘程度。上界为1表示完全记忆,下界为0表示完全遗忘,其计算公式为:
ft=σ(Wf·[ht-1,xt]+bf)
(1)

it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
当前的新信息Ct可以通过以上的状态计算,即遗忘一些信息并加入要记忆的新信息,计算公式如下:
(4)
输出门中,ot用以控制哪些信息需要作为输出,计算公式如下:
ot=(W0[ht-1,xt]+bo)
(5)
ht=ot×tanh(Ct)
(6)
式中:W为权重矩阵;b为偏置矩阵。
一般RNN在训练中可能会发生梯度消失的情况,后面的时间节点对以前时间节点的感知力下降,这样两个距离较远的节点之间的联系就被削弱。而LSTM可以记忆符合算法或规则的信息,其他信息则会被遗忘。当神经网络中的信息进入隐藏节点时,记忆单元通过三个门机制来控制信息的传播,只有符合门控的信息才会被记忆并且向后传递,否则遗忘门会将信息丢弃,得以保留的信息则会根据需求继续向后传播或者直接输出结果。
(2) 双向LSTM。单向LSTM对句子进行建模存在一个问题:无法编码从后到前的信息。而在机器翻译中,对某个词的翻译往往需要借助上下文相关信息,此时双向LSTM就可以更好地捕捉到双向语义依赖。
双向LSTM是由前向LSTM与后向LSTM组合而成。从1时刻到i时刻正向计算一遍,得到并保存每个时刻向前隐藏层的输出。还要沿着时刻i到时刻1反向计算一遍,得到并保存每个时刻向后隐藏层的输出。最后在每个时刻结合双向计算相应时刻输出的结果得到最终的输出。双向LSTM结构图如图7所示。

图7 双向LSTM结构图
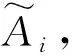
1.5 注意力机制
在普通的“编码器-解码器”架构中,解码和编码都依赖于内部一个固定长度向量(中间语义向量context)。注意力机制打破了这个限制,它通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性学习,并且在输出时将输出序列与之相关联。Bahdanau等[9]把注意力机制用到了神经网络机器翻译上,在生成目标序列中的每个词时,传统的做法是只用编码器最后一个时刻的输出,但加入注意力机制后,用到的context是源序列通过编码器隐藏层的加权和。通过这种方式,使源序列的每个词与目标序列的词建立了联系。图8为神经机器翻译注意力机制示意图。
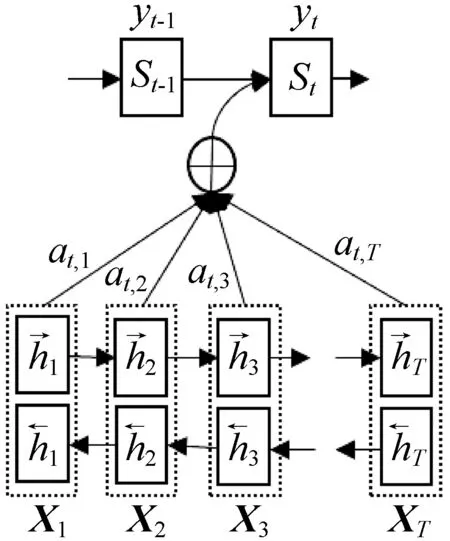
图8 注意力机制
