
基于交叉验证和Voronoi图的煤气化过程优化
2020-11-24 04:14张志华白金锋李绍军
高校化学工程学报 2020年5期
张志华,白金锋,周 洋,李绍军
(1.辽宁科技大学 化学工程学院,辽宁 鞍山114051;2.辽宁科技大学 电子与信息工程学院,辽宁 鞍山114051;3.华东理工大学 信息科学与工程学院,上海200237)
1 前 言
煤气化技术是实现煤炭清洁高效利用的重要途径。对煤气化过程的优化,可以挖掘和提升气化装置生产潜能,对工业实际应用具有重要意义。Aspen Plus[1-2]和Fluent 等仿真软件[3-4]常用于煤气化反应过程研究,但其高精度寻优过程却是计算昂贵的问题。目前,代理模型辅助进化算法(surrogate-assisted evolutionary algorithms,SAEAs)已经广泛用于昂贵问题优化中,在化工过程仿真模拟优化中逐渐被研究者关注[5]。基于代理模型的优化,训练样本点选取是一个关键因素。因此,在有限计算成本下采样策略的构建成为SAEAs的研究重点。
最简单、直接的采样策略是选择当前代理模型预测的最好解加入训练数据集[6],改善当前最优解的精度,也就是局部开发[7]。局部开发的采样准则更多集中在局部区域寻找最优解,如采用信赖域法[8]、序列二次规划法[9]等。另一种采样策略是全局探索,通过搜寻未探索区域选择当前代理模型的最不确定点,跳出局部最优,有效提高代理模型精度[7]。在最不确定的样本点选择中,常以均方误差(mean squared error,MSE)[10-11]、采样点和已知点之间距离函数[12-15]最大为目标选择采样点。Xu 等[16]基于Voronoi 图,根据误差和距离选择样本点,对低维度(维度d≤10)问题获得较好的最优解。Wang 等[17]基于委员会的主动学习方法,以不同代理模型之间预测偏差最大的样本点作为最不确定的点,有效地解决了复杂高维问题(d=20,30),但在低维度问题(d=10)上不具优势。
为了在有限的精确函数评价(function evaluations,FEs)内获得更好的最优解,本文提出了基于交叉验证和Voronoi 图的代理辅助进化算法(cross validation Voronoi surrogate-assisted evolutionary algorithm,CVVSAEA)。CVVSAEA 通过留一交叉验证(leave-one-out crossvalidation,LOOCV)和Voronoi 图选择不确定性较高的样本点,采用全局集成模型和局部代理模型辅助粒子群优化(particle swarm optimization,PSO)算法寻优。通过对中等规模复杂问题的测试说明了本文方法的有效性,并将其应用到煤气化过程中。
2 代理模型及PSO算法
2.1 代理模型
常用的代理模型有Kriging[18]、径向基函数(radial basisfunction,RBF)[8]、多项式回归响应面(polynomial regression surface,PRS)、支持向量回归以及多个单独代理模型构成的集成代理模型[17]。Kriging 模型是一种采用插值方法的无偏估计模型,除了可以预测某一特定点处的值外,还可以预测方差,方差可以作为一种不确定性衡量。RBF是一种采用多变量数据插值方法的模型,通过基函数加权求和近似函数,具有较好的局部逼近能力。
不同的代理模型适用于求解不同特性的问题,集成代理模型可以弥补单个代理模型的缺点,更有效解决复杂黑箱优化问题[11]。集成代理模型一般采用单个代理模型权重求和的方法建立,其形式如下[7]:

2.2 PSO算法
PSO算法由于其简单且寻优能力强在工程优化设计领域中得到了广泛应用[17]。本文采用一种具有惯性权重因子的改进PSO算法,粒子每代的速度v g和位置x g更新公式如下[17]:

式中:xpbest为单个粒子最好解;xgbest为整个群体中所有粒子的最好解;g为当前迭代代数;r1和r2为[0,1]的随机数;c1和c2为学习因子,这里参照Wang 等[17]数据,取c1=c2=1.494 45。ɷg为惯性权重因子,这里ɷg从0.9到0.4之间随着迭代代数g线性下降,具体形式如下[20]:

