
基于MF-SSD卷积神经网络的玉米穗丝目标检测方法
2020-11-29 13:04朱德利林智健
华南农业大学学报 2020年6期
朱德利,林智健
(1 重庆师范大学 计算机与信息科学学院,重庆 401331; 2 重庆市数字农业服务工程技术研究中心,重庆 401331)
玉米是中国主产农作物之一,在我国国民经济中具有举足轻重的作用。现阶段对玉米生长状态的监控和产量的预测主要还是人工方式[1],主要原因是玉米生长状态特征不容易自动提取,果穗性状在生长周期内变化较大。玉米是雌雄同体异花,雌花在植株的叶腋位置,雄花在植株的顶部位置[2]。玉米穗丝作为授粉器官,不同生长阶段的性状对玉米生长状况的监控[3]和果穗产量的预测有重要的参考意义。监控玉米穗丝的重要一步即是对其所处的位置进行检测。
不同生长阶段的玉米穗丝的特性和性状有很大不同,不具有通用特征,用传统机器视觉方法进行目标提取和定位的效果不佳。近年来,大量大型图像数据建设和硬件计算力的增强促使卷积神经网络在计算机视觉的各个方面获得突破;王临铭等[4]提取甘肃大麦病斑的颜色和纹理特征,以特征向量为输入向量构造大麦病害神经网络分类器模型,对甘肃大麦病害的整体识别正确率达到86.7%;王璨等[5]提出了基于卷积神经网络提取多尺度分层特征的玉米识别方法。此外,利用神经网络可对农作物的生长状态进行科学分析;周云成等[6]提出一种基于面向通道分组卷积网络的番茄主要器官实时识别网络模型;刘永波等[7]提出一种基于深度卷积神经网络的在自然环境条件下识别玉米病害的方法;Koirala等[8]以芒果为研究对象,使用深度学习方法对研究目标进行检测并预测产量;Tian等[9]通过改进的YOLO-V3模型对果园中不同生长阶段苹果的检测进行了研究。
目前目标检测算法一般分为2种,基于候选区域的两步目标检测算法(如Faster R-CNN系列[10])和基于回归的单步目标检测算法(如YOLO、SSD[11])。两步目标检测算法的精度高但检测速度稍慢,单步目标检测算法的检测速度快但精度略低。其中,SSD同时借鉴了YOLO的回归思想和Faster R-CNN的锚(Anchor)机制,检测性能相对较好,效果也超越了两者。但是SSD的模型参数过多,运行时内存占用量过大,在显存容量较小的GPU设备上无法运行[12]。
针对农业生产实践中玉米生长状况监控和产量预测中对玉米穗丝实时视觉识别的需求及问题,本研究通过改进深度学习中的SSD目标检测算法以完成玉米穗丝的位置确定,提出了基于多特征融合SSD (Multi-feature fusion SSD, MF-SSD)的玉米穗丝检测模型。该模型有较高的小目标识别性能,在识别准确度和性能消耗方面均可满足实际要求。
1 SSD网络模型及其改进
1.1 SSD网络模型
