
基于WGAN单帧人脸图像超分辨率算法
2020-11-14 11:31周传华吴幸运
计算机技术与发展 2020年9期
周传华,吴幸运,李 鸣
(1.安徽工业大学 管理科学与工程学院,安徽 马鞍山 243002;2.中国科学技术大学 计算机科学与技术学院,安徽 合肥 230026)
0 引 言
超分辨率重建是指通过技术手段将单帧或多帧低分辨率图像重建成相应的高分辨率图像,超分辨率重建已经在图像处理和计算机视觉方面被广泛应用,如红外图像[1-2]、医学影像[3-4]、人脸识别[5]等场景。人脸超分辨率重建即通过超分辨率重建模型输入一张或多张低分辨率人脸图像,输出相应的纹理更清晰,视觉效果更好的高分辨率人脸图像,文中主要针对单帧的人脸图像进行超分辨率重建。
由于深度学习[6]在图像处理和计算机视觉领域展现出的巨大潜力,使得基于深度学习的超分辨率重建技术逐渐成为研究热点。基于深度学习的超分辨率重建算法主要利用相关卷积神经网络及其改进架构进行图像超分辨率重建。2014年,Dong等[7]率先将卷积神经网络与超分辨率重建相结合,提出了卷积神经网络超分辨率重建算法(SRCNN)。该算法先经过双三次插值进行图像上采样,然后通过三层卷积的神经网络结构学习低分辨率与高分辨率图像间的映射关系,通过该方法获得的高分辨率图像相对传统方法有较大提高,但由于神经网络的结构太浅,难以学习到更深的特征。之后,Dong等[8]对其改进,提出了网络深度更深的FSRCNN。该网络架构将原先三层的卷积层提升到8层,并在重建网络的最后用反卷积层进行上采样,代替图像在输入过程中用双三次插值进行上采样,减少了图像卷积过程的参数,加快了重建速度并取得了比SRCNN更好的重建效果。但8层的网络结构深度依然较浅,对图像的重建效果仍然有限。Kim[9]制定了深度递归卷积神经网络进行超分辨率重建,网络相较SRCNN通过利用更多的卷积层来增加重建网络的局部感受野,并进一步减少过多的参数,重建效果较好。深度更深的网络因为允许建模高度复杂的映射,能大幅提高训练效果,但更深的网络结构很难训练[10]。残差网络(ResNet)[11]和快捷连接(skip connection)被应用训练更深层次的网络,可以提高训练速度,降低模型训练的内存消耗。