
面向贵州省三大战略行动的文本挖掘及LDA 模型分析研究
2020-10-13 08:58杨秀璋武帅夏换于小民范郁锋丛楠张懿源
现代计算机 2020年25期
杨秀璋,武帅,夏换,于小民,范郁锋,丛楠,张懿源
(1.贵州财经大学信息学院,贵阳550025;2.贵州财经大学,贵州省经济系统仿真重点实验室,贵阳550025;3.贵州财经大学计划财务处,贵阳550025;4.贵州财经大学,贵州省电子商务大数据营销工程研究中心,贵阳550025)
0 引言
随着大数据和计算机技术的迅速发展,政务信息逐渐依托于互联网发布,然而,网络上存在着数量庞大、语义复杂的文本数据,如何从这些数据中挖掘出用户需要的精准信息,获取民众对国家和省部级政策、战略的关注主题及舆情影响,已经成了当今研究的热点内容[1]。
目前国内外很少利用数据挖掘或机器学习算法深层次分析政用信息,也没有针对贵州省三大战略行动的主题挖掘和舆情分析研究。因此,本文研究了面向贵州省三大战略行动的文本挖掘及LDA 模型分析。首先通过Selenium 和XPath 技术抓取微信公众号关于贵州省大扶贫、大数据、大生态的网页文本信息,再进行数据预处理,最终利用LDA 模型和K-means 聚类算法进行文本主题挖掘。本文提出的模型可以广泛应用于国家战略和社会话题的主题分析、舆情检测、文本挖掘、知识计算等领域,更好地帮助国家和各省份进行舆情分析和预测,实现政用信息主题挖掘,为政府管理、社会治理和民生服务提供舆情预警,推进社会经济的稳定发展。
1 相关研究进展
1.1 贵州省三大战略
贵州省坚守发展和生态两条底线[2],统筹推进国家大数据综合试验区、生态文明试验区和内陆开放型经济试验区建设。中共贵州省第十二次代表大会明确提出了“决战脱贫攻坚、同步全面小康、奋力开创百姓富生态美的多彩贵州新未来”三大奋斗目标,吹响了“大扶贫”、“大数据”和“大生态”三大战略行动。
在大扶贫方面,贵州省寻求问题根源,致力于脱贫攻坚第一线[3]。在大数据方面,贵州省率先深挖大数据潜在的商业、政用以及民用价值,成立了全国首家大数据综合试验区,全国首个省级政府大数据平台——“云上贵州”大数据平台[4]。在大生态方面,贵州省全面贯彻落实习总书记关于“青山绿水就是金山银山”的理念,坚守发展和生态两大底线。坚持绿色发展优先的同时,推进贵州生态文明建设,共同为多彩贵州新未来而奋斗[5]。
1.2 主题挖掘
主题挖掘旨在通过主题模型与识别不同来源文本的主题、关键词、情感分散、聚类类标等对文本挖掘以及舆情分析[6]。主流的主题模型算法包括LSA 和LDA。Blei 等人[7]提出了LDA(Latent Dirichlet Alloca⁃tion)主题模型,并被广泛应用于各个领域。王世杰等人[8]将Hawkes 模型与LDA 模型结合深度学习算法进一步提高信息扩散过程中的预测精准度。在应用领域上,孟超颖等人[9]提出基于LDA 耦合空间计算文章之间相似度来提高作文检测准确度。金苗等人[10]基于LDA模型分析构建西方主流媒体舆论地图。周娜等人[11]基于LDA 主题模型揭示学科领域隐性知识组合。熊回香等人[12]基于LDA 生成的标签准确地描述微博用户的使用特征。冯勇等人[13]基于TF-IDF 和LDA 主题模型来提高中文短文本分类精确度。杨秀璋[14]针对水族文献进行了LDA 主题挖掘研究。