SSD属于单步目标检测算法,在多尺度特征图上以回归的方式直接得到目标的类别和位置。如图1所示,传统的SSD网络模型架构包括2个部分,基础网络采用VGG16用于目标特征提取,在基础网络后是额外添加的特征层,最后从6个不同尺度的特征图上提取特征为目标检测使用。
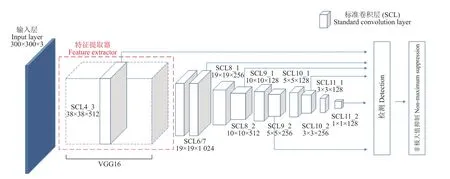
图1 VGG16-SSD的网络结构Fig. 1 VGG16-SSD network structure
传统的VGG16-SSD模型结构较长,操作相对复杂,不易训练。其中VGG16的参数过多,模型较大,在有限资源的工程应用设备上使用会造成困扰。另外,在VGG16-SSD训练过程中,小目标特征经过多层卷积后会发生特征消失现象,甚至不会检测到目标。因此,如何改善SSD网络参数规模大、小目标识别能力不佳等问题是本文研究的重点。
1.2 使用MobileNet作为特征提取器
VGG16的权重参数约1.38×108个[13],是为解决类似ImageNet这类大规模图像任务而设计的深度卷积神经网络。玉米穗丝的检测在类型和样本数量方面都远小于ImageNet,所以可使用比VGG16更轻量化的特征提取器。
Alawad等[14]提出的MobileNet卷积网络模型属于一种轻量级的卷积网络,它基于深度可分离的卷积架构,将常规标准模型结构分解成深度卷积与逐点卷积2类,如图2所示。深度卷积作用于每个通道,而逐点卷积用来组合各个通道的输出。通过卷积分解,可以有效减少计算量,加快运算速度,减轻因过度拟合导致的训练问题。
深度可分离卷积较传统卷积所降低的参数比例可以定义为公式(1):

式中,Dk为卷积核的宽高,DF为输出特征图的宽高,M为输入的特征图数量,N为卷积核数量。其中传统卷积的计算量为Dk2MNDF2,深度可分离卷积的计算量为MNDF2+Dk2MDF2。

图2 传统卷积和深度可分离卷积Fig. 2 Traditional convolution and depth separable convolution
本文使用MobileNet网络作为特征提取器替换SSD中的VGG16,能够减少整体网络的计算开销,减少内存占用量,改进后的网络结构如图3所示。MobileNet-SSD模型网络结构与VGG16-SSD的网络结构类似,都是抽取多个不同尺度的特征图进行目标检测。该模型结合MobileNet和SSD 2种类型网络的优势,保持了原有SSD网络结构,降低了参数模型大小。
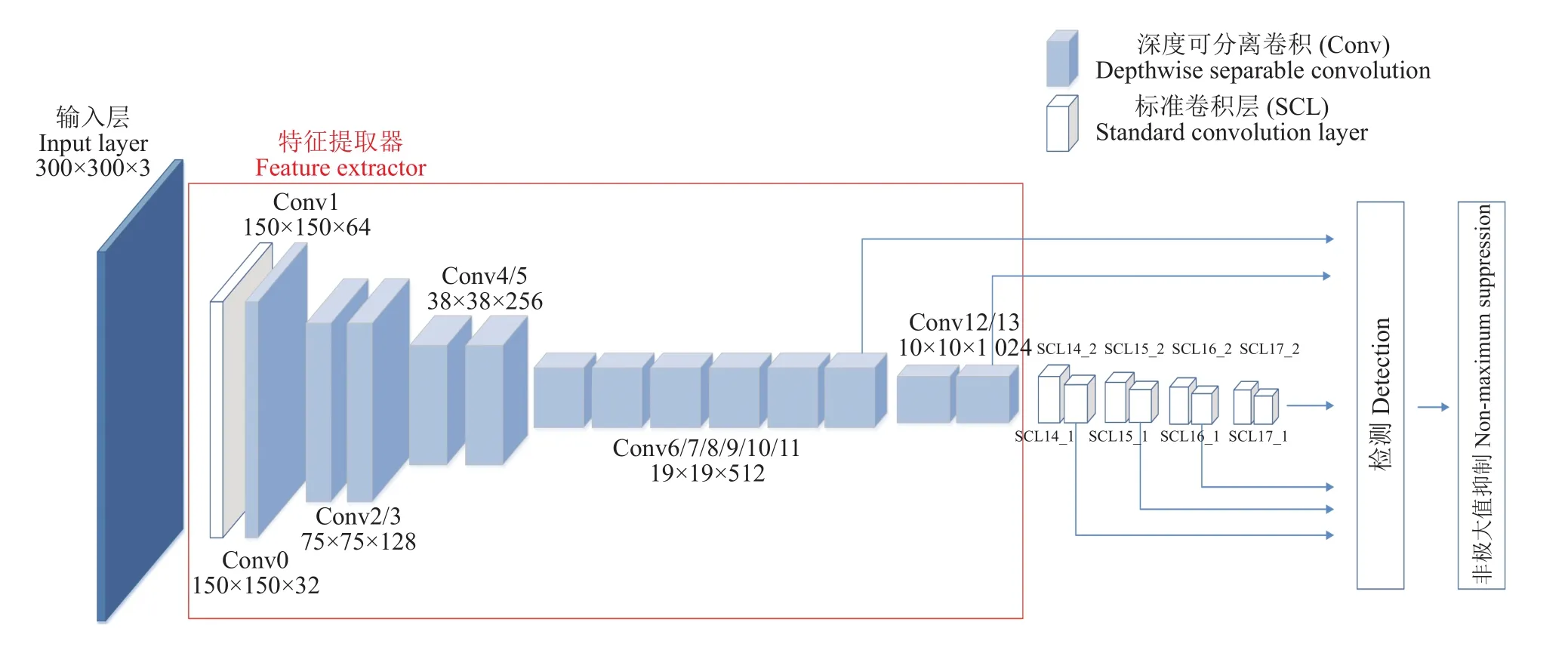
图3 MobileNet-SSD的网络结构Fig. 3 MobileNet-SSD network structure
1.3 MF-SSD的网络模型架构设计
MobileNet替换VGG16后的网络MobileNet-SSD仍然存在小目标检测能力不佳的问题,原因是该网络不能充分利用局部的细节特征和全局的语义特征。随着网络层次的增加,卷积层提取特征的语义越来越强,SSD却直接用不同语义的特征图进行预测。图4a为原始SSD结构,这种方式各个层之间没有联系。最底层的特征图分辨率高但是语义值不够,导致不能被使用。SSD只使用较上层的特征图用于目标检测,因此对小物体的检测性能不佳。
