
基于深度学习的多角度人脸检测方法研究
2020-11-14 11:31厚佳琪张子昊
计算机技术与发展 2020年9期
李 欣,张 童,厚佳琪,张子昊
(中国人民公安大学 信息技术与网络安全学院,北京 100038)
0 引 言
与其他生物特征相比,人脸特征信息具有非接触性、易采集性和易接受性等优点,所以人脸识别在模式识别领域一直备受关注[1]。近年来,通过捕捉人脸图像对犯罪嫌疑人进行检测识别,在公安领域侦破案件过程中广泛应用。人脸检测是人脸识别的基础,也是其中最重要的一个环节,常用于图像中人脸位置的定位。但是在实际图像采集过程中,由于人脸姿势以及光照等环境因素的不确定性和多变性,往往会导致人脸系统无法对该类人脸进行较为精确的定位。因此,基于多角度的人脸检测越来越受到广大学者的关注。
传统的人脸检测方法是采用模板匹配技术,也就是将被检测图像与给定人脸模板图像各个位置进行对比,进而判断是否存在人脸,最终对人脸进行定位。后来随着深度学习的出现,通过卷积网络来对图像进行特征提取便应用到了人脸检测领域。其中最具代表性的两种方法是:基于区域的人脸检测和基于滑动窗口的人脸检测。前者是通过搭建物体建议产生器(object proposal generators)或选择性搜索算法(selective search)来对人脸进行定位。后者是按照给定比例计算特征图上每个位置的人脸得分值,实现人脸边界框的定位和回归。Zhang等[2]采用多任务的级联卷积神经网络将人脸检测和人脸对齐两个任务结合起来,提出了MTCNN模型。Joseph Redmon等[3]在YOLOV1的基础上提出了YOLOV2检测方法,将原本主干网络换成Darknet-19网络[4],同时在人脸框定位方面结合带有锚点框的卷积层大幅度地提高了定位精度。但是由于二者应用的特征提取的卷积网络层数不深,通过卷积网络提取到的特征鲁棒性和准确性并不高。
文中在YOLOV2算法的基础上提出了一种新的人脸检测算法。该算法使用DenseNet作为人脸特征提取器,使提取到的特征具有更高的鲁棒性和准确性。在人脸定位方面采用带有锚点框的卷积层对提取到的特征进行定位,同时通过引入归一化层,使模型的收敛速度加快。
1 基于YOLOV2的人脸检测
1.1 YOLOV1算法
