
基于改进GS-XGBoost的个人信用评估①
2020-11-24 05:46俞卫琴
计算机系统应用 2020年11期
李 欣,俞卫琴
(上海工程技术大学 数理与统计学院,上海 201620)
在信用贷款不断发展的今天,信用评分已成为金融机构日益关注的问题,目前已成为研究的热门问题.信用评分是金融业的重要组成部分,在信用客户选择、风险计量、贷款前后监管、综合绩效评估和资产组合风险管理等现代事务中发挥着重要作用[1].在银行、金融机构以及基于互联网的金融公司中,强大的信用风险预测能力可以更好地巩固市场上的可持续利润.信用评分的目的是将申请人分为两类:信誉良好的人和信誉不良的人[2].信誉良好的人很有可能还清财务义务.信誉不良的人极有可能发生违约.信用评分的准确性对金融机构的盈利能力至关重要.即使将信用不良的申请人的信用评分准确性提高1%,也将减少金融机构的巨大损失.
针对信用评估的方法主要有逻辑回归[3]、支持向量机[4]、神经网络[5]和决策树[6]等.传统的对信用评估的模型主要采用单一模型.如王黎等[7]直接采用Gradient Boosted Decision Tree (GBDT)的方法对个人信用进行评估.罗方科等[8]运用逻辑回归模型对小额贷款风险进行评估.然而,单一模型在处理非线性问题时效果并不十分理想.
为了解决单一模型的问题,对模型进行组合应用逐渐成为提高信用评估准确率以及稳定性主要方法.Wang 等[9]将逻辑回归分析、决策树、人工神经网络以及支持向量机多个分类器(即集成学习)结合使用,显著提高单个基础学习者的学习能力.Koutanaei 等[10]提出特征选择算法和集成学习分类器的混合数据挖掘模型引用于信用评估,将4 种特征选择算法进行比较得出PCA 算法较好.He 等[11]为信用评分生成一个新颖的集成模型,使用粒子群优化算法进行基本分类器的参数优化,减少了数据不平衡带来的负面影响,提高了信用评分方面预测模型的综合性能.刘潇雅等[12]应用C4.5 信息熵增益率方法进行特征选择,减少了数据的冗余属性.王名豪等[13]对混沌粒子群法进行改进,并应用于XGBoost 算法中进行参数优化,提高了信用评估的准确性.
基于上述研究进展,本文提出基于改进的GSXGBoost 的个人信用评估研究,用改进的网格搜索法寻找分类器的最优参数.实验部分,在UCI 机器学习数据库中的信贷数据集上比较了本文提出GS-XGBoost与其他常用算法的性能.实验结果表明,本文算法具有较高的预测准确率,是进行信用风险评估的有效模型.
1 理论与方法
1.1 XGBoost 模型
XGBoost (eXtreme Gradient Boosting)是极限梯度提升算法,由Chen 等[14]设计,主要使提升树突破自身的计算极限,来实现运算快速,性能优秀的工程目标.
XGBoost 的目标函数为:
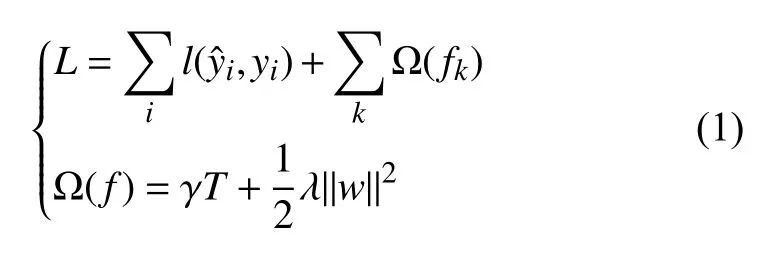
其中,l是损失函数,用于测量预测值与真实值yi之间的差,第二项 Ω是惩罚函数,即惩罚了模型的复杂性.在惩罚函数中,γ是复杂度参数,T为叶子节点数,λ是叶子权重w的惩罚系数[15].惩罚函数 Ω有助于平滑最终学习的权重,以避免过度拟合.
