
联邦学习浅析
2020-10-13 08:58王佳苗璐
现代计算机 2020年25期
王佳,苗璐
(1.山西金融职业学院,太原030008;2.中国科学技术大学,合肥230000)
1 研究的背景
2016 年是人工智能(AI)成熟的一年,随着Alpha⁃Go 击败了顶尖的人类围棋选手,我们真正见证了人工智能的巨大潜力,并开始期待在许多应用领域出现更复杂、更尖端的人工智能技术,例如无人驾驶。目前,人工智能的成就依赖于大量可用的标记数据。例如,AlphaGo 使用了160000 个实际游戏的3000 万步作为训练数据,ImageNet 数据集中则包含了超过1400 万张图片[1]。
随着AlphaGo 的成功,人们自然希望大数据驱动的人工智能能很快在我们生活的方方面面实现。然而,现实情况却有些令人失望:在各个行业中,更多的应用领域中只有少量或低质量的数据,并且标记数据非常昂贵,特别是在需要人类专业知识的领域。因此,人工智能技术在这些行业的发展比较缓慢。
此外,特定任务所需的数据可能不会保存在一个地方。许多组织可能只有未标记的数据,而其他一些组织的标签数量可能非常有限。那么能否通过跨组织传输数据,将来自多个站点的数据融合在一个共同的站点上?事实上,在许多情况下,要打破数据源之间的障碍是非常困难的,甚至是不可能的。一般来说,任何人工智能项目所需的数据都涉及多种类型。例如,在人工智能驱动的产品推荐服务中,产品销售商有关于产品的信息和用户购买的数据,但没有描述用户购买能力和支付习惯的数据,这些数据可能存在于银行中。在大多数行业中,数据以孤岛的形式存在。由于行业竞争、隐私安全和复杂的管理程序,即使是同一公司不同部门之间的数据集成也面临着很大的阻力。几乎不可能将分散在全国各地的数据和机构整合起来。
此外,随着公众的数据安全和用户隐私的意识日益增强,数据隐私和安全已成为世界性的重大课题。有关公共数据泄露的新闻引起了媒体和公众的高度关注。例如,Facebook 最近的数据泄露引起了广泛的抗议。作为回应,世界各国都在加强保护数据安全和隐私的法律。例如,欧盟于2018 年5 月25 日实施的《通用数据保护条例》(GDPR),旨在保护用户的个人隐私并提供数据安全。它要求企业在用户协议中使用清晰明了的语言,并授予用户“被遗忘的权利”,即用户可以删除或撤回其个人数据。违反该法案的公司将面临严厉的罚款。中国2017 年颁布的《网络安全法》和《民法通则》要求,互联网企业不得泄露或篡改其收集的个人信息,在与第三方进行数据交易时,它们需要确保拟议的合同遵守法律规定的数据保护义务。这些法规的建立将有助于建立一个更为安全的社会,然而,如何在满足数据隐私的前提下,为缺少相关数据的企业和机构建立有效、准确的人工智能模型,是一个重大挑战。
更具体地说,人工智能中传统的数据处理模型往往涉及到简单的数据事务模型,一方收集数据并将数据传输给另一方,另一方负责数据的清洗和融合。最后,第三方将采用集成的数据,并构建模型供其他方使用。模型通常是作为服务销售的最终产品。这一传统过程面临着上述新的数据法律法规的挑战。因此,我们面临着一个两难的境地,即我们的数据是以孤岛的形式存在的,但在许多情况下,我们被禁止在不同的地方收集、融合和使用这些数据进行处理。如何解决数据碎片化和隔离问题是当今人工智能研究者和实践者面临的一大挑战。