首先,将输入图像划分为n×n的网格。如果某个物体中心位置坐标落在哪个网格内,就由哪个网格对该物体进行定位检测。每个单元格生成B个预测边界框以及对应的置信度,通过阈值限定以及非极大值抑制的方式对边界框进行筛选,得到最终的人脸框。在网络结构方面,YOLOV1[5]用1×1卷积层加3×3卷积层来代替GoogLeNet中的inception module[6]并行模块,同时在网络模型的末端使用全连接层来输出类别。
1.2 YOLOV2算法
YOLOV2是YOLOV1的改进版本。对定位准确度和召回率进行了改进。YOLOV1算法存在两个缺点:(1)对bounding box[7]的定位不够准确,即对小目标检测效果不佳;(2)相对于region proposal方法,YOLOV1的召回率较低。于是,YOLOV2在YOLOV1的基础上进行了改进。具体改进方法如下:
(1)带有锚点框的卷积。
YOLOV2中去掉全连接层,使用锚点框来预测边界框。具体方法如下:
YOLOV2使用卷积层进行下采样,使得最终的特征图的尺寸为13×13。最终的特征图的宽和高都为奇数,使得特征图只有一个中心点。较大的物体通常占据图像的中心位置,通过这种操作使用一个中心点来预测图像位置,而不是使用相邻的4个单元格进行预测。YOLOV1使用每个单元格预测物体类别,使用边界框预测坐标值,而YOLOV2中使用锚点同时预测类别和边界框的坐标。使用锚点进行预测会使得准确率稍微下降,但是召回率有明显的提升。
(2)使用K-means聚类。
YOLOV2使用K-means[8]的方式对训练数据集中的边界框进行聚类分析,从而找到最优的锚点框。由于欧氏距离会因bbox的大小产生不同程度上的误差,而IOU[9]与bbox尺寸无关,所以选择用IOU来计算距离,公式如下:
d(box,centroid)=1-IOU(box,centroid)
(1)
IOU表示网络预测的边界框和图片标签中实际的边界框的重合率,计算公式如下:
(2)
分子表示预测边界框和实际边界框的交集部分,分母表示预测边界框和实际边界框的并集部分。
(3)直接预测边界框位置。
YOLOV2中延续YOLOV1中直接预测的方法对边界框进行预测。网络在特征图中每个单元格中预测5个边界框,每个边界框预测5个值:tx,ty,tw,th和t,其中tx和ty表示相对于单个网络的边界框的中心坐标的偏移值,tw和th表示相对于整幅图像的边界框的宽和高,t表示置信度,即表示预测的边界框和真实边界框的重合率。
(3)