在XGBoost 中,完整的迭代决策树的公式应该写作:
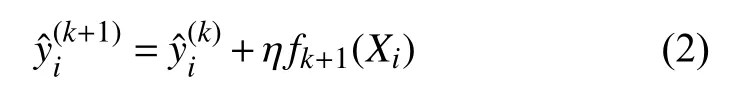
其中,fk+1为 第k+1棵 树的模型,η是迭代决策树时的步长(shrinkage),又称为学习率(learning rate).η越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳.η越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢.
式(1)中的树集成模型L将函数作为参数,且无法使用欧几里得空间中的传统优化方法进行优化,取而代之以附加方式进行优化训练.通常情况下,令表示第t次迭代中第i个实例的预测值,我们将需要添加ft来最小化以下目标:
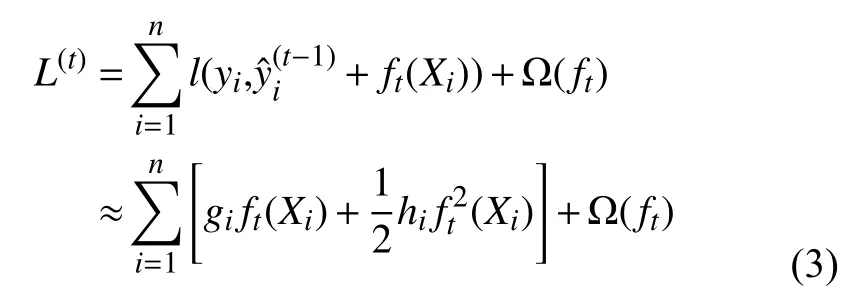
其中,gi和hi分别为损失函数的一阶和二阶梯度统计量.
定义Ij={i|q(Xi)=j} 为叶子j的实例集,则可以将等式(3)写成如式(4).
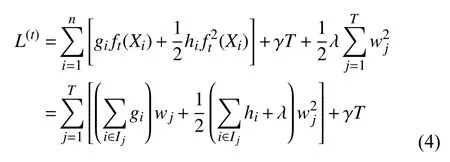
对于固定结构q(X),我们可以计算出叶子j的最优权重以及目标函数的最优值为:
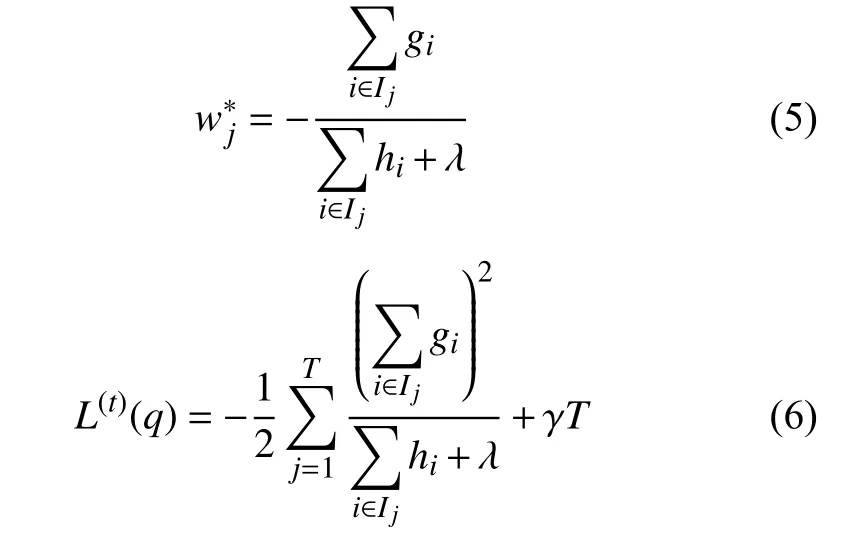
式(6)用来对结构树q的质量进行评分.该分数类似于评估决策树的杂质系数,不同之处在于它是针对更广泛的目标函数而得出的.XGBoost 本身的核心是基于梯度提升树实现的集成算法,整体来说可以有3 个核心部分:集成算法本身,用于集成的弱评估器,以及应用中的其他过程.