Lin等[15]提出一种旨在提高准确率的特征提取器-特征金字塔网络(Feature pyramid network,FPN),如图4b。FPN提供了一条自顶向下的路径,从语义丰富的层构建高分辨率的层。把浅层的细节特征和高层的语义特征结合起来进行预测,使得算法的精度明显提升。

图4 SSD与特征金字塔网络结构对比Fig. 4 Structure comparison of SSD and feature pyramid network
本文受FPN网络结构思想的启发,重新构建了MobileNet-SSD中的特征提取器,图5为重建的网络模型。该网络的前向过程实现了自底向上特征提取,在前向过程中,特征图大小在经过某些层后会改变,而经过某些层不会改变。将不改变特征图大小的卷积层归为一个阶段,将每个阶段的最后一层得到的特征图进行组合能够构成特征金字塔。
对MobileNet-SSD不同阶段的最后一层C3、C5、C11、C13构建一条自顶向下反向路径。自顶向下构建层的过程采用最近邻上采样法进行,从语义丰富的层构建高分辨率的层,得到重建层的语义较强,但目标的位置不精确。为检测更加准确,本文通过添加横向连接将上采样的结果和自底向上生成的相同大小的特征图进行融合得到融合结果M3、M5、M11、M13。在横向连接前对前一层特征图要使用1×1的卷积核,目的是改变卷积核个数,使其和后一层的特征图个数相同,如图6。在融合后使用3×3的卷积核对每个融合结果进行卷积,消除上采样的混叠效应,最终生成的特征图结果是P3、P5、P11、P13,然后使用P3到P13进行多尺度目标检测。
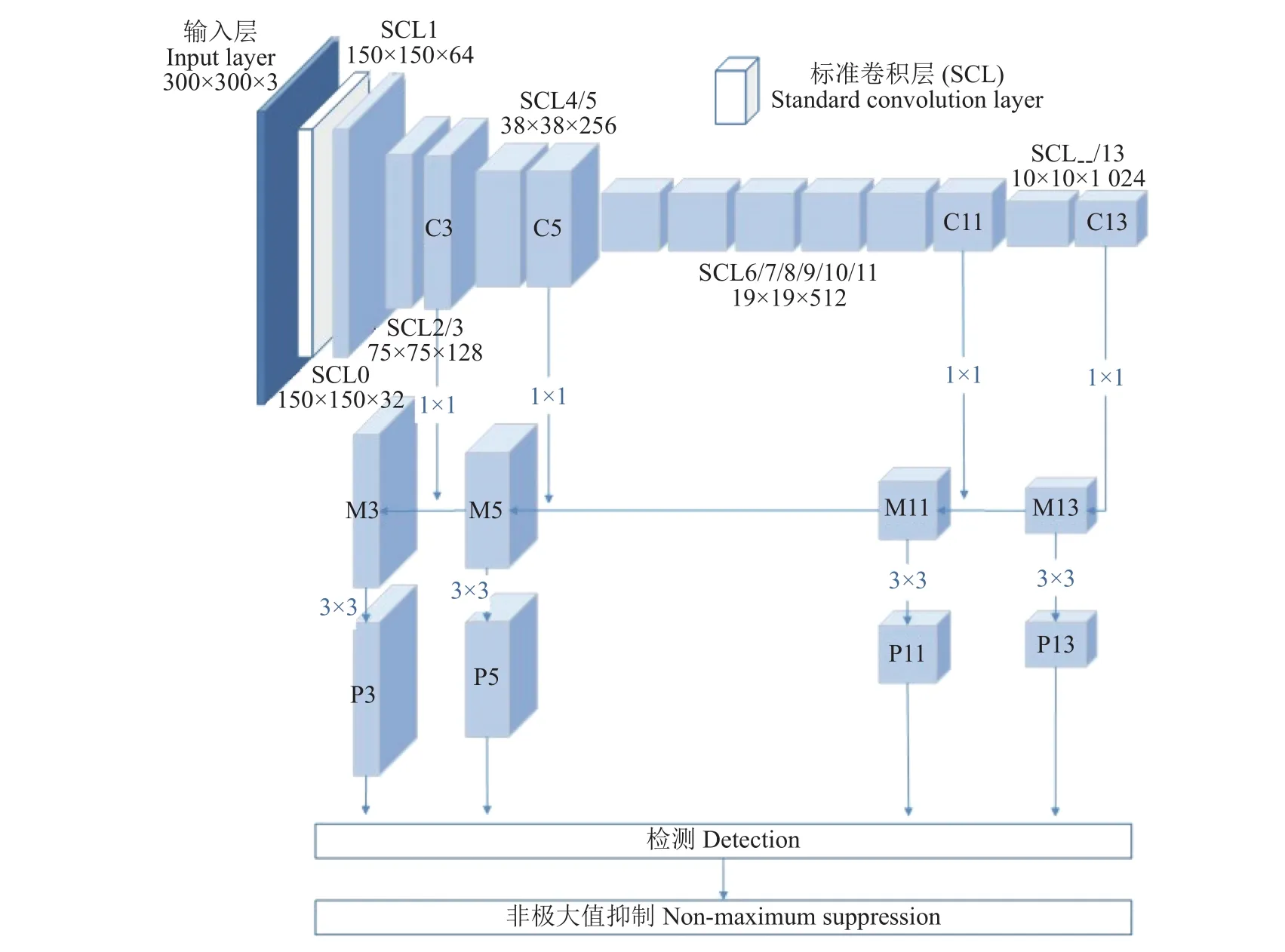
图5 MF-SSD的网络结构Fig. 5 MF-SSD network structure
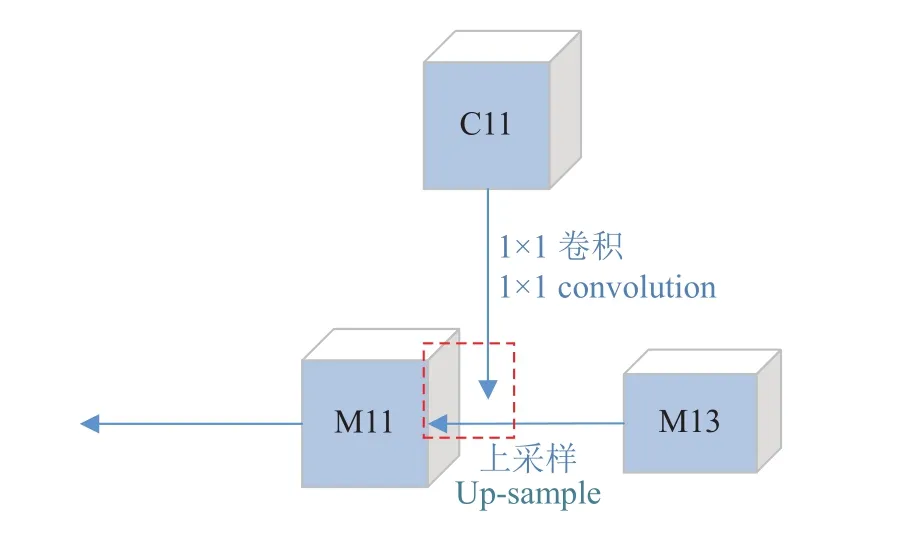
图6 横向连接过程Fig. 6 Horizontal connection process
该模型对网络结构的关键改进在于把多层特征融合到了特征图的提取层,故最终的模型本文称之为MF-SSD网络模型。相比于传统的VGG16-SSD网络模型,该网络模型减少了网络参数,能够提升检测速度;同时融合底层特征的高分辨率和高层特征的高语义信息,提高检测准确度,改善模型检测小目标的性能。
