
时间序列预测与深度学习:文献综述与应用实例
2020-10-15 12:14杜守国
计算机应用与软件 2020年10期
李 文 邓 升 段 妍 杜守国
1(上海对外经贸大学统计与信息学院 上海 201620) 2(上海市人力资源和社会保障局信息中心 上海 200051)
0 引 言
时间序列预测旨在基于给定的时间序列观测值估计未来时间点上的取值或概率分布,这是风险管理和决策的关键任务,它在许多领域中发挥了重要作用,包括统计学、机器学习、数据挖掘、计量经济学、运筹学等。例如,预测产品的供需可用于优化库存管理、车辆调度和拓扑规划,这对于供应链优化的大多数方面都至关重要[1-2]。
传统的时间序列预测模型包括ARIMA模型、指数平滑方法和状态空间模型(SSM)等,其中ARIMA模型、指数平滑方法都可以表示成状态空间模型的形式,SSM提供了时间序列建模的通用框架,由状态方程和观察值方程组成[2]。
在现代预测应用中,传统的SSM模型无法从相似的时间序列数据集合中推断出共享模式,这就产生了繁重的计算任务和大量人力劳动需求。因此,深度神经网络(Deep Neural Networks,DNN)凭借其提取高阶特质的能力走进了人们的视野。通过深度神经网络,可以识别时间序列内部和时间序列之间的复杂模式,并且能够从原始时间序列的数据集合中进行识别,所需的人力要少得多。然而,由于这些模型所作的结构假设较少,它们通常需要更大的训练数据集来学习得到准确的模型[2]。
为了弥补这两种方法各自的不足,将传统统计模型与深度学习融合,产生了一些新的预测方法。Chung等[3]和Fraccaro等[4]使用循环神经网络(Recurrent Neural Networks,RNN)在SSMs和变分自编码器(Variational Auto Encoding,VAE)之间建立联系。Krishnan等[5]利用深度卡尔曼滤波器(Deep Kalman Filters,DKF)在SSM中引入外生变量。在预测方面,Rangapuram等[2]使用RNN在每个时间步上生成线性高斯状态空间模型(LGSSM)的参数,提出了深度状态空间模型(Deep State Space Model,DSSM)。对于非线性SSM,Eleftheriadis等[6]提出非线性高斯过程状态空间模型(Gaussian Process State Space Model, GPSSM)。Salinas等[7]研究了多元时间序列预测问题。Salinas等[8]的深度自回归模型(DeepAR)是建立在对时间序列数据进行深度学习的基础上,为概率预测问题设计了一个类似的基于LSTM(Long Short-Term Memory)的自回归RNN架构。而Vaswani等[9]提出的Transformer利用Attention Mechanism来处理数据。与基于RNN的方法不同,Transformer允许模型访问历史的任何部分,而不考虑距离,这使得它更适合于捕捉具有长期依赖性的循环结构。
徐超等[10]提出一种集成自回归综合移动平均(ARIMA)模型与自适应过滤法的组合预测模型。该组合强调ARIMA模型对时间序列数据特征识别与参数估计的优势,同时引入自适应过滤法的“权数”调整思想,对ARIMA模型的参数进行调整,以减少预测误差,提高预测精度。沈旭东[11]对近年来基于深度学习的时间序列分析方法进行讨论,从应用、网络架构、思想等方面总结了最新的时间序列预测、分类、异常检测等任务的深度学习方法,为了解时间序列深度学习解决方案的技术和发展趋势提供了参考。吴双双[12]利用卷积神经网络、循环神经网络、双通道神经网络对数据进行了预测,并取得了不错的预测效果。权钲杰[13]利用长短期记忆网络和卷积神经网络对数据进行预测,并针对深度神经网络模型训练不稳定的问题,研究了将集成学习方法应用于对深度神经网络预测模型的改进,提出了基于噪声扰动集成方法的深度神经网络集成模型。刘峰等[14]提出了一种组合聚类分析和神经网络的预测方法。王慧健等[15]提出一种新的时间序列短期趋势预测方法,通过对时序数据进行离散化,用字符表示各个时间段数据的范围,并利用神经网络语言模型预测得到下一个字符。李洁等[16]基于真实的民航旅客历史出行记录,根据其时序数据的特征建立基于后向传播算法的循环神经网络(RNN)预测模型,对未来时段的日客流量进行预测。在此基础上考虑到时序数据在不同时间尺度呈现不同的变化规律,建立多时间尺度的预测模型对旅客出行的周期性和趋势性进行建模,提升预测精度。蒋倩仪[17]根据震荡盒理论提出一种新的适应于与机器学习相结合的交易边界模型,通过结合基于距离的多核极限学习机(DBMK-ELM)与交易边界模型,构建基于时间序列预测的股票交易决策建议系统,使得在股票交易中能稳定获得较高的收益率并保持较低的投资风险。
本文旨在介绍近年来提出的与深度学习相结合的时间序列预测方法。本文介绍三种时间序列预测模型:深度状态空间模型(DSSM)、深度自回归模型(DeepAR)、Transformer模型(Transformer),并运用上海市出口额数据的预测实例说明它们的应用效果。实验结果表明,基于深度学习的时间序列预测效果明显优于传统的ARIMA模型。
1 时间序列预测问题
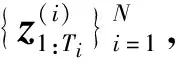
(1)

