
基于层次分析法与理想点逼近法的车辆安全驾驶评价模型
2020-10-10 16:47蔡小敏张梓坪张佳楠林耿
廊坊师范学院学报(自然科学版) 2020年3期
蔡小敏,张梓坪,张佳楠,林耿
(闽江学院,福建福州350108)
0 引言
当今时代汽车普及化,汽车已经成为日常生活中不可或缺的交通工具,因此,保证驾驶安全一直是人们追求的根本目标。驾驶人作为道路交通系统的主体,不仅仅是事故处理的决策者,同时还是事故的参与者与受害者。根据事故统计分析,与驾驶人有直接因果关系的道路交通事故高达85%以上[1],可以说绝大部分事故与驾驶人员自身紧密相关。要从根本上提高我国驾驶人员交通安全意识,规范交通行为,需对驾驶人员的行为特征展开深入研究。
鉴于此背景,分析驾驶人在驾驶过程中的行为对行车安全、运输效率与节能情况具有重要意义。秦雅琴等[2]根据在风险驾驶情境中的驾驶行为数据,通过多项Logistics回归模型实现了驾驶人风险感知类型预测;吴紫恒等[3]提出了一种基于FCMBP方法的驾驶行为实时分类的模型;任慧君等[4]针对车载GPS轨迹数据提出相对应的特征提取方法,但并没有针对特征背后的内容进行深层次的挖掘;Herrera等[5]通过应用GPS定位手机的方法,制作了交通数据的系统平台,却未对驾驶行为进行分析;Greaves等[6]通过对GPS技术的应用,获取车辆驾驶数据,但仅对驾驶人超速驾驶行为进行了分析。美国爱达荷州大学国家高级运输技术研究中心的Wei Lien Liang和Dr.Michael Kyte在研究环境对驾车车速的影响时发现,环境和能见度对车速有显著影响,能见度降低,车速也随之降低。但是,它们并不成线性关系,变异系数较大。以上这些方法均未能综合考虑各种因素对运输车辆驾驶行为的影响。
本文利用车联网记录车辆运行过程中的卫星定位信息、驾驶速度等数据,并结合《汽车驾驶节能操作规范》释义和《中华人民共和国道路交通安全法实施条例》释义中的说明,总结出7个驾驶行为特征。设计并定义了驾驶人行为的特征指标和评价指标,通过回归分析方法对驾驶人的驾驶风格进行分析;采用两种聚类算法对驾驶人的不良行为进行科学聚类;经过对比,最终选用K-means聚类算法和因子分析的结果对驾驶行为进行评价,共分为6类,并给出相应的建议。本文通过对车联网数据进行挖掘,建立行车安全的评价模型。该模型建立了车联网数据与安全驾驶行为分析的有效关联,具有更高的准确性与科学性。
1 不良驾驶行为特征提取
本文所采用的数据来自某运输企业车联网系统,运输企业管辖范围内的每辆车都可以在驾驶员每次运输期间自动采集当前的驾驶状态信息并上传到车联网系统。
车联网借助装载在车辆上的电子标签通过无线射频等识别技术,提取和有效利用信息网络平台上所有车辆的属性信息以及静、动态信息,同时根据功能需求的不同,对所有车辆的运行状况进行有效监管并提供综合服务。
ArcGIS是一个全面的地理信息系统,用户可用来收集、组织、管理、分析、交流和发布地理信息[7]。借助ArcGIS软件,在WGS-84(世界标准地理坐标系)的坐标系下,导入中国地图的shp文件,将采集的数据抽样导入,样本的线路图显示驾驶员均在江西省内运输。
根据所采集的数据,设计并提取以下不良驾驶行为特征参数。
