
一种基于集成学习的用户基础属性预测方法
2020-12-09 09:27孙践知张青川
小型微型计算机系统 2020年12期
王 曼,曹 倩, 孙践知, 张青川, 徐 菲
(北京工商大学 计算机与信息工程学院,北京 100048)
1 引 言
随着移动互联网的发展,智能手机已经逐渐成为人们拥有最多的移动设备.目前国内应用商店中可用App数量已经超过四百万个,人们安装及使用App的情况通常与他们的性别、年龄等基本属性密切相关,能够反映用户的基本属性、兴趣偏好、生活习惯等个人信息[1].用户属性的深入挖掘可以丰富用户画像,帮助企业深入了解用户从而有针对的推荐产品,还能帮助企业个性化投放互联网广告,提升广告投放效果.
在个性化推荐和广告定向中,用户的搜索内容、浏览记录、地理位置信息和基础属性等均发挥着重要作用,其中基础属性性别、年龄至关重要,但并非所有用户都愿意公开自己较为隐私的基础属性信息,此类信息不容易获取,需要结合现有数据及相关算法进行预测.
很多学者通过分析用户的搜索、浏览等互联网行为数据获取用户的人口统计信息.Hu等[2]根据用户浏览的网页信息,结合贝叶斯网络算法对用户的性别及年龄进行预测;Bock等[3]根据用户的网页点击行为中提取特征,结合随机森林算法构建模型,对用户的性别、年龄、教育程度等属性进行预测,并将预测结果用于网页在线广告的定向投放;鹿迅[4]以微博用户为研究对象,基于用户昵称、标签、微博文本等对用户的性别、年龄分布以及教育程度进行预测推测;宋巍等[5]提出根据微博用户的兴趣偏好建模,从而推断用户的隐藏属性.
近年来,逐渐有学者开始利用手机应用相关数据进行用户属性预测的研究.Seneviratne等[6]首次基于用户手机安装的应用列表数据推断用户特征,利用支持向量机方法预测用户的宗教信仰、人际关系、感兴趣的国家等;Yilei等[7]通过分析用户手机安装的App,提出一种将贝叶斯和协同过滤相结合的用户年龄预测算法;赵莎[8]通过分析移动终端应用的安装数据,提出挖掘用户属性的框架,使用支持向量机算法对用户属性进行预测.Zhao等[9]通过分析用户一个月手机App的使用记录,对用户使用App行为的相似性进行研究,提出特征排序、两步聚类的方法,挖掘出382类不同的用户群体.
综上所述,一方面,目前已有研究主要是基于用户安装的App进行基础属性预测,对用户App使用数据的特征挖掘较少且较为粗糙,对用户使用App的时长、频率以及App使用的序列缺乏深入的分析;另一方面,现有研究主要采用SVM、贝叶斯等传统机器学习方法,集成学习作为机器学习的重要部分也逐渐被应用于用户属性预测领域.但是,现有基于集成学习的算法也有一些不足之处,如集成学习在问题划分过程中会有一定程度的信息损失,最终的模型融合是一个复杂、耗时的参数调整过程等.针对目前算法的不足,本文主要做了以下工作:
1)提出一种基于集成学习的用户属性预测算法,首先将原问题转化为多个二分类问题,每个二分类问题侧重于对某个具体属性进行预测,数据标签和特征的较大差异保证了不同二分类器间的差异性;;然后将多个二分类器的预测概率结果与原始数据集结合进行多分类模型的学习,实现二分类器的融合,以获得整体预测精度的提升;
2)将LightGBM和FM融合构造二分类器,利用LightGBM自动对特征的进行挑选、组合,提取出高阶特征;进一步将高阶特征作为FM模型的输入,二分类器的准确率得到提升;
3)根据用户App安装和使用数据构造了基础统计特征、用户App使用偏好特征、Applist2vec特征,充分反映了用户的安装偏好、使用时长及频率,为我们的研究提供了可靠的基础.
2 算法设计
2.1 基于集成学习的多分类框架
本文所提出的算法基于集成学习多分类框架,由两部分构成.首先将原问题划分为多个二分类问题,分别提取特征并训练得到多个二分类器;然后把多个二分类器的预测概率与原数据特征进行结合得到新的特征,再进行多分类器的训练.具体过程如图1所示.

