
性能暴增价更香,RTX 30开启光追新纪元!
2020-10-14 22:26
电脑报 2020年37期

GPU发展史上又一次巨大飞跃!安培架构升级亮点看这里


安培架构的SM单元、RT Core和TENSOR Core都进行了巨大升级,算力大幅提升
由于采用了更先进的三星8nm制造工艺,RTX 30系列采用的安培架构得以大幅提升了晶体管数量并优化了效率,同时RT Core升级到了第二代,TENSOR Core也升级到了第三代。从官方数据来看,相对于图灵架构来讲,安培架构的SM单元FP32最高算力提升了大约173%,RT Core最高算力提升了71%左右,TENSOR Core最高算力也提升了约167%,可见其升级幅度是非常巨大的。

RTX 3080相对于RTX 2080 SUPER规格大幅提升
安培架构的SM单元的升级细节包括:翻倍的FP32单元,每个时钟周期可以做到128bit FMA浮点运算;全新的 L1缓存/材质系统,提供双倍的L1缓存带宽和缓存分区尺寸,总容量提升33%;全新的加速核心,包括具備两倍三角形相交速率的第二代RT Core和具备两倍稀疏矩阵计算能力的第三代TENSOR Core。

那么大家最关心的RTX 30系列显卡第二代RT Core除了数量增加之外,性能方面有什么进步呢?其实第二代RT Core在计算光线追踪时,计算三角形相交和时间插值三位置可以同时进行,从而可以实现带光追特效的动态模糊效果。在这个计算过程中,相当于提供了最快8倍的射线穿越计算性能。第三代TENSOR Core方面,虽说RTX 30系列显卡每个SM单元的TENSOR Core数量减少,但它的架构得到了进一步强化,最终的效率反而巨幅提升。例如RTX 2080 SUPER每个SM单元一个时钟周期可以完成512次FP16浮点运算操作,而RTX 3080仅用一半数量的第三代TENSOR Core就能单时钟周期完成512次(密集矩阵)/1024次(稀疏矩阵)FP16浮点运算操作,如此来看,第三代TENSOR Core的性能相对上代大约提升了一倍。也正是因为如此,RTX 30系列显卡的DLSS性能也得到了大幅提升,从而让RTX 3090这样的旗舰显卡可以在8K分辨率下达到非常流畅的帧率。

第二代RT Core能从硬件层面对带光追特效的动态模糊效果进行加速

第三代TENSOR Core提供了更强大的算力且为稀疏深度学习进行了专门的优化
从图中可以看到,安培架构的核心布局采用了新的设计,中间区域是图形芯轨,周围区域则是存储系统芯轨,两块区域分离之后可以获得更优化的芯片利用率与执行效率。在每瓦性能方面,安培架构相对图灵架构更是有了近乎翻倍的提升,这也得益于8nm工艺的使用。温度和噪声方面,从图上也可以看到,安培架构的RTX 30显卡在30db(A)工作噪声下的温度为78℃,图灵架构的RTX 20显卡在32db(A)的噪声下温度为81℃,而前者的游戏帧率几乎比后者高出一倍。

安培架构的每瓦性能约为图灵架构的1.9倍,能效比几乎翻倍
这一次安培架构的RTX 3090/3080显卡还有一个巨大的升级,那就是采用了与美光合作开发的GDDR6X显存,由于GDDR6X显存采用了PAM4信号编码,也就是每个周期利用4个电平信号进行数据传输,相比GDDR6的两个电平信号自然效率大增。

RTX 30系列显卡采用全球最快的GDDR6X显存,速率为GDDR6的两倍
视频方面,RTX 30系列显卡这次率先提供了对HDMI 2.1接口的支持,可以实现单数据线8K/60Hz或者4K/120Hz的HDR画面输出。当然,这一方面也是因为RTX 3090这样的旗舰显卡已经可以在多数3A游戏大作中达到8K/60fps流畅标准,既然性能方面有这个实力,那么输出接口配套升级也顺利成章了,这也意味着8K真的离我们越来越近了。此外,RTX 30系列也是全球首批支持AV1硬件解码的显卡,可以流畅解码8K/60fps视频,这不但为发烧友提供了顶级的视频体验,同时也能大大提升创意工作者们剪辑视频的效率。