Ledig等人[12]利用上述训练深层次网络结构的方法,结合了生成对抗网络(GAN)和残差网络,构建了基于生成对抗网络的超分辨率重建模型(SRGAN),实验结果表明SRGAN在图像超分辨率重建方面较其他的重建算法生成了视觉效果更好的图像。
将超分辨率重建应用到人脸图像,可以有效提高人脸图像的清晰度,增强原始图像的纹理细节信息,改善图片的质量。鉴于生成对抗网络在其他图像超分辨率重建方面表现出的良好视觉效果,文中将其应用到人脸图像领域,并在其基础上针对生成网络,判别网络和损失函数做出改进,提出基于W-GAN的人脸超分辨率算法(SRWGAN)。对比其他超分辨率重建算法,在4倍的人脸超分辨率重建中增加了更多的高频信息,重建出的人脸图像效果更好。
1 相关理论
1.1 生成对抗网络
生成对抗网络启发自二人零和博弈,由Goodfellow[13]在2014年提出。该框架包含生成网络和判别网络,它们的功能分别是生成网络G接收噪声z生成一个类似真实训练数据的样本,判别网络D判别输入判别器网络的样本来源于生成样本还是真实样本,通过不断交替地训练生成器和判别器来训练模型,最后判别器无法辨别样本真伪时,生成器模型训练完成。其基本架构如图1所示。
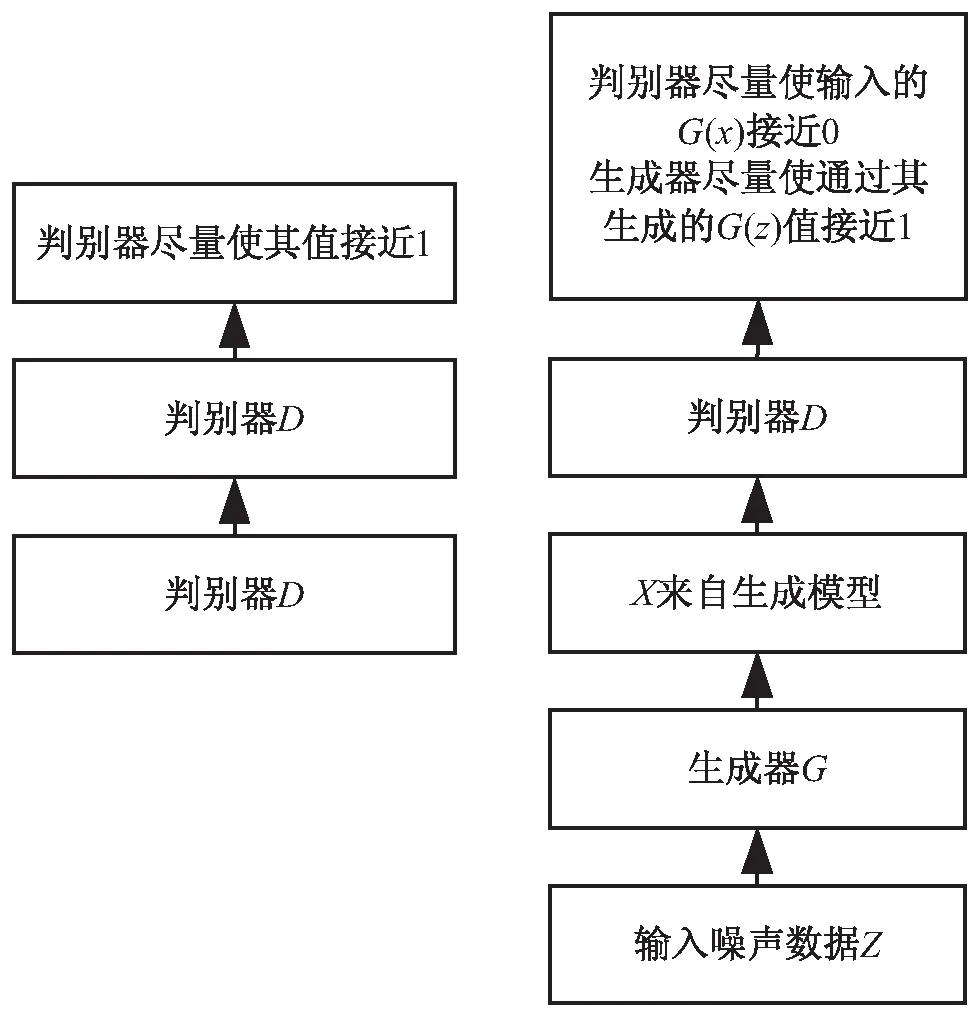
图1 GAN基本框架
图1所示为GAN的基本框架,通过对抗过程来估计生成模型。该框架包含生成网络和判别网络,它们的功能分别是生成网络G接收噪声z生成一个类似真实训练数据的样本,判别网络D判别输入判别器网络的样本来源。具体训练为先将真实样本x输入判别网络,判别网络通过自身的训练,尽可能输出概率为1的值;其次,将噪声z输入到生成网络生成样本G(z),将生成的样本G(z)作为判别网络的输入,判别器网络尽量使D(G(z))接近0,而生成器尽量使它接近1。两者相互博弈,当判别器网络无法准确识别样本来源时达到平衡。
生成对抗网络的训练是通过训练判别网络D最大化判别准确率,同时训练生成网络G最小化log(1-D(G(z))),即训练生成网络G和判别网络D是关于函数V(G,D)的极小极大的博弈:

Ez~pD(z)[log(1-D(G(z)))]
(1)
1.2 W-GAN
为了解决原始的生成对抗网络不易收敛的问题,Martin[14]提出了用Wasserstein距离代替KL或JS散度的损失函数训练方法,Wasserstein距离定义如下:
(2)

通过数学变换将Wasserstein距离应用到生成对抗网络得到如下公式:

Ex~Pg[Fw(x)]
(3)
要求函数fw的Lipschitz常数‖fw‖L不超过K的条件下,对所有可能满足条件的fw取到Ex~Pr[f(x)]-Ex~Pg[F(x)]的上界,然后再除以K,即近似求解:

Ex~Pg[Fw(x)]
(4)
通过构造一个含参数w、最后一层不是非线性激活层的判别器网络fw,在限制w不超过某个范围的条件下,使得L=Ex~Pr[f(x)]-Ex~Pg[F(x)]尽可能取到最大,此时L就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数K)。同时生成器要近似地最小化Wasserstein距离,即最小化L,通过整理得到生成对抗网络的两个损失函数:-Ex~Pg[fw(x)](生成损失)和Ex~Pg[f(x)]-Ex~Pr[F(x)](判别损失)。
WGAN相对于原始GAN,做出如下改进:
(1)判别器最后一层去掉sigmoid;
(2)生成器和判别器的loss不取log;
(3)每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c;
(4)不要用基于动量的优化算法。
1.3 残差网络和快捷连接
随着网络深度的加深,模型会出现梯度消失与梯度爆炸问题。为了解决该问题,He等人[11]提出了残差网络模型(residual network,ResNet),通过残差学习和恒等映射来优化网络结构,使网络学习能达到更好的效果。ResNet网络根据网络层数和相关组件的不同可分为ResNet34、ResNet50、ResNet101和ResNet152等。当前的ResNet网络已在网络深度1 000层以上仍取得了良好的效果,ResNet基本组件如图2所示。

图2 ResNet网络基本组件示意图
图2曲线部分表示恒等映射x,将残差块定义如下:
y=I(x,{Wi})+x
(5)
这里x和y分别表示输入和输出向量,函数I(x,{Wi})为要学习的残差映射,对于图2的示例, I=W2σ(W1x)(σ表示激活函数,并且为了简化符号,这里省略了偏差);通过快捷连接将原始要学习的H(x)转换为H(x)=I(x)+x,即对I(x)的学习,使得网络更容易被训练,有效提高了网络的性能。
2 基于W-GAN的人脸超分辨率重建
2.1 改进思想
文中的网络结构基于原始的SRGAN进行改进,针对其生成网络、判别网络和损失函数分别进行改进。
2.1.1 生成网络的改进
原始SRGAN模型的生成器网络是包含16个残差块的ResNet网络,每个残差块包含卷积层、BN层、激活函数(ReLU),并通过跳跃连接构建残差块,最后通过两层亚像素卷积层进行上采样。其中,BN层在构建识别任务的相关卷积神经网络模型中被广泛使用,通过使用一个batch数据的均值和方差对特征进行归一化,能有效对深层次的网络进行训练,防止梯度消失和梯度爆炸。但在超分辨率重建任务中模型对图像Scale比较敏感,BN层会使特征标准化,同时限制了模型的泛化能力,增加了CPU的负担,相关实验[15]也证明去掉BN层的相关神经网络超分辨率重建模型获得了更好的收敛效果,并减少计算复杂度。因此文中在构建生成器网络时去除了残差块中的BN层,同时,深度更深的网络能学习更多的高频信息[16],引入更多的先验知识。因此,生成网络模型在原有16层网络深度的基础上进一步加深网络深度,构建32层残差块的生成模型。
2.1.2 判别网络的改进
判别网络以原始的VGG19网络作为判别网络,用来判别输入判别网络的图像是真实样本图像(HR)还是生成网络重建出的图像(SR)。但VGG19的模型结构较为复杂,深度较深,且特征图通道数较少,模型在训练过程中难以收敛。因此,文中设计判别网络模型时较原有模型增加了特征图通道数[15],并引入快捷连接,同时基于Wasserstein距离作为对抗损失函数,判别网络由原来二分类任务变成近似拟合Wasserstein距离,变成回归任务。因此,判别网络最后去除Sigmoid层。
2.1.3 损失函数的改进
SRGAN采用原始生成对抗网络的损失函数KL散度作为对抗损失,在训练时存在难以收敛、训练不稳定等问题,因此文中采用Wasserstein距离代替原始生成对抗网络的损失函数KL散度作为对抗损失,加快网络收敛,并使用训练W-GAN的方式进行训练。
2.2 基于W-GAN人脸超分辨率重建网络结构
文中采用W-GAN来进行人脸超分辨率重建,并采用2.1的改进思想设计具体的生成网络、判别网络和损失函数。
生成器网络结构如图3(a)所示,输入低分辨率图像,先进入卷积层进行卷积操作(卷积层包含64个9×9的滤波器,通道数为3,步长为1),再使用PreLU进行非线性映射,然后依次进入32个相同的残差块网络进行训练,每个残差块去除了BN层,包含两个3×3×3×64的卷积层和PreLU激活层,并使用Skip Connection加快网络训练,用两次亚像素卷积进行图像的上采样增加图片分辨率,最后通过卷积层输出重建的高分辨率图像。
为了判别生成的SR样本是否和真实样本足够相似,训练判别网络D,其网络架构如图3(b)所示。输入生成的SR样本,先经过6层卷积(包含64个4×4的卷积核,3个通道)抽取图片特征,并借鉴VGGNet,卷积层的通道数以2倍逐层增加,由最初的64个通道逐层增加到第6层的2 048个;接着通过1×1卷积进行降维,然后通过两层卷积并使用Skip Connection加快网络训练,再将图片输入Flatten层进行维度压平,最后经Dense层输出结果。
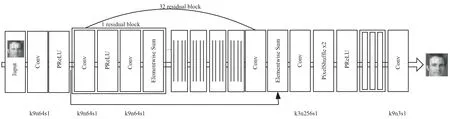
(a)生成器网络
2.3 损失函数
设计生成网络和判别网络的损失函数,通过交替训练生成网络和判别网络获得更好的重建效果,损失函数如下:
(6)
优化损失函数即优化生成网络的损失函数和判别网络的损失函数。
2.3.1 生成网络的损失函数
鉴于W-GAN相对GAN易收敛且生成的样本效果更好,文中选择Wasserstein距离作为对抗损失,同时像素的MSE损失通常与PSNR相关,优化MSE能实现更高的PSNR。综合考虑,文中的生成损失函数采用像素MSE损失加上对抗损失,公式如下:
(7)