2 联邦学习的定义
为了克服这些挑战,Google 首先引入了联邦学习(FL)系统[2]。谷歌的主要想法是基于分布在多个设备上的数据集构建机器学习模型,同时防止数据泄漏。最近的改进集中在克服统计数据挑战[3]和提高联邦学习的安全性[4]。也有一些研究致力于使联邦学习更加个性化[5]。以上工作都集中在涉及分布式移动用户交互的设备的联邦学习上,其中大规模分布的通信成本、不平衡的数据分布以及设备可靠性是优化的主要因素。
此外,数据是按用户ID 或设备ID 进行分区的,因此在数据空间中是水平的。联邦学习与保护隐私的机器学习密切相关,因为它还考虑了分散协作学习环境中的数据隐私。为了将联邦学习的概念扩展到组织间的协作学习场景,我们将原来的“联邦学习”推广到一个通用概念,即所有隐私保护的分散协作机器学习技术。
假设有N 个数据所有者{F1,…,FN,},他们拥有的数据分别是{D1,…,DN},每个数据所有者都希望通过整合各自的数据来训练一个机器学习模型。传统的方法是把所有的数据放在一起,使用D=D1∪…∪DN来训练模型MSUM。而联邦学习系统是一个协作过程,在这个过程中,数据所有者协同训练一个MFED,任何数据所有者Fi都不会将其数据Di公开给其他人。此外,MFED的精度VFED应该非常接近MSUM的精度VSUM的性能。形式上,设δ为非负实数;如果|VFED-VSUM|<δ则称该联邦学习算法有δ精度损失。
3 联邦学习研究的进展
联邦学习是人工智能当中发展较快的领域,研究成果层出不穷。接下来,本文将介绍近期的两项研究进展:联邦迁移学习和基于概率的联邦学习。
3.1 联邦迁移学习
迁移学习(TL)[6]是一种为数据集较小或只有部分标签的应用提供解决方案的强大技术。近年来,将迁移学习技术应用于各个领域的研究工作已经取得了很大的进展,比如图像分类以及情绪分析。迁移学习的性能取决于领域之间的关联程度。直观地说,同一个数据联邦中的各方通常是来自同一行业或相关行业的组织,因此更容易进行知识传播。
联邦迁移学习(FTL)适用于两个数据集不仅在样本上不同,而且在特征空间上也不同的场景。假设有两个机构,一个是位于中国的银行,另一个是位于美国的电子商务公司。由于地域限制,两家机构的用户群有只一个小的交集。另一方面,由于业务的不同,双方的特征空间只有一小部分重叠。在这种情况下,迁移学习技术为联邦内的整个样本和特征空间提供解决方案。具体来说,就是使用有限的公共样本集,学习到两个特征空间的公共表示,随后用这个公共表示获得只有单侧特征的样本的预测。联邦迁移学习是对现有联邦学习系统的重要扩展,因为它处理的问题超出了现有的联邦学习算法的范围。
近年来,深层神经网络被广泛应用于迁移学习中,来寻找隐含的迁移机制。在一般的场景中,A、B 双方通过两个神经网络产生各自的隐层表示d是隐层表示的维度。为了标记目标域,通用的方法是引入一个预测函数不失一般性,假设于是,训练目标函数可写为:
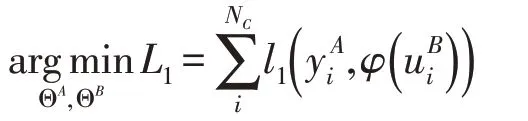