RTX 30系列显卡支持HDMI 2.1接口,可实现单数据线输出8K/60Hz HDR视频信号,同时还提供了对AV1的硬件解码加速,支持8K/60fps视频实时解码
其实除了制造工艺、架构和硬件规格上的升级,安培架构的RTX 30显卡还有大量的黑科技可以提升玩家的使用体验,下面请看详细介绍。
不光是硬件规格提升,RTX 30显卡黑科技一样爆棚
1.NVIDIA REFLEX低延迟技术

NVIDIA REFLEX低延迟技术旨在为电竞玩家提供更低的画面与操作延迟,提供更加快速而顺滑的电竞对战体验

启用REFLEX技术的情况下,主流电竞游戏的系统延迟时间都得到了明显降低

RTX 3080在开启硬件光追+DLSS+Async的情况下,响应速度是RTX 2080的1.9倍

新版GFE中集成了性能工具,可自动优化系统降低延迟,也可以实时监测系统状态
相信大家对于NVIDIA“帧能赢”的概念非常熟悉,而这一次的REFLEX技术更加强大。我们知道,从电竞玩家按下键鼠到最终反应在显示器画面上这个过程要经历输入设备、处理器、游戏引擎渲染队列、GPU、显示器几个步骤,这中间每一个步骤之间都会产生延迟,如果延迟时间太长,就会导致玩家的操作严重滞后甚至是画面卡顿,对战中自然就处于劣势。因此,NVIDIA推出了REFLEX低延迟技术,通过将渲染队列的延迟时间降低为0、大幅降低处理器负担、提升GPU频率来降低整个系统的延迟,让玩家的操作更加快捷、顺滑。之所以能做到这一点,与RTX 30显卡的Shader单元、RT Core、TENSOR Core同时加速可以提供极高的运算能力不无关系,从统计数据来看,RTX 3080在开启硬件光追+DLSS+Async的情况下,响应速度是RTX 2080的1.9倍之多!当然,REFLEX低延迟技术绝非只包括RTX 30显卡,这次NVIDIA还宣布了支持360Hz刷新率的G-Sync电竞显示器(首发品牌有华硕、宏碁、外星人和微星),而且这些显示器中还首次集成了可监测延迟的REFLEX硬件模块(外设通过显示器上的USB接口与REFLEX模块通信)。除此外,也宣布了数款来自华硕、罗技、雷蛇和赛睿支持REFLEX技术的电竞鼠标。新版GFE中也提供了性能工具,可自动优化系统降低延迟,也可以实时监测系统状态,甚至还能录制8K/30fps HDR视频!总而言之,NVIDIA REFLEX低延迟技术其实是一套完整的解决方案,可以有效提升玩家的电竞对战操作体验,提升胜率。
2.RTX IO快速載入技术

RTX IO技术可直接将压缩数据读取到显存,CPU占用率降低20倍、载入速度相较HDD提升百倍
现在的3A游戏大作体积越来越大,未来超过200GB也是很正常的事,那么在玩游戏的时候,需要载入的游戏数据也变得越来越多,游戏加载时间也变得更长。为了解决这个问题,游戏开发团队采用了压缩数据的方法,不过,虽说使用压缩数据可以有效加快游戏载入的速度,但是需要占用大量CPU资源来进行解压缩,同时增加了数据通过CPU与系统内存的步骤,从而增加了延迟。特别是当升级到读取速度高达7000MB/s的PCIe 4.0固态硬盘后,这个数据解压的操作就需要占用更多的CPU核心数了。因此,NVIDIA推出了RTX IO技术,通过这项技术,就能让GPU来处理数据解压,从而大幅度降低CPU的占用率。从图上可以看到,在PCIe 4.0固态硬盘上达到同样读取速度的时候,如果采用传统的方式,会占用24个CPU核心(如果CPU核心数量不够,就会造成瓶颈,达不到PCIe 4.0固态硬盘的速度上限),而采用RTX IO技术后,只需要占用0.5个CPU核心。当然,除了游戏外,在需要载入大量素材文件的3D渲染工作中也可以通过RTX IO来提升效率、降低CPU占用率,从而获得更流畅的体验。要享受这项技术,需要游戏支持微软的DirectStorage API,当然也需要RTX 30系列显卡。
3.基于RTX 30系列显卡的NVIDIA STUDIO