2 时间序列模型
2.1 深度状态空间模型(DSSM)
传统的SSM模型利用时间序列的潜在状态lt∈RL对数据结构进行建模,该状态可用于编制时间序列的组成部分(如水平、趋势和季节性构成),并通常应用于单个时间序列的预测。一般的SSM包含了定义潜在状态随时间演变的随机转移概率p(lt|lt-1)的状态转移模型,以及给定潜在状态的观测条件概率p(zt|lt)的观测模型。
状态转移方程的形式为:
lt=Ftlt-1+gtεt
(2)
式中:εt~N(0,1);在时间t潜在状态lt-1代表关于水平、趋势以及季节性因素的信息,通过确定的转移矩阵Ft和随机创新gtεt进行递归计算;转移矩阵Ft和创新强度gt确定了由潜在状态lt编制的时间序列构成。
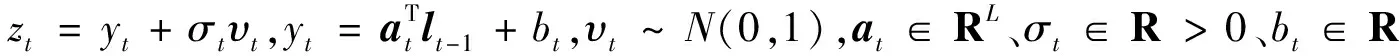
状态空间模型完全由参数指定Θt=(μ0,Σ0,Ft,gt,at,bt,σt),∀t>0,并假定为时不变的,即Θt=Θ,∀t>0。通用的估计方法是最大边际似然估计,即:
(3)


(4)

(5)


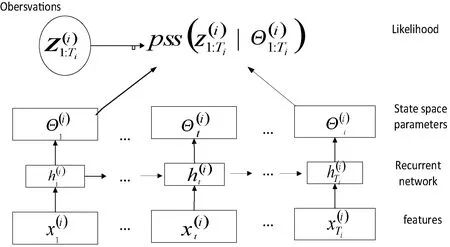
图1 状态空间模型的框架
(6)

(7)
通过训练参数Φ得到极大似然估计后,就可以对每个给定的时间序列进行概率预测。给定Φ可以计算每个时间序列在预测范围内的联合分布,该联合分布是多元高斯分布。在实践中用K个蒙特卡洛样本来表示预测分布通常更为方便,公式为:

k=1,2,…,K
(8)
为了从状态空间模型生成预测样本,从样本lT~p(lT|z1:T)开始,递归地应用:
t=1,2,…,τ
lT+t~FT+tlT+t-1+gT+tεT+tεT+t~N(0,1)
t=1,2,…,τ-1
在DSSM中,与经典的SSM和基于深度学习的自回归模型(如DeepAR)相比,目标值并没有直接用作输入,这就带来了几个优点。首先,目标值只是适当考虑噪声的似然项的合并,故模型对噪声更为鲁棒;然后,简单地删除相应的似然项,就可以很容易地处理丢失的目标值;最后,生成预测样本路径的计算效率也更高,因为整个预测过程中RNN只需要展开一次(与样本数无关)。
2.2 深度自回归模型(DeepAR)
DeepAR由一个RNN(使用LSTM或GRU单元)组成,该RNN以序列滞后值和协变量作为输入,训练和预测遵循自回归模型的一般方法。
与传统模型不同的是,DeepAR不仅将最后的目标值作为输入,而且还将一些滞后项作为输入。例如,对于小时数据,滞后可能是1(前一小时)、1×24(前一天)、2×24(前两天)、7×24(前一周)等。
用zi,t表示时间序列i在时间t的值,在给定过去{zi,1,zi,2,…,zi,t0-2,zi,t0-1}:=zi,t0-1的前提下,建立未来每个时间序列{zi,t0,zi,t0+1,…,zi,T}:=zi,t0:T的条件概率分布:
p(zi,t0:T|zi,1:t0-1,xi,1:T)
式中:t0表示预测开始的时间点;xi,1:T为在所有时间点都已知的协变量。
假设模型分布p(zi,t0:T|zi,1:t0-1,xi,1:T)由似然因子的乘积组成(无边界条件):
(9)
由输出hi,t参数化的自回归递归网络,hi,t=h(hi,t-1,zi,t-1,xi,t,Θ),其中h是由具有LSTM单元的多层递归神经网络实现的函数。该模型是自回归的,最后时刻的观测值zi,t-1以及递归网络的先前输出hi,t-1都会作为下一时刻的输入。似然函数l(zi,t|θ(hi,t,Θ))是一个固定分布,其参数由网络输出hi,t的函数θ(hi,t,Θ)给出。
zi,1:t0-1中的观测值信息通过初始状态hi,t0-1传递到预测范围。在sequence-to-sequence的设置中,此初始状态是编码器网络的输出。一般来说,这个编码器网络可以有不同的结构,在这里选择在条件区间和预测区间(对应于sequence-to-sequence模型中的编码器和解码器)中对模型使用相同的结构。此外,它们之间共享权重,以便计算t=1,2,…,t0-1时解码器的初始状态hi,t0-1。编码器hi,0以及zi,0的初始状态初始化为零。


