
基于深度编码器的复杂网络社区发现算法*
2020-10-10 02:39张士进田纪彪吴志强戴维凯
计算机工程与科学 2020年9期
张士进,张 胜,田纪彪,吴志强,戴维凯
(南昌航空大学信息工程学院,江西 南昌 330063)
1 引言
复杂网络是复杂系统的抽象,网络中的节点是复杂系统中的个体,节点之间的边则是系统中个体之间按照某种规则自然形成或人为构造的一种关系。随着对复杂网络的不断深入研究,学者们发现复杂网络具有多种特性,如无标度特性、小世界特性、分形特性和社区结构特性等。其中,社区结构的研究有利于理解复杂网络构成的特点,具有重要的应用价值,如社交网络的精准推荐、电力网络的最佳规划和蛋白质互作网络的功能预测等。复杂网络不是将具有相同属性的节点随机地连接在一起,而是将不同属性节点组合在一起。具有社区结构的复杂网络是由若干社区组成,而社区是具有相同特性的节点所组成的集合,社区内部的节点之间的连接比较紧密,而不同社区之间的节点连接却相对稀疏[1]。社区发现是找出一个给定的复杂网络的社区结构的过程,它是复杂网络分析中的一种基本手段。
复杂网络的社区发现起源于图论与模式识别相关理论,而Newman和Girvan的研究成果使得社区发现成为一个研究热点。社区发现能够揭示复杂网络中节点之间的交互关系,大量的研究人员尝试从不同角度探究社区结构,其算法可以分为基于图分割的算法[2]、基于聚类的算法[3]、基于网络动力学特性的算法[4]和基于目标函数的优化算法[5]等。近几年将深度学习用于解决大规模复杂网络的社区发现成为热点,虽然研究人员提出了很多基于深度学习的模型,但存在模型复杂性高和参数过多导致普适性差的问题。Wang等[6]提出DA-ELM(Deep Auto-encoded Extreme Learning Machine)算法,使用多层自动编码器和极限学习机对相似矩阵表征学习,提高了精确度和稳定性,但训练耗时过高。Jia等[7]提出CommunityGAN(Community detection with Generative Adversarial Nets)算法,利用对抗网络优化节点隶属社区强度,使生成器与判别器之间相互竞争,二者交替迭代提高了精确度,但参数多造成普适性差。Li等[8]提出CD-ERL(Community Detection algorithm based on Edge Representation Learning)算法,通过对网络的边进行表征学习,利用边聚类算法转化成节点的重叠社区划分,提高了精确度,但稳定性不高。尚敬文等[9]提出CoDDA(Community Detection algoritym based on Deep sparse Autoencoder)算法,利用多层稀疏自动编码器对s-jump相似矩阵降维并进行表征学习,用K-means聚类,提高了精确度,但算法的参数不易选择,普适性较差。Zhang等[10]利用多层的谱聚类对网络的社区进行划分,该算法的精度比单层的要高,但层数是一个不稳定参数。