为获得更好的玉米穗丝检测网络,考虑到轻量级特征提取器参数较少,可以通过改变特征提取单元修改网络结构的特征提取能力[16]。本文以MFSSD模型为基准,通过增加和减少特征提取层数获得了MF-SSD的另外2种变体结构,分别是MFSSD-add-3和MF-SSD-cut-3。其中,MF-SSD-add-3是对MF-SSD模型的每个阶段增加1层深度可分离卷积,并选取 C4、C7、C14、C16这 4层进行特征融合,将最终生成特征金字塔P4、P7、P14、P16进行多尺度的目标检测;MF-SSD-cut-3是对MF-SSD模型的每个阶段减少1层深度可分离卷积,并选取C2、C3、C8、C10这4层进行特征融合,将最终生成特征金字塔P2、P3、P8、P10进行多尺度的目标检测。图7是3种不同特征提取结构的模型说明。在本文的试验中,把玉米穗丝图像作为输入,通过对比3种不同网络结构的MF-SSD性能来筛选最优网络模型。
1.4 网络训练目标
MF-SSD的训练同时对目标位置和种类进行回归,其目标损失函数是分类损失与定位损失之和,表达式如公式(2)所示。
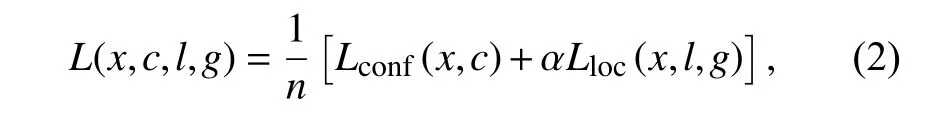
式中,n是与真实框相匹配的预测框个数;Lconf(x,c)是分类损失,采用Sofmax分类器;Lloc(x,l,g)是定位损失,采用Smooth L1 loss[17];x为预测框与不同类别的真实框的匹配结果;c为预测物体框的置信度;l为预测框的位置信息;g为真实框的位置信息;α是2种损失的均衡系数,一般设置为1。

图7 MF-SSD-add-3、MF-SSD和MF-SSD-cut-3的特征提取结构Fig. 7 Feature extraction structures of MF-SSD-add-3, MF-SSD and MF-SSD-cut-3
在训练过程中,减小损失函数值可以确保在提升预测框分类置信度的同时提高预测框的位置准确度,从而训练出性能较好的预测模型。
1.5 解决正负样本数量失衡问题
MF-SSD在各检测层生成不同尺寸的预测框,选取交并比(Intersection over union, IoU)大于0.50的预测框作为正样本,IoU小于0.50的预测框作为负样本。大目标物体上IoU大于0.50的预测框多,正负样本均衡;小目标物体上IoU大于0.50的预测框少,正负样本数量失衡,训练效果不佳。IoU是候选框与正确标记框(Ground truth)的交叠率,即它们的交集与并集的比值,如图8所示。
在VGG16-SSD中使用困难负例挖掘策略从困难样本中选取负样本,实现了正负样本数量1∶3的比例,但却忽略了Loss较小的简单样本。本文认为训练一个有效的网络应该平衡简单样本和困难样本的权重,不能完全舍弃简单样本对Loss的贡献。因此本文使用Lin等[17]提出的Focal loss同时解决正负样本不平衡以及简单样本与困难样本不平衡的问题。Focal loss (FL)的表达式如公式(3)所示。

式中,pt是不同类别的分类概率;αt是[0, 1]区间的小数,用于调节正负例比例,正例为 αt,负例为1- αt;1-pt用于对简单样本进行权重抑制;γ用于平滑权重抑制。对于简单样本,pt较大,权重1-pt较小;而对于困难样本,pt较小,权重1-pt较大。γ和αt都是固定值,本文采用αt=0.25,γ=2。