梯度提升算法是XGBoost 算法的基础,它是实现模型预测的有力技术之一,在Boosting 算法中处于重要位置.集成算法主要通过在数据集中生成弱评估器(n_estimators),并将弱评估器集合起来,效果优于单一的模型.n_estimators 过小容易造成数据的欠拟合,过多容易造成数据的过拟合问题.所以如何选择合适的n_estimators 是一个重点.
1.2 改进的网格搜索法
网格搜索法(grid search)[16]是指将指定参数进行枚举,通过将评估函数中的参数进行交叉验证得到最优参数的算法.即把指定优化的参数在一定范围内依次排序,并将这些数据排列成组合形成网格,依次将数据放入分类器中进行训练,并采用交叉验证方法对参数的表现进行评估,在分类器遍历了所有的参数组合后,返回一个最优的分类器,同时获得最优的参数组合.
本文中对网格搜索法的实际应用是让eta 与n_estimators 在一定的范围内划分网格并遍历网格内所有点进行取值(数据为本文借贷数据),其中eta 的范围为[0.05,1],步长为0.01,n_estimators 的范围为[1,300],步长为3.在此范围内得到eta 与n_estimators下训练集分类准确率,通过比较准确率来确定最优的参数组合.参数的寻优如图1所示.
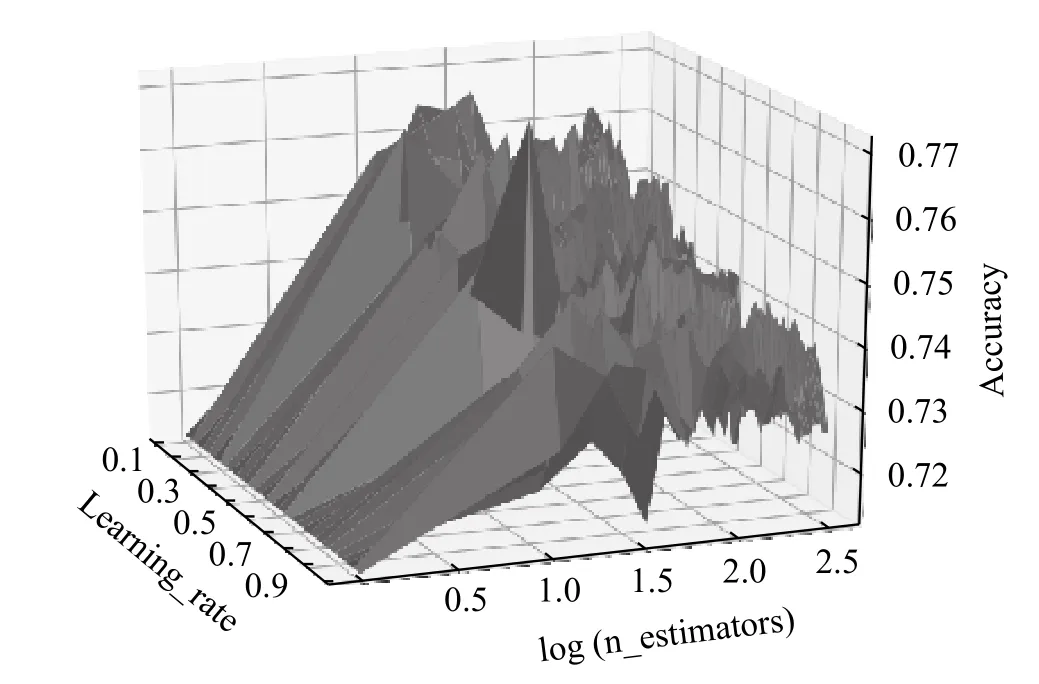
图1 网格搜索法
从图1中能够知道,参数eta 和n_estimators 在一定的区间范围内能够取得比较高的准确率,但在其他的多数范围内的准确率并不高,使得在进行参数寻优的过程中消耗大量的时间.
