
基于轻量级网络的PCB元器件检测
2020-10-28 01:44产世兵刘宁钟沈家全
计算机技术与发展 2020年10期
产世兵,刘宁钟,沈家全
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
近年来电子工业技术发展迅速,PCB(printed circuit board)电路板从简单板向现在的高密度、高精度、多层化和多样化板方向发展。同时,在体积缩小、性能提高、污染减少、品种增多等方面也在不断进步,这些使得电路板在未来还会保持强大的市场潜力以及生命力。
目前大多数工业流水线上都是由人工配合机器进行生产,这种生产方式可能会因为人类的视觉疲劳等因素,造成电路板上出现一些缺陷,例如元器件误插和漏插等问题。但是,在严密的工业和国防应用的领域中,为了实现信息化和智能化的要求,需要大量的PCB电路板,这种精密的部件不能容忍半点差错,否则会导致系统运行不畅甚至是无法运行。所以,在PCB电路板投入使用之前必须对其进行缺陷检测。
对于PCB电路板的传统检测方式有人工检测和自动光学设备检测等。PCB电路板作为大批量生产的产品,需要一种与之契合的快速的、高效的检测方式。随着制造技术的高速发展,传统的检测方式根本无法满足生产的高效性要求。为了提高元器件检测的准确度和速度,该文提出了一个轻量级的目标检测网络,实现了对PCB电路板元器件的快速识别与精确定位。
1 相关工作
自动光学检测设备[1],用于在生产过程中对PCB板的品质检测。自动光学检测设备集光学、精密机械、识别诊断算法和计算机技术于一体。检测时,设备通过电荷耦合器件或激光自动扫描PCB,采集图像后,利用计算机处理,再与数据库中的标准数据进行对比,检测出PCB板上的缺陷。尽管自动光学检测能够解决人类检测的一些弊端,但是该技术的可靠性仍然不够,严重依赖于计算机图像处理技术,如果图像处理算法不够有效,将导致误判。
在机器视觉方面,主要包括传统的图像检测算法和基于深度学习的目标检测算法。传统的图像检测算法主要包括图像预处理、特征提取、ROI提取[2]等步骤,实现待检测元器件的提取。图像预处理是对图像进行灰度化、增强和平滑的处理;特征提取是利用Harris[3]算子的角点检测算法来提取角点;ROI提取是一种根据角点坐标确定ROI区域的方法,能提取出待检测元器件所在区域的图像。
深度学习作为计算机科学研究领域的一个热点,受到了学术界和工业界的广泛关注,并取得了一系列显著的成果,近年来,深度神经网络在目标检测领域表现出了巨大的优势。
近年来,一系列基于深度卷积神经网络的目标检测算法被开发出来,例如,Faster RCNN[4]、YOLO[5]、SSD[6]和RefineDet[7]。Faster RCNN采用区域建议网络(RPN)从候选框中确定目标,然后通过分类定位来进行分类。Faster RCNN是一种端到端的目标检测方法,实现了接近实时的速率和最优的性能。在YOLO中,目标检测任务被视为回归任务,边界框的坐标和框中包含的目标的置信度以及各个类别的概率都是直接从整个图像的所有像素获得。使用YOLO,每个图像只需要“瞥一眼”就可以知道图像中包含的目标类别以及位置分布。SSD在整个图像上采用了多尺度的局部特征回归,在保持快速检测的同时保证高精确度。在RefineDet中,它在检测框架中引入了传输连接块和对象检测模块,可以在保持高效率的同时提高精度。
这些基于深度卷积神经网络的检测模型已经实现了很高的检测精度。但是,深度卷积模型附带大量参数,并且会产生大量计算成本,从而无法有效地进行实时检测。由于处理资源有限,因此将CNNs用于实时应用需要高效的计算方法。最近,在学术界出现了大量的轻量级网络,例如GoogleNet[8]、MobileNet-v2[9]、ShuffleNets[10-11]、PeleeNet[12]和Xception[13]。与CNNs相比,它们都具有较低的计算成本,同时保持了相近的甚至更高的精确度。ShuffleNet-v1[10]使用逐点分组卷积和通道混合的方式来减少计算成本,与使用Faster RCNN检测算法的MobileNet-v2相比,具有优越的性能。ShuffleNet-v2[11]提出了轻量级网络的四个设计标准。根据这些设计,作者指出了ShuffleNet-v1的一些缺点,并在此基础上进行了改进。在PeleeNet中,作者提出了DenseNet[14]体系结构的一种变体,称为PeleeNet,它改用传统的卷积运算方式,该模型旨在满足对内存和计算预算上的严格约束。
2 模型和方法
该文提出的基于Faster R-CNN和PeleeNet网络结合实现的轻量级小目标检测网络,可以用于快速准确地定位PCB电路板上的元器件并且进行准确识别。
受PeleeNet和Faster RCNN的启发,建立了一个用于小目标检测的轻量级网络,该网络可以有效地从小目标中提取特征,同时减小网络开销。轻量级小目标检测网络总体结构如图1所示,该结构一共包含五个阶段。前四个阶段是特征提取网络,不同于原本的PeleeNet结构,舍弃了原文结构的最后一个阶段,并且舍弃了阶段3的平均池化层,获得一个256维的特征图用于区域建议网络和ROI Pooling。