式中:gmax为最大迭代代数。
3 CVVSAEA的采样策略
以基于委员会主动学习的代理模型辅助粒子群优化(committee-based active learning for surrogate-assisted particle swarm optimization,CAL-SAPSO)[17]为基本框架,本文分别从寻找最不确定点、全局最优点、局部最优点3个方面选择样本点,在全局搜索和局部搜索之间进行采样准则转换。
假设已知样本点X=[x1,…,x i,…,x t]T,x i∈dℝ ,d为每个样本x i的维度,t为当前集合中样本个数,对应精确函数值Y=[y(x1),…,y(x i),…y(x t)]T=[y1,…,yi,…,yt]T,构成了训练数据集(X,Y)t={(x1,y1),…,(x i,yi),…(x t,yt)}T。
3.1 最不确定点x U 选取
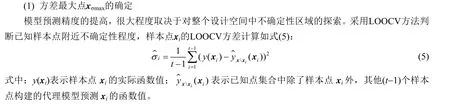
方差最大点xσmax具有最大的不确定性,xσmax周围的点相对其他区域也应具有较大的不确定性。在xσmax周围选择点加入已知样本中,则会极大地提高模型的精度。采用Kriging 模型预测,其相关函数选择常用的高斯函数。
(2)空间分割和xσmax区域的界定
根据Voronoi 图方法,由设计空间中任意两个已知样本点垂直平分线为界把整个设计空间分割成t个单元{C1,C2,… ,Ct},每个Ci包含一个已知点x i[16]。对于多维问题,如果要精确计算出形状不规则的单元Ci的边界,需要比较复杂的计算过程。采用Monte Carlo方法可以简单有效地对Voronoi 图中各个单元进行分割,近似确定单元Ci的边界范围[16]。
首先,在整个设计空间内,产生大量均匀分布随机点xr,数量为N=t×d×ωr,ωr为随机点生成数量的权值;把xr归入距离最近已知点x i的单元Ci中,由包含xσmax点的单元Cσmax中所有随机点近似描述单元边界。Cσmax中随机点相对其他单元具有较大方差,在其单元内选取采样点可以提高模型近似精度。
(3)采样点xU选择
单元Cσmax内的随机点xr在模型构建上具有和xσmax相似的影响作用,直接从这些随机点中选取采样点更加简单有效。为了增加采样点的多样性,在单元Cσmax内选择距离xσmax最远的随机点。为了提高模型的近似精度,还要考虑模型预测的偏差大小。因此,建立了以距离和偏差为目标的函数fU(xr),
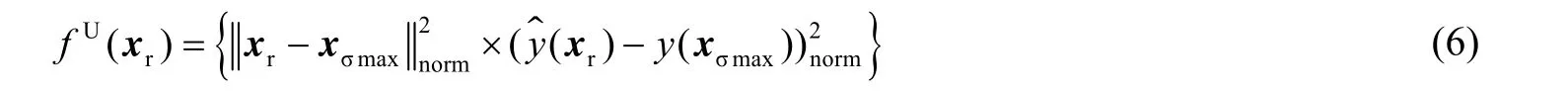
式中:xr为单元Cσmax内的随机点,ˆr( )y x为代理模型预测xr的函数值,为了减少距离差和函数值差范围不同的影响,对求得差值分别进行最大最小归一化处理,norm 表示归一化处理。
满足maxfU(x)的解x即为最不确定的采样点xU。xU描述如下:

xU选取流程如图1所示。

图1 x U 选取的流程图Fig.1 Flowsheet of selecting x U
3.2 当前全局最优点x Gb 选取
全局模型采用Kriging、RBF、PRS构成集成代理模型ˆG( )y x。根据LOOCV的误差,获得各个代理模型的权值[21]。权值ωk(x)形式为