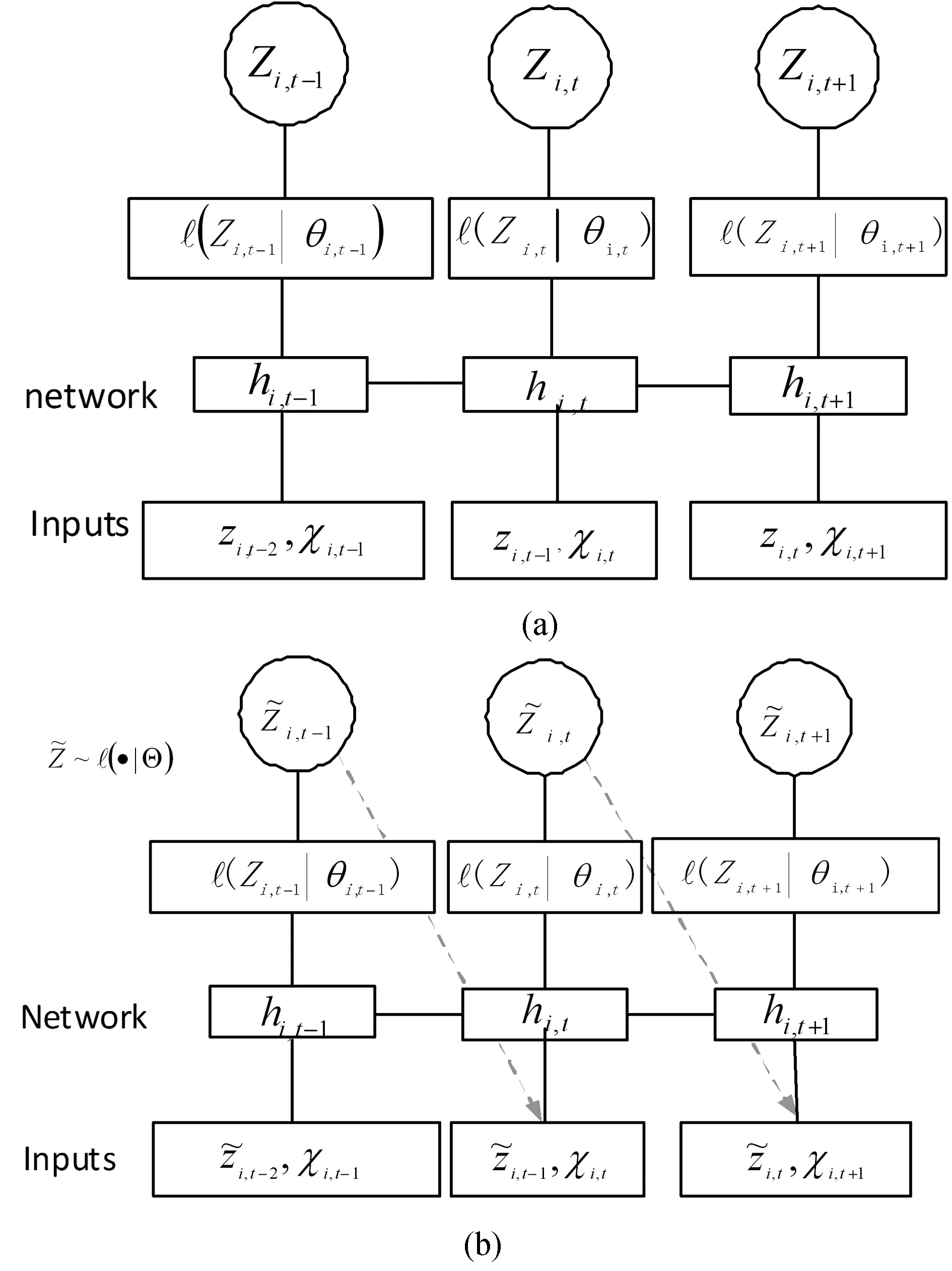
图2 DeepAR模型摘要
2.3 Transformer 模型
Transformer完全基于Attention Mechanisms,而不需要递归和卷积。递归模型通常沿输入和输出序列的符号位置进行因子计算。将位置与计算的时间步对齐,生成隐藏状态ht的序列,作为先前隐藏状态ht-1和位置t的输入函数。这种固有的序列性质使得训练无法并行化,而在较长的序列研究中,因为内存约束限制,并行化至关重要。Transformer完全依赖于Attention Mechanisms来绘制输入和输出之间的全局依赖关系,允许更显著的并行化[18]。
时间序列概率预测的目标是建立以下条件概率分布:
p(zi,t0+1:t0+τ|zi,1:t0,xi,1:t0+τ;Φ)=
(10)
具体预测过程中将此问题简化为学习一步预测模型p(zt|z1:t-1,x1:t;Φ),其中Φ表示由所有时间序列集合共享的可学习参数。为了充分利用观测值和外生变量,将它们连接起来得到一个增广矩阵(无边界条件)
yt[zt-1∘xt]∈Rd+1,Yt=[y1,y2,…,yt]T∈Rt×(d+1)
式中:∘ 代表两个向量的拼接。观测值和外生变量作为整体输入变量,探讨一个合适的zt~f(Yt)模型来预测给定Yt条件下zt的概率分布。
利用multi-head self-attention机制,用Transformer实例化f,因为self-attention使Transformer能够捕获长期和短期依赖,并且不同的attention heads学习时间模型的不同方面。这些优点使Transformer成为时间序列预测的一个很好的预选方法。
图3为Transformer模型概述。大多数竞争性神经序列转导模型都具有编码器-解码器结构。这里,编码器将由符号表示的输入序列(x1,x2,…,xn)映射到连续表示的序列z=(z1,z2,…,zn)。给定z,解码器一次生成一个符号的输出序列(y1,y2,…,yn)。每一步,模型都是自回归的,在生成下一步时,将先前生成的符号作为附加输入。Transformer遵循这个总体架构,使用堆叠的self-attention和point-wise作为编码器和解码器完全连接层,如图3所示。