尽管国内外学者就主题挖掘在算法创新和应用领域都有些许研究,但很少有学者利用数据挖掘或机器学习的算法来分析政务信息,也不能很好地完成针对政务知识的舆情分析和文本主掘研究,甚至由于不及时处理某些突发性的新闻报道,可能会给政府和社会造成非常重大的损失。针对上述问题,本文拟采用LDA 模型和文本聚类分析贵州省大扶贫、大数据、大生态三大战略的政用主题知识,为政府提供更好的舆情监测,掌握民生动态。
1.3 LDA模型
LDA 是一种文档主题生成模型,由Blei 等人[7]在2003 年首次提出,是一种基于主题(T)、文档(D)和主题词(W)的三层贝叶斯结构,其中文档到主题(D-T)以及主题到主题词(T-W)层面均服从多层分布。LDA 主题模型将多个文档(D)映射到k 个主题(T)中,每个主题(T)包括一定量的主题词(W)的主题模型。
本文主要针对贵州省“大扶贫、大数据、大生态”三大战略行动完成主题挖掘研究,经过LDA 主题分布后,得到各个文档的不同主题所占比例,实现贵州省三大战略行动各主题关键词的挖掘,并给出每篇文档对应的关键词及比例。
2 文本主题挖掘算法
2.1 基本思路与流程
本文采用LDA 模型、K-means 算法进行政务数据分析,旨在挖掘贵州省三大战略行动的微信公众号网页文本知识,获取深层次的语义主题词,实现政务数据舆情分析。该算法的框架图如图1 所示。
(1)调用Python、Selenium 和XPath 技术自动抓取微信公众号关于贵州省大扶贫、大数据、大生态的网页文本,并存储至本地保存。
(2)对抓取的文本语料进行数据预处理,包括中文分词、停用词过滤、特征提取和权重计算。
(3)进行LDA 主题模型分析和文本聚类挖掘,并采用可视化技术进行文本类别识别和结果展示。同时,LDA 模型可以获取<主题,词>和<文档,主题>的概率分布矩阵,最终将相似性较高的主题及文本聚类在一起。
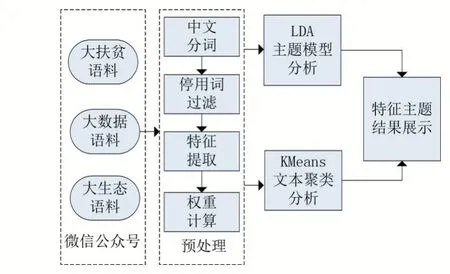
图1 文本主题挖掘框架图
2.2 自定义爬虫抓取数据
本文主要分析贵州省政用信息,通过自定义爬虫抓取贵州省大扶贫、大数据、大生态的网页文本信息。构建一个基于Python 语言环境下的Selenium、XPath和PhantomJS 技术的网页自动爬虫,所抓取的信息包括网页标题、发表时间、正文内容、涉及主题等相关字段,其抓取流程如图2 所示。爬虫管理器依次遍历含微信公众号的URL 队列,输入关键词并设置需要抓取网页的日期,然后发送HTTP 请求调用XPath 技术解析贵州省三大战略网页文本,最后将网页下载至数据存储器进行主题挖掘实验。