3.3 局部最优点x Lb 选择

3.4 搜索区域转换

3.5 CVVSAEA 具体流程
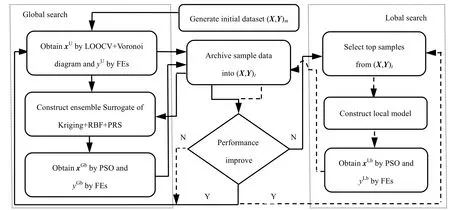
图2 CVVSAEA 流程图Fig.2 Flowsheet of CVVSAEA
CVVSAEA 流程图如图2所示,具体步骤如下:Step1:通过试验设计方法在设计空间中得到m个样本的初始数据集(X,Y)m,设定最大函数评价次数tmax;Step2:全局搜索
Step2.1:采用Kriging 模型,通过LOOCV 和Voronoi图,找不确定性较大区域,根据式(7),选择出最不确定点xU,并计算其精确函数值yU,保存到当前数据集(X,Y)t;
Step2.2:由已知数据集(X,Y)t建立Kriging+RBF+PRS模型ˆG( )y x。根据式(9),采用PSO算法找到全局最优点xGb,计算精确函数值yGb,保存到(X,Y)t,根据函数性能改善情况进行全局搜索或者局部搜索;

4 数值实例的实验结果及分析
为了验证所提出算法的性能,把CVVSAEA 和先进的代理模型辅助优化算法CAL-SAPSO[17]、代理模型加权平均法之一(one of the weighted average method,WTA1)[19]、代理模型辅助进化策略之期望改进(metamodel assisted evolution strategieswith expected improvement,MAES-ExI)[22]进行了比较。
4.1 参数设置
本文采用拉丁超立方采样(latin hypercubesampling,LHS)生成初始样本点,取初始样本个数m= 5d。函数评价最大次数tmax=11d,作为整个算法终止条件。其中,随机点生成权值ωr=100,全局和局部的转换阈值ε=1.0×10-3,top=20%,局部代理模型采用RBF,其基函数为适合拟合复杂函数的多重二次函数。PSO 算法中初始种群大小为100个,最大迭代次数为100代。为了保证公平性,PSO 在其他的算法中设置相同。对广泛采用的5个函数维度d=10 和d=20 情况分别进行了测试,函数信息如表1所示。
4.2 数值结果
为了防止随机性,每个算法独立运行30次。CVVSAEA、CAL-SAPSO、WTA1、MAES-ExI算法的平均最好函数值及方差和平均运行时间如表2所示,收敛曲线如图3所示。由于前5d个FEs用于初始训练数据的评价,因此图中只从5d个FEs开始显示。
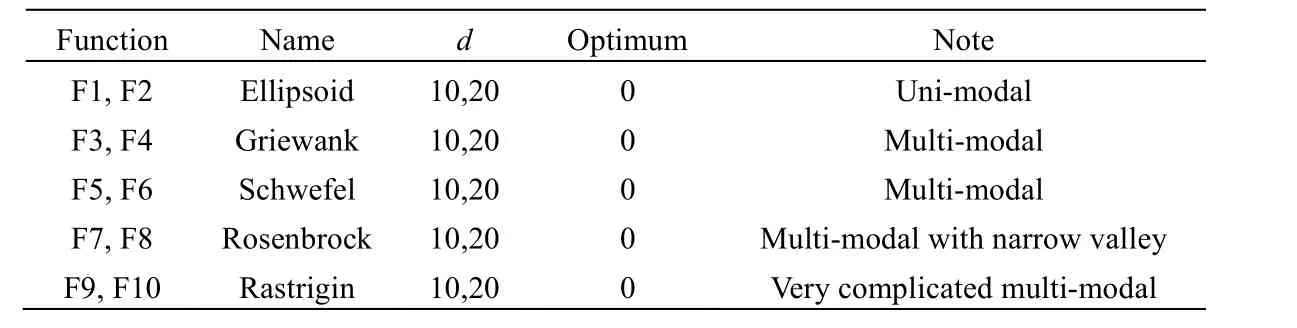
表1 测试函数Table1 Test functions

