
基于优化BP神经网络的TBM性能预测
2020-12-02 01:18赵光祖王亚旭李尧徐受天陈帅
河南理工大学学报(自然科学版) 2020年5期
赵光祖,王亚旭,李尧,徐受天,陈帅
(1.山东大学 岩土与结构工程研究中心,山东 济南 250061;2.中铁工程装备集团有限公司,河南 郑州 450016)
0 引 言
隧道掘进机(tunnel boring machine,TBM)开挖隧道具有掘进速度快、安全性高、劳动强度低、工程质量好、经济和环保等优势,因此,广泛应用于开挖地下通道工程[1],尤其对于修建长大输水隧洞工程,TBM已成为输水隧洞快速开挖的首选施工设备。可靠有效的TBM性能预测研究对于隧道施工的施工方法选择、工期规划和成本控制十分重要。近年来,TBM性能预测研究成为热门研究课题,针对TBM性能预测方法,国内外学者已经开展了多方面的研究,并建立多种TBM 性能预测模型。
TBM 性能预测模型分为经验模型和理论模型。经验模型主要依据现场施工资料,但是由于不同工程地质条件的特殊性,不具有普遍性。经验模型中最著名的是挪威科技大学开发的 NTNU 模型,但该模型需特殊试验以获取模型中的输入参数,适用性限制很大。理论模型中最著名的是科罗拉多矿业学院开发的 CSM 模型[2]。该理论模型基于压痕试验或室内全尺寸切割试验,结合刀具受破岩机制,获得刀具力平衡方程从而进行性能预测。除经验和理论模型外,一些学者还应用岩体分级系统建立 TBM 性能预测的经验模型[3-5]。近年来,支持向量机、神经网络、粒子群等人工智能算法逐渐引入TBM性能预测研究中。例如S.Mahdevari等[6],S.Yagiz等[7],A.C.Amoussou等[8]分别使用支持向量回归分析,粒子群优化,贝叶斯算法预测纽约市皇后水隧道的TBM掘进速度;Zhao Z等[9]使用集成神经网络研究新加坡DTSSs隧道的围岩可掘进指数(SRMBI),预测值与实际值的相关系数达0.81,并分析了网络各输入对SRMBI 的影响;A.G.Benardos 等[10]基于雅典地铁隧道数据,应用双隐藏层神经网络进行TBM性能预测,误差在10%以内。然而,神经网络存在固有缺陷,应用于TBM性能预测研究仍需改进优化。
BP神经网络是目前应用最广泛的神经网络,非线性映射能力强。传统的BP网络通过梯度下降法处理反向传播的误差获得最优解,但梯度下降法往往会陷入局部最优而达不到理想效果。模拟退火算法和遗传算法是两种全局搜索算法,对于解决具有多个局部最优的非线性问题非常有效[11]。因此,本文提出使用遗传算法和模拟退火优化的BP神经网络预测TBM掘进速度。以机器参数和岩体参数为输入,TBM掘进速度为输出,构建模拟退火神经网络(SA-BP)预测模型和遗传算法神经网络(GA-BP)预测模型,并基于吉林引松工程数据进行验证,以期获得可靠的TBM性能预测模型服务于实际工程。
1 性能预测方法
1.1 BP神经网络
BP神经网络[12]是误差反向传播的神经网络,由Rumelhart于1988首次提出。神经网络各层节点间的计算式为
式中:Hj,Ok分别为隐藏层和输出层的输出;fhid,fout分别为隐藏层和输出层的激活函数;wij为连接输入层和隐藏层各神经元间的权重;bj,bk分别为隐藏层和输出层的阈值;m,l分别为隐藏层和输出层的神经元数目;xi为网络输入,x1,x2,x3,…,xn组成一组输入。
作为BP网络的输入,TBM机器参数和岩体参数数据属性各异,量纲不同且数量级差距大,因此,训练前对各个属性的数据需做归一化处理。归一化方法见式(2),

(2)
式中:xmax和xmin分别为各属性数据归一化前的最大值和最小值;x′为输入数据归一化后的值。
BP网络训练的目标是获取一组权值阈值,使输出值与实际值之间的误差最小。本文将掘进速度的预测值与实际值间的均方差(MSE)作为损失函数,见式(3),

(3)

1.2 模拟退火-神经网络(SA-BP)算法
模拟退火是一种启发式随机搜索方法,它模拟物理退火过程的自然机制,并引入足够的随机因素[13]。在与BP网络的联合中,全部权重阈值组模拟退火的一个解。给当前解Xold的随机扰动产生新解Xnew,