图8 4种不同类型的样本Fig. 8 Samples of four different types
Focal loss函数可以通过减少简单样本的权重让简单样本对Loss做贡献,但又不主导Loss,使得MF-SSD网络模型在训练时更专注于困难样本的分类。用数据集进行多次结果优化训练模型可不断提高模型的检测性能,从而训练出性能较好的MFSSD检测模型。
2 玉米穗丝目标检测网络的训练
2.1 玉米穗丝图像数据采集
现场采集并结合网络采集共搜集了2 980幅玉米穗丝图像作为模型训练和验证的数据集。其中,现场采集设备使用的是Nikon D7200,使用AFS尼克尔镜头,焦距范围是18~105 mm,该设备使用35.9 mm × 23.9 mm的CMOS图像传感器,有较好的图像采集质量。采集地点选择在重庆璧山种植玉米的农地。为避免所收集数据存在随机性、图片尺寸大小不一、重复率较高等问题,数据输入网络前对图像进行了预处理,去除了冗余图像样本以及目标特征不清等杂糅图像300幅,最终获得有效现场图像共2 200幅,包括吐丝期650幅,灌浆期700幅,成熟期850幅。网络采集图像780幅,包括吐丝期200幅,灌浆期280幅,成熟期300幅。在上述玉米穗丝数据集中,选择2 400幅作为训练集,580幅作为测试集。通过人工对每幅玉米穗丝图像进行标注,圈选出穗丝的真实区域,并标注区域的类别。为降低训练样本多样性不足导致网络过拟合的概率,图像收集过程中采取了一些措施。考虑到温室环境光条件不同会造成成像结果差异,分别搜集晴天和阴天的玉米穗丝图片;考虑到玉米穗丝形态和遮挡情况不同,对不同形态、不同成熟度的玉米穗丝从不同高度(1.0 m、1.5 m、2.0 m),距离(0.50 m、0.75 m、1.00 m)和拍摄方向等多个角度进行搜集,以增加样本的多样性。
2.2 试验环境
试验软件环境操作系统为Window 10,深度学习软件框架为TensorFlow。试验硬件环境CPU型号为IntelCorei7-8750H,内存为16 G,GPU型号为NVIDIA GTX 1 070 (Max-Q Design)。为提高模型的训练效率,本文使用COCO数据集对模型进行预训练,再使用玉米穗丝数据集训练本文模型,能在一定程度上提高用玉米穗丝数据集训练模型的效率[18]。
2.3 数据增广方法
作为一种数据驱动的深度学习模型,训练样本越多,覆盖的对象种类越全面,越能保证MFSSD模型的检测效果。本研究受时间和条件的限制,采集的玉米穗丝数据集样本偏少,故在研究中使用了数据增广技术。数据增广是在保持图像数据标签不变的前提下,对原图像进行变换以获取新的样本。在已有样本的基础上制作更多的图像样本,可以增加样本的多样性,降低网络过拟合的风险。