表2 CVVSAEA、CAL-SAPSO、WTA1、MAES-ExI平均最好函数值(均值±方差)和平均运行时间的比较Table 2 Averagebest function values(AVG±STD)and average runtime by CVVSAEA,CAL-SAPSO,WTA1 and MAES-ExI
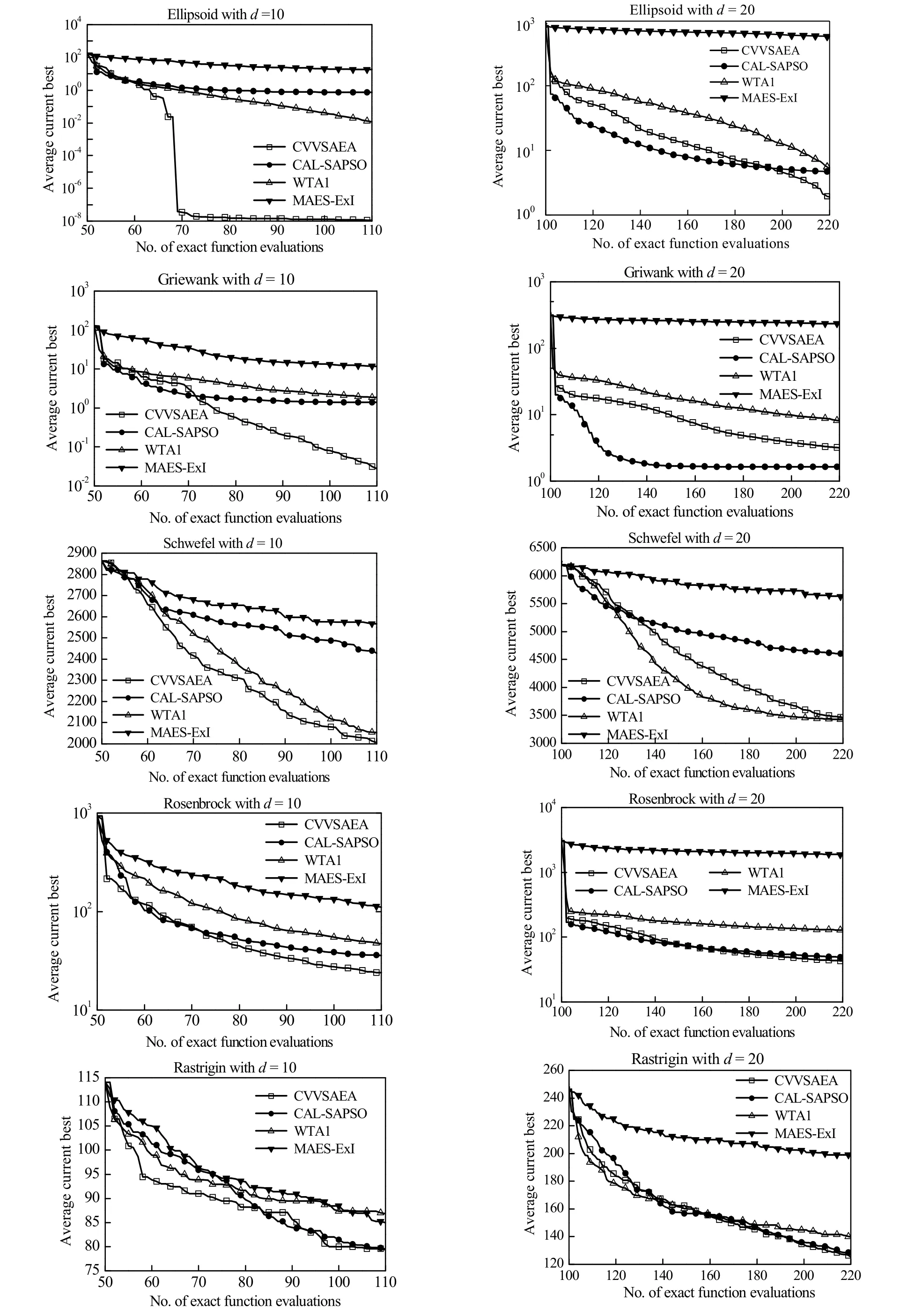
图3 CVVSAEA、CAL-SAPSO、WTA1和MAES-ExI 对测试函数的收敛曲线(d = 10,d = 20)Fig.3 Convergence curves of CVVSAEA,CAL-SAPSO,WTA1 and MAES-ExI on the test functions of d = 10,d = 20
对表2中的平均最好函数值进行了Friedman 检验[23],p-value=7.9×10-5<0.05,表明4种算法有显著差异。进一步采用Nemenyi 后续检验[23]比较各算法之间的差异,CVVSAEA 性能明显好于MAES-ExI算法,同时CVVSAEA 的平均序值也比CAL-SAPSO和WTA1好。
Ellipsoid 函数是一个单模态问题。CVVSAEA 性能最好,尤其是d= 10,基本得到了真实最优值0,远远好于其他算法。CVVSAEA 采样策略更易跳出局部最优,比较适合解决单模态优化问题。Griewank函数是一个有很多规律分布局部极小点的多模态问题。在d= 10时,CVVSAEA 明显好于其他算法。但在d= 20时,未能取得好于CAL-SAPSO的最优解。由于Griewank 具有大量局部极小点,在非常有限训练数据下,建立的代理模型可能未能找到最优解附近足够的样本信息。Schwefel 函数是一个典型的欺骗复杂问题,有很多局部极小值、全局最优值与最近的局部最小值距离很远,很难跳出局部最优。在d=10下,CVVSAEA 好于其他3种算法,在d= 20下,略差于WTA1,但好于CAL-SAPSO和MAES-ExI。WTA1只从全局寻找最优解,不去探索不确定性和局部区域,因此具有更多全局搜索的机会。Rosenbrock函数是一个全局最优值位于一个狭长平滑抛物线形谷底的多模态问题。在d=10,d= 20条件下,CVVSAEA 寻优性能最好,加入最不确定点和局部最优点的CVVSAEA、CAL-SAPSO比仅取全局最优点的WTA1更好。Rastrigin 函数与Griewank 函数有些相似,都是有很多规律分布的局部极小点,但它更复杂。在d=10下,CAL-SAPSO算法在搜索后期略超过CVVSAEA,得到更好的解。Rastrigin 函数由于具有大量局部极小点,在有限次FEs内很难跳出局部最优,可能是ωr略小未有效探索不确定点或者局部取top点有些过多造成的。随着维度增加在d=20下,CVVSAEA 寻优性能好于其他3个算法。除了F9外,采用集成模型的CVVSAEA、CAL-SAPSO以及WTA1均取得比仅用Kriging 模型的MAES-ExI 好的解。
总体来说,基于集成模型的采样策略具有更好的鲁棒性,最不确定样本点加入可以更好地提高模型精度,CVVSAEA 的取点策略要好于其他3个算法。从表2可以看出,在有限的FEs内CVVSAEA 在10种情况下7次求得解最好,其余均排序在第2位;在运行时间方面,MAES-ExI算法虽然最快,但求得的优化解最差,CVVSAEA 运行时间在d= 10 时仅次于MAES-ExI 算法,在d=20 总体略差于CAL-SAPSO算法。因此,综合考虑算法的求解精度和收敛速度,CVVSAEA 具有更好的寻优性能。
5 煤炭气化过程的优化
煤气化过程是通过煤炭与气化剂(水蒸气H2O、CO2、空气、O2等)在高温下经过一系列复杂的物理化学过程,产生以CO、H2等为主的清洁合成气的过程。工业上常见的气化炉有Lurgi 炉、英国燃气Lurgi炉(British Gas-Lurgi,BGL)、高温温科勒(high temperaturewinkler,HTW)炉和Texaco炉等。气流床气化技术是目前煤气化技术发展的主要方向[24-25],本文以气流床煤气化炉Texaco为研究对象,CVVSAEA 作为一种优化求解策略对其他气化炉同样适用。首先经过研磨,满足粒度要求的煤粉先与水混合成水煤浆,然后水煤浆和O2同时从Texaco气化炉顶部喷入,依次发生煤热解、挥发分燃烧和焦炭气化反应,产生以CO和H2为主的合成气,接着合成气和熔渣及未反应的碳离开反应区后进入炉子底部的激冷室,冷却后的合成气和饱和水蒸气从激冷室上部排出气化炉,熔渣经激冷固化后被分离出来最终进入渣罐,未反应的碳进入黑水处理系统。Texaco炉气化过程模拟流程如图4所示。

