
基于目标检测网络的交通标志识别
2020-10-23 09:11何凯华
软件工程 2020年10期


摘 要:在无人驾驶和驾驶辅助领域,交通标志识别是非常重要的。利用YOLOv4算法的实时性检测效果,本文提出了一种基于YOLOv4的交通标志识别框架,主要识别LISA数据集中的四种交通标志:禁止标志、行人通过标志、前进标志、限速标志,为了进一步提高YOLOv4的实验性能,采用K-means算法对实验数据进行聚类分析,确定适合LISA数据集的先验框大小,实验结果表明改进后的框架对比原始的yolov4框架和YOLOv3框架,其mAP值分别提高了0.37%和1.04%,说明改进后的YOLOv4框架在交通标志识别方面具有较高的实用价值。
关键词:目标检测;交通标志识别;K-means算法;LISA数据集
中图分类号:TP311.5 文献标识码:A
Traffic Sign Recognition based on Target Detection Network
HE Kaihua
(Zhejiang Sci-Tech University, Computer Technology, Hangzhou 310018, China)
1137730657@qq.com
Abstract: Traffic sign recognition plays a crucial role in the field of unmanned driving and driving assistance. In view of the real-time detection effect of YOLOv4 (You Only Look Once, YOLO) algorithm, this paper proposes a traffic sign recognition framework based on YOLOv4, which mainly identifies four types of traffic signs in LISA dataset: stop, crosswalk, go, and speed limit. In order to improve the experimental performance of YOLOv4, K-means algorithm is used to conduct cluster analysis on the experimental data and determine a suitable size for the LISA dataset. Experimental results show that compared with the original YOLOv4 and YOLOv3 framework, the improved framework's mAP (mean Average Precision) value is improved by 0.37% and 1.04%, indicating that the improved YOLOv4 is of great practical value in traffic sign recognition.
Keywords: target detection; traffic sign recognition; K-means algorithm; LISA dataset
1 引言(Introduction)
目标检测是计算机视觉领域中一项重要的研究课题,主要是利用机器的自主学习能力来检测图像中是否存在预定的目标。目标检测网络的定义为在给定的图像或者视频中,判断其中是否存在多个预定义类别的任何目标实例。如果存在,则返回每一个实例的空间位置和覆盖范围。传统的目标检测算法的基本流程分为:区域选择、特征提取及分类器分类,区域选择使用传统的滑动窗口对整幅图像进行遍历,来确定图像中目标的位置。常用SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)和HOG(Histogram of Oriented Gradient,方向梯度直方圖)对图像进行特征提取,最后使用SVM(Support Vector Machine,支持向量机)、Adaboost等分类器进行分类。但是传统的目标检测算法步骤流程在基于滑动窗口的区域选择时,时间复杂度高、窗口冗余,并且手工提取特征的鲁棒性不高。综上所述,传统的目标检测方法受限条件比较多,很难达到很好的识别准确率。近年来,随着深度学习广泛运用于图像领域,基于卷积神经网络的目标检测算法[1]也取得了很大的成就,其大致可以分为两大类:基于区域生成的目标检测算法:如R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]。基于回归的目标检测算法:如SSD[5]、YOLO[6]系列、retina-net[7]。本文使用YOLOv4[8]目标检测算法对交通道路场景下的4种主要的交通标志进行识别。
本文主要的工作内容如下:
(1)针对目标定位不准确的问题,对于不同的实验数据集,重新调整anchor值的大小。
(2)通过图像增强的方法,分别从旋转角度、饱和度、曝光量、色度这四个方面来增加实验数据集的数量。
(3)将YOLOv4、YOLOv3和更改anchor值后的YOLOv4进行了对比实验,实验结果表明更新anchor值后的YOLOv4的实验效果是最好的。
2 YOLOv4算法(YOLOv4 algorithm)
2.1 YOLOv4框架介绍
YOLOv4目标检测算法是众多目标检测算法中的一种,是一种端到端的检测算法。主要以CSPDarknet53网络为基础,利用残差网络来进行深层特征的提取,最终经过多尺寸的特征层得到目标的类别和位置。