(9)
2.3.2 判别网络的损失函数
判别网络仅考虑对抗损失作为损失函数,分别将原始高清图像和生成的高分辨率图像输入判别网络,将判别网络分别输出的近似Wasserstein距离相加作为判别网络的损失函数。公式如下:
(10)
3 实 验
3.1 数 据
文中使用了进行处理的MS-Celeb-1M和LFW人脸数据集作为实验数据集,MS-Celeb-1M是微软提供的世界上最大的人脸公开数据集,主要用于人脸检测识别等任务,包含100多万名人的1 000万多张人脸照片。实验中,随机选取3万个名人的3万张人脸作为数据集,并按照8∶2的比例,选取24 000张人脸作为训练集,6 000张人脸作为测试集。LFW人脸数据集是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要从互联网上搜集图像,用来研究非受限情况下的人脸识别问题,一共含有13 000多张人脸图像。实验中通过数据预处理剔除重复和不满要求的人脸图像,最终选取6 000张人脸作为数据集,并选取4 800张人脸图像作为训练集,1 200张人脸图像作为测试集。
人脸具有五官相对固定的特征,而神经网络对不同位置提取的特征是不同的,因此,固定相应的人脸区域,结合神经网络的局部感知性,可以优化网络训练,加快收敛。文中结合人脸检测对齐算法,针对以上预处理过的MS-Celeb-1M和LFW人脸数据集通过OpenCV和dlib返回对齐的人脸图像,具体就是通过人脸检测返回人脸关键点,然后旋转平移进行人脸对齐,并截取96*96的人脸图像,处理的示例如图4所示。

图4 人脸检测对齐
预处理过的MS-Celeb-1M和LFW数据集经过上述处理组成HR人脸数据集,之后对图像进行下采样(进行4倍下采样),形成对应的LR人脸数据集。
3.2 训练细节和参数
实验环境:Linux系统环境;python3.6;CUDA10.0+CUDNN7.60+Tensorflow1.13+Keras2.2+;32 G内存,RTX2080 GPU(8 G显存)。
训练过程中为了避免SRWGAN陷入局部最优解,首先使用SRResNet网络在处理过的LFW人脸数据集上进行训练,实验迭代1 000 000次,batchsize设置为16,学习率初始化为1×10-4,每隔500 000次学习率变为原来的0.1倍,学习动量设置为0.9,采用Adam优化算法更新网络权重。在训练SRWGAN时,利用训练好的SRResNet网络作为初始化生成模型,交替训练生成模型和判别模型,batchsize设置为16,初始学习率为1×10-5,迭代100 000次,每隔50 000次将学习率变为原来的0.1倍,同时使用RMSProp优化算法进行训练更新网络权重。
3.3 质量评价
超分辨率重建的算法性能可以通过超分辨率图片质量进行评价,超分辨率质量可分为主观评价和客观评价。主观评价方法主要是通过主观的视觉感受评价生成图片的质量。客观评价主要通过数据量化图片的指标,评价重建图像质量。文中选用常用的峰值信噪比(PSNR)[17]和结构相似性(SSIM)[18]作为客观评价的评价指标。
为了充分验证文中方法的有效性,分别在MS-Celeb-1M和LFW人脸数据集进行了4倍的人脸超分辨率重建,分别从主观评价和客观评价两方面进行对比,综合评估该算法的有效性。
3.3.1 主观效果
分别用NN[19]、Bicubic[20]、SRCNN[7]、SRGAN、SRWGAN对MS-Celeb-1M和LFW人脸数据集进行了4倍的人脸超分辨率重建,实验结果如图5(a)、图5(b)所示。