为解决上述算法的不足,本文提出一种新的算法DA-EF(Deep Auto-encoder and EForest)和用于度量节点之间相似度的影响力扩散指标。影响力扩散是对节点之间不存在连边的情况,赋予节点网络的局部信息,使其更全面地表征网络。本文算法是将多层自动编码器级联一层森林编码器,用于复杂网络的社区发现,其贡献有2点:(1)提出了用于度量节点之间相似度的影响力扩散指标,可以更加完整地表示网络;(2)提出了DA-EF算法,级联的森林编码器在保持神经网络模型的深度的同时,大幅降低了模型的时间复杂度。实验表明,该算法的表征学习能力优异,社区结构划分更加准确。
2 相关工作
2.1 影响力扩散
若一个网络是由n个节点和m条边组成,那么可以简述为:网络G=(V,E),节点集合V={v1,v2,…,vn},边集合E={e1,e2,…,em}。一般用来刻画网络中节点间信息的是邻接矩阵A=[aij]n×n,其中元素aij是表示节点之间有无连边,如果节点vi与节点vj有连边,则aij=1;否则aij=0。邻接矩阵只能表示网络中具有连边的节点信息,然而网络中没有连边的节点之间同样具有一定的相似度,因此,将节点局部信息引入到邻接矩阵,以更加全面地刻画网络,本文提出影响力扩散指标,用于度量节点之间的相似度。影响力扩散是将网络中节点的重要程度作为节点的影响力,将其影响力扩散到其邻居节点,由邻居节点再去影响其没有辐射到的邻居节点,直到影响力衰减到某个阈值(假定没有影响作用)为止,从而计算节点之间的相似度。
(1)节点的初始影响力。
网络中节点重要程度可以用节点度表示,为了避免网络中某些节点度过大而造成影响力失衡,采用对数的形式计算任意节点的初始影响力:
Ei=lg(1+di)
(1)
其中,di表示节点vi的度,节点影响力Ei>0。
(2)影响力扩散规则。
假设节点vi的初始影响力为Ei,其邻居节点集为Φi。
①若|Φi|=1,即节点vi只有1个邻居节点,那么此节点称为跟随节点(无影响力),其邻居节点获得全部影响力Ei,但不继续扩散。
②若|Φi|>1,节点vi至少存在2个邻居节点,而且认为该节点能够直接对邻居节点造成影响,但影响力大小由2个部分组成,一个是所有邻居节点都相同的基础影响力,保证具有连边的节点存在影响;另一个是增量影响力,依据节点的共同邻居节点数增加影响力的值,使联系紧密的节点之间影响更大,保证节点之间影响力的差异化。基础影响力的定义如式(2)所示:
(2)
从式(2)可知,邻居节点的基础影响力之和为初始影响力的一半,那么节点vi的另外一半影响力值作为增量影响力。增量影响力的引入,不会使节点受到的影响力的值大于1。增量影响力的定义如式(3)所示:
(3)
其中Φj是节点vj的邻居节点集,且vj∈Φi,则节点vi传递到邻居节点的影响力为:
(4)
(3)影响力扩散终止条件。
随着影响力不断扩散,其值将越来越小,那么在网络中起到的作用也是越来越小。设定一个影响力阈值作为影响力元,当节点接收的影响力小于阈值时,终止传递。
(5)
其中,β是影响因子,取值为(0,1)。
2.2 自动编码器
近几年深度学习成功应用于许多领域,而自动编码器(Auto-encoder)[11]是人工神经网络的一种,常用于表征学习和特征降维,属于非监督学习。自动编码器是一个3层的神经网络,由编码和解码2部分组成,其结构如图1所示。

