
基于YOLOv3的轻量级目标检测网络
2020-10-15 11:01贾瑞生徐志峰毛其超
计算机应用与软件 2020年10期
齐 榕 贾瑞生 徐志峰 毛其超
(山东科技大学计算机科学与工程学院 山东 青岛 266590) (山东科技大学山东省智慧矿山信息技术省级重点实验室 山东 青岛 266590)
0 引 言
目标检测是计算机视觉领域的一个经典的任务,是进行场景内容分析和理解等高级视觉任务的基本前提[1-2]。目标检测领域传统的方法是使用简单的手工特征和级联分类器级联进行检测。然而,这类检测器的性能在现实应用中会随着视觉多样性变化而显著降低。Felzenszwalb等[3]在2008年提出基于 HOG的变形组件模型(Deformable Part Model,DPM)检测算法,利用 SVM 作为分类器,使用少量未完全标注的样本即可取得较好的检测效果,但计算量太大,特征需要人为设置,且模型无法适应大幅度的旋转,稳定性很差。
近年来,基于深度学习的目标检测算法取得突破,逐渐取代传统算法成为目标检测算法的主流[4-6]。基于深度学习的算法主要分为两类。第一类是基于区域的目标检测算法,该类算法对物体进行两步检测,首先生成候选区域,然后对候选区域进行分类与回归。这类算法最经典的框架为Girshick等[7]提出的R-CNN框架;He等[8]在R-CNN框架中加入空间金字塔池化提出SPP算法;Girshick[9]为解决R-CNN进行特征提取时大量重复运算提出了Fast R-CNN;Ren等[10]通过构建区域建议网络生成候选框提出了Faster R-CNN;Mask R-CNN[11]使用RoIAlign代替RoIPooling,并在Faster R-CNN基础上加上mask分支,增加相应loss,取得了更好的分类效果;Cascade R-CNN[12]通过级联检测网络并基于不同的IOU阈值进行检测。第二类算法是基于回归的目标检测算法,这类算法为单阶段检测算法,不需要生成候选区域,直接预测物体的类别概率和位置坐标,最典型的为YOLO系列和SSD系列。YOLOv1[13]使用单个网络进行检测,大大提升了目标检测算法的速度,有很强的泛化能力;YOLOv2[14]引入FastR-CNN[12]的anchor box思想同时使用K-Means聚类方法产生anchor;YOLOv3[15]使用多标签分类和跨尺度预测的方法,将YOLOv2的特征提取网络Darknet-19增加为Darknet-53提升网络的检测精度。SSD[16]将YOLO的回归思想和Faster R-CNN的anchor box机制结合;Fu等[17]提出DSSD将SSD算法基础网络从VGG-16更改为ResNet-101,增强网络特征提取能力;FSSD[18]借鉴了FPN[19]的思想,重构了一组pyramid feature map,使得算法的精度有了明显的提升。