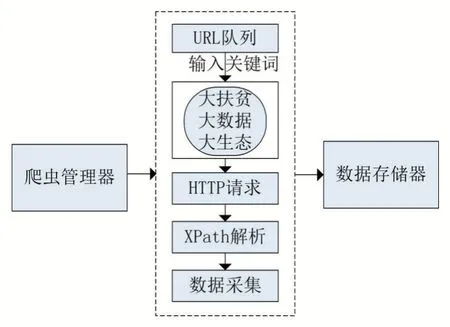
图2 自定义爬虫流程图
2.3 基于LDA模型和K-means聚类算法的贵州三大战略主题挖掘
本文基于LDA 主题模型以及K-means 文本聚类算法对贵州省三大战略行动的网页文本信息进行主题挖掘。采用Jieba 工具进行中文分词和停用词过滤;依托TF-IDF 计算各特征词权重,其主要程度由特征词在文档中出现的次数以及在整个数据集中出现文档频率决定的,从而尽可能保留影响程度高的主题词,进而起到降维的效果;最后利用LDA 主题模型分析各主题的Top-N 个主题词及文档主题分布,通过K-means 算法进行文本聚类,旨在尽可能提高文档间的相识度,将原本无标签的文档依托文档相似性自动归类。完整算法如下所示:
算法1:贵州三大战略主题挖掘方法
输入:贵州省三大战略主题网页文本数据
输出:文档-主题-关键词、聚类类标、情感分数
步骤:
①对所抓取的数据集进行基于Python 环境下Jie⁃ba 工具进行中文分词;
②对分词后的数据集进行停用词过滤、数据清洗、特殊符号去除等数据预处理;
③提取文本语料特征,利用向量空间模型VSM 将中文文本数据转化为数值向量;
④对第③步所筛选的特征词进行TF-IDF 权重计算,将每篇文档转换为主题词矩阵;
⑤利用LDA 模型进行分析,设置主题数为3,分别计算每个主题下的Top-N 主题词,计算每篇网页文本所属主题;
⑥采用KMeans 聚类算法进行文本聚类,对所有网页文本进行聚类分析;
3 实证分析
(1)数据抓取与预处理
本文数据集采用Python 自定义爬虫抓取微信公众号关于贵州省“大扶贫、大数据、大生态”的网页文本信息,所抓取的字段包括新闻标题、发布时间、超链接、关键词、网页文本等。数据的起始时间为2018 年7 月20日,每类主题抓取各100 篇网页,图3 表示抓取至本地的数据集。
数据预处理主要将所采集的政务数据集进行中文分词,导入Jieba 词典进行停用词和特殊标点过滤,最终提供干净且高质量的数据集,为后续分析提供支撑。
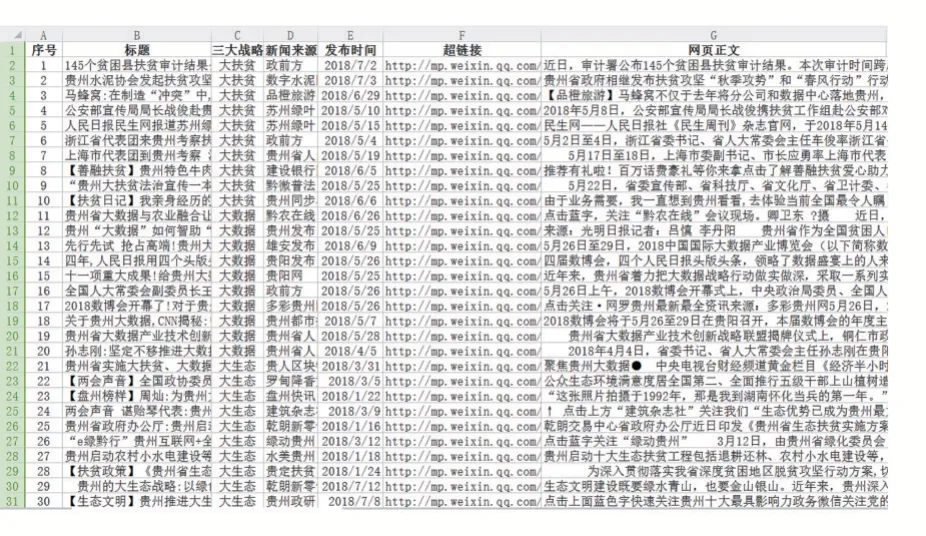
图3 贵州三大战略部分数据集
(2)评价指标
本实验采用准确率(Precision)、召回率(Recall)和F 值(F-measure)进行实验评估。其中,准确率P(i,j)定义如公式(1),召回率R(i,j)定义如公式(2),F 值定义如公式(3)所示。
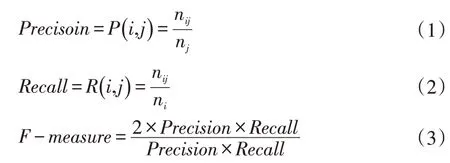
其中,ni表示主题为i 的文本数目,nj表示聚类主题为j 的文本数目,nij表示聚类主题为j 中属于原主题i 的数目,最终结果通过F 值平衡。