图3 Transformer模型摘要
其中attention函数可以描述为将query和一组键值对映射到输出,query、键、值和输出都是向量。输出是值的加权和,分配给每个值的权重由query的兼容函数和相应的键计算得出。
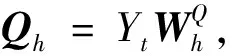
Oh=Attention(Qh,Kh,Vh)=
(11)
为了避免将来的信息泄漏,使用mask矩阵M通过将所有上三角元素设置为-∞来过滤rightward attention。之后,O1,O2,…,OH被串联起来,再次线性投影。在attention输出端,叠加一个位置前馈子层,该子层具有两层完全连接的网络,中间有一个ReLU激活[19]。
3 实证分析
3.1 研究背景
2018年3月,美国使用“232措施”对进口钢、铝产品分别加征25%和10%关税。2018年6月,美国贸易代表办公室公布修订版的“301”对华加征25%关税的产品清单,并在2018年7月和8月分两批对从中国进口的500亿美元商品加征25%关税,涉及的行业主要有通用设备、电气机械、专用设备、通信电子设备、仪器仪表等5个设备制造业,其余为橡胶和塑料制品业、金属制品业等行业。2018年9月又对2 000亿中国输美产品征收10%的关税(《关于中美经贸摩擦的事实与中方立场》白皮书2018)。为了了解中美贸易摩擦对上海市出口贸易的影响,利用深度学习方法预测上海市出口额数据,探究在中美贸易摩擦不断升温背景下上海市出口额的变化发展规律。
3.2 数 据
本文使用的数据来自“上海海关数据库”(http://shanghai.customs.gov.cn),数据集是上海市总出口额和上海市对美国市场的出口额数据,该数据集一共有72个时间点的数据,涵盖了从2014年1月份开始到2019年12月结束的每个月上海市总出口额和上海市对美国市场的出口贸易额信息。每个时间点以月为单位,出口额的单位是亿元人民币。图4和图5分别为上海市总出口额和上海市对美国市场出口额的时序图。