(a)MS-Celeb-1M数据集各方法重建效果对比
图5为MS-Celeb-1M和LFW测试集中的人脸图像的超分辨率重建主观视觉效果图(其中上面两个为MS-Celeb-1M测试集中的人脸图像,下面两个为LFW测试集中的人脸图像)。可以发现对人脸图像进行超分辨率重建时,基于深度学习的SRGAN算法和文中所提算法重建出的图像视觉效果较好。具体来说,NN重建出的人脸图像棋格现象严重,效果最差,Bicubic和SRCNN算法重建出的人脸图像整体看起来模糊,虽然SRCNN算法在图像锐度方面有所提升,但清晰度和图像细节方面的表现不足;SRGAN算法和文中提出的改进算法都重建处理了视觉效果出色的人脸图像,但SRGAN算法在纹理细节方面处理的不够细腻,文中所提算法在视觉上表现出了更逼真的纹理细节。综上所述,文中算法重建表现出了具有最好视觉效果的人脸图像。
3.3.2 客观效果
为了客观评价所提SRWGAN算法与其他超分辨率重建的效果,分别计算MS-Celeb-1M和LFW人脸数据集中重建的人脸图像与原始高清人脸图像的PSNR和SSIM,所得结果如表1所示。

表1 MS-Celeb-1M数据集各算法评价指标
由表1和表2各超分辨率重建算法重建出的图像与原始图像的PSNR和SSIM指标值可以看出,对于客观评价指标SSIM,文中算法获得了最高的SSIM值,并且NN、Bicubic、SRCNN、SRGAN、SRWGAN重建出图像的SSIM值依次提高。同时,对于评价指标PSNR,文中算法的PSNR值低于Bicubic和SRCNN算法,但高于NN和SRGAN算法。相较SRGAN算法,文中算法在客观评价指标上均有所提高,其中,在MS-Celeb-1M_LR人脸数据集中PSNR和SSIM分别提高了0.26和2%,在LFW_LR人脸数据集中PSNR和SSIM分别提高了0.31和3%。

表2 LFW数据集各算法评价指标
3.3.3 综合评价
虽然PSNR广泛应用于图像的客观评价,但其有很大的局限性,最近的大多数实验和文献[21]都显示了其作为评价指标往往数值无法与视觉感官的图像质量相符合,有些情况,PSNR较高的反而不如PSNR值低的视觉效果出色。针对此,文中采用客观评价指标PSNR、SSIM和主观视觉效果综合的评价方法。
在重建出的人脸图像的主观视觉效果上,SRWGAN重建出了纹理细节效果更出色的人脸图像。在客观评价上,SRWGAN算法获得了最好的SSIM评价指标数值。PSNR评价指标数值相较SRGAN也有所提高,因此,提出的基于SRWGAN的超分辨率算法能重建出效果更好的人脸图像,且效果优于NN、Bicubic、SRCNN、SRGAN算法。
4 结束语
针对4倍人脸的超分辨率重建提出了基于WGAN的人脸超分辨重建算法,该算法由生成网络生成高分辨率人脸图像,由判别网络近似原始高分辨率图像和生成图像的Wasserstein距离,并通过生成图像和原始图像的内容损失以及网络结构的对抗损失构建损失函数进行网络训练优化。最后在MS-Celeb-1M和LFW人脸数据集上与其他超分辨重建算法的重建结果对比表现出所提算法的优越性。下一步的研究工作将考虑多帧人脸图像的超分辨率重建,以探索更高效的超分辨率重建算法。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
奥秘(2021年5期)2021-06-15
家庭影院技术(2020年2期)2020-03-25
米娜·女性大世界(2016年8期)2016-08-17
CHIP新电脑(2016年3期)2016-03-10
奇闻怪事(2014年5期)2014-05-13