图1 集成分类算法框架图Fig.1 Framework diagram of integrated classification algorithm
首先将原始多分类问题划分为多个二分类问题,这一过程需要将数据集标签进行转换,将多分类数据标签转换为对应的二分类数据标签.以本文数据为例,原始数据标签中将年龄划分为11个年龄段,是一个多分类问题,本算法需要将用户年龄标签转为和二分类器对应的二分类标签,即年龄区间1、非年龄区间1,年龄区间2、非年龄区间2等,不同二分类数据集之间仅数据标签的不同,其他数据不做改变.
对每个二分类数据集提取特征,并输入对应二分类器,得到并保留各分类器对训练集的预测概率,为避免边缘信息及整体信息的丢失,将得到的预测概率与原始特征进行合并,将合并后的新特征输入最后的多分类器.从而实现将原本模型的融合转为自动学习的过程.
2.2 基于集成学习的用户基础属性预测算法
本文通过分析一定数量的性别、年龄已知的用户手机安装的App安装、使用等数据,对其他用户的性别和年龄进行预测.用户的性别预测是一个二分类问题,用户的年龄被划分为11个年龄段,预测年龄是一个多分类问题.
将上述分类框架应用于用户基础属性预测问题,给出一种基于集成学习的用户基础属性预测算法.首先,性别预测是一个二分类问题,需要将用户年龄预测转为多个二分类问题,需要将数据集中年龄标签根据对应的二分类器转为年龄区间1、非年龄区间1的模式.然后,对于二分类器部分,考虑到现有的机器学习方法如决策树、SVM等需要大量人工经验对训练样本进行特征挑选和组合,采用LightGBM+FM模型实现框架中二分类学习.最后,结合集成学习中stacking的思想,将二分类器预测的概率与原特征结合,拼接为新特征输入到多分类器中进行训练.具体过程见算法1.
算法 1.基于集成学习的用户基础属性预测算法
输入:原始数据集S
1.将原始数据划分为12个二分类数据集,其中包括1个性别二分类和11个年龄二分类,不同二分类数据集之间仅数据标签的不同;
2.对12二分类数据集分别提取特征,输入到二分类器进行训练,得到预测概率;
3.将预测概率与原特征进行拼接,得到新的训练子集特征为{原特征,概率1,概率2,……,概率12};
4.将性别和年龄进行组合,问题转化为一个多分类问题.新的训练子集输入到多分类器进行训练,输出结果.
2.3 基于LightGBM和FM模型的二分类器
2.3.1 LightGBM
LightGBM[10,11](Light Gradient Boosting Machine,轻量级梯度提升,简称LGB)是GBDT(Gradient Boosting Decision Tree,梯度提升决策树,简称GBDT)的一种高效实现方式,针对GBDT存在的容易过拟合、训练速度慢等问题,2016年微软公布了LightGBM,主要从直方图算法和带深度限制的Leaf-wise决策树生长策略优化GBDT,减小数据储存和执行计算时的成本,保证高效率的同时避免发生过拟合.
利用LightGBM模型来提取高维组合特征[12],将特征集输入LightGBM模型中进行训练,在LightGBM模型中对训练样本进行五折交叉预测,计算每个训练样本是否属于每个决策树的叶子节点,属于的叶子节点记为1,其他的叶子节点记为0,提取高维组合0-1特征向量为:
x′i=g(xi,θ)num_tree×num_leaves
(1)
其中,x′i表示第i条训练样本的高维组合0-1特征向量,xi表示第i条训练样本的特征向量,g(·)表示LightGBM分类器的叶节点,当该第i条样本属于该叶节点时取1,否则取0;num_tree表示LightGBM模型中决策树的数量,num_leaves表示每棵决策树上叶子节点的数量.
2.3.2 FM
因子分解机模型[13,14](Factorization Machine,简称FM)由Rendle在2010年首次提出,将矩阵分解和支持向量机算法的优势进行结合,对变量之间的交互进行建模,可以有效解决高维稀疏数据下特征组合的参数学习不充分问题,提高预测准确率,模型表示为:
(2)