在实际应用中,尽管网络可以在服务器等大型计算机上达到实时检测目标的效果,但是当将网络结构移植到手机等嵌入式设备时却难以达到该效果,因为嵌入式设备的处理器性能远不如服务器等。Tiny-YOLO的出现一定程度上解决了该问题,它将主干网络的层数大幅度减少,使模型的结构和参数数量减少,但网络的检测精度也随之下降,难以在检测精度与实时性两者间取得较好的平衡。因此提出一种模型结构小、目标检测效果稳定的轻量级网络,将Tiny-YOLO的主干网络替换为MobileNet[20],将模型移植到嵌入式平台时满足嵌入式平台的计算能力,模型使用深度可分离卷积代替传统卷积,使模型的参数数量更少,模型更小,同时采用多个点卷积来增加网络的深度,使模型的检测精度与检测速度都得到提升。
1 相关理论基础
1.1 Tiny-YOLOv3算法原理
YOLO系列是Redmon等提出的通用目标检测算法,Tiny-YOLOv3是YOLOv3的轻量化网络,它将YOLOv3的特征提取网络Darknet-53缩减为一个7层的卷积神经网络,并取消网络中的全连接层,采用维度聚类生成先验框和多尺度预测的技术提高检测精度,模型结构简单,参数数量和计算量较少,检测速度更快。Tiny-YOLOv3的流程图如图1所示。

图1 Tiny-YOLOv3检测流程示意图
具体检测流程如下:
Step1输入图片,将图片进行图像预处理缩放至416×416大小。
Step2将输入图片划分为13×13、26×26两个尺度的网格单元,如果ground truth中某个物体的中心点落在网络单元中,就由这个网格单元预测该物体。
Step3每个网格单元通过K-Means聚类方法生成3个先验框,2个尺度共生成6个先验框。
Step4将处理后的图片输入网络进行特征提取,模型首先在13×13小尺度上预测输出特征。
Step5将13×13小尺度的输出特征进行一次1×1卷积和2倍上采样后进行拼接,在26×26中尺度进行预测输出特征。
Step6将两个尺度预测输出的特征进行融合,设定阈值过滤掉低于阈值的边界框,将剩余的边界框进行非极大值抑制得到最终的目标检测结果。
1.2 Mobilenet网络
Mobilenet[20]是为移动和嵌入式设备提出的一种轻量级神经网络,主要基于深度可分离卷积思想。深度可分离卷积是网络模型小型化的一种方式,它的本质是将标准卷积分解为两个步骤:(1)逐通道的卷积Depthwise,一个卷积核对应一个通道,一个通道只被一个卷积核提取特征;(2)点卷积Pointwise,使用N个1×1的卷积核,将第一步得到的特征图再串联起来,维持特征的完整性。这种结构可以在减少输出通道的同时实现跨通道的信息整合,在减少参数量的同时保持算法性能不下降[21]。标准卷积和深度可分离卷积如图2所示。
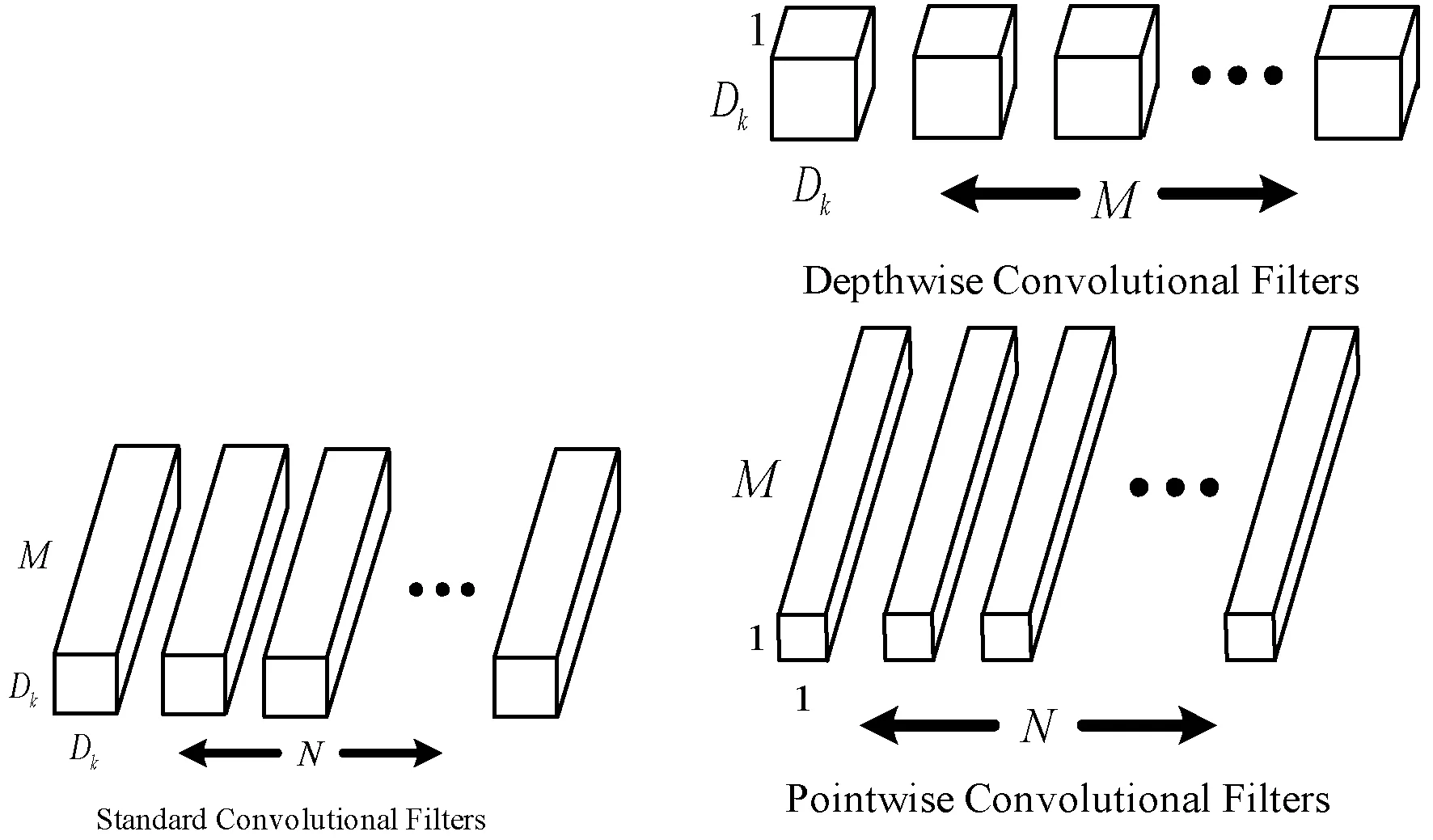
图2 标准卷积和深度可分离卷积
深度可分离卷积与传统卷积的参数数量比值为:
(1)