研究采用的第1种数据增广方法是通过以一定角度(0~180°)随机旋转原始图像来形成新图像;虽然在玉米穗丝图像采集过程中考虑了样本形态、角度等的多样性,但玉米穗丝的生长以及成像角度是随机的;通过随机角度旋转原始图像,可部分消除样本多样性不足的问题;研究在训练集中随机选取了800幅图像进行了这种增广操作。采用的第2种数据增广方法是水平翻转和平移图像;将搜集到的图像进行等比例缩放,然后从缩放后的图像中随机裁剪300像素×300像素的图像作为结果,同时对裁剪结果做随机水平翻转和平移;研究在训练集中随机选取了600幅图像进行了第2种增广操作。
经过数据增广处理,使训练样本的数量增加到了3 800幅,可以增强训练的有效性,同时提高网络推理的泛化能力。
2.4 网络训练策略
本文的网络模型使用二次训练策略。首先用COCO数据集训练本文的网络结构,得到预训练网络模型,保存模型参数。COCO数据集图像目标均有明确信息标注,并具有目标位置以及类别等信息,且单张图像包含丰富的信息,便于目标检测与识别。预训练模型学习率初始值为0.001,网络结构各层参数均初始化为0。然后使用玉米穗丝数据集再次进行训练,先对网络模型参数初始化,对各个特征提取层参数进行赋值,参数来源于COCO数据集预训练模型所产生的参数保存值;训练后输出模型分类检测结果。该策略可提高模型训练性能[19]。
2.5 评价指标
物体检测中,精度的评估通常用平均精度(Average precision,AP)表示,覆盖面的评估通常用平均召回率(Average recall,AR)表示[20-21]。本文采用COCO数据集使用的目标检测评价指标[19]对算法效果进行评测,以期能够客观、全面、多样化地评价本文的检测算法性能。
在评价指标中,AP从2个方面来衡量。其一是从IoU方面,对不同的IoU阈值分别计算AP,再综合得到平均值,比如AP (IoU=0.50~0.95)表示对IoU范围在0.50~0.95、0.05为步长的检测结果分别计算精度并取平均值,AP (IoU=0.50)表示IoU=0.50时的平均精度;其二是以目标在图像中的尺寸为依据来看目标检测精度,本文依据尺寸把目标对象分成小目标、中型目标和大目标,小目标在图像中的尺寸小于32像素×32像素,中型目标在图像中的尺寸在32像素×32像素~96像素×96像素之间,大目标在图像中的尺寸大于96像素×96像素。AR是针对3类不同的目标尺寸分别计算每个图像中的穗丝目标在IoU方面的召回率的平均值。
使用AP和AR指标对算法的检测精度有效性进行评价,是目标检测领域对算法进行评估的常用方法[10,22],能较好地体现模型的检测性能。本试验使用该指标分析各个网络模型对小目标的检测效果和对所有目标的平均检测精度,优选出适合于玉米穗丝检测的网络模型。
3 结果与分析
3.1 检测性能分析