针对上述问题提出改进方法.首先,在参数区间上选择大步长进行参数寻优,得到准确率高的最优局部参数.再次,在局部最优参数范围内采用小步长在该范围内进行二次寻优,寻找最优参数.改进的方法减少了不必要的计算,节省了大量的时间.
2 改进的GS-XGBoost 的个人信用评估模型
改进的个人信用评估模型分为2 部分,第1 部分为数据预处理过程,首先将数据集进行极差标准化处理后进行特征选择,筛选出重要性高的特征属性.第2 部分为模型的优化过程,将筛选出的特征数据集进行改进的网格搜索法处理,寻找最优参数n_estimators和learning rate.随后将模型进行评估,采用5 折交叉验证法并取均值进行对比.
2.1 算法流程
改进的GS-XGBoost 的个人信用评估模型的流程图如图2所示.

图2 算法流程图
具体步骤如下:
步骤1.数据预处理.对数据进行建模分析之前,需要对数据中的缺失值进行填补或删除.之后,对处理后的数据进行极差标准化处理,公式如下:
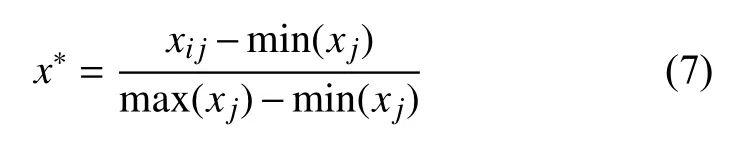
其中,xij为样本点,m in(xj) 与m ax(xj)是第j属性下样本数据的最小与最大值.
步骤2.特征选择.数据集中的维数过高时,不相关的属性特征对个人信用的评估之间并没有相互关联性,影响个人评估的准确率.通过特征选择可以提高模型的精确度,预防过拟合.本文采用随机森林算法(RF)对数据集进行训练,取得每个特征的重要性排名并移除重要度低的特征属性.
步骤3.参数寻优.使用改进的网格搜索法对分类器的参数进行寻优.
1)将数据集D分为训练集Dtrain与 测试集Dtest,比率为7/3.在数据集中采用五折交叉验证法(5-fold Cross Validation)将训练集分为5 份Dtrain1,Dtrain2,···,Dtrain5.
2)将产生的5 组数据对分类器中的弱评估器(n_estimators)以及学习速率(learning_rate)进行训练,使用改进的网格搜索法对XGBoost 模型进行寻优,得到最优参数.
步骤4.模型评估.将最优参数与特征子集代入模型中进行评估,并与其它分类器进行比较.
2.2 评价指标
本文选择F−value与G−mean值来对信用评估进行评价.混淆矩阵如表1所示.

表1 混淆矩阵

3 实证分析
3.1 数据预处理
为了检验本文改进算法的有效性,对本文算法进行实证分析,从UCI 国际机器学习库中挑选出信用卡借贷数据.数据的相关信息如表2所示.属性相关信息如表3所示.

表2 样本信息
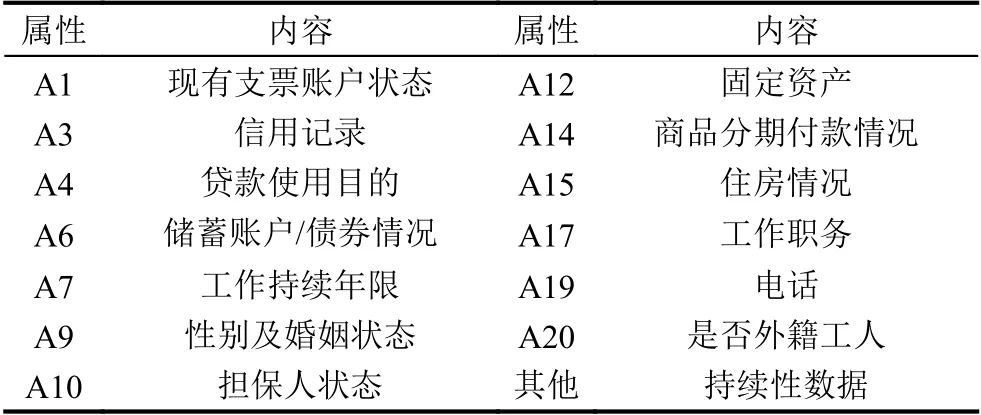
表3 特征属性
对数据集进行特征选择,利用随机森林对数据集进行特征重要性排名,结果如图3所示.选取排名前12 的特征属性数据集.