RTX 30系列显卡的高超算力为内容创作提供了强大的动力

部分测试项目中,RTX 3080的3D渲染加速性能超过了RTX 2080 SUPER的两倍

在渲染动态模糊画面方面,RTX 3080的性能约为RTX 2080 SUPER的5倍
对于内容创意设计用户,NVIDIA推出了NVIDIA STUDIO解决方案,新一代的RTX 30系列显卡更是将NVIDIA STUDIO的效能提升到了新的高度。从官方提供的数据来看,RTX 3080在各种主流渲染器中的加速性能都远超RTX 2080 SUPER,在LUXMARK和V-Ray中甚至超过了RTX 2080 SUPER的两倍。视频剪辑部分,RTX 3080也表现出了惊人的性能,达文西测试中的成绩远远领先RTX 2080 SUPER,甚至有些项目非常接近RTX 2080 SUPER的2.5倍性能。此外,我们知道很多复杂3D建模与高码率8K视频剪辑是非常吃显存的,而RTX 3090具备的24GB超大显存无疑是针对这些应用而来,为设计师用户提供更高效的解决方案。总而言之,基于RTX 30系列显卡的NVIDIA STUDIO套装无疑能为内容创意设计用户提供效率远超上代产品的解决方案。
4.NVIDIA OMNIVERSE MACHINIMA

RTX 3090高达24GB的显存可以轻松应对高细节几何建模、多应用3D渲染动画、8K RED EAW的AI剪辑等高运算量专业应用

在达芬奇视频剪辑中,RTX 3080的效率甚至超过了RTX 2080 SUPER的两倍
由于图形技术的飞速发展,现在游戏技术已经被广泛应用在电影制作过程之中,而NVIDIA OMNIVERSE MACHINIMA就是基于RTX 30系列GPU强大计算能力打造的游戏叙事APP,也就是能够让玩家利用现有的游戏素材,通过RTX 30显卡AI技术制作出电影级的视频!NVIDIA OMNIVERSE MACHINIMA可以从支持该技术的游戏中获取素材、工具,然后通过赋予材质、Audio2Face(声音转表情)、增加物理效果、AI采集动作,最后使用RTX光线追踪渲染从而制造出堪比电影画质的视频。

通過NVIDIA OMNIVERSE MACHINIMA可以让用户使用游戏素材打造电影级视频
得益于RTX 30系列显卡强大的视频加速和AI计算能力,玩家可以轻松打造家庭工作室
5.NVIDIA BROADCAST
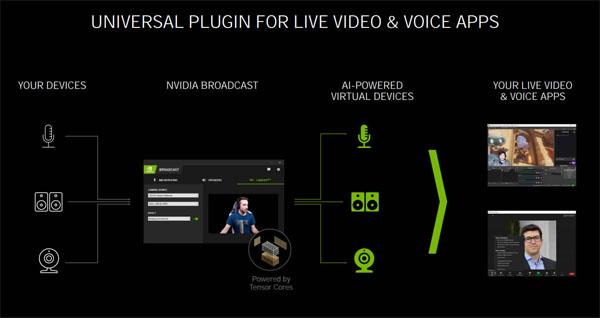
NVIDIA BROADCAST工具旨在为玩家提供强大的直播应用解决方案,它主要包括了音频降噪(降低录音的环境噪声)、虚拟背景(通过AI抠出人像,并提供各种直播时需要的虚拟背景)、摄像头自动构图(可以保证改变动态视频图像比例时,自动将目标位于视觉中央)等实用功能。从图上可以看到,麦克风、音箱(或耳机)、摄像头等设备连接到电脑后,通过NVIDIA BROADCAST工具可以被AI技术强化形成虚拟设备,从而获得各种强大的功能。
好了,有关安培架构RTX 30系列显卡的主要技术亮点讲解就到这里,接下来就让我们来看看来自NVIDIA官方的Founders Edition版RTX 3080显卡实物吧!
猜你喜欢
科学大观园(2022年6期)2022-04-21
内燃机与配件(2022年2期)2022-01-17
产城(2021年11期)2021-12-09
中兴通讯技术(2021年3期)2021-11-28
软件和集成电路(2019年9期)2019-11-29
学生天地·小学低年级版(2018年3期)2018-05-17
小学科学(2015年8期)2015-09-06
小学科学(2015年7期)2015-07-29
中国总会计师(2015年5期)2015-06-16
中国信息化周报(2014年41期)2014-11-07