图8中,设有长度为T的词向量序列X=(X1,X2,…,XT),源语言词的向量X2同时包含了上一个词X1和后一个词X3的语义向量信息。其中:a表示源语言对齐权重;S表示神经网络隐藏层状态向量;Y表示神经网络的输出序列;h为编码器输入序列。基于注意力机制的对齐权重计算公式如下:
(7)
式中:score(ht,hs)=htWhs,ht表示目标端隐藏节点状态信息,hs表示源语言端隐藏层状态信息,W为权重矩阵。将注意力机制加入到神经机器翻译模型中,在生成目标语言词时,计算得到当前词和源语言端所有词的对齐的权重,即生成当前词时只关注源语言端的部分词。注意力机制在一定程度上使得神经机器翻译模型在处理长句子上的能力得到提升。
1.6 TensorFlow深度学习框架
TensorFlow是由谷歌团队开源的机器学习框架。它拥有一个由工具、库和社区资源组成的全面、灵活的生态系统,使研究人员能够在机器学习中推动最先进的技术,开发人员可以轻松地构建和部署基于机器学习的应用程序。图9为TensorFlow深度学习框架示意图。

图9 TensorFlow模型训练框架示意图
如图9所示,Input为神经网络输入,通常是训练模型的数据;Inference表示神经网络经过前向推断预测模块;Evaluate表示神经网络模型评估模块;Loss是计算神经网络损失代价模块;Train表示神经网络的训练模块,主要通过计算各个节点的梯度以及通过梯度来更新模型中的参数。神经网络中的经验风险最小化以下的目标函数:
(8)
式(8)用于计算整个训练数据集的损失值,由神经网络模型中所有训练样本N的损失值Li的均值和正则化损失值R(W)两部分之和构成,λ为权重系数,i表示第i个训练样本。
1.7 TensorFlow中的参数迁移
本文进行的基于参数迁移的蒙汉机器翻译模型是搭建在TensorFlow环境下,使用TensorFlow内部的存储器对象来保存模型。利用导入预训练的模型来实现参数权重的迁移,将训练好的英汉神经网络参数权重迁移蒙汉翻译模型中,即蒙汉神经机器翻译时网络各节点参数不再是随机初始化,而是将训练好的英汉模型参数导入蒙汉模型中进行初始化。
TensorFlow深度学习框架中计算图和相关参数是分开存储的,因此导入预训练的模型需要分两步:首先需要构造神经网络模型图;然后加载权重参数。
当预训练模型训练完成后,Checkpoint文件(对应的扩展名为.ckpt)会存储神经网络中所有节点的权重、偏置和梯度等相关变量的值。通过调用TensorFlow中Saver对象的save()方法来保存全部网络参数。然后在新的神经网络中,通过restore()方法来加载预训练模型的参数,在此基础上继续进行训练。图10为TensorFlow参数迁移的过程示意图。