1.1 疲劳驾驶
《中华人民共和国道路交通安全法实施条例》第六十二条第七款规定:驾驶机动车时不得有连续驾驶超过4h未停车休息或者停车休息时间少于20min的疲劳驾驶行为[8]。本文连续驾驶时间用T表示,全天驾驶时间用Total表示,即:
T≥4h或Total≥8h。
1.2 急加(减)速
通过GPS速度计算出其瞬时加速度,通过加速度对急停急起进行分级评价。急加(减)速行为等级划分标准。
一级标准:加速度≥2.78m/s2或加速度≤-2.78m/s2,此时速度差为10km/h,对油耗影响较大,车内货物可能发生重摔。
二级标准:2.22m/s2≤加速度<2.78m/s2或-2.78m/s2<加速度≤-2.22m/s2,此时速度差为8km/h,对油耗影响适中,车内货物可能发生摔落。
三级标准:1.67m/s2≤加速度<2.22m/s2或-2.22m/s2<加速度≤-1.67m/s2,此时速度差为6km/h,对油耗影响较小,车内货物可能发生碰撞。
1.3 熄火滑行
当车辆行驶中临时关闭发动机判定为熄火滑行,且车辆速度不为0。本文主要通过两个触发条件:发动机状态Acc_state=0和GPS速度v>0,判断驾驶人员是否存在熄火滑行行为,并记录熄火滑行行为的次数。
1.4 超长怠速
怠速状态是指发动机空转时的一种运转状态。根据《汽车驾驶节能操作规范》,停车超过60s时,应将发动机熄火[9]。通过计算车辆行驶过程中的停车怠速时间,判定其是否存在停车怠速状态。判断条件包括两个方面:发动机转速不为零且车速为零,即车速v=0和Acc_state=1。如果怠速时间超过限制时间T_a时,则认为行驶过程中出现超长怠速行为,并记录超长怠速行为的次数。本文设定限制时间T_a=60s。
1.5 怠速预热
车辆预热是驾驶过程中必不可少的行为,但预热时间无需过长,否则易对发动机造成损伤,从而留下安全隐患[10]。本文首先读取车联网数据,如果数据符合当天非首次发动的数据或者该条数据的上一条数据发动机状态Acc_state≠0的判定条件,则认为是正常驾驶过程中的停车怠速,不属于预热怠速行为。因此,车辆预热怠速的判断条件为:①GPS速度v=0;②发动机状态Acc_state=1;③发动机状态Acc_state=1的数据是当天首次发动的数据或该数据的上一条车联网数据的发动机状态Acc_state=0。
1.6 超速
判断车辆当前速度是否超过道路限定速度,如果判定车辆超速,记录时间t1,当车辆速度低于限定速度,记录时间为t2;超速时间t=t1-t2;超速次数加1。
1.7 急变道
判断车辆每秒转过的角度(角速度rad/s),如果每秒转过的角度过大,则判定为急变道。
2 驾驶行为安全性多属性评价模型
2.1 不良驾驶行为特征整合与分析
2.1.1 特征数据的整合
在不良驾驶行为特征提取时,主要得到的是每一辆车在数据集的整个行程中发生不良驾驶行为的次数,但因为每一辆车在整个行程中的总里程数不一样,所以要以单位里程中发生不良驾驶行为的次数来标注每一个特征值。为此,引入以下变量:
count:整个行程中发生不良驾驶行为的次数;
total_mileage:整个行程中的总里程数;
count_permileage:单位里程上发生不良驾驶行为的次数,则