2)在60℃时,加入0.021 mol/L的亚铁离子,1.0 mol/L的氨水,恒温搅拌8 min,混合矿赤铁矿的回收率由70.86%提高到83.39%,同时尾矿铁品位由16.59%降低到11.63%。
(3)文本聚类实验
文本聚类实验采用TF-IDF 计算各特征词权重,其主要程度由特征词在文档中出现的次数以及在整个数据集中出现文档频率决定的,从而尽可能保留影响程度高的主题词,进而起到降维的效果从而提升实验的准确率、召回率和F 值。
TF-IDF 计算公式如(4)所示,它能按照特征词在文档中的重要程度进行权重计算,从而尽可能提升影响程度较高的特征词重要性,降低影响程度较低的特征词重要性。

其中,tfidfi,j表示词频tfi,j和倒文档词频idfi,j乘积,tfidfi,j值越大则该特征词对这个文档的重要性就越高。TF 表示某个主题词在整个文档中出现的频率,其计算如公式(5)所示,ni,j为特征词在训练文本dj中出现的次数,分母是文本dj中所有特征词个数,计算结果为特征词的词频。

IDF 表示计算倒文本频率,其计算公式如(6)所示,|D|表示数据集中文本的总数,|Dti|表示文本中包含特征词ti的数量。为防止某些词语在数据集中不存在,及公式(6)中的分母为0,故使用1+|Dti|作为分母,以防止无法计算。

贵州省三大战略的K-means 文本聚类结果如图4所示,共将网页文本聚集成三类主题,其中红色圆圈表示大数据、蓝色方块表示大扶贫、绿色星星表示大生态。从图4 可以看到三个类簇有效的分隔开来,说明文本聚类效果显著。
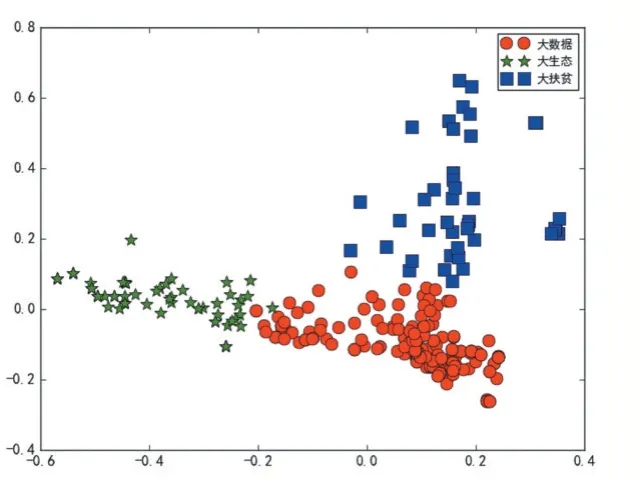
图4 K-means文本聚类图
文本聚类实验结果如表1 所示,其中“大数据”主题聚类实验结果最好,准确率为0.905,召回率为0.570,F 值为0.699;而大扶贫和大生态实验结果不太理想,F 值为0.674 和0.645。由于三大战略主题相互融合,部分网页可能同时描述三大战略不同主题的内容,所以会出现主题识别不精准的情况,接下来的LDA主题模型分析将会进一步优化。
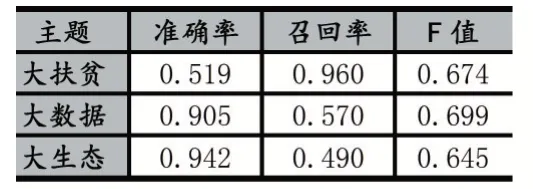
表1 K-means 文本聚类实验结果
(4)LDA 主题分布实验
在基于LDA 模型的主题挖掘实验中,设置的主题数(n_topic)为3,迭代次数(iterations)为500,调用基于Python 的LDA 主题模型进行模拟训练及计算,LDA 主题模型三大主题的前30 个主题词如表2 降序排列。

表2 LDA 模型主题-词识别结果
由表2 可知,每个主题的差异明显。主题0 中的特征词主要是大扶贫战略,包括“脱贫”、“扶贫”、“贫困户”、“建档立卡”、“搬迁”等相关词汇;主题1 中的特征词主要是大数据战略,包括“数据”、“贵阳”、“互联网”、“融合”、“人工智能”等相关词汇;主题2 中的特征词主要是大生态战略,包括“生态”、“绿色”、“旅游”、“苗族”、“环保”、“健康”等相关词汇。