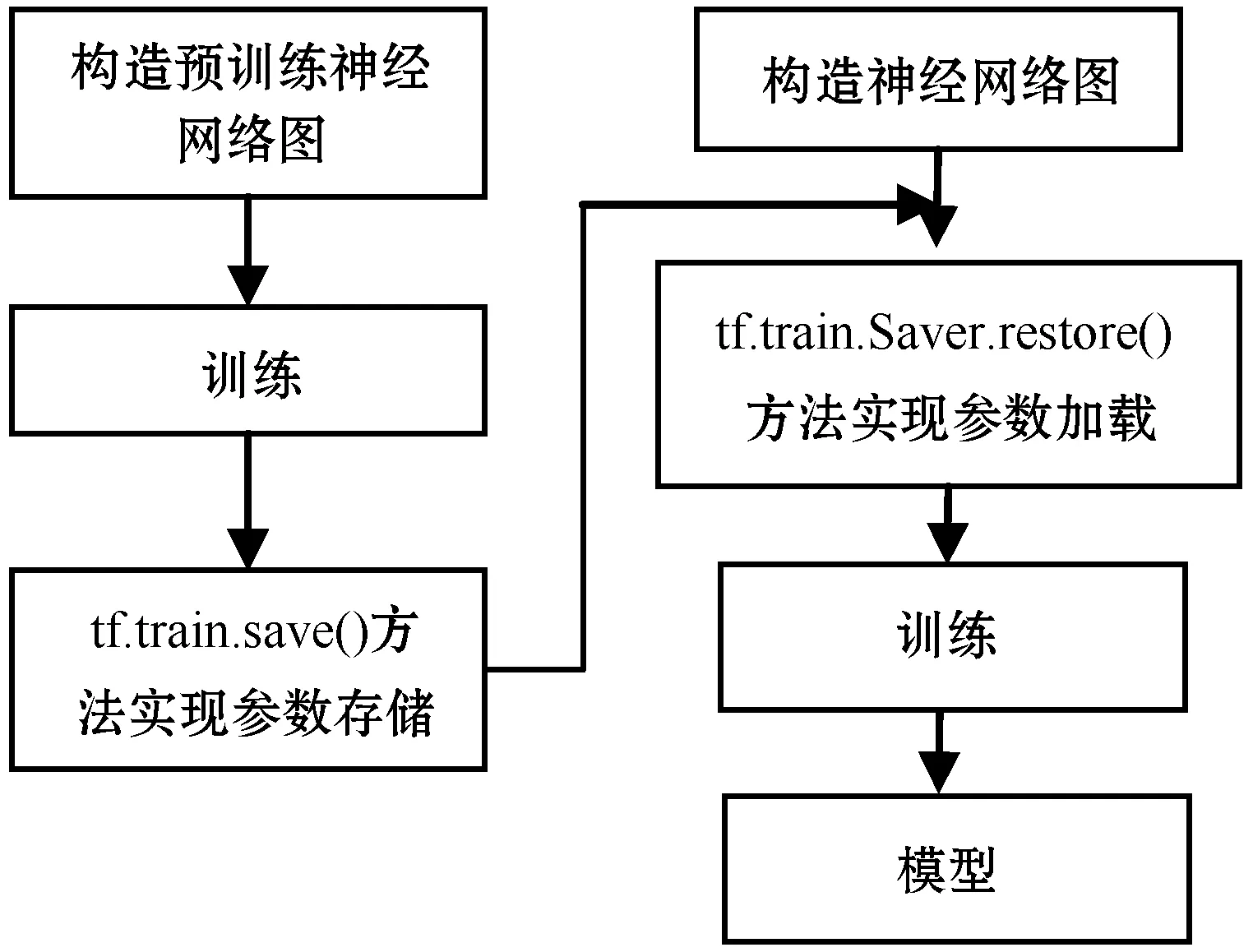
图10 TensorFlow参数迁移
2 实 验
2.1 实验数据
本文实验数据包含两大部分:一部分是用于英汉翻译模型的英汉平行语料库;另一部分是用于蒙汉翻译模型的蒙汉平行语料库。每部分的训练集、验证集和测试集划分及规模如表1所示。

表1 实验数据集划分
2.2 实验流程
本文具体实验流程如图11所示。
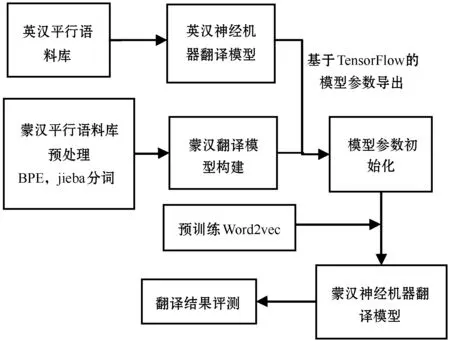
图11 实验流程
TensorFlow平台搭建神经网络模型,通过英汉平行语料库训练得到英汉翻译模型,将该神经网络模型的参数存储并导出。对蒙古语和汉语分别进行预处理得到处理后的平行语料库,同样在TensorFlow平台搭建用于蒙汉翻译的神经网络模型,把导出的参数导入该神经网络中进行参数初始化,然后再输入处理后的蒙汉平行语料库进行训练,最后得到翻译模型并进行翻译结果评测。
2.3 实验结果分析
本文在相同数量蒙汉平行语料库的前提下,进行了基于TensorFlow的传统蒙汉神经机器翻译(未进行参数迁移)模型训练、英汉神经机器翻译模型训练、基于Word2vec模型预训练得到词向量,并完成基于参数迁移的蒙汉神经机器翻译模型训练。本文对英汉进行了185 000步训练得到模型参数,对蒙汉进行了100 000步训练,记录了每10 000步BLEU值以进行实验对比。在Tensorflow框架中,Checkpoint文件存储了神经网络中所有结点的参数权重、偏置值、函数梯度等相关变量的值。本文在利用英汉平行语料训练神经机器翻译模型后会得到相关模型文件,其中包括了存储神经网络结构图的.meta文件和存储神经网络参数权重的.ckpt文件。图12为本文BLEU值随训练步数变化的情况。
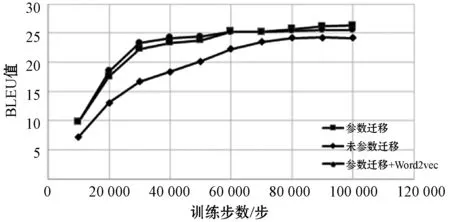
图12 BLEU值与训练步数关系
通过图12对比实验,可以分析出,使用了参数迁移的蒙汉神经机器翻译的最终结果(BLEU值)要优于传统的未使用迁移策略的机器翻译结果(提高了2.1BLEU值)。可以看到,在经过英汉参数迁移的基础上进行训练,BLEU值提高的速度在前期要快于完全依靠蒙汉语料进行神经网络初始化的翻译模型。以BLEU值达到20为目标点,引入参数迁移的翻译模型在训练不到30 000步就可以完成,但是未引入参数迁移的传统翻译模型需要训练约50 000步。