图1 网络结构
2.1 模 型
PeleeNet是一种轻量型的卷积神经网络,如图2所示,它主要由两种结构组成:stem block和dense block。stem block结构,在增加很少的额外计算量的前提下,增强了网络的特征表达能力,使特征图的语义信息更加丰富。它利用双通道的方式进行特征提取并进行融合。不同于原始的stem block结构,该文首先在max pool前添加一个1×1 conv层,这是因为在越深的网络层中语义信息更加抽象,感受野更大,普通的3×3卷积核无法提取小物体的特征,使用1×1卷积核来提取特征,该特征具有相对较小的感受野,在深层网络对提取小目标特征有利。而且1×1卷积核执行非线性运算,可以大大提高模型的非线性特征表达能力。另一个通道使用1×1大小和3×3大小的卷积核来提取特征,然后对两个通道进行融合。其中,3×3卷积核在小物体特征提取的初始阶段具有较大的视野,可以减少特征提取初始阶段的信息丢失。

图2 PeleeNet
其次,受到shuffleNet-v2的启发,相同的网络结构,卷积层的输入输出通道数会大大影响模型的速度。假设一个1×1卷积层的输入特征通道数是c1,输出特征尺寸是h和w,输出特征通道数是c2,那么经过1×1卷积层的浮点计算量(float-point operations,FLOPs)的公式如下:
FLOPs=hwc1c2
(1)
接下来计算内存访问消耗时间(memory access cost,MAC),经过1×1的卷积后,输入和输出的特征的尺寸大小并不变化,那么计算公式如下:
MAC=hw(c1+c2)+c1c2
(2)
根据均值不等式,可以得到式(3):

