
基于随机森林算法的陈垓灌区降水量预测模型
2020-09-25 06:20沙世琨
水利技术监督 2020年5期
沙世琨
(济宁市水利事业发展中心,山东 济宁 272000)
1 研究背景
陈垓灌区地处山东省济宁市梁山县,随着区域设施配套、改造的不断升级,目前已经被水利部命名为全国先进灌区,并且成为集自流、提水、补源等功能于一身的大型水利灌区[1]。
为确保陈垓引黄灌区节水改造工程顺利完成,工程继续进行节水改造。工程改造过程中,水文气象资料不仅是当地干旱、洪涝预报和工程实施过程中的一个重要参考依据,同时也是影响流域径流计算的主要因素之一,但由于降雨量及其影响因素的复杂性,目前对所采用的预测模型的研究和应用均没有趋近完善,存在稳健性差、计算量大、预测精度不高和过度拟合情况等不足,极大地降低了模型的实用性[2- 3]。
近年来,人工智能机器学习领域的随机森林(Random Forest,RF)算法在学习复杂非线性关系、提高模型泛化性等方面取得了丰硕的研究成果[4]。因此,文章针对目前降雨量预测模型在计算量、精度、泛化性等方面的缺点[5],充分结合随机森林算法的特有优势,建立了基于随机森林算法的陈垓灌区降水量预测模型,提高了模型的拟合预测性能。
2 随机森林原理
2.1 模型简介
随机森林作为一种集成学习已在很多领域有了一定的应用,以决策树作为核心单元,主要思想是集成学习[6]。通常选取Bootstrap重抽样方式进行训练集样本抽样处理,依照规则,对样本集进行一分为二分割,以二分递归方式来实现决策树模型搭建。模型中的各个决策树相互独立,互不干涉,通常不对决策树进行修剪,任其生长,最后把生长好的决策树进行组合得到分类器,即随机森林,对于使用该模型的数据分类结果采用投票方式来决定新样本的类别,以实现对数据的预测。
决策树属于典型的单分类器,通过递归的方式从一组数量较大,且杂乱无章的样本中推求出决策树对于分类数据的分类规则,利用规则来分析数据。文章采用分类回归树(Classification and Regression Tree,CART)来实现决策树的节点分裂[9]。CART算法依据Gini指标来衡量数据划分标准,以Gini指标最小的特征值作为节点的分裂属性,可解释生成的规则。
(1)样本Gini系数的计算公式
(1)
式中,T—样本;k—样本类别个数;p(i|t)—类别i在t节点处的概率。
(2)计算划分的指数
(2)
式中,m—子节点个数;ni—子节点i处的样本数;n—母节点的样本数。
在属性分裂过程中,根据公式(1)和公式(2)进行CART算法中参数的计算,即Gini系数,并根据计算结果选择优先属性作为节点分裂的属性,即Gini系数最小的属性,通过递归循环的方式,不断更新,最终产生完整的决策树。
随机森林模型属于集成学习的一种,由若干个小型分类器组合而成,并对这些学习器的计算结果进行优化,选取出最优结果。因此,随机森林集成学习算法的模型性能必然优于任何一个弱学习器的预测性能,同时进一步提高了预测模型性能的稳定性。