式中:Dk为卷积核尺寸;M为输入通道;N为输出通道。由式(1)可知,在卷积网络模型中使用深度可分离卷积层代替标准卷积层,对同一个图像进行卷积操作得到相同维度的图像特征所需要的计算量大幅度降低。
2 目标检测算法设计
2.1 目标检测模型
Tiny-YOLOv3是YOLOv3[15]的简化版本,可以在手机移动和嵌入式设备上运行,但检测精度较低,原因是特征提取网络层数较少,不能提取出更高层次的语义特征。因此Mobilenet-YOLOv3将Tiny-YOLOv3的特征提取网络替换为Moblienet[20],并将模型结构进行修改,增加网络层数提高检测精度。将Tiny-YOLOv3的双尺度预测变为三尺度预测,更好地检测类型不同的物体,提高检测精度。改进后的网络结构如图3所示。

图3 改进后的网络结构图
Moblienet-YOLOv3的特征提取网络使用14个3×3个卷积核提取复杂背景下的物体信息,其中5层卷积的步长为2,对图像进行下采样代替YOLOv2中的池化层;10个1×1的卷积核进行跨通道的信息整合。最终特征图变为原图的1/32,图像每进行一次卷积步长为2的下采样操作,特征图的通道数就增加一倍来充分利用特征图的信息。
Moblienet-YOLOv3的检测网络借鉴了FPN多个scale特征融合的思想,采用13×13、26×26、52×52三尺度的特征图对不同大小的目标进行检测,可以加强对小目标的检测精度。网络在第34层进行32倍下采样的检测,然后进行一次点卷积和2倍上采样与23层的特征进行特征拼接,在46层进行16倍下采样的检测。最后进行一次点卷积和2倍上采样在58层进行8倍下采样的检测。进行特征拼接的原因是网络同时学习深层特征与浅层特征,表达效果更好。图3中,“Conv dw”表示深度可分离卷积;“Convolutional”表示Conv2d+BN+LeakyReLU;“Detection Set”是Convoltional1×1、Convoltional3×3、Convoltional1×1、Convoltional3×3、Convoltional1×1的组合检测块。
Moblienet-YOLOv3同样使用了K-Means聚类来生成先验框,设置先验框的主要目的是使预测框与ground truth的IOU更好。13×13的特征图感受野最大,因此先验框的尺寸也最大,尺寸为(116×90)、(156×198)、(373×326),26×26的特征图先验框尺寸为(30×61)、(62×45)、(59×119),52×52的特征图先验框尺寸为(10×13)、(16×30)、(33×23)。每个网格预测3个边界框,在训练模型时,如果物体的中心点落在该网格内,则只选择与真实边框IOU重叠度最大的边界框进行预测,舍弃其他IOU值较小的边界框,这样可以提高模型对小目标的检测能力,使单元网格的边界框提高泛化能力。每个边界框输出目标边框的中心点坐标(x,y),高度h,宽度w和边框的置信度5个参数,置信度的计算公式为:
(2)
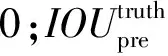