(3)
通过随机梯度下降(SGD)方法对FM模型进行训练,模型中各参数的梯度表示为:
(4)
2.3.3 LightGBM+FM融合模型
Facebook提出GBDT和LR融合模型[15]并应用在广告点击率预测中,通过GBDT进行非线性特征转换,生成新的特征后提供给LR进行最终预测,融合模型比单一模型的预估准确度提升了3%左右.类比于GBDT+L融合模型,本文将LightGBM模型和FM模型进行融合,构建二分类器.首先利用LightGBM自动对特征的挑选及组合,生成高阶特征;进一步将高阶特征输入FM模型中,二分类模型算法框架见图2.

图2 二分类模型算法框图Fig.2 Block diagram of the binary classification model algorithm
算法 2.基于LightGBM和FM模型的二分类算法
1.将原始数据进行预处理,转化为多个二分类数据集;
2.对每个二分类数据集进行特征提取;
3.将特征输入LightGBM模型进行训练,把模型中每棵树计算得到的预测概率值所属的叶子节点记为1,其他叶子节点记为0,提取出高维组合特征;
4.将LightGBM提取的特征导入FM分类器中进行训练;
5.输出二分类结果.
3 实验结果及分析
3.1 数据集介绍
本文数据来源于国内某应用商店真实数据,主要包含用户App安装数据、App使用数据、App类别数据、基础属性数据.App安装数据是每个设备上安装的App列表,共5万条;App使用数据是在一定时期内每个设备上各个应用的打开、关闭行为数据及对应时间点,共104万条;App类别数据是每个App的类别信息,共分为46类;基础属性数据是每个设备对应用户的性别和年龄段,性别编号1、2分别表示男和女,年龄段编号有0-10共11种,分别表示用户不同的年龄段,年龄段编号越大表示用户年龄越大.一个用户只属于唯一的类别(性别-年龄段),组合后的性别-年龄段共有22个类别,记为sex_age.
sex_age=(sex-1)·11+age
(5)
其中,sex表示用户性别,取值1、2分别表示男和女;age表示用户年龄段,取值0-10分别表示用户不同的年龄段.数据集中用户基础属性性别及年龄段编号方式及分布如表1所示.

表1 用户基础属性分布Table 1 Demographic attribute category information
3.2 数据预处理
首先我们对数据集中的异常数据进行过滤,过滤方案包括:
1)用户App使用时间:从解析出的时间戳可知,用户打开关闭App的时间包含了少量1970、1975以及2025年这种异常年份的数据,绝大部分的数据都来自于2017年2-3月,因此我们也只保留了2-3月的数据,其他月份的数据视为噪音;
2)用户每天使用时长:小时数过少可能是用户数据采样过程中存在问题,删除使用时长小于0.5小时的用户行为数据记录;
3)App被安装次数:对于某些只有极少用户安装的App,对用户分类意义较小,所以剔除安装用户少于5人的小众App.
3.3 特征提取
3.3.1 统计学基本特征
根据用户的App安装、使用数据和App类别信息,统计得到App安装特征、App使用特征见表2.
3.3.2 基于TF-IDF加权信息增益的特征
为了进一步衡量不同基础属性的用户对App的使用偏好,结合信息增益和TF-IDT构造了用户App使用偏好特征.首先基于信息增益提取每个属性下的重要App,然后利用TF-IDF对App的使用集合提取特征.
1)基于信息增益发现重要App
基于用户安装的App列表,如果利用全部的App构造one-hot特征,维度过高且稀疏性较大.并且用户安装的大量App中,每个App的重要程度是不同的,可能存在大量对用户属性贡献较低的App,影响用户属性的挖掘及计算效率的提升.所以,我们需要知道对于用户基础属性性别及年龄的分类来说,哪些App是重要的及对应的重要程度.