(3)
把式(1)和式(2)代入式(3),可以得到(c1-c2)2≥0,该等式的成立条件是c1=c2,也就是输入输出特征通道数相等时,在FLOPs给定的前提下,MAC可以达到最小值。shuffleNet-v2通过实验证明输入输出特征通道数相同时,模型的检测速度最快。这也就表明了输入输出通道数相同时,内存访问消耗时间最小,模型的速度最快。所以为了提升模型的检测速度,分别统一了stem block和dense layer中的输入输出特征通道数。
最后,在PeleeNet中,作者结合SSD构建目标检测网络,但是SSD在小目标检测中表现并不好,所以该文结合Faster RCNN构建目标检测网络。在原始的Faster RCNN中,作者利用ROI Pooling层使生成的候选框映射成固定大小的特征图。但是,ROI Pooling会使小目标在pooling之后导致物体结构失真,会影响后层的目标框的回归定位,对于大目标的检测准确率影响不大,但对小目标的影响很大。为了解决小目标在ROI Pooling时结构失真的问题,受SINet[15]的启发,使用Context-Aware ROI Pooling代替原文中的ROI Pooling层。如图3所示,分别为原文ROI Pooling和CAROI Pooling的结果,其中(1)为原图;(2)为原图的建议区域;(3)为ROI Pooling的结果,会有重影;(4)为CAROI Pooling的结果,没有重影。
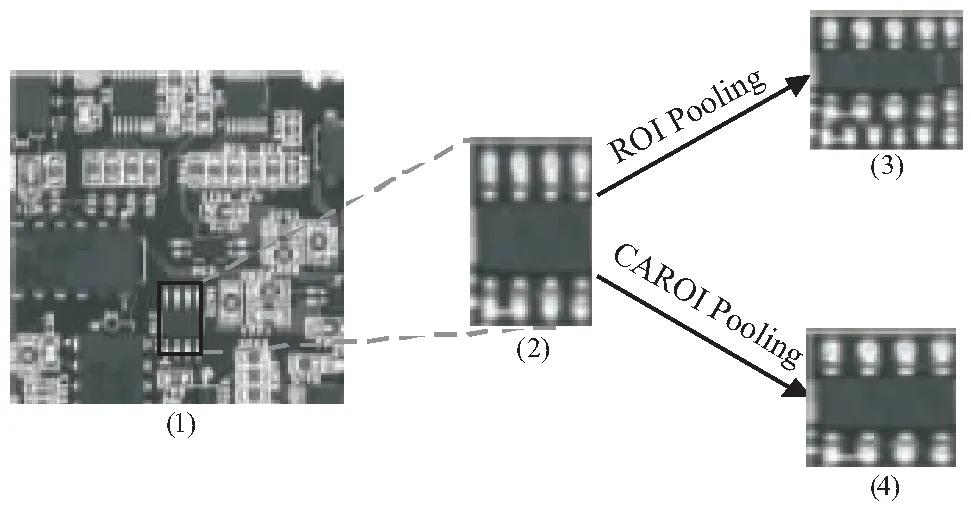
图3 ROI Pooling和CAROI Pooling的结果
该文使用Context-Aware ROI Pooling代替ROI Pooling层,解决了Pooling后物体失真的问题,明显提升了小目标检测的精度。
2.2 训练过程
RPN区域建议网络将优化的PeleeNet网络提取的特征图作为输入,文中特征图大小为原图大小的1/16,输出为一系列的建议框,每个建议框都有得分。为了生成区域建议框,通过3×3的窗口在特征图上滑动,每个窗口都映射到256维的特征向量,然后对特征向量进行目标分类和回归。如图4所示,每个滑动窗口都预测9个不同长宽比例和尺度的建议框。