(3)
式中:Classi为种类;Pr(Classi|object)为预测框中存在物体时,该物体属于某一类的概率;i=1,2,…,I,I为检测的类别数,在COCO数据集中I为80,在PASCAL VOC数据集中I为20。通过设定阈值, 过滤掉置信度低于阈值的边界框, 并对类别置信度高于阈值的边界框进行非极大值抑制后得到最终的边界框。
2.2 损失函数
本文的损失函数分为三部分,分别为边界框坐标误差、边界框置信度误差、分类误差。损失函数计算公式为:
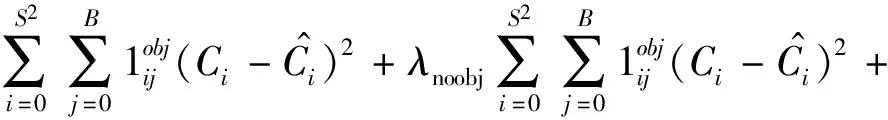
(4)
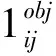
3 实 验
3.1 实验数据及环境
实验使用的数据集是PASCAL VOC数据集和COCO数据集。PASCAL VOC数据集是评估图像分类和目标检测的基准数据集,这些图片取自现实场景中的可视对象,共包含20类已经标注好的对象,其中训练图片使用VOC2007和VOC2012的train+val数据集,共包含16 551幅图片的40 025个物体,测试图片使用VOC2007的test数据集,共包含4 952幅图片的12 032个物体。COCO数据集是微软团队提出的一个用来进行图像分类和识别的数据集,通过使用Amazon Mechanical Turk在各类复杂的日常场景收集了80类对象类别,其中包括82 783幅训练图片,40 775幅测试图片。
实验操作系统为Ubuntu 16.04,深度学习框架为Keras。实验硬件环境为Intel Core i7 8700处理器,GPU为NVIDIA GTX 1080Ti。
3.2 实验结果分析
为了更好地理解Moblienet-YOLOv3,对其中应用的机制进行逐个测试来检测每个机制对最终检测性能的影响。首先对比Batch Normalization的效果,然后对K-Means聚类分析生成的先验框与手动设置的先验框进行对比,再对网络结构的特征拼接部分进行实验,使模型直接与特征拼接之后进行检测对比,最后进行多尺度与单尺度检测的对比实验。实验中除了对比机制不同,其他设置均相同,实验结果如表1所示。

表1 网络各个机制对比实验
由表1可知,模型使用BN层之后,其mAP提升了2.1个百分点,网络不需要每层都去学数据的分布,极大地降低过拟合,提升模型的收敛速度,防止梯度消失。模型使用K-Means维度聚类生成先验框之后,mAP提升了3.1个百分点,模型通过在数据集上进行维度聚类,可以得到最为理想的先验框来取代人为预设的先验框,使模型更加容易产生准确的预测框。模型进行特征拼接之后可以同时学习深层特征与浅层特征,mAP提升了1.0个百分点。模型进行三尺度预测比单尺度预测mAP提升了1.5个百分点,多尺度检测可以对不同大小的目标进行更精准的检测,尤其对小目标的检测效果更好。