因为翻译模型训练之前参数初始化的影响,将同属于翻译任务的英汉翻译模型的参数引入蒙汉翻译模型的初始化,使得模型在训练之前已有了一定的参数基础,所以再进行训练时,其学习速率会有所提升。并且使用Word2vec预训练的词向量后,最终的结果也要优于传统的翻译效果,其BLEU值相比提高了1.4。
3 结 语
目前神经机器翻译在大语种之间互译的相关研究趋于成熟,例如英德、英汉等语种之间的互译效果已经达到了很好的效果。但是对于蒙古语这种小语种来说,现有的平行语料库规模有限,短时期内获取语料的难度也相对较大,这就限制了蒙汉神经机器的发展。本文将迁移学习引入到蒙汉神经机器翻译中,利用大语种拥有大规模语料库的优势,将其模型参数迁移。并且为了提高翻译效果,使用Word2vec预训练了词向量,将词汇表示成固定维度的实数向量,相近语义的词在词向量空间上距离相近,这样在一定程度上提升了双语词向量的表达能力。实验结果表明,引入迁移学习对蒙汉翻译效果有一定提升(BLEU值),说明对蒙汉机器翻译中存在的平行语料库不足的问题有一定的缓解。
同时,本文在源域中选择的是英语到汉语的翻译任务,而目标域是蒙古语到汉语,两者虽然都属于机器翻译任务,但是英语和蒙古语在语法、语言结构上仍然存在较大差别。迁移学习在机器翻译中应用时应存在一定语言相关性,因此在源域选择与蒙古语语法相近的语言例如日语,这样迁移到目标域可能会达到更好的翻译效果,但是目前获得较大规模的日汉平行语料库还是相对困难的。平行语料库不足依然是蒙汉神经机器发展的主要阻碍之一,而迁移学习的特性能在一定程度上缓解这个问题。因此,接下来的工作一是尽可能获取蒙汉平行语料,二是继续进行迁移学习方面的研究,获取与蒙古语相近的其他拥有较大规模的语言的语料库,并继续尝试其他模式的迁移方法在蒙汉神经机器上的研究。
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
新湘评论·上半月(2020年11期)2020-12-07
记者观察(2019年14期)2019-11-08
电脑知识与技术(2019年23期)2019-11-03
世界家苑(2018年11期)2018-11-20
新一代(2017年15期)2018-01-12
卷宗(2016年12期)2017-04-19
读写算·教研版(2016年6期)2016-03-28
外语教学理论与实践(2014年2期)2014-06-21
教学与管理(理论版)(2009年9期)2009-11-04