YOLOv4网络的整体框架和YOLOv3[9]网络是一样的,主要是在YOLOv3的基础之上进行四个方面的改进。
(1)输入端的改进:主要是对输入数据进行Mosaic增强,通过选取四张图像进行随机裁剪、随机拼接、随机排布来达到丰富数据集的效果,并且由于拼接操作增加了很多小目标,增加了网络对于小目标识别的鲁棒性。
(2)Backbone主干特征提取网络的改进:使用CSPDarknet53,相比YOLOv3中的Darknet53网络多了五个CSP[10]模块,并且只在主干网络中使用Mish[11]激活函数,网络其余部分使用Leaky_relu激活函数。使用Dropblock[12]正则化方式随机删除神经元的数量,简化网络结构,防止过拟合。
(3)Neck:目标检测网络在Backbone和最后的输出层之间添加了SPP[13](Spatial Pyramid Pooling,空间金字塔)模块和FPN+PAN[14](Path Aggregation Network,路径聚合网络)模块。
(4)预测模块:将训练时的损失函数改为CLOU_Loss,将预测筛选框的nms改为DIOU_nms。这样做的好处是将重叠面积、中心点距离、长宽比这三个因素都考虑到了。
2.2 anchors的更新
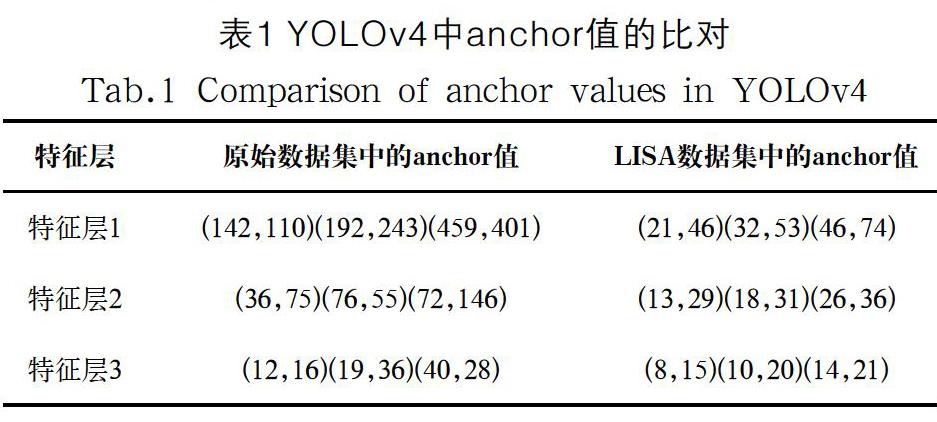
anchor值的大小对于YOLOv4目标检测网络十分重要,它是由当前数据集通过K-means[15]聚类算法统计出来的,合适的anchor值能够加快网络的收敛速度,降低误差。在原始的YOLOv4目标检测网络中,anchor值是针对coco数据集的,所以为了提高对于本次实验物体的定位精度,重新使用K-means聚类算法对anchor值进行更新,更新后的anchor值,详见表1。
3 实验(Experiment)
3.1 实验框架结构
使用CSPDarknet-53网络时,首先根据检测的对象对算法中的配置文件进行修改,将检测类别按照检测所需修改为四类,然后将CSPDarknet-53网络加入到YOLOv4网络中,根据GPU的实际使用情况,修改网络参数,然后使用训练集进行模型训练。
交通标志识别检测过程,如图1所示。
首先利用YOLOv4检测算法对已经完成预处理的图像数据进行模型训练,得到适合该场景的最优模型并保存。测试检测目标时将输入图像放入对应的YOLOv4目标检测测试脚本中,并通过保存下来的最优模型进行多目标测试,最终选择置信度最高的边框输出。由于本实验的检测对象为交通场景下的四种主要交通标志,具体为禁止标识、行人通过标识、限速标识和前进标识,所以得到的模型仅能够检测这四种交通标识类别。
3.2 实验数据集的准备
本文的数据集为LISA[16]数据集,主要检测四种交通标志,分别为禁止标志(Stop)、行人通过标志(Crosswalk)、前进标志(Go)、限速标志(Speed Limit)。其各自的标志样例,如图2所示。
实验数据集参考Pascal voc 2007数据集的制作格式,对数据集中的数据进行标注,标注完成后生成对应的XML文件。本文中的交通标识主要分为四大类,涵盖了日常生活中最常见的几种交通标志。一共制作了4750张图像,数据集会通过旋转角度、调整饱和度、调整曝光量、增加色度这四个方面来增加数据集的数量,然后按照8:2的比例分成训练集和测试集。
3.3 网络的训练参数及实验设备配置
在ubuntu18.04操作系统下对YOLOv3、YOLOv4和优化过的YOLOv4网络分别进行训练,实验所用计算机的硬件参数,详见表2。
训练的初始参数,详见表3。在训练迭代次数达到6400和7200时,将学习率分别降至初始学习率的10%和1%。
本实验训练图像的大小为416×416,因此不同特征对应的尺度是13×13、26×26、52×52,即每一个yolo层会输出三个预测框(有三个yolo层,故共有九个anchor值),預测种类数为4,则卷积层的输出维度为3×(4+1+4)=27。这样能够在维持准确率的同时,减少网络的运算量,节约训练时间,提高实验模型的检测精度和检测速度。
3.4 实验结果展示
实验数据AP值,如图3所示。图(a)为原始anchor大小下YOLOv4的目标检测结果、图(b)为使用K-means聚类后YOLOv4的目标检测结果、图(c)为YOLOv3的目标检测结果。
为了评估网络模型的检测效果,本文采用AP(Average Precision)值来衡量模型的效果,其值越大表明效果越好。
(a)YOLOv4+原始anchor值(b)YOLOv4+新anchor值(c)YOLOv3+原始anchor值
图(a)和图(c)使用的都是网络原始的anchor值,实验结果表明YOLOv4的实验mAP值比YOLOv3的提升0.67%,更新anchor值后的YOLOv4的实验结果,如图(b)所示,相比图(a)其mAP值提升0.37%。更直观的实验结果分析对比,详见表4。
4 结果(Result)
原始的YOLO架构中的anchor值是对应COCO数据集的,当训练新的数据集时,需要使用K-means聚类方法对anchor值的大小重新进行计算。从表4可得,这种做法能够提升实验的mAP值。并且在测试阶段,使用YOLOv3框架平均处理一张图片的时间为66.31毫秒,而更新anchor值后的YOLOv4框架平均处理一张图片的时间为52.72毫秒。综上所述:不管是检测的准确性还是实时性,更新anchor值后的YOLOv4框架的总体性能是最优的。
5 结论(Conclusion)