Figure 1 Structure of auto-encoder图1 自动编码器的结构
从第1层到第2层是表征学习和特征降维的编码过程,将输入的n维数据映射到h维(n>h);第2层到第3层是重构原始数据的解码过程。在自动编码器中,具体的训练过程如下所示:
由Salton得到的相似度矩阵As作为自动编码器的输入,As=[bij]n×n=(x1,x2,…,xn)T,其中xi=(bi1,bi2,…,bin),是相似度矩阵的第i个节点对应的向量,将向量xi作为自动编码器的第i个输入向量。将xi输入到一个具有h个神经元的编码层,通过式(6)得到编码 。
yi=f(Wxi+b)
(6)
其中,f是编码器的sigmoid激活函数,W∈Rh×n是权重矩阵,b∈Rh×1是编码层的偏置向量。

(7)


(8)
2.3 森林编码器
研究表明[15],森林编码器EForest对原始特征的表征学习能力比自动编码器强,重构误差更小,因此本文选择森林编码器对低维相似度矩阵做更深一层的学习。森林编码器是由编码和解码2部分组成,其具体操作是基于决策树产生的。
前向编码操作是给定一个有T棵树的随机森林,而编码过程就是森林形成过程,将输入数据送到每棵树的根节点,并计算每棵树,得到其所属的叶节点,最后返回一个T维向量,这个T维向量的每一项是每棵树中求到的叶节点在树中的编号。反向解码操作是重构的过程,将前向编码得到的T维向量,以及从树中得到T个决策规则,再根据这些规则得到最大完备规则MCR(Maximal-Com-patible Rule),并利用MCR重构原始数据。DA-EF没有利用森林编码器中的解码操作,限于篇幅对此不作详细介绍。
算法1EForest算法前向编码
输入:随机森林T棵树,数据Aa。
输出:Xenc。
1.Xenc=zero[T,1];//初始化
2.foreachiinT
Xenc[i] =Forest.Tree[i].encode(Aa)/*第i棵树的叶子编号*/
3.end
4.returnXenc
3 DA-EF算法
深度神经网络中自动编码器(Auto-encoder)能够将数据从高维映射到低维,从而达到降低维度的效果,同时也能对原始数据进行表征学习。而社区划分对数据特征的依赖度很高,因此,本文在自动编码器之后级联一层森林编码器,主要目的是再次提取高阶特征。通过建立一个由多层自动编码器和森林编码器组成的二级级联模型,本文提出DA-EF算法,如图2所示,该算法对相似度矩阵As降维和表征学习,能够更好地对网络进行社区划分。DA-EF算法结构由多层自动编码器和森林编码器组成,图2中自动编码器的层数是2,而算法中自动编码器的层数是根据复杂网络的规模确定的,相关实验在第5.2节探讨。自动编码器的输入是根据影响力扩散相似度指标得到的节点间的相似度矩阵As,经过多层自动编码器处理之后,得到一个低维高阶特征矩阵Aa,而Aa作为森林编码器的输入,提取其高阶特征,最后得到输出矩阵At。