2.2 样本集选择
模型原始样本集总共包括N个样本,M个特征,这些实测数据资料中包含了复杂的作用关系,可能是线性关系,也可能是非线性关系,但一般非线性关系在数据科学中最为常见[10]。随机森林模型从中抽取N个样本集作为模型的训练集(随机有放回方式)。由于在抽样过程中采用了随机有放回的方式,所有抽取的样本在一定程度上均含有重复样本,但由于没有全部抽取,抽取的样本又不包含全部样本,所以避免了将全部样本输入模型而造成过拟合现象。抽样过程中未被采样到的数据通常被定义为袋外数据(Out of Bag, OOB),由于其在训练模型中未出现的特殊性,因此通常被用来检验模型的训练性能,即测试样本集。
随机森林模型抽样次数n(既决策树个数)和特征分裂节点数m决定着模型的预测能力。决策树个数可以通过其与OOB误差的关系实验来确定;特征分裂节点数m按照推荐值选取为M/3。
2.3 模型训练和预测
分别采取独立同分布的训练样本对每棵决策树进行训练,基于所有决策树预测结果投票决定RF最终的预测结果[11]。RF无须专门设置交叉验证,通常采用袋外数据样本输入到训练好的最优参数模型中进行模型测试[12]。
3 基于RF的降雨量预测模型
传统的降雨量预测模型在预测精度、泛化性和实用性等方面存在缺陷,因此,建立基于RF的降雨量预测模型,具体建模步骤如下。
3.1 数据预处理
采用统计学方法对实测降雨量数据进行粗差处理,为预测模型的建立提供可靠的数据基础。将降雨量数据样本作为模型数据集,采用标准化公式对所有数据样本进行标准化处理[13]。
(3)
式中,μ—相应变量数据的均值;σ—相应变量数据的标准差。
3.2 模型训练
将经过预处理的标准化训练集样本作为模型输入,通过梯度下降算法进行误差反向传播驱使模型损失函数收敛,获得最优参数模型。
3.3 模型测试
模型训练过程中样本的重采样方式是防止过拟合现象的一项重要措施,抽样剩余的袋外数据未在模型训练数据集中出现,因此这一部分数据可被用来进行模型测试,同时作为模型参数优化的一项重要手段。
将重采样剩余的训练样本数据作为模型测试样本进行模型测试,同时根据测试结果的相关评价指标(如标准差、平均绝对百分比误差等)作为决策树个数这一重要参数优化的损失函数,当这些损失函数达到最小值时,其最小值所对应的模型决策树个数即为其最优取值。
3.4 模型预测
将测试集自变量因子数据输入训练好的最优参数预测模型中,获得相应的降雨量预测结果。
3.5 模型评价
为了准确衡量模型预测性能,结合统计多元回归理论,采用均方根误差RMSE和平均绝对百分比误差MAPE作为模型预测效果评价指标[14]。
(4)
(5)
如果模型预测评价指标较其他模型最优,那么这个模型就为最优模型。
4 工程实例应用
4.1 项目简介
陈垓灌区区域气候四季分明,春季干旱且风沙较大,夏季降雨集中且容易发生洪涝灾害。为了能提前预测干旱年和洪涝年,文章以灌区内梁山气象站1954—2007年实测降雨量数据为依据,建立基于随机森林算法的陈垓灌区降水量预测模型,实现降雨量的精准预测。梁山县气象站历年降雨量过程线如图1所示。