其中,Pr(Object)表示边界框是否包含物体。如果边界框包含物体,即人脸,那么Pr(Object)=1,如果边界框中不包含物体,则Pr(Object)=0。
假设此单元格距离图像左上角顶点的偏移量为cx,cy,先验框的宽和高为pw,ph,那么网络的预测结果将如式(4)~式(8)所示,预测的边界框参数如图1所示。
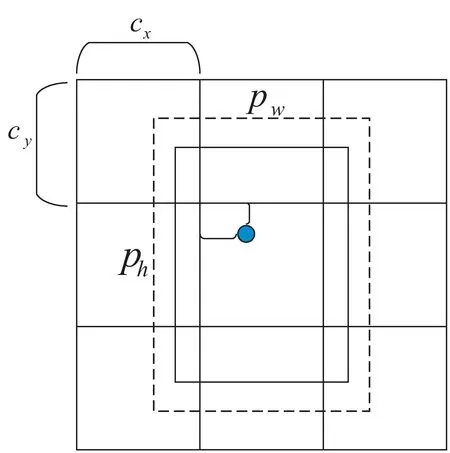
图1 边界框预测参数图
bx=σ(tx)+cx
(4)
by=σ(ty)+cy
(5)
bw=pwetw
(6)
bh=pheth
(7)
Pr(Object) × IOU(b,object)=σ(to)
(8)
(4)网络架构。
在YOLOV2中,使用448×448分辨率的图片代替原先的224×224作为预训练图像。采用Darknet-19[10]模型来提取图像中的特征信息。Darknet-19采用全局平均池化层做预测,并在3×3卷积之间使用1×1卷积来实现特征图通道数量的压缩,进而减少模型参数和计算量。最后,Darknet-19在每个卷积层后面使用了BN层,以加快模型收敛速度,降低模型过拟合。
YOLOV2人脸检测算法流程如图2所示。
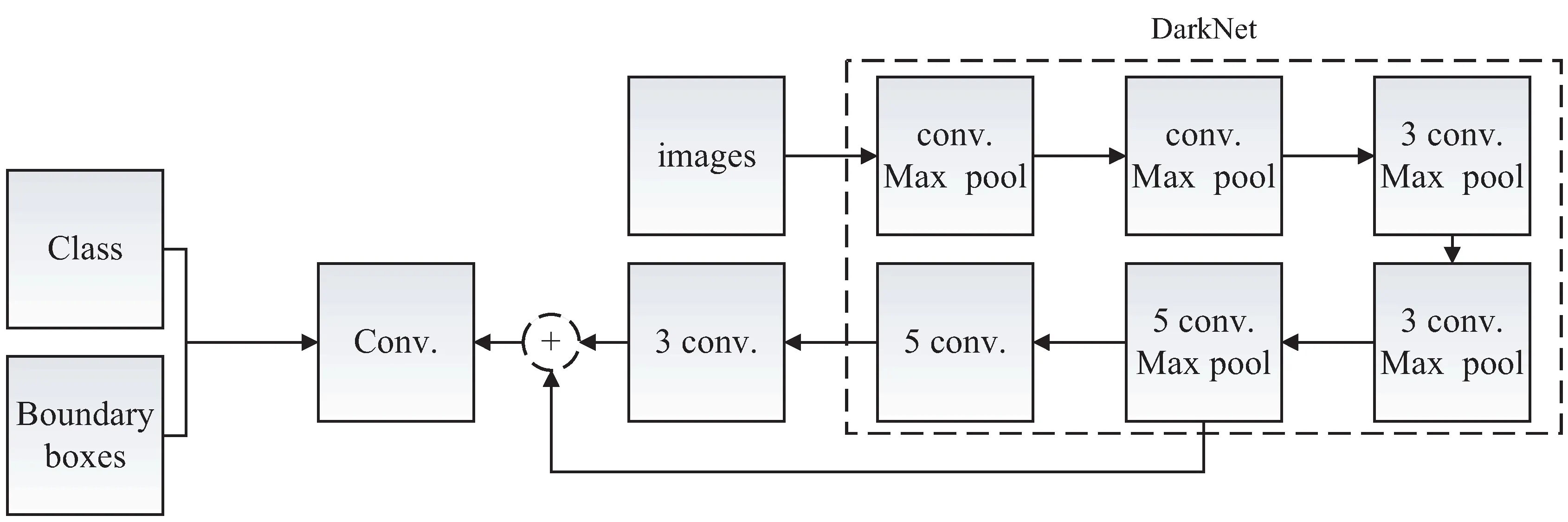
图2 YOLOV2人脸检测算法流程
2 基于DenseNet-201改进的YOLOV2人脸检测算法
YOLOV2中使用的主干网络是DarkNet-19,但是由于网络层数较浅,无法提取到更加细粒和有效的人脸特征信息。而DenseNet[11]网络在图像分类任务中取得了较高的准确率,所以文中采用DenseNet-201网络结构代替DarkNet-19模型用做人脸特征提取模块。
2.1 DenseNet网络结构

密集连接的操作需要特征图的大小统一,这就需要引入池化层来进行限定,同时为了引入池化层,需要添加过渡层来将Dense Block连接起来,这样就把网络划分成了若干个不同的Dense Bloc。其中每一个Dense Bloc为瓶颈结构,包含3×3和1×1两种类型的卷积。可以通过设置参数k来限定每一个Dense Bloc输出的特征图的数量,卷积表示为3×3×k。同时由于过渡层包括BN层,1×1的卷积层以及2×2的平均池化,过渡层中的BN层会进一步对特征进行归一化,从而加快模型的收敛速度。