以上述方式计算后发现有的为小数(比如0.00002),有的为整数。需要进行规范化,使单位里程上的次数都为整数,于是在上述计算方式的基础上将结果扩大10000倍,即

数据整合后为7个特征值和1个目标值(待标记),为了叙述方便,给出对应的符号定义。本文所用到的符号在表1中给出。
2.1.2 不同评价指标的相关性分析

表1 特征提取所用到的符号
在一个特征集合中,特征之间可能存在着某种联系,通过相关性分析,判断特征集中是否存在过强的关联性。如果指标之间有较强的关联性,则说明指标之间存在冗余。因此,当建立一个特征矩阵时,检验其指标的相关性系数,保留最直接能体现评价结果的有效指标,减少工作量,利用450个待评价车辆的实验数据对不同表征的相关性进行分析,相关性的计算结果如表2所示。
由相关性分析结果显示各特征之间均不存在强相关性,相关性最大的超速和超长怠速两个特征之间的相关性也仅为0.3,不存在冗余特征,所以应根据这7个特征进行分类。

表2 特征相关性分析结果
2.1.3 指标集合内在分布结构分析
假设对车辆的行车安全给出的评价结果是两类即安全和不安全,为此,采用K_means聚类分析方法,令k=2,对训练数据进行二分类,数据的内部分布情况如图1所示。

图1 粗聚类结果
图1 展示的是粗聚类的结果,两个簇的簇中心对应的7个特征的值,因为聚类前对数据进行了标准化,所以簇中心的特征值存在小于0的情况。从图中明显地看出类别0的簇中心的特征值普遍比类别1的簇中心小,所以可以初步认为聚类的簇0为行车安全的类别,簇1为行车不安全的类别,这对后面的决策树分类也有一定参考价值。根据图1来看,训练数据进行聚类行成2簇,两种类别比例大概为1:2.5,数据的分布相对偏差不大。
2.2 不良驾驶行为特征权重计算
车辆行为安全性的评价分析中,因多属性指标在评价中的贡献值不同,导致不同属性的评价指标对行车安全性的影响不同。因此,有必要对不良驾驶行为属性评价指标进行权重计算,建立最为合理的评价方法。
熵信息法是一种客观的判断指标权重的方法,这个方法通过指标客观信息,定义在同一个指标间的波动越小,则该指标的权重越小;若波动越大,那么指标权重就越大。这类方法的优点是简单,所需定量数据信息不多,但是,定性成分多且当指标过多时,数据统计量大,且权重难以确定。为了兼顾专家对指标的偏好和指标间的客观信息,采用层次分析法对不良驾驶行为指标进行主观赋值与评价,同时考虑各特征的熵信息赋予的权值,在此基础之上,通过最小二乘法确定最终各指标的权重[11]。
2.2.1 特征客观权重确定方法-熵值法
在信息论中,熵是系统无序程度的一种度量,熵越小,不确定性就越小,熵越大,不确定性也越大。根据此性质,可以利用评价中各方案的固有信息,通过熵值法得到各个指标的熵,熵越小,其信息的效用值越大,指标的权重越大[12]。具体求解过程如下。
(1)数据标准化
假设给定的数据矩阵包含n条数据,m个属性,即其数据矩阵如公式(3)所示。

采用最小-最大规范化规范数据,将各属性值映射到区间[0,1]上。假设规范化前xij表示第i条数据的第j个属性值,x′ij表示其规范化之后的值。具体的规范公式如下:

(2)求各属性的熵
对规范化之后的数据,计算各属性的信息熵。首先计算第j个属性下第i条数据所占该属性的比重,假设计算后的值为pij,其计算公式为:

假设第j个属性的信息熵值用ej表示,则其计算公式如下:

其 中k=1/ln(n)>0,如 果pij=0,则 定 义
(3)计算各指标权重
求出m个属性的信息熵依次为e1,e2,e3,…,em,假设第j个属性计算出的权重为wj,其计算公式为

通过应用熵权法对450条数据、7个属性进行处理与计算,计算出7个属性的权重如表3所示。
2.2.2 特征主观权重确定方法-AHP

表3 基于熵权值的指标权重
首先确定目标层为“行车不安全”,将“行车不安全”划分为“行车危害行为”、“违规行为”、“驾驶员不良驾驶习惯”三个准则。根据准则代表的实际物理意义及其可能包含的不良驾驶行为,构建出层次分析结构[13],如图2所示。
对于方案层各元素,给出其相对重要性,构建判断矩阵[14]。

图2 聚类结果分析
准则层元素对目标层的相对重要性判断矩阵:

方案层相关元素对行车危害行为的相对重要性判断矩阵:
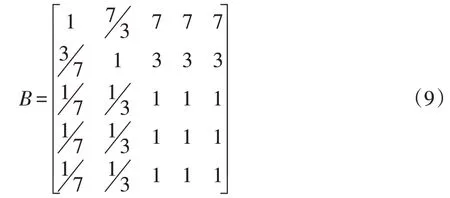
方案层相关元素对“违规行为”的相对重要性判断矩阵:

方案层相关元素对结束阶段不安全的相对重要性判断矩阵:

由于B1阶数为2,不需要进行一致性检验。对于剩下的3个矩阵,进行单排序以及一致性检验。通过检验,发现3个矩阵均具有较好的一致性,可进行后续计算。
将方案层中计算出的所有元素对准则层各元素权重组成矩阵,进行层次总排序。通过总排序可以计算出方案层各元素对目标层影响程度的权值,各属性影响权值如表4所示。
2.2.3 最小二乘法融合权重

表4 基于层次分析的指标权重总排序
假设各不良驾驶行为指标综合权重为η=(w1,w2,…,wn)T,为了达到主观和客观的统一,综合后的权重指标与主客观权重决策结果偏差越小越好。因此,建立如下最小二乘法决策模型:ω和μ分别为两种方法求出的权重列向量,η为混合权重向量,X是标准化之后的数据矩阵。
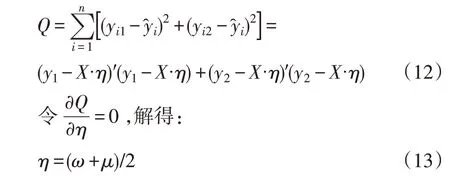
2.2.4 结果利用梯度下降法计算混合权重的结果如表5所示。
2.3 基于理想点逼近法(TOPSIS)构建评价模型

表5 基于层次分析的指标权重总排序
TOPSIS是一种用于多目标决策的方法,通过检测评价对象与最优解、最差解的距离来排序。若评价对象最靠近最优解同时又最远离最差解为最好;否则为最差。考虑TOPSIS法原理简单并对实验样本要求不高,并且可生成一个明确的安全等级,因此,选取TOPSIS来做为评价车辆行为安全性的方法[15]。
2.3.1 理想点逼近法(TOPSIS)
(1)构建初始评价指标矩阵
在对450辆车的7个不良驾驶行为进行统计分析后,给出车辆不安全指数的评价矩阵Z:

由于各属性量纲相同,均为“次/万千米”,因此,不需要对评价指标矩阵进行属性值的规范化。
(2)构建加权评价指标矩阵
前面使用了层次分析法、熵权法两种手段对各个异常行为特征的权重进行了计算,并使用最小二乘法将两种权重进行了融合,最终得到了综合权重向量,并根据该向量得到了综合权重矩阵W:

在得到异常行为特征权重后,即可计算得到加权评价指标矩阵F:

其中,fi,j=wj zi.j;i=1,2,…,450;j=1,2,…,7
(3)确定正负理想解
对于加权评价指标矩阵F,找到第j列的最优记为f∗j,最劣为f^j,最终得到正理想解和负理想解需要注意的是,对于加权评价指标矩阵F,元素的值越大,说明该车辆样本在该异常特征下的表现越不安全。因此,每一列的最小值为最优,最大值为最劣。
①计算各样本与正负理想解的距离
对于每个车辆样本,依次计算它们与正负理想解的欧氏距离如下:

②计算相对接近度并作出判断

对于每个样本,计算相对接近度如下:需要明确的是Ci的取值范围为[]0,1,取端点的情况为:

相对接近度越大,说明车辆样本与正理想解距离越小,与负理想解距离越大,驾驶行为越安全。如果将样本按照相对接近度由大到小排序,那么设定阈值后取末尾若干位,得到的即是不安全行驶的车辆。
2.3.2 结果分析
通过TOPSIS算法分析,共有126辆车被标记为不安全,其余324辆车被标记为安全。对于评估中不安全车辆所占比例的合理性,解释如下。
在TOPSIS算法中,最后一步需要确定相对接近度阈值,这样才能对样本进行二分类,确定车辆的驾驶行为是否安全。但是,算法本身并没有给出确定阈值的具体方法,单凭主观判断给定阈值,无法判断划分得是否准确,这样就失去了算法根据7个异常行为特征的综合权重对车辆进行分类的意义。
对此,希望寻找一种客观的方法,通过客观分析来得到相对接近度下限Cs。
使用聚类分析样本二分类的均衡性,而聚类分析正是一种无监督学习,能够根据数据集中样本本身的相似度特性,分出不同的簇,且不需要人为干预。采取基于划分的K-means算法,得到了二簇聚类的结果:两个簇的样本数目分别为124和326。
基于聚类分析,如果分类的结果比例接近于聚类的结果,那么该分类是比较符合客观情况的,对此,不断调整相对接近度下限Cs,最终发现,当Cs=0.96时,分类的结果的比例最接近聚类结果,如表6所示。