(4)
式中:t为当前温度;T为初始温度;R为[-1,1]中的随机数。
前期扰动较大,算法即将结束时,扰动很小,保证了稳定性。
通过比较当前解与新解的损失函数值Enew,Eold,以一定概率接受一个比当前解要差的解,新解接受按照式(5)Metropolis准则[14],

(5)
随着t降低,接受概率p也会逐渐降低。t较高时,若此时搜索到局部最优解,较差解仍有较大概率被接受,这使得算法最初有较大概率跳出局部最优。随着温度降低,算法接受差解的概率降低。温度下降系数θ一般为[0.95,0.99],温度下降方式见式(6),
t′=t×θ,θ∈[0.95,0.99],
(6)
式中,t′为下降后的温度。
温度每下降一次,需在当前温度下设置合适的内循环迭代次数[15],保证算法可以在搜索空间内充分选择。算法终止后,优化得到的权值阈值作为BP神经网络的初始权值阈值,然后BP网络训练直至收敛,SA-BP算法流程见图1。

图1 SA-BP算法流程
1.3 遗传算法-神经网络(GA-BP)算法
遗传算法借鉴了生物界的进化规律,采用概率化的寻优方法,能自动获取和指导优化的搜索空间,并自适应调整搜索方向[16]。在GA-BP中,神经网络的所有权值阈值构成种群中的个体,初始化生成若干组权值阈值构成初始种群。初始种群通过交叉变异不断淘汰适应度差的个体,最终获得最优个体。GA-BP算法流程见图2。

图2 GA-BP算法流程
应用遗传算法的首要问题是对个体信息进行编码,即将所需优化参数编码为G(g1,g2,g3,…),G为完整的染色体,g为染色体上的基因。本文采用浮点数编码方法[17],编码完成后进行选择交叉变异,具体操作如下。
(1)选择:评价个体表现的适应度函数选取为MSE的倒数,
F=1/MSE,
(7)
个体适应度值越大,越容易保留在下一代的种群中。采用轮盘赌方法,个体被选择的概率为该个体适应度与种群总适应度的比值,

(8)
其中Fi为i个体的适应度值。
(2)交叉:
g′B=βgA+(1-β)gB,
g′A=αgB+(1-α)gA,
(9)
式中:α,β为(0,1)内的随机数;gA,gB为交叉前的基因;g′A,g′B为交叉后的基因。
(3)变异:本算法采用随机变异,当产生(0,1)内的随机数小于变异率时,将随机选择父代遗传信息中的某一个基因,将其设置为基因上下限范围内的一个随机数。
2 算法实现
2.1 模型输入变量优选
建立TBM性能预测模型,首先选取与掘进速度最相关的因素。TBM的机器参数超过100 种,岩体力学参数也有多种[18]。其中,岩石的单轴抗压强度(UCS)、岩石的耐磨性、岩体结构面发育程度及主要结构面产状与隧道洞轴线方位的夹角(α,下文简称节理夹角)等是TBM效率能否发挥的主要影响因素[19]。刀盘转速(RPM)和掘进速度(ROP)是TBM主司机的主要控制参数;滚刀推力(T)、刀盘扭矩(Tor)、贯入度(Pe)是主司机控制 TBM 的主要运行参数[20-21]。刘泉声等[2]统计了17 个国内外模型中岩体参数的使用频率,所有岩体参数中使用频率最高的是表征不连续面信息的节理夹角(α)、岩石脆性指数(Bi)和岩石质量指标(RQD)。综合理论基础及国内外预测模型,本文将UCS,RQD,α,Bi,T,Tor,P,RPM作为神经网络的输入,ROP为输出,如图3所示。

图3 神经网络结构
2.2 模型的超参数调整
BP网络结构中输入维度为8,输出维度为1。参照式(10)[22]选择隐藏神经元数,将神经元个数设定为4~14,通过MSE确定最佳的隐藏层神经元数。

(10)
式中:h为隐含层节点数;m为输入层节点数;l为输出层节点数;k为1~10的调节常数。
根据表1,隐藏层神经元为12时最优。故本文的神经网络设计为8-12-1的结构,并选取双曲正切tansig函数作为传输函数。遗传算法和模拟退火的参数设置见表2。
3 工程应用
3.1 工程概况
吉林省中部城市引松供水工程为自流输水隧洞,输水总干线全长109.687 5 km,高程264.0~484.0 m,隧道最大埋深260 m。主要采用TBM工法和钻爆法施工。取水口位于丰满水库,途经温德河、岔路河到饮马河分水干线。施工四标段位于吉林市岔路河至饮马河之间,总长229 55 m。TBM施工段采用中铁装备生产的 “永吉号”TBM进行开挖,开挖断面为圆形[23]。“永吉号”TBM的具体设计参数见表3。