利用玉米穗丝的数据集进行训练和测试,用对VGG16-SSD、MobileNet-SSD、MF-SSD、MF-SSD-add-3、MF-SSD-cut-3的训练结果分别进行检测,选取的置信度阈值为0.50,即所有检测出物体的类别置信度均在0.50以上。检测结果如表1所示,检测时间表示在300像素×300像素图像上的检测时间。
由表1可知,MobileNet-SSD在检测精确度上略低于VGG16-SSD网络,但仍表现出良好稳定性与精确性,在基本保证准确率的情况下减少了计算时间和参数数量。使用MF-SSD网络模型时,在IoU取0.50时,其AP可达到96.6%,与VGG16-SSD模型基本一致,但在高IoU(0.50~0.95)下的AP相比VGG16-SSD提高了7.2%。在小目标检测精度上,相比VGG16-SSD模型,MF-SSD有20.4%的提高,对玉米穗丝小目标检测的AR提高了19.6%,说明把浅层的细节特征和高层的语义特征融合起来能够提升算法对小目标的检测能力。从统计的数据分析来看,本文所提出的MF-SSD模型及其变体的检测效果均比VGG16-SSD和MobileNet-SSD模型更好。
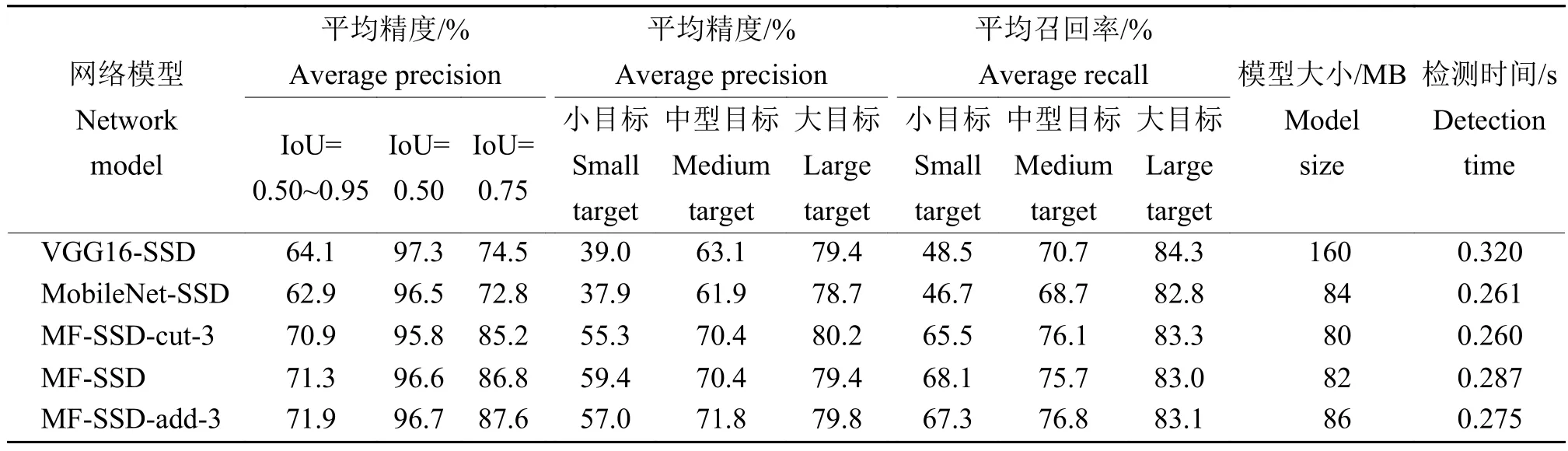
表1 不同网络模型试验结果对比Table 1 Comparison of experimental results of different network models
分析MF-SSD模型变体的检测试验数据可知,与MF-SSD相比,MF-SSD-add-3的AP略有提升,但对小目标的AP下降了2.4%;MF-SSD-cut-3在不同IoU取值下的检测性能要弱于MF-SSD,但差距在1%以内,而对大目标的AR还要高出0.3%。从模型尺寸的角度来说,MF-SSD-cut-3的最终模型是最小的。同时,在检测时间方面,在不同变体的改进模型中MF-SSD-cut-3耗费时间最少,与VGG16-SSD模型相比速度提升了18.7%。
综合上述结果,玉米穗丝目标检测的最终网络结构的选择方法是:在存储空间和运行时间有较高要求的嵌入式环境下,选择MF-SSD-cut-3模型可以在满足检测效果的前提下,以较小的空间代价获得相对较快的运行时间;在不考虑空间和时间的情况下,则可以选择MF-SSD模型以获得更好的检测效果。
3.2 不同训练策略对训练结果的影响
为分析不同训练策略对模型训练的影响,本文对是否使用二次训练策略和是否使用Focal loss解决样本不平衡问题进行了试验,并比对分析Loss的下降过程。