图5 是三大战略“文档-主题”分布图。图中表示了文档下标为0、1、101、102、201 和202 六篇网页的主题分布。X 轴表示3 个主题(0 代表大扶贫主题、1 代表大生态主题、2 代表大数据主题),Y 轴表示每个主题所占的比例,其中文档0、文档1、文档101 预测的主题为0(大扶贫),文档102 预测的主题为2(大数据),文档201、文档202 预测的主题为1(大生态),文档下标为0、1、102、201、202 的预测成功,而文档101 真实主题为大数据,却被预测为大扶贫。
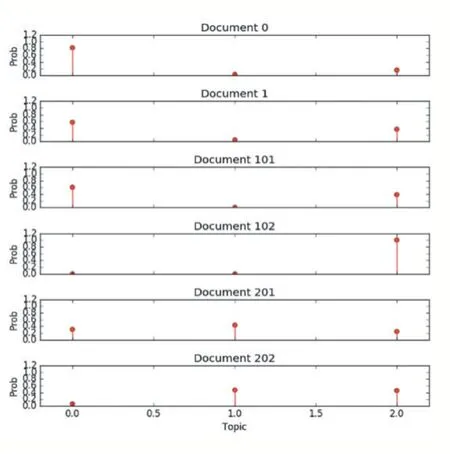
图5 LDA文档-主题分布图
图6 是比较LDA 模型和K-means 文本聚类算法的F-值实验结果。图中X 轴表示大扶贫、大数据、大生态三个主题,Y 轴表示F-值,实验结果显示:LDA 主题模型的方法优于传统基于TF-IDF 模型的文本聚类方法,其中大扶贫主题的F-值从0.674 提升到0.704,大数据主题的F 值从0.699 提升到0.838,大生态主题的F 值从0.645 提升到0.671。
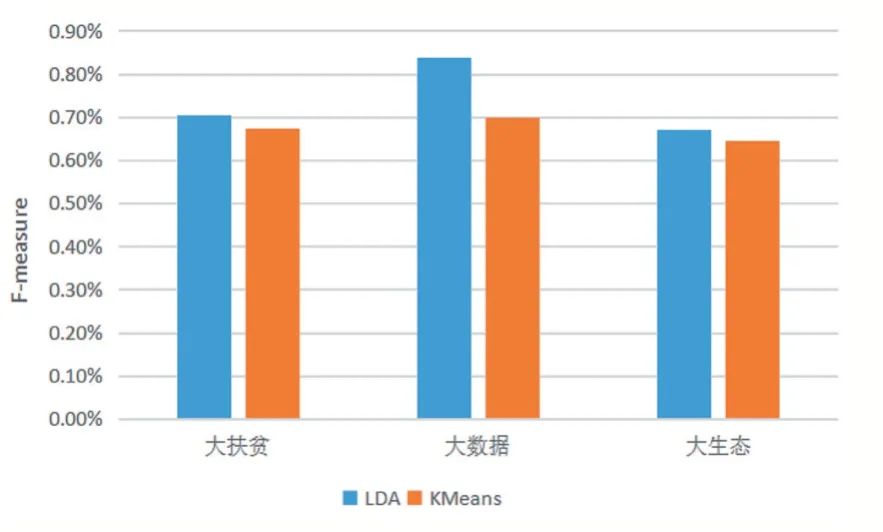
图6 LDA主题算法与K-means聚类算法F值对比图
4 结语
本文的研究成果主要应用于政务信息的文本挖掘与舆情分析,以贵州省大扶贫、大数据、大生态网页文本为例进行主题分布和文本聚类的研究。实验结果表明,本文提出的算法有效地挖掘出贵州省三大战略的主题关键词及民众关注话题,各提取了30 个主题词,使得文本的主题脉络更加清晰,同时计算出各类政用信息相关的舆情主题词及聚类结果,当给出一篇新的新闻网页时,能准确实现新闻主题分类和关键词挖掘。同时,本文也存在一些不足,如没有进行更深入的语义关系识别、情感分析及海量数据获取。
综上,为了更好地帮助政府部门、企业公司、高校及科研单位进行政务文本挖掘,实现文本知识主题提取,为政府管理、社会治理和民生服务提供舆情分析基础,推进社会经济的稳定发展,本文面向贵州省三大战略行动进行了详细的文本挖掘及LDA 模型分析研究,具有一定的理论研究意义和实际应用价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
南京理工大学学报(2022年1期)2022-03-17
中国新闻周刊(2021年26期)2021-07-27
计算机应用与软件(2021年7期)2021-07-16
电脑爱好者(2021年9期)2021-05-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
魅力中国(2018年5期)2018-07-30
中学科技(2016年7期)2017-05-16
电脑爱好者(2017年7期)2017-05-06