表1 隐藏层节点数对应误差
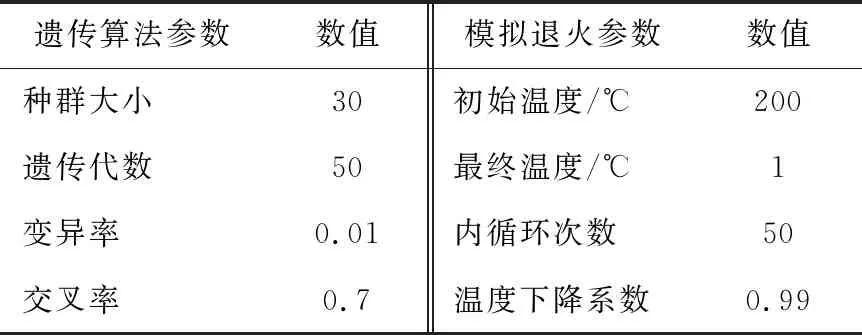
表2 模型的参数设置

表3 吉林引松供水工程TBM设计参数
3.2 工程数据
岩芯取自四标段的180个桩,岩体参数由室内试验获得,TBM机器参数数据由中铁装备TBM数据云平台获取,数据详细信息见图4。
为验证模型的泛化能力,将数据等分为6个无重叠的数据集,如图5所示。150组数据用于五折交叉验证,剩余30组测试交叉验证中的最优模型。
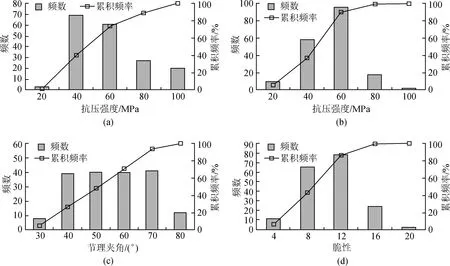

图4 网络输入变量频率分布
4 试验结果
如图6所示,经过3 000步迭代,BP模型收敛于0.010 22便陷入局部最优,误差不再下降,SA-BP模型与GA-BP模型较BP模型收敛速度更快,最终分别收敛于0.001 02和0.001 04。经过模拟退火和遗传算法优化,预测模型可以减小一个数量级的误差,实现更高的预测精度。

图6 误差收敛对比曲线
如表4所示,BP模型、GA-BP模型和SA-ANN模型在验证集上的MAPE分别为16.45%,9.87%和9.62%,在测试集上分别为19.15%,11.79%和11.55%。GA-BP模型、SA-BP模型在验证集和测试集上预测精度较BP模型分别提升7%,8%左右。

(11)


表4 模型的预测精度
图7~8为3个模型在测试集上的TBM掘进速度真实值与实际值的对比。由图7~8可知,GA-BP和SA-BP模型明显优于BP模型,特别是在掘进速度值变化较大时,BP模型表现较差。在图7~8标记的4个数据上,BP模型的误差分别为17.25,13.33,12.62,8.45;GA-ANN的误差为8.53,7.12,4.51,7.32;SA-BP的误差为9.78,5.26,4.56,5.32。结果表明GA-BP模型和SA-BP模型能较好预测测试集的每个数据。

图7 BP模型的预测值与实际值

图8 改进BP模型的预测值与实际值
5 结 论
(1)通过经验公式确定隐含层神经元节点数为12时,模型效果最好。BP神经网络在模拟退火和遗传算法的优化下在验证集和测试集上预测准确率分别提升7%和8%左右。SA-BP和GA-BP模型的预测精度分别达到了88.45%和88.21%。
(2)BP神经网络经模拟退火算法与遗传算法优化后,模型在预测时对于数据不挑剔,泛化性较好。前后两个数据点变化较大时,也可以较好地预测。
(3)本文数据仅来源于同一工程,后续研究中仍需积累多个工程数据,尝试更多的智能算法训练TBM性能预测模型,以期开发出更为准确、可靠的预测模型。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
现代电力(2022年2期)2022-05-23
汽车工程(2021年12期)2021-03-08
中国金属通报(2020年2期)2020-06-30
电子制作(2019年19期)2019-11-23
电子制作(2019年16期)2019-09-27
电子制作(2019年24期)2019-02-23
电子制作(2019年24期)2019-02-23
软件(2017年7期)2018-01-24
软件(2016年3期)2016-05-16