图4 Texaco煤气化过程模拟流程图Fig.4 Simulation flowsheet of Texaco coal gasification process
在煤炭气化过程中,有效气产率是一个重要的评价指标,代表了单位质量的煤产出的有效气产量,有效气产率主要受气化原料组成及性质、进料量、氧煤比、蒸汽煤比、气化温度、气化压力等工艺参数影响。根据Texaco的Aspen Plus模型[1],以Illinois No.6煤为研究对象,气化压力维持在2 431 800 Pa不变,选取干煤粉进料流量及其温度、氧煤比和O2温度、蒸汽煤比和水蒸气温度6个参数为操作变量,各个操作变量的取值范围根据文献[26]确定,最大化有效气(CO+H2)产率为优化目标。采用LHS方法生成5d个初始样本点,调用Aspen Plus仿真模型计算其对应的有效气产率,得到初始训练数据集。仿真模型调用最大次数tmax=11d。随机点生成权值ωr=100,转换阈值ε=1.0×10-3,局部取函数值排序top=30%,局部代理模型采用Kriging,全局模型为Kriging+RBF+PRS。PSO算法初始种群为100个,最大迭代次数为100代。
从图5中可以看出,大约从第40次FEs开始,CVVSAEA 找到的优化解开始好于其他3种算法,具有更好的寻优性能。分析表3中数据,与其他3种算法相比,CVVSAEA 使有效气产率分别提高了0.32%、0.16%、0.48%,对煤炭气化工业流程优化具有一定的应用价值和指导意义。
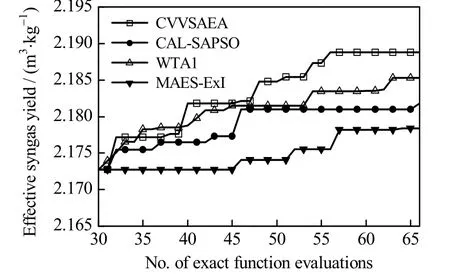
图5 有效气产率优化过程Fig.5 Optimization process of effective syngas yield