图4 上海市总出口额

图5 上海市对美国市场出口额
可以看出,上海市总出口额和上海市对美国市场的出口额两者存在相似的趋势,并且时序图的走势存在一定的周期性规律,在每年年初和年末的时候会出现下降的趋势,而年中大部分时间存在上升的趋势。
3.3 计量方法
本文采用五种模型对上海市总出口额和上海市对美国市场的出口额作预测,分别是自回归求和移动平均模型(ARIMA)[20]、条件时序卷积模型(Wavenet)[21]、深度状态空间模型(DSSM)、深度自回归模型(DeepAR)和Transformer模型(Transformer),并对五种模型的预测效果进行比较。用连续分级概率评分(CRPS)对模型的预测效果进行评价。
连续分级概率评分(Continuous Ranked Probability Score,CRPS)或“连续概率排位分数”是一个函数或统计量,可以度量概率分布F(由分位数函数F-1表示)与观测值z的相容性[22]。CRPS可视为平均绝对误差(Mean Absolute Error, MAE)在连续概率分布上的推广。CRPS可以作为概率模型的损失函数和评价函数,应用于概率天气预报、误差分析、异常值检测(Anomaly Detection)等现实问题。作为评价函数时,按CRPS评价概率模型所得的(优劣)结果与按MAE评价概率模型的数学期望所得的结果等价。
在分位数水平为α∈[0,1]且预测的第α分位数为q的条件下,pinball损失(或分位数损失)定义为:
Λα(q,z)=(α-I(z (12) 式中:z是观测值;I(z (13) CRPS作为一个适用的评分规则[22],意味着当预测分布等于从实际数据中得出的分布时,CRPS值最小。CRPS值越小,说明预测分布与观测值分布相近,预测性能越好。 本文使用GluonTS时间序列预测框架进行预测(http://gluon-ts.mxnet.io/index.html),GluonTS是亚马逊推出的一种使用 Gluon API 的 MXNet 时间序列分析工具包。 利用以上五种模型对上海市每月贸易总出口额(TS1)和上海市每月对美国市场的贸易出口额(TS2)进行预测和预测效果评估,样本数据区间是2014年1月到2019年12月,训练期是2014年1月到2018年12月,测试期是2019年1月到2019年12月。表1给出五种预测模型CRPS值,可以看出,深度状态空间模型(DSSM)、深度自回归模型(DeepAR)和Tansformer模型的预测CRPS值相对较小,表明这三种方法预测效果较好,并且预测效果都明显优于传统的自回归求和移动平均模型(ARIMA),其中Transformer模型的预测效果是相对最优。图6和图7是Transformer模型的预测效果图。 表1 五种模型预测CRPS值 图6 利用Transformer模型预测上海市总出口额 图7 利用Transformer模型预测出口市场为美国的上海市出口额 尽管传统的统计建模方法将结构假设合并到模型中,使得模型易于解释,但是在现代预测应用中,传统统计模型对时间序列单独建模,这就需要大量的劳动和计算成本。深度学习方法恰好可以识别时间序列内部和时间序列之间的复杂模式,所需的人力要少得多,但是这些模型所做的结构假设较少,很难解释,通常需要更大的训练数据集来学习得到准确的模型。由此产生了将传统统计模型与深度学习融合的一些新的预测方法,这些方法较好地克服两方面的不足。它们既允许模型自动提取特征并学习复杂的时间模式,同时也可以实施和利用时间平滑等假设,使模型可解释。本文在综述时间序列预测与深度学习文献的基础上,重点介绍三种与深度学习相结合的时间序列预测模型,并利用这些模型预测中美贸易摩擦背景下的上海市出口额数据。实验结果表明,相比于传统的时间序列预测方法(ARIMA模型),基于深度学习的时间序列预测方法的预测CRPS值显著降低,预测效果更优。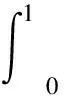
3.4 实证结果



4 结 语
猜你喜欢
——2022年1-6月上海节能(2022年9期)2022-09-30舰船科学技术(2022年11期)2022-07-15煤气与热力(2022年2期)2022-03-09北京航空航天大学学报(2021年4期)2021-11-24中小学校长(2021年7期)2021-08-21学生导报·初中版(2020年1期)2020-05-03电子制作(2019年24期)2019-02-23世界热带农业信息(2014年6期)2014-09-12世界热带农业信息(2014年5期)2014-08-06