Figure 2 Structure of DA-EF图2 DA-EF算法结构
从复杂网络到社区划分主要分4步:表征网络邻接矩阵A;计算相似度矩阵As;降低维度和表征学习;得到低维高阶特征矩阵At;利用聚类算法划分社区集合C,其社区发现流程如图3所示。本文提出的用于计算节点间相似度的影响力扩散指标,利用网络中节点的邻居节点的局部信息,增强了节点相似度的稳定性和准确性;提出DA-EF算法对相似度矩阵进行特征降维和表征学习,得到一个低维高阶特征矩阵,有利于提高大规模网络的社区发现精确度;K-means具有精确度高和时间复杂度低的优点,本文选择它对网络的低维高阶特征矩阵进行聚类,得到社区划分结果。
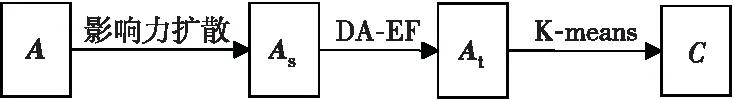
Figure 3 Community detection process图3 社区发现流程
算法2DA-EF算法
输入:网络图G=(V,E)的邻接矩阵A,社区个数k,影响因子β,深度自动编码器的层数L,森林编码器中T棵树,每层节点数h={h1,h2,…,hL}。
输出:社区划分结果C={C1,C2,…,Ck}。
1.ForeachiinV
2.ForeachjinV
3. 根据式(4)计算节点的相似度;
4. 得到相似度矩阵As;
5.X1=As;
6.ForeachminL
7. 建立一个自动编码器;
8. 输入特征矩阵Xm;
9. 通过优化式(8)训练自动编码器;
10. 得到隐藏层的表示Yj;
11.Xj+1=Yj;
12. 将XL矩阵作为森林编码器的输入;
13. 由算法1得出At;
14. 对低维高阶特征矩阵At运行K-means,聚类得到社区划分结果C={C1,C2,…,Ck}。
4 实验结果与分析
为了验证本文算法DA-EF的有效性,将其与其它算法CoDDA[9]、K-means[13]和DA-EML[6]进行实验对比,实验的数据集由人工合成数据集和真实数据集组成,而评价标准是模块度Q(Modurity)[14]和标准互信息NMI(Normalized Mutual Information)[15]。本文的实验环境配置:Windows 10操作系统,Intel core i7-7800X CPU,128 GB;编程语言是Python 3.6,编译工具为Pycharm community 2018。
4.1 评价指标
模块度自被Newman等[16]提出之后,就一直作为社区划分评价标准之一,能够在不知网络真实社区划分的情况下对划分结果做出客观的评价。模块度的定义如下所示:
(9)
其中,用vi和vj表示网络中不同的节点;n为网络节点总数;m为网络总边数;aij为图的邻接矩阵元素;ki和kj分别为节点vi和vj的度;δi和δj分别为节点vi和vj所在的社区编号,若δi=δj,则c(δi,δj)=1,否则c(δi,δj)=0,Q值越大说明社区划分得越准确。
标准互信息NMI是在已知网络真实社区划分的情况下,对实验划分结果的精确度进行评价,其函数表达如下所示:
NMI(A,B)=
(10)
其中,CA(CB)是A(B)划分的社区数目;Ci和Cj分别表示第i个和第j个社区的节点数目;Ci ·是混淆矩阵C的第i行元素之和;C·j是第j列元素之和;n是网络节点数目。当A=B时,NMI(A,B)=1,A和B划分结果相同;当NMI=0时,A和B的划分结果完全相反,其值越大越接近真实社区划分。
4.2 人工合成数据集
本文使用的人工合成网络是LFR benchmark[17],由于该网络的节点度和社区大小都是可调节的,而且符合幂律分布,因此生成的网络更加接近真实网络。网络的参数和算法参数如表1所示,网络节点数分别是1 000, 3 000和5 000,其中k是网络节点平均度,maxk是最大节点度,mink是社区最小节点数,maxc是社区最大节点数,u是网络混合参数(Mixing parameter),其值越大网络的社区结构越模糊,通过调节该参数值对网络社区结构进行改变。
DA-EF算法的自动编码器的层数以及每层节点数设置,如表2所示,譬如LFR编号为1的网络,其算法结构为1000-800-650-600,其中1 000是输入节点数,800是第1层自动编码器隐藏层的节点数,650是第2层自动编码器隐藏层节点数,600是森林编码器中树的棵数,其它网络算法结构依此类推。

Table 1 Main information of the LFR networks表1 LFR网络主要信息
DA-EF与K-means、DA-EML和CoDDA 3种算法进行对比,每个网络都用模块度Q、标准互信息NMI和运行时间Time作为评价标准。3个不同规模LFR网络在3种评价标准下的实验图如图4所示,实验结果是重复实验20次取得的平均值。DA-EF在3个网络下的Q和NMI都是高于K-means和CoDDA算法的,而且随着网络的节点数增加,精确度下降的趋势变慢,而且DA-EF、CoDDA和DA-EML的精确度明显比K-means要高,说明自动编码器对挖掘网络深层信息是有效的;在运行时间上,DA-EF明显比其它算法要低很多,而且优于同类算法CoDDA和DA-EML,体现出了本文算法的高效性。在人工合成数据的实验中说明,本文提出的算法DA-EF精确度明显提升,而且与同类算法相比运行时间更少,表明了算法的有效性和高效性。

Figure 4 Comparison of algorithm results on LFR networks图4 LFR网络上算法对比实验

表2 LFR网络的DA-EF结构
4.3 真实数据集
本文的真实数据选取了Football[18]、Polbooks[19]、Jazz[20]和Facebook[21]。Football是美国NCAA足球联赛的对阵关系网络;Polbooks是书店出售政治书籍联系网络;Jazz是爵士音乐家合作关系网络;Facebook是用户的朋友圈的关系网络。真实网络的信息如表3所示,包括网络的节点数、边和社区数目,模型结构同LFR。