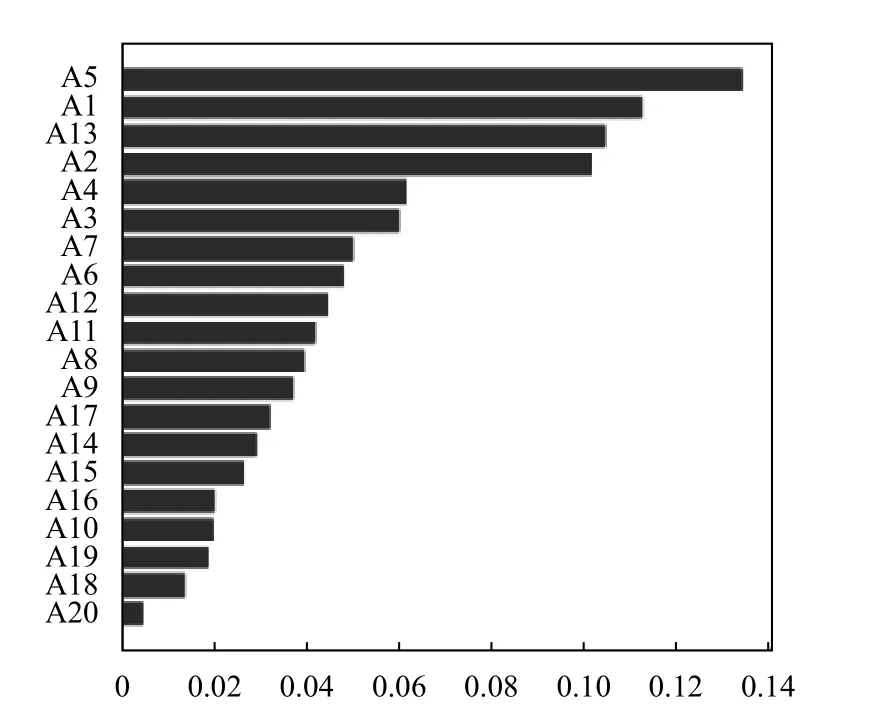
图3 特征重要性排名
3.2 改进网格搜索法
为了比较改进算法的优越性,将特征选择后的数据集进行参数寻优.网格搜索法的变量为n_estimators和learning rate,设定不同的步长范围,分为4 组数据进行比较.第1 组数据n_estimators 的范围为(1,300),步长为5,learning rate 的范围为(0.05,1),步长为0.05.第2 组数据n_estimators 的范围为(1,300),步长为10,learning rate 的范围为(0.1,1),步长为0.1.第3 组数据n_estimators 的范围为(1,300),步长为20,learning rate 的范围为(0.1,1),步长为0.1.第4 组数据n_estimators 的范围为(1,300),步长为50,learning rate 的范围为(0.1,1),步长为0.1,结果如表4所示.选择最优参数n_estimators 为16,learning rate 为0.44.
3.3 模型评估
本文将改进后的模型进行评估.经过特征选择后的数据集从20 维下降为12 维,将特征选择后筛选的数据集作为分类器XGBoost 的训练集进行训练,使用改进的网格搜索法寻找XGBoost 的最优参数n_estimators和learning rate.本文使用软件为Python3.7,使用5 折交叉验证法对数据集进行训练来减少随机性对分类结果的影响.本文算法模型(GS-XGB) 与支持向量机(SVM)、随机森林(RF)、逻辑回归(LOG)、神经网络(BP)以及未改进的XGBoost (XGB)进行比较,实验结果如表5和表6所示,F 和G 分别为F−value和G−mean的值,其中加粗部分为相同条件下的模型的最大数值.