图1 梁山县气象站历年降雨量过程线
4.2 预测模型训练与预测
(1)模型参数设置
决策树个数作为随机森林模型最重要的参数,其选取结果对于模型的拟合预测能力起着关键性作用。为了获取最优的模型参数,初步拟定决策树个数为1~500,分别计算每棵决策树下随机森林模型的袋外数据误差,决策树个数与袋外数据误差关系曲线如图2所示。基于最优参数下模型预测误差最小的准则,确定本数据集下决策树个数为200。

图2 决策树个数与袋外数据误差的关系图
(2)模型预测分析
以预处理的标准化降雨量数据为基础,分别建立基于最小二乘回归(Least Square Regression,LSR)、基于RF的降雨量预测模型,并按照前面所采取的最优模型参数进行模型训练。图3为降雨量实测值和各模型降雨量拟合值过程线。

图3 各模型降雨量拟合值和实测值过程线
通过对图3分析可知,基于RF的降雨量预测模型曲线吻合度最高,目标损失函数最小,模型训练结果较优,同时其预测性能也明显优于基于LSR的降雨量预测模型因此,RF模型能更好地挖掘数据信息的内部特征以反映降雨量的真实性态,具有良好的实际参考价值。
(3)模型评价
为了验证基于RF的降雨量预测模型的性能,选取常用的预测值与实测值残差、均方根误差和平均绝对百分比误差等指标评价预测模型精确性,并对基于LSR、RF的降雨量预测模型评价指标计算结果进行对比分析。各模型的预测值与实测值过程线如图4所示,各模型的均方根误差和平均绝对百分比误差计算结果见表1。
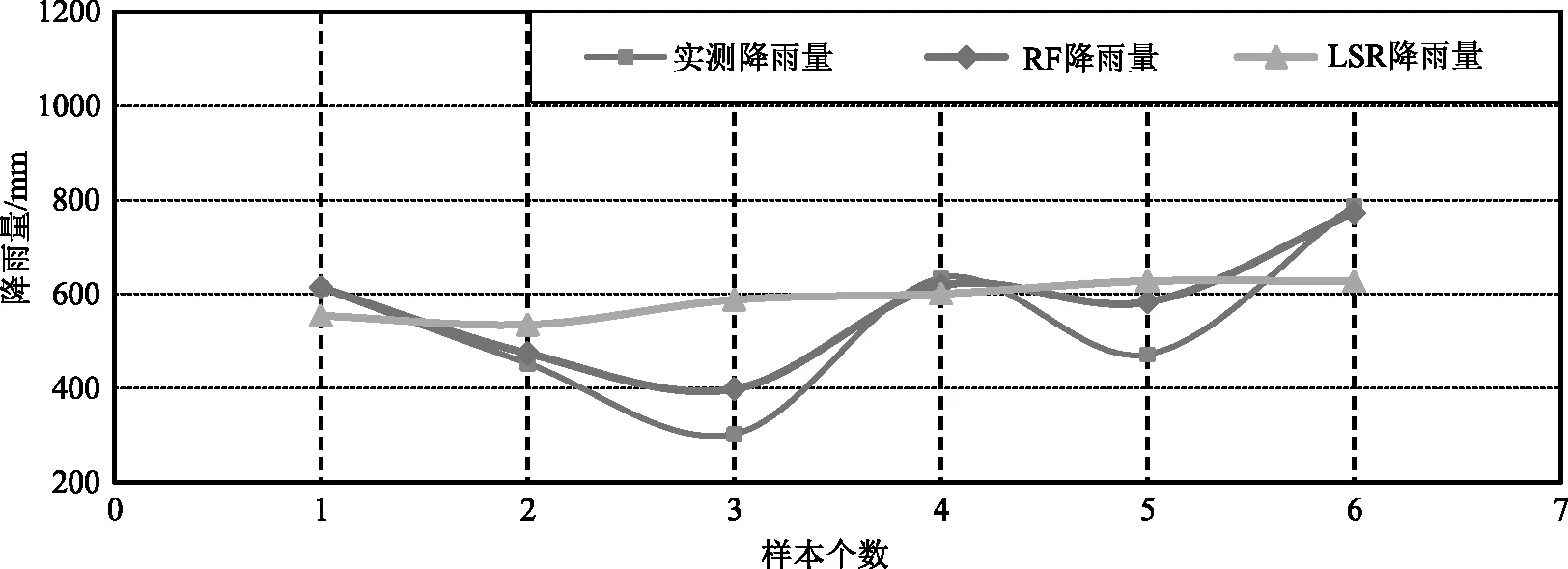
图4 各模型降雨量预测值和实测值过程线

表1 预测模型精确性指标
分析图5和表2可知,常用的LSR模型在一定程度上能够实现区域降雨量的预测,但基于RF的降雨量预测模型预测效果最好,具有较高的精准度。相较于基于LSR的降雨量预测模型各项指标,基于RF的降雨量预测模型残差最小,RMSE低于50,MAPE低于10,均处于较低的区间。因此,基于RF的降雨量预测模型精准度性能较佳,预测结果更接近真实数据。
5 结论
(1)机器学习技术在降雨量预测模型建立中的成功应用,能够有效提高模型预测性能,更加准确地预测降雨量的发展趋势。
(2)基于RF的降雨量预测模型不仅提高了预测运算效率,同时能有效地避免过拟合现象,具有较高的预测精度,并且兼有较强的外延性和泛化性,这些良好的性能使得降雨量预测具有较高的灵敏度。
(3)基于RF的降雨量预测模型必须基于大量的历史实测数据,不适用于小样本数据。
猜你喜欢
治淮(2022年4期)2022-01-01
小学生学习指导(低年级)(2021年9期)2021-10-14
数学小灵通·3-4年级(2021年6期)2021-07-16
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
决策与信息·下旬刊(2013年1期)2013-03-11