其中,ΘA,ΘB分别是NetA,NetB的训练参数。设LA,LB分别是NetA,NetB的层数,那么是第l层的训练参数。l1表示损失函数,对于logistic 损失,
另外,我们希望最小化A 和B 的对齐误差:

其中,l2表示对齐误差。典型的对齐误差可以是
最终的目标函数为:

接下来要获取反向传播过程中更新ΘA,ΘB所需的梯度:

其中i∈{A,B} 。联邦迁移学习要保证A 和B 不泄露自己的数据,因此需要隐私保护算法来计算损失函数和梯度。文献[7]中提供了一种新颖的方法,将加性同态加密(HE)应用于神经网络的多方计算(MPC),从而仅需要对神经网络进行最小的修改,并且准确性几乎是无损的,而大多数现有的安全深度学习框架在采用隐私保护技术时会失去一定的准确性。联邦迁移学习的未来工作可能包括采用该方法到其他需要隐私保护数据协作的深度学习系统,并通过使用分布式计算技术继续提高算法的效率,以及寻找成本较低的加密方案。
3.2 基于概率的联邦学习
联邦学习中的每个数据源是隔离的,联邦学习算法在训练每个数据源上的本地模型和将它们提取为全局联邦模型之间进行迭代,而无需显式地组合来自不同数据源的数据。典型的联邦学习算法需要访问本地存储的数据进行学习,更极端的情况是访问本地数据预先训练的模型,而不是数据本身。文献[8]解决的问题是,将根据不同来源的数据独立训练的“遗留”模型组合成一个改进的联邦模型。
文中开发了一个基于概率的联邦学习框架,称为贝叶斯非参数的神经网络联邦学习框架。假设每个数据服务器提供本地神经网络的权重,这些权重通过该框架进行建模。然后使用一种推理方法,合成一个更具表现力的全局网络,这个过程无需额外的监督和数据汇集,而且只需一个通信轮次。假设要么是本地数据,要么是经过本地训练的模型可用。当数据可用时,并行地为每个数据源训练本地模型。然后匹配不同数据源估计的局部模型参数(权重向量)构建全局网络。局部参数的匹配,由贝塔-伯努利过程(BBP)控制。BBP 是一个模型,允许局部参数匹配现有的全局参数,或在现有的全局参数是差的匹配时,创建新的全局参数。
以包含单个隐层的多层感知机为例,假设已经训练出J个多层感知机,分别拥有一个隐层。对于第j个感知机是隐层的权重,是隐层的偏置项,其中D 是数据维度,Lj是隐层神经元的个数。是softmax 层的权重,∈RK是softmax层的偏置项,其中K是类别数目。在拥有J个的情况下,试图学习全局模型,它的参数为其中L是全局模型的隐层神经元个数,由推理得出。
算法的原理如图1 所示,三个本地多层感知机的隐层神经元经过匹配后,形成全局模型。图中的节点表示神经元,相同颜色的神经元已经匹配。
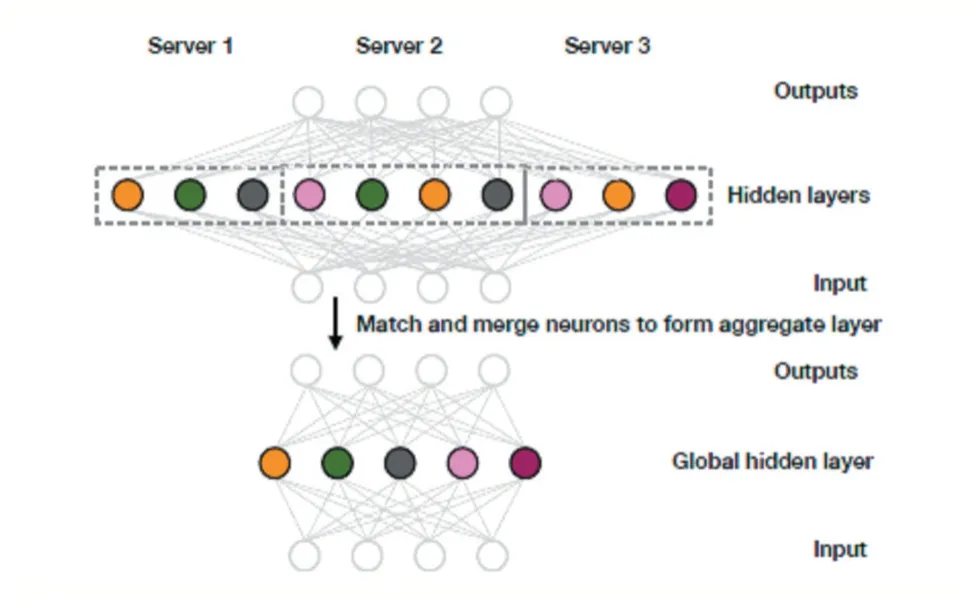
图1 单层概率联邦神经匹配算法原理示意图
文中提出的概率联邦神经匹配(PFNM)算法比现有方法有几个优点。首先,它将局部模型的学习与局部模型合并为全局联邦模型的过程相分离。这种解耦允许我们对局部学习算法保持不可知的态度,局部学习算法可以根据需要进行调整,每个数据源甚至可能使用不同的学习算法。此外,只要给定预先训练的模型,PFNM 就能够将它们组合成一个联邦全局模型,而不需要额外的数据或关于生成预训练模型的算法的知识。而现有的神经网络联邦学习的方法需要关于局部学习的强假设,例如,共享相同的随机初始化,这个假设在很多情况下是不现实的。并且,不同于现有的方法,文中提出的框架本质上是非参数的,允许联邦模型灵活地增大或缩小其复杂性(即神经元的数目),以考虑不同的数据复杂性。