Table 3 DA-EF structure of real networks表3 真实网络的DA-EF结构
本文算法DA-EF在真实网络上的对比实验结果如表4所示,对比算法依然是K-means、DA-EML和CoDDA;评价指标是模块度Q和运行时间Time。在Football网络上,Q值最高的是DA-EML,其次是DA-EF,运行时间最少的是CoDDA;在Polbooks、Jazz和Facebook网络中,DA-EF的Q值最大,运行时间也同样相对较少,随着网络规模的增大,DA-EML和DA-EF运行时间增加速率明显小于K-means与CoDDA的。实验表明,DA-EF算法在真实数据集上精确度高,而且更加有利于大规模网络的划分。
5 算法DA-EF有效性探讨
在人工合成数据集和真实数据集上的实验表明,与其它算法相比,本文提出的DA-EF算法能提升社区划分精确度。DA-EF算法是多层自动编码器和森林编码器组成的二级级联结构,为计算网络中节点间的相似度,本文提出了影响力扩散指标,下面将探讨森林编码器、自动编码器的层数和影响力扩散指标对算法的影响。选择LFR编号为2的数据网络进行实验。
5.1 森林编码器的影响
DA-EF算法在多层自动编码器的基础上级联了一层森林编码器,研究表明[12]森林编码器的重构误差相比于循环神经网络和卷积神经网络要低,能够更好地提取高阶特征。因此,本文将森林编码器应用到社区发现,并构造一个二级级联模型,其不仅能够实现降维和表征学习,还能避免森林编码器对降维失真的问题。实验结果如图5所示,AE算法表示只有多层自动编码器,没有级联森林编码器,DA-EF是级联了森林编码器的算法。将AE与DA-EF进行对比,在评价标准NMI下,可以得出,在级联森林编码器之后,算法的精确度明显得到了提高,森林编码器的引入有积极效果。

Table 4 Comparison of algorithms results on real networks表4 真实网络上算法结果对比

Figure 5 Impact of EForest encoder图5 森林编码器影响
5.2 自动编码器的层数影响
实验数据为LFR编号为2,混合参数u为0.3的网络,自动编码器的结构为3000-2000-1600-1000-500。实验结果如图6所示,横轴Deep level表示DA-EF中自动编码器的层数。