表6 Cs阈值选取
最终,确定了相对接近度阈值,得到了分类结果。用K_means聚类和理想点逼近法(TOPSIS)两种方法,对原数据进行标记,存在部分歧义。对于每一辆车的行车安全(drive_safety)得到两种标记。两种不同标记的比较如表7所示。

表7 两种标记方式结果比较
由表7可知,两种标记相同的样本数为373个,标记不同的样本数为77个。
2.4 评价决策树的构建
2.4.1 决策树评价模型
为了进一步确定77个不一致数据的行车安全性,基本思想是在标记相同的数据集上(即373个)训练一个分类器,由于决策树分类器的可解释性以及经调参后的准确率优于其他分类器,通过调节max_depth、min_impurity_split、max_leaf_nodes以及min_samples_leaf,使得模型最优的参数如表8所示。

表8 参数的解释以及最优取值
2.4.2 决策树方法与结果分析
本文采用准确率(Precision)和召回率(Recall)来对推荐效果进行评估。推荐效果取决于推荐正确和推荐错误的数量。准确率便是基于这两点,以下为准确率计算公式:

其中precesion代表准确率,TP代表被模型预测为正的正样本,FP为被模型预测为正的负样本。准确率越高则推荐质量就越高。
召回率同样可以作为验证推荐正确性的指标,基于如下公式:

其中recall代表召回率,TP代表被模型预测为正的正样本,FN为被模型预测为负的正样本。
基于训练好的决策树,对已标注的测试集进行预测,预测结果通过混淆矩阵的形式,如表9所示。
从表9可以计算出,模型的准确率为0.969,召回率为0.904,f值为0.809,因此,该模型表现出了较好的评价能力。决策树分类器的另一优点在于可解释性比较强,同时评价规则也比较直观。

表9 测试结果的混淆矩阵
根据决策树输出的规则,可以看出以超速特征为属性进行划分的效果最好,即分类的基尼系数(Gini)最小,分类的不纯度最低,其次是疲劳驾驶特征、急加急减特征。这也与主观想法类似,超速行为对行车安全影响最大,然后是疲劳驾驶和急加急减速。而其他一些特征,如怠速、熄火滑行等可能对车辆本身的伤害比较大,对行车过程安全的影响相比于上面几个特征要小得多。通过TOPSIS评价模型和聚类结果分析,最终发现有77个车辆行车安全的评价是不一致的,对此,可以以通过训练的决策树评价模型进行进一步修正。
基于投票的方式,将之前不一致的评价结果进行修正。由最终预测结果可知,对于两种方式标记结果不同的样本,最终预测结果大部分与TOPSIS方法标记的结果相同。也可以认为相比于最初的两种标记方法,TOPSIS的效果比较好,同时TOPSIS能够给出相应的行车安全性等级。
3 结论
本文首先采用主客观相结合的方法对权重进行融合,形成兼顾专家意见与客观数据因素的评价指标权重;其次,根据理想逼近法TOPSIS法对评价模型进行构建,并在真实数据上对研究对象进行安全等级排序;最后,通过K-means对数据进行粗略二分类,将TOPSIS标记与粗略二分类的标记进行对比,选出标记相同的数据作为标注数据,训练二叉决策树评价模型,利用训练好的模型再对不确定数据进行评价,最终以投票的方式对不确定的数据进行安全性评价。结果表明,该评价模型能够高效和准确地对运输车辆安全驾驶行为进行分析。
猜你喜欢
当代陕西(2020年17期)2020-10-28
铁道通信信号(2019年6期)2019-10-08
人大建设(2018年5期)2018-08-16
雷达学报(2017年6期)2017-03-26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
应用科技(2015年5期)2015-12-09
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