2.2 基于DenseNet-201改进的YOLOV2人脸检测
相比于DarkNet-19,DenseNet-201模型网络的层数明显得到增加。DenseNet-201中的密集连接的方式不仅使得网络每一层提取到的人脸特征信息尽可能得到利用,并且在训练过程中可以学习到新的人脸特征信息。因此,文中使用DenseNet-201作为人脸检测器的特征提取部分,其他部分与YOLOV2算法相同。改进的YOLOV2人脸检测算法流程如图3所示。
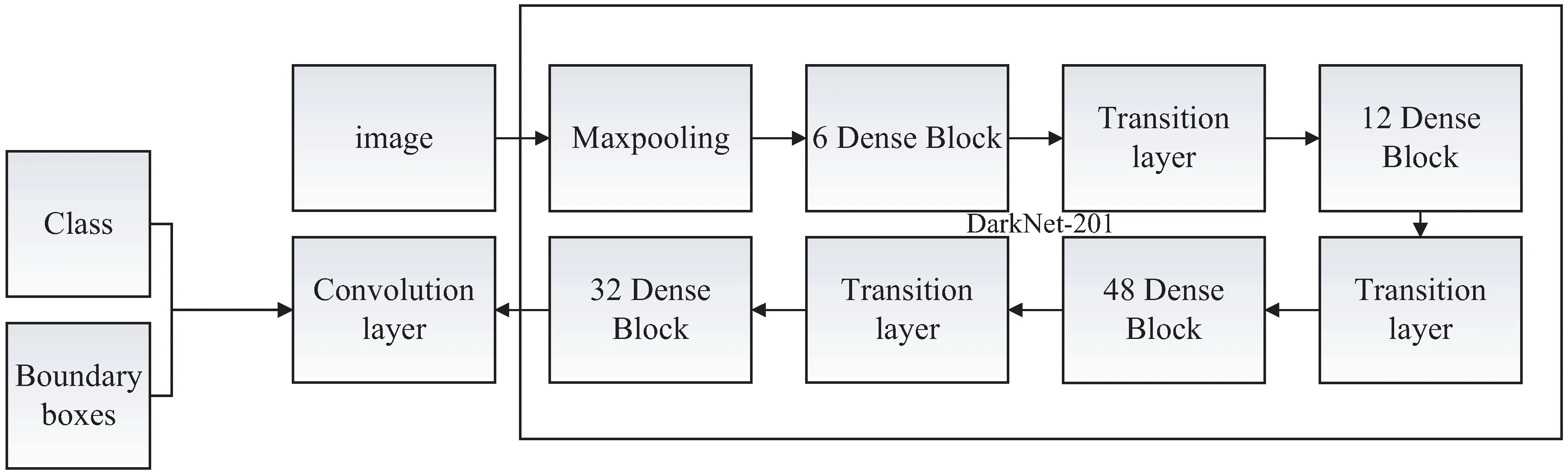
图3 基于DenseNet-201的YOLOV2人脸检测算法流程
由于DenseNet-201采用的是密集连接的方式,会使特征图的数量大大增加,同时参数的数量也会大大增加。于是文中在DenseNet-201[12]的部分提出了三点来控制网络参数和特征图的数量。具体参数设置过程如下:
第一,引入超参数k作为网络的增长率。网络的增长率表示每一个Dense Block输出的特征图的个数为k个,为了防止网络变得太宽,并且提升网络的计算效率,将k值限制成一个较小的整数。在DenseNet中,将每一个Dense Block输出的特征图的个数设置为32,即k=32。实验证明,当k值是一个较小的正整数时,网络的表现性能也更好。
第二,引入瓶颈层。DenseNet采取密集连接的方式,虽然每一层产生k个特征图,但是整个网络产生的特征图的数量是巨大的。为了控制DenseNet网络中特征图的数量,在网络的构建中引入了瓶颈层。
第三,对网络进行压缩。通过压缩过渡层中的特征图,增强模型的紧凑性。在DenseNet中,当Dense Block包含m个特征图时,网络中随后的过渡层产生的特征图的个数为θm,其中0<θ<1。于是,将θ的值设置为0.5,即过渡层将前一个Dense Block产生的特征图的数量减半。DenseNet-201网络模型的具体设置细节如表1所示。

表1 DenseNet-201网络模型
从以上表格可以看出,将每一个Dense Block的输出特征图的数量以及大小设置为3×3×32,同时每经过一个过渡层输出的特征图尺寸以及数量均减小一半,大大压缩了特征网络,使网络的运行速度加快。
3 仿真实验与结果分析
3.1 数据预处理