为验证本文算法的检测性能,与Tiny-YOLOv2、Mobilenet-YOLOv2、Tiny-YOLOv3、Mobilenet-SSD,Faster RCNN等算法进行对比。模型训练集为VOC 2007和VOC 2012,测试集为VOC 2007,实验结果如表2所示。

表2 不同算法在VOC数据集测试结果
由表2可知,本文算法在对比的先进算法中检测效果达到最佳,检测mAP达到73.3%,比Tiny-YOLOv3的mAP高6.5个百分点。通过改进Tiny-YOLOv3的特征提取网络,使网络的层数加深,提取的特征更为详细,深度可分离卷积保证了模型在检测精度提高的同时模型参数数量没有增加,取得较好的检测效果。然后对比了Tiny-YOLOv3与Mobilenet-YOLOv3在VOC数据集中每一类的AP。通过表3可知,Mobilenet-YOLOv3对小物体鸟、瓶子、盆栽植物等具有较高的检测精度,证明多尺度的检测对于大小不同的物体尤其是小物体具有很好的检测效果。图4为在VOC数据集上的部分检测结果。
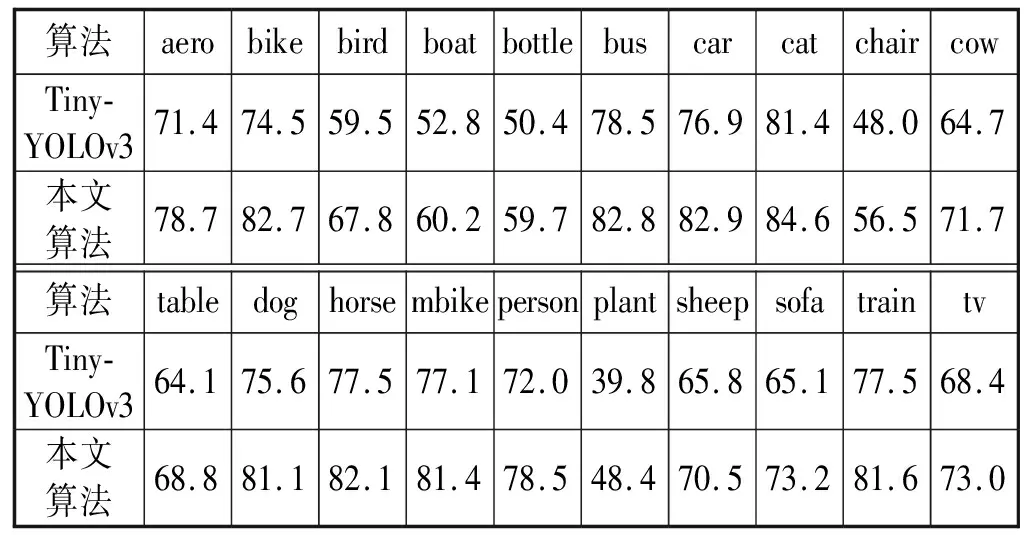
表3 VOC数据集单类AP对比 %

图4 模型在VOC数据集上的部分检测结果
在COCO数据集上进行测试,COCO是一个比VOC更具挑战的数据集,它含有80个种类。由表4中数据可知,本文算法在COCO数据集的模型大小为23 MB,为Tiny-YOLOv2模型大小的53%,Tiny-YOLOv3模型大小的67%,检测效果上比Tiny-YOLOv3的mAP提高7.1个百分点,对种类较多和尺度不一的对象具有较高的鲁棒性,与在VOC数据集上的评估结果基本一致。图5为在COCO数据集上的一些检测结果,可以看出,本文算法在实际环境中具有良好的鲁棒性和可迁移性,能够准确检测出目标物体并进行分类。
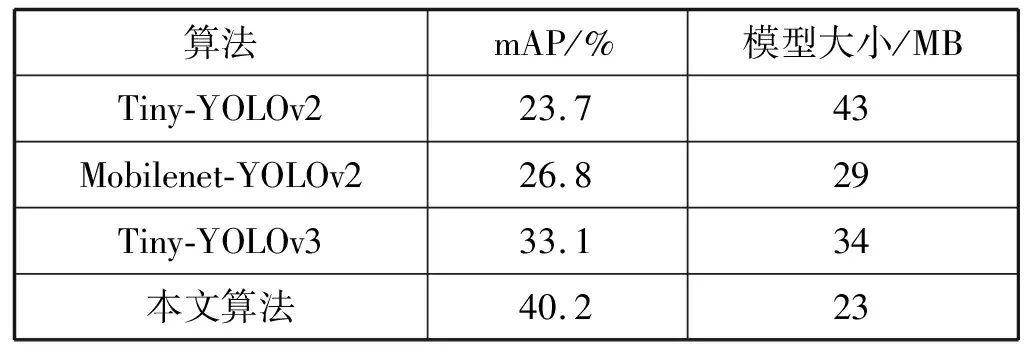
表4 不同算法在COCO数据集测试结果

图5 模型在COCO数据集上的检测结果
4 结 语
为解决嵌入式设备计算能力较弱模型难以移植且检测精度较低的问题,本文提出一种基于深度可分离卷积的轻量级目标检测网络,该模型将Tiny-YOLOv3的特征提取网络替换为Mobilenet,使模型的参数数量与模型规模减少。通过K-Means聚类生成先验框提高了模型的检测精度,同时采用特征拼接和多尺度预测的方法保证模型对多类不同物体的检测效果。实验结果表明,本文算法与现有的其他算法相比具有一定的优势,在提高物体检测精度的同时保证较小的模型计算量。如何进行极端拍摄角度下目标检测的漏检现象,是下一阶段的研究方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
马克思主义哲学研究(2020年1期)2020-11-26
海外文摘·艺术(2020年22期)2020-11-18
岁月(2016年5期)2016-08-13
太空探索(2016年5期)2016-07-12