图9的4种策略中,MobileNet-SSD未使用二次训练策略和使用二次策略的模型结构完全相同,两者区别在于是否使用COCO数据集预训练网络模型,对这2种网络的训练误差下降过程进行了比较。结果表明,使用二次训练策略情况的训练误差降落速度快于未使用二次训练策略的训练方法,同时其损失百分比更小,说明使用二次训练策略更利于模型收敛。MF-SSD使用困难负例挖掘策略和使用Focal loss策略的区别在于解决不平衡样本的策略。结果表明,在学习率相同的情况下,MF-SSD网络使用Focal loss能让网络更容易收敛,收敛速度加快,并且误差收敛到较小的值;使用困难负例挖掘时,Loss值的降落速度较慢,震荡幅度较大,不易收敛。因此使用二次训练策略和Focal loss更利于MF-SSD模型的训练,训练出性能更好的检测模型。图10是使用MF-SSD检测的结果例图。

图9 不同训练策略误差比较Fig. 9 Error comparison of different training strategies

图10 MF-SSD检测结果示例Fig. 10 MF-SSD test result example
4 结论
本文通过改进目标检测算法SSD的不足之处,在玉米穗丝检测的应用方面进行了试验研究和分析,提出一种基于MF-SSD卷积神经网络的玉米穗丝检测网络模型。在原始VGG16-SSD的基础上,用MobileNet替换特征提取器,并加入多层特征融合结构改进MobileNet-SSD,得到MF-SSD网络模型;同时,根据不同应用场景的需求设计了3种结构的MF-SSD网络。在玉米穗丝训练样本上,通过多种数据增广技术,对每种网络分别进行训练,优选一种网络模型作为玉米穗丝检测网络模型。研究结论如下:
1)特征层融合的方式能够显著提高检测网络的检测能力,提高对小目标的检测精度和召回率。与VGG16-SSD相比,MF-SSD在高IoU (0.50~0.95)下的AP提高了7.2%,对小目标的AP提高了20.4%,对玉米穗丝小目标的AR提高了19.6%,并且降低了模型尺寸,提高了识别速度。MF-SSD玉米穗丝目标检测网络结构具有较高的检测性能,能够有效用于玉米穗丝的检测。
2)在存储空间和运行时间有较高要求的嵌入式环境下,选择MF-SSD-cut-3模型可以在满足检测效果的前提下,以较小的空间代价获得相对较快的运行时间;在不考虑空间和时间因素的情况下,可以选择MF-SSD模型获得更好的检测效果。
3)二次训练策略可提高网络的收敛速度,提高模型的稳定性和健壮性;Focal loss能够有效解决SSD算法中正负样本数量不平衡问题,使网络模型的训练更容易收敛。
猜你喜欢
少儿科学周刊·儿童版(2021年21期)2021-12-11
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年13期)2020-01-14
小天使·二年级语数英综合(2019年10期)2019-11-08
电子制作(2019年11期)2019-07-04
领导决策信息(2018年16期)2018-09-27
北京航空航天大学学报(2018年1期)2018-04-20
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