文中使用CelebA和FDDB人脸数据集作为人脸检测的训练数据集和测试数据集。CelebA人脸数据集包括202 599张人脸图像[13]。每一张图像的标签包括人脸边界框,5个人脸关键点以及40个人脸属性。FDDB人脸数据集包括2 845张人脸图像和5 171个人脸区域,数据集包括不同人脸姿态、不同分辨率以及旋转和遮挡的人脸图像。
文中选取CelebA人脸数据集中的190 000张图像作为训练集。将12 599张CelebA[14]数据中的人脸图像和FDDB[15]人脸数据集作为测试集,测试算法性能。
3.2 仿真实验
实验一:在不同角度人脸图像上进行算法性能测试。
实验一中选择三种不同角度的人脸图像作为测试图像,分别为正面人脸图像,60度人脸偏转图像和90度人脸偏转图像,衡量改进前和改进后不同人脸检测模型的性能,如图4所示。

图4 基于YOLOV2人脸检测算法和基于DenseNet-201的YOLOV2人脸检测算法效果示例(1)
由图4可以看出,两种人脸检测模型都可以检测出三种不同角度图像中的人脸。在人脸角度一致的前提下,基于DenseNet-201的YOLOV2算法检测效果最佳,其次是YOLOV2算法;在人脸角度不同的前提下,基于DenseNet-201的YOLOV2算法鲁棒性最强,其次是YOLOV2算法。实验结果表明,改进的YOLOV2人脸检测算法相较于原始算法,检测性能有明显的提升。
实验二:在不同光照人脸图像上进行算法性能测试。
实验二中选择三种不同光照环境下的人脸图像作为测试图像,衡量改进前和改进后人脸检测模型的性能,如图5所示。

图5 基于YOLOV2人脸检测算法和基于DenseNet-201的YOLOV2人脸检测算法效果示例(2)
由图5得出两种人脸检测模型在不同光照条件下均可以检测出人脸图像,原来的YOLOV2人脸检测算法和DenseNet-201人脸检测算法在不同光照条件下检测出的人脸框的大小几乎是一致的,表明改进算法的鲁棒性较好。并且基于DenseNet-201的YOLOV2人脸检测算法在检测的精确度最高。
实验三:在CelebA人脸数据集上进行算法性能测试。
实验三中选取CelebA的测试数据集对不同人脸检测模型进行测试,算法测试指标如表2所示。
由表2可知,DenseNet-201的YOLOV2人脸检测算法的各项性能指标相较于原模型,性能更优。

表2 不同人脸检测模型在CelebA的性能指标
实验四:在FDDB人脸数据集上进行算法性能测试。