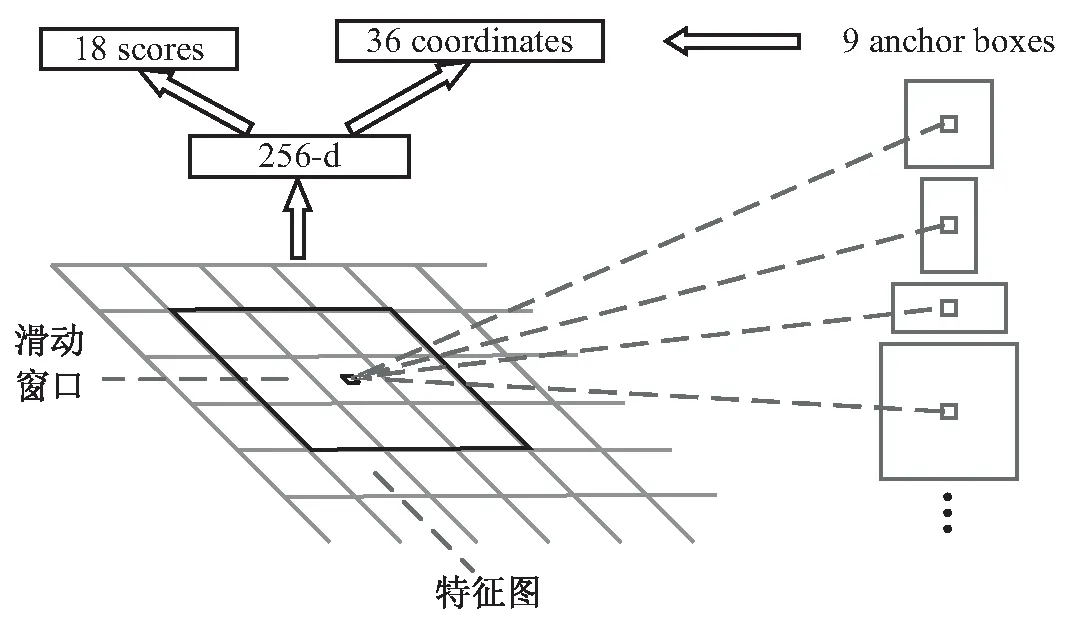
图4 RPN层
在Faster RCNN原文中,特征图的大小为原图大小的1/32,也就是特征图上的每个点对应原图上的32×32个像素点,原文采用的建议框比例和尺度分别为(0.5,1,2)和(8,16,32),建议框映射到原图上的大小也就是(256,512,1 024)。该文前面提到了用作RPN网络输入的特征图大小为原图大小的1/16,所以将建议框的尺度改为(16,32,64),映射到原图上的大小为(256,512,1 024)。但是这样的建议框的大小用在文中的数据集上并不合适,根据先验知识和实验表明,文中的数据集最适合的建议框的比例和尺度为(0.5,1,2)和(8,16,32),映射到原图上的大小为(128,256,512)。
在使用ImageNet与训练模型初始化文中的网络时,实验结果表现并不好,这是由于ImageNet数据分布和文中的PCB板元器件数据集分布完全不同,差异较大。所以在网络初始化时,利用Kaiming[16]初始化方式,实验结果表明效果很好。
在训练时,模型的迭代次数为300 k,区域建议网络的批量大小为256,在每次迭代中,模型都会预测建议框的类别和边界框。然后将预测框Bp与真实框Bg的交并比大于0.7的作为正样本,将交并比小于0.3的作为负样本,抛弃交并比在0.3~0.7之间的样本,并且保证正负样本的数量比例为1∶1。IOU的定义如下:
(4)
其中,area(Bp∩Bg)表示Bp与Bg的交集,area(Bp∪Bg)表示Bp与Bg的并集。
将所有的正样本和负样本都输入到损失函数中。另外使用多任务损失函数来训练网络,其目的是使得分类和定位的误差最小。多任务损失函数定义如下:
L(pi,loci)=Lcls+λLreg
(5)
其中,i表示每个迭代中预测框的索引,Lcls是分类的softmax损失函数,Lreg是预测框的回归损失函数,使用的是smoothL1损失。Ncls和Nreg分别表示每个迭代批次的图片区域的个数和预测框的数量。在这里,设置λ=2,是为了使Lcls和Lreg的权重一样。损失函数定义如下:

(6)

该网络模型通过随机梯度下降来训练。在训练阶段,使用0.000 1的权重衰减和0.9的动量。对于前100k迭代,学习率设置为0.001,对于接下来的200k迭代,学习率设置为0.000 1。RPN批量大小设置为256。为了抑制冗余框,基于置信度得分对建议框采用了非极大值抑制算法。
3 实验结果及分析
3.1 小目标
在该数据集中具有很多小目标,小目标大小占据整个图片的比例很小,难以检测。小目标难以检测的原因包括:分辨率低,图像模糊,携带的信息少。由此导致特征表达能力弱,也就是在提取特征的过程中,能提取到的特征非常少,这不利于对小目标的检测。在MS COCO数据集中,对小目标、中目标和大目标的定义如表1所示。

表1 MS COCO小、中、大目标的定义
为了解决小目标检测精度不高的问题,在小目标数据集上做出了两点改进。第一点,通过对包含小目标的图像进行oversampling操作。第二点,通过在每个包含小目标的图像中多次复制粘贴小目标来处理,复制目标时,确保不会和已经存在的目标有任何交叠。这增加了小目标位置的多样性,同时确保这些目标出现在正确的上下文中。
3.2 数据集
该数据集是从PCB板生产线上通过高精度相机拍照而得到的,一般为CCD相机或者是CMOS相机。原图大小为2 048×2 048的分辨率,为了获取更多小目标的特征信息,将原图切割成1 024×1 024大小的图片作为训练集。但是,PCB的数据集很难获取,能获取到的数据量很少,很难满足本章提出的网络训练达到收敛的需求,并且容易出现过拟合的状况。为了解决训练时所需的数据量,采用深度学习中数据增广的方式来增加训练数据集,让数据集尽可能多样化,使得训练的模型具有更强的泛化能力。
使用的数据增广的方法主要包括:水平或垂直翻转,旋转,缩放,裁剪,平移,对比度调整,色彩抖动和添加噪声等。经过数据增广过后的数据集,用作训练数据的有20 664张,用作测试数据的一共有3 036张。数据集一共包含元器件11类,总的分为电容、芯片、电阻、三极管和二极管五个大类,每个大类下有若干个小类,其中小目标类为第7类,它们的最大尺寸不超过32×32。
3.3 结果及分析
这部分将在提供的数据集上测试结果。同时,对提出的模型性能进行分析,并与其他方法进行了比较。实验环境为基于Caffe深度学习框架,CPU为i7-8700k,显卡为RTX 2080 Ti 11 GB显存,物理内存为16 GB,操作系统为Ubuntu 16.04。
在该模型中,使用广泛应用的召回率、准确率和mAP标准来评估性能。召回率表示总样本中有多少个正例被分为正例,定义为:
(7)
准确率表示被分为正例的目标中实际为正例的比率,定义为:
(8)
其中,TP表示将正样本预测为正的数量,FP表示将负样本预测为正的数量,FN表示将正样本预测为负的数量。
平均均值精度mAP是反映整体性能的检测指标,定义为:

(9)
如表2所示,通过消融实验表现了模型各个部分的重要性,统一通道数可以很大提升检测速度,其他各个组件对mAP的提高有不错的效果。

表2 各个组件的表现
实验结果如表3所示,在该数据集上运行了VGG16[17]模型、ResNet50[18]模型以及文中利用PeleeNet改进后的模型。
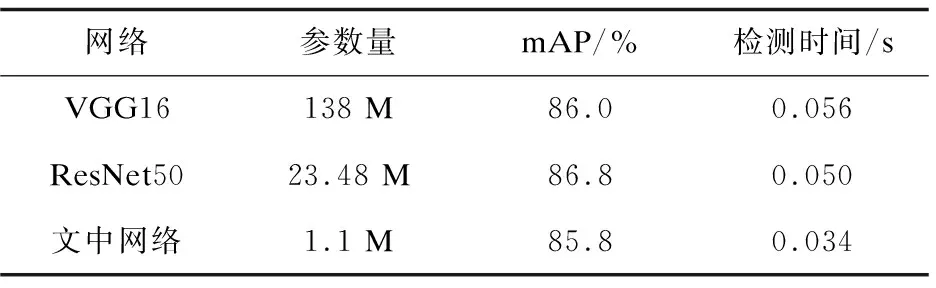
表3 实验结果对比
通过表中数据对比可以看到,文中模型在保证mAP没有多少降低的前提下,在速度上有很大的提升。同时,在小目标的检测精度上也有不错的结果。部分实验结果如图5所示。

图5 检测结果
4 结束语
基于PeleeNet网络和Faster RCNN目标检测模型设计了一个轻量级卷积神经网络检测模型,该模型在PCB板元器件数据集上具有较好的精度和较高的速度。
该检测模型在PeleeNet的基础上改变stem block的结构,统一通道数量,并且结合Faster RCNN和CAROI Pooling,同时通过先验知识设计了anchor box的大小来提高检测速度和保持检测精度。实验结果表明,该检测模型在PCB板元器件检测上有很好的效果。
在小目标的问题上,对小目标数据集进行了增广,提升了小目标的检测精度。但是,该检测模型仍然存在一些缺陷。例如,虽然模型速度有提高,但提高的幅度不够大,而且精度也有下降。在以后的工作中,将把工作重心放在提升模型速度和精度上。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
军民两用技术与产品(2022年7期)2022-08-06
航天工业管理(2022年4期)2022-05-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
航天工业管理(2021年4期)2021-05-19
孩子(2019年5期)2019-05-20
读者(2018年6期)2018-03-01
大众摄影(2015年7期)2015-07-01