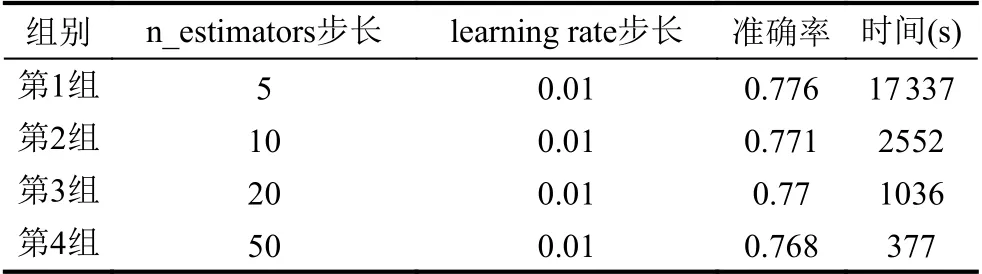
表4 参数寻优结果比较
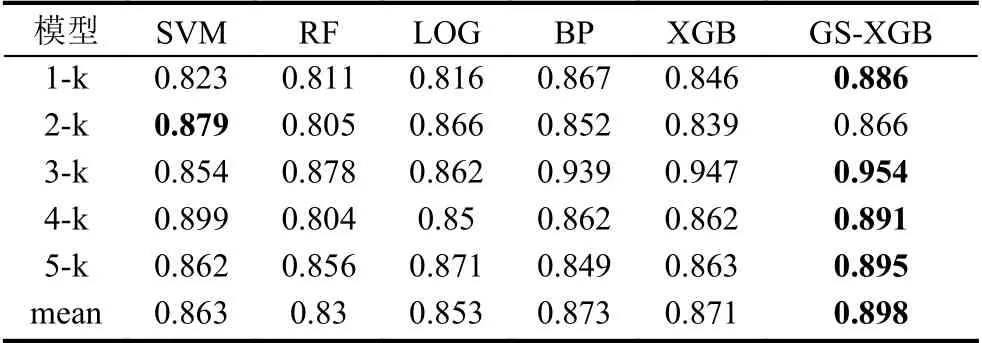
表5 少数类准确率

表6 模型实验结果对比
表5为各模型下少数类的准确率,少数类为信用较差的用户.从表中可以得到如下结论:1)总体上每个模型下的少数类准确率都比较高,差异较小,但与其他模型相比,该方法对信用评估的分类效果优于其他算法,能够有较大的准确率识别信用不良人员.2)与随机森林模型(RF)相比,少数类分类的平均准确率提高了6.8%,与未经过改进的XGBoost 相比,平均准确率提高了2.7%.
表6为各个评估模型在信贷数据集上的F−value和G−mean值,从实验结果可以得到如下结论:1)改进的网格搜索法优化XGBoost 算法的评估效果优于其他算法.2)相比没有进行改进的XGBoost 算法,改进的XGBoost 算法F−value平均值提高了5.88%,G−mean平均值提高了0.5%.这是因为在对数据进行特征选择后摒弃了无关的数据特征.
4 结语
随着个人信用贷款消费愈来愈普及,个人信用良好与否直接导致信贷金融机构的损失,因此对个人信用评估的研究非常重要.本文提出了基于改进的GSXGBoost 的个人信用评估研究,该方法将改进的网格搜索法应用于XGBoost 模型,筛选出最优参数n_estimators 和learning rate.选用UCI 公开数据集进行评估,使用F−value和G−mean以及少数类准确率作为评估指标.实验结果表示,该算法对个人信用借贷的评估性能优于其他算法.
未来需要解决的问题有:1)本文属于二分类问题,对于多分类还需要进一步的研究.2)该算法对本文数据集的有效性是否对其他数据也有效.3)在特征选择上,如何将该算法与其他方法相结合(如神经网络,支持向量机等)进一步提高算法精确度.
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
无线互联科技(2020年12期)2020-09-03
科学大观园(2019年10期)2019-09-10
中国经济周刊(2019年9期)2019-05-24
——中国制药企业十佳品牌
西部大开发(2017年5期)2017-07-05
软件导刊(2017年4期)2017-06-20
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