本文介绍了道路交通场景下基于YOLOv4目标检测算法的交通标志识别方法,包括了数据集的预处理、模型训练、调参优化、检测结果分析。实验结果表明,优化后的YOLOv4的交通标志识别模型已经达到很好的效果,四种交通标志类别识别的mAP值能够达到98.9%,能够准确快速地检测出四种交通标志。并且使用相同的数据集和网络参数在YOLOv3上进行了对比实验,实验结果表明YOLOv4框架对比YOLOv3,其mAP值有1.04%的提升,并且前者对比后者的检测时间快了13.59毫秒。CNN的训练需要大量的数据,在使用数据增强的方法之后,实验mAP值提高将近5.02%,使得最终的网络模型具有非常优秀的检测效果。
参考文献(References)
[1] 李杰. 基于卷积神经网络的交通标志检测算法研究[D]. 华中科技大学,2019.
[2] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2014: 580-587.
[3] Girshick R. Fast r-cnn[C]. Proceedings of the IEEE international conference on computer vision, 2015: 1440-1448.
[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]. Advances in neural information processing systems, 2015: 91-99.
[5] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]. European conference on computer vision. Springer, Cham, 2016: 21-37.
[6] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 779-788.
[7] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]. Proceedings of the IEEE international conference on computer vision, 2017: 2980-2988.
[8] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection[J]. Computer Vision and Pattern Recognition, 2020, 17(9): 198-215.
[9] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. Computer Vision and Pattern Recognition, 2018, 22(4): 17-23.
[10] Wang C Y, Mark Liao H Y, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of cnn[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 390-391.
[11] Misra D. Mish: A self regularized non-monotonic neural activation function[J]. Machine Learning, 2019, 18(5): 5-21.
[12] Ghiasi G, Lin T Y, Le Q V. Dropblock: A regularization method for convolutional networks[C]. Advances in Neural Information Processing Systems, 2018: 10727-10737.
[13] Ghiasi G, Lin T Y, Le Q V. Dropblock: A regularization method for convolutional networks[C]. Advances in Neural Information Processing Systems, 2018: 10727-10737.
[14] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8759-8768.
[15] Cover T, Hart P. Nearest neighbor pattern classification[J]. Nearest neighbour pattern classification. IEEE Transactions on Information Theory, 1967, 13(1):21-27.
[16] Li L, Li X, Cheng C, et al. Research collaboration and ITS topic evolution: 10 years at T-ITS[J]. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 517-523.
作者簡介:
何凯华(1995-),男,硕士生.研究领域:图像处理.
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
哈尔滨理工大学学报(2016年4期)2016-11-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年16期)2016-07-22
电脑知识与技术(2016年6期)2016-06-06
电脑知识与技术(2016年7期)2016-05-19
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
现代电子技术(2015年14期)2015-07-22