实验四中选择FDDB人脸数据集作为算法测试数据集,对人脸检测模型进行性能评测,得出ROC曲线图,如图6、图7所示。

图6 YOLOV2人脸检测模型和改进的模型ROC曲线
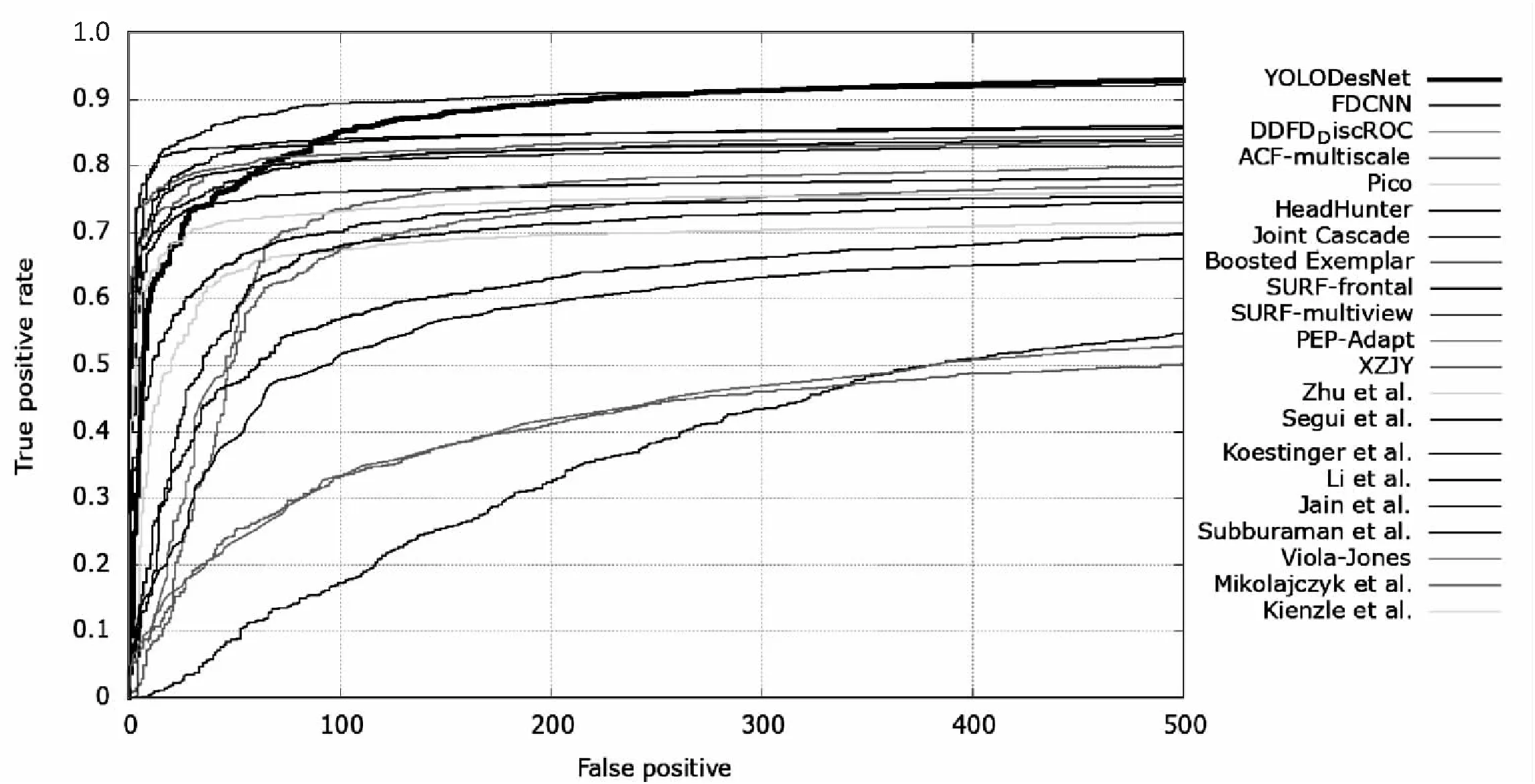
图7 基于DenseNet-201的YOLOV2模型与其他模型对比
由上图可得,在YOLOV2系列的人脸检测算法中,DenseNet-201模型在FDDB数据集上的效果最好,并且与其他人脸算法进行比较时,基于DenseNet-201的YOLOV2人脸检测算法的表现性能最好。
3.3 结果分析
实验一到实验四的结果均显示,改进的DenseNet-201的YOLOV2人脸检测模型相较于YOLOV2模型,性能得到较大的提升,并且在多角度、不同光照条件下,以及不同数据集的评测中,基于DenseNet-201的YOLOV2人脸检测模型的鲁棒性以及准确性等性能表现最优。结果表明,DenseNet的密集连接的网络结构相比于Darknet-19网络,不仅能够提取到更为细粒度、更为抽象的人脸特征,而且使得网络提取到的人脸特征在整个任务中最大化地被网络利用,并学习到新的人脸特征,提升人脸检测算法的性能。
4 结束语
基于DenseNet-201对YOLOV2算法进行了改进,提出了一种新的多角度人脸检测算法。该算法相较于之前YOLOV2中的DarkNet网络,可以提取更为丰富的人脸特征,并且使提取到的特征更具准确性和鲁棒性。在CelebA和FDDB两个人脸数据集上对YOLOV2和改进后的YOLOV2方法进行测试,实验结果表明,改进后的YOLOV2算法对多角度人脸检测的准确性更高,且具有更强的鲁棒性。经过对YOLOV2算法的改进,虽然在多角度人脸检测的性能上有所提升,但是在算法的准确性上还存在一定的差距,尚需进一步完善。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
故事作文·高年级(2022年2期)2022-02-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
奥秘(2021年5期)2021-06-15
读者·校园版(2019年18期)2019-09-09
汉语世界(The World of Chinese)(2018年5期)2018-11-24
小猕猴智力画刊(2017年6期)2017-07-03