Figure 6 Layer number experiment of auto-encoder图6 自动编码器的层数实验
从图6中可以看出,当层数增加到2时,算法精确度达到最高;层数增加到3或4时,精确度都变得更低,因此,层数并不是越多越好,要根据网络的规模选择。当网络规模在1 000以下时,选择1层AE就能够得到较好的结果,如真实数据集Football、Polbooks和Jazz上的结果;当网络规模为1 000~5 000时,选择2层AE,如真实数据集Facebook和LFR网络;当网络规模更大时,选择的AE层数也就越多。AE层数对DA-EF算法具有一定的影响,合适的层数能够提升社区划分的精确度。
5.3 相似度指标的影响
使用DA-EF算法进行实验,实验数据与5.2节中一样,相似度指标有s-jump、RA(Resource Allocation)[22]、Jaccard[23]、CN(Common Neighbors)[24]和影响力扩散,其评价指标为NMI和Q,实验结果如图7所示。每种指标都是同一种算法DA-EF,从图7中可知,不同的相似度指标下,算法得到的划分结果也不同,其中,RA指标是最差的,而CN和影响力扩散的精确度最好,影响力扩散对社区结构不明显的网络,也能得到较好的划分结果。因此,本文提出的影响力扩散选择指标,更有利于处理网络结构不明显的网络。
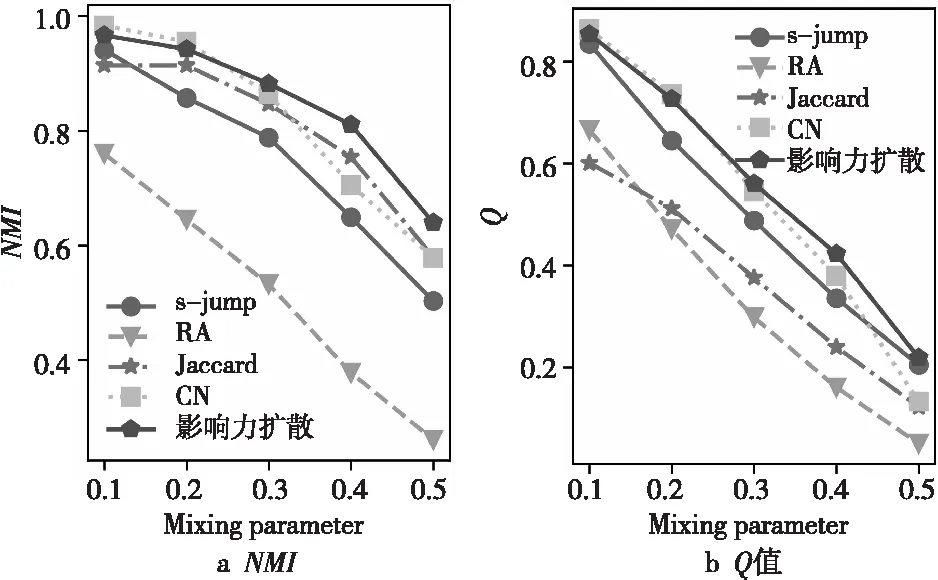
Figure 7 Comparative experiment of similarity index图7 相似度指标对比实验
5.4 算法优势的结论
在人工合成数据集和真实数据集上的实验可知,DA-EF算法具有精确度高以及收敛快的优势。同时,为了进一步探索该算法优势的原因,对森林编码器的引入、自动编码器的层数和影响力扩散指标分别进行对比实验。本文算法引入的森林编码器提升了表征学习的能力,森林编码器具有简易的统计学习思维以及快速表征学习的特点,但对于从高维度映射到低维度的数据不敏感,所以将自动编码器降维优势和森林编码器表征学习优势进行结合。此外,森林编码器不仅降低了自动编码器的层数而且能够提升算法收敛速度,即在保证网络深度的同时,能够降低算法的复杂度。影响力扩散指标保证了网络信息的完整度和提供给模型的良好输入数据。因此,该算法的优势主要来自于森林编码器和自动编码器优势互补以及对网络良好的表示。
6 结束语
本文提出的DA-EF算法,将深度神经网络中的自动编码器与森林编码器组成二级级联模型,应用于复杂网络的社区发现,尤其适用于大规模网络。
为了更好地表征网络,本文提出了影响力扩散相似度指标,增加节点之间没有连边的局部信息。首先,通过影响力扩散计算网络中节点间的相似度,构成网络的相似度矩阵;然后,利用DA-EF算法对其进行降维和表征学习,得到低维高阶特征矩阵;最后,利用K-means算法聚类,得到网络的社区划分结果。经过与K-means、DA-EML和CoDDA算法在人工合成网络LFR和真实数据集上的实验对比表明,DA-EF算法具有精确度高和适合大规模复杂网络的优点;同时对算法的性能分析实验表明,森林编码器的级联形式具有积极作用,使用合适的自动编码器的层数和相似度指标对算法的精确度有影响。DA-EF算法相比其它算法具有精确度高的优势,但也存在算法参数和模型结构不易选取问题,森林编码器和自动编码器的结合会导致鲁棒性较差的问题。下一步将对DA-EF算法作进一步优化,利用半监督学习解决这一问题。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
东北水利水电(2022年6期)2022-06-28
科学技术创新(2022年15期)2022-05-18
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
电子制作(2019年11期)2019-07-04
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
探测与控制学报(2015年4期)2015-12-15
小天使·五年级语数英综合(2015年4期)2015-04-20