4 联邦学习的相关概念
联邦学习使多方能够协同构建机器学习模型,同时保持其私有训练数据的私有性。联邦学习作为一门新兴的技术,有着许多独创性的思想,其中一些思想植根于现有的领域。下面,我们将从多个角度解释联邦学习与其他相关概念之间的关系。
4.1 隐私保护的机器学习
联邦学习可以看作是一种隐私保护、分散协作的机器学习。过去,许多研究工作都致力于多方、隐私保护的机器学习这一领域。例如,文献[9]的作者提出了用于垂直分区数据的安全多方决策树的算法。Vaidya和Clifton 提出了安全关联挖掘规则[10]、安全K-means[11]和朴素贝叶斯分类器[12]。文献[13]的作者提出了一种基于水平分块数据的关联规则算法。文献[14]的作者提出了多方线性回归和分类的安全协议。文献[15]的作者提出了安全的多方梯度下降方法。这些作品都使用了安全多方计算(SMC)来保证隐私。
4.2 分布式机器学习
联邦学习与分布式机器学习有点相似。分布式机器学习包括很多方面,如训练数据的分布式存储、计算任务的分布式操作、模型结果的分布式分布等。参数服务器[16]是分布式机器学习中的一个典型元素。参数服务器作为一种加速训练过程的工具,将数据存储在分布式工作节点上,通过一个中心调度节点来分配数据和计算资源,从而更有效地训练模型。对于联合学习,工作节点表示数据所有者,对本地数据具有完全的自主权,可以决定何时以及如何加入联邦学习。在参数服务器中,中心节点总是起控制作用。然而,联邦学习面临着一个更加复杂的学习环境。此外,在模型训练过程中,联邦学习强调数据所有者的数据隐私保护。有效的数据隐私保护措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
5 结语
最近,数据的隔离和数据隐私保护成为人工智能面临的下一个挑战,联邦学习给我们带来了新的希望。它可以在保护本地数据的同时,为多个机构建立统一的模型,使多个机构能够在数据安全的基础上协同工作。本文简述了联邦学习的基本定义、提出背景和研究进展,包括联邦迁移学习和基于概率的联邦学习,最后介绍了联邦学习的相关概念。预计在将来,联邦学习将打破行业之间的壁垒,使数据和知识可以安全地共享,并根据每个参与者的贡献公平地分配收益。联邦学习的发展将会促进人工智能应用到我们生活的每个角落。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
科学与财富(2021年35期)2021-05-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
金桥(2018年4期)2018-09-26
电脑爱好者(2018年14期)2018-08-05
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
当代贵州(2014年13期)2014-09-21