表3 CVVSAEA、CAL-SAPSO、WTA1和MAES-ExI优化结果比较Table 3 Comparison of optimization results by CVVSAEA,CAL-SAPSO,WTA1 and MAES-ExI
6 结 论
基于LOOCV 和Voronoi图,本文提出了一种选取最不确定点的采样准则优化代理模型,进而更加有效辅助进化算法解决其优化时计算昂贵问题。界定不确定性最高的区域,综合考虑多样性和性能指标选点,且无需进化算法求解,快速精准地改善了代理模型精度。采用集成模型预测具有更稳定的近似能力,选择较好点建立局部模型加快了收敛过程。全局搜索和局部搜索的自适应切换达到了平衡全局探索和局部开发的目的。通过不同模态不同维度下10个复杂测试问题和煤气化过程实例,发现在有限昂贵函数评价限制内,CVVSAEA 具有更好的寻优性能,在煤气化过程优化中应用前景较好。尽管CVVSAEA在昂贵函数评价上有一定优势,但同时也存在一些不足。如问题维度过高时,Kriging 模型计算成本较高,如何在高维问题下提高其计算效率是今后需要进一步深入研究的方向。

猜你喜欢
中国化肥信息(2022年9期)2022-11-23
水泥技术(2022年5期)2022-09-28
数学物理学报(2022年4期)2022-08-22
应用化工(2022年3期)2022-05-27
数学物理学报(2022年2期)2022-04-26
环境卫生工程(2021年4期)2021-10-13
煤气与热力(2021年7期)2021-08-23
诗林(2019年6期)2019-11-14
金桥(2018年4期)2018-09-26
化工管理(2017年30期)2017-03-05