表2 基本统计特征Table 2 Basic statistical features
所以,根据用户App安装数据,对每一个用户属性,计算各App的信息增益值并进行排序,信息增益值越大表明App越重要.一个手机AppA对一个特定用户属性Φ的信息增益[16]可以表示为:
IG(Φ,A)=H(Φ)-H(Φ|A)
(6)
其中,H(Φ)表示这个特定用户属性的信息熵,H(Φ|A)是指在AppA固定条件下的信息熵.基于用户安装的App列表及属性信息,我们可以计算得到在性别和年龄属性下每个App的信息增益,取属性Φ下信息增益排名前100的App,得到信息增益值排名前100的重要App及对应的信息增益,即:
IG(Φ)=(IG1,…,IG100)
(7)
2)TF-IDF
TF-IDF[17]是一种常用于文字信息检索的通用统计分析方法,可以表示某一个字词在一个文件集或语料库中某个文件的重要程度.某字词的重要程度一般与其在文件及语料库中出现的频率高低有关,在文件中出现的频率越高且在语料库中出现的频率越低,则该字词越重要.
根据用户App使用数据,将用户一段时间内使用的App集合看作一篇文档,将每个App视为文档中的文字,利用TF-IDF计算重要App的TF-IDF值,公式为:
(8)
其中,ni,j是Appi在用户App使用集合dj中的数量,∑knk,j是用户App使用集合dj中总的App数量,|D|是用户App使用集合的总数即用户总数,|{j:wi∈dj}|是包含Appi的App使用集合数.
所以,100个重要App的TF-IDF为:
TFIDF=(TFIDF1,…,TFIDF100)
(9)
与信息增益值相乘,得到100维的TF-IDF加权信息增益特征,记为TFIDF_IG,即:
TFIDF_IG=TFIDFi·IGi(i=1,2,…,100)
(10)
3.3.3 基于Word2vec的Applist2vec特征
Word2vec[18,19]是由Google公司2013年发布的一个DeepLearning学习工具,利用神经网络模型,学习一个函数可以将文档中的单词映射到向量.类比于词和文本建模,我们把每个App视为一个词,每个用户一段时间内使用App的序列视为一个文档集,利用Word2vec中Embedding层提取特征,可以得到降维后的App向量矩阵.一方面可以考虑用户使用App的顺序关系,另一方面降低了矩阵的稀疏性、提高了计算效率.Applist2vec特征的训练过程如图3表示.

图3 Applist2vec特征的训练过程Fig.3 Applist2vec feature training process
word2vec有CBOW(continuous Bag-of-words)和Skip-gram两种网络结构,本文利用基于CBOW的词向量模型提取用户使用的App序列特征,词向量模型如下.
1)已知中心词wt和上下文Context(wt),其中context(wt)={wt-k,…,wt-1,wt+1,…,wt+k},k为窗口大小.基于层次softmax的CBOW方式,我们需要最终优化的目标函数是:
ζ=∑logp(wt|Context(wt))
(11)
2)定义一个正类和负类的公式为:
(12)
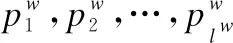
3)条件概率p(wt|Context(wt))一般写为:
(13)
其中:
(14)
4)得到目标函数为:
(15)

3.4 评价指标
3.4.1 基础指标
本文采用准确率(Acc)、召回率(Rec)、F1值、AUC来量化评价二分类器的性能.准确率Acc表示分类正确的样本数占全部样本数的百分比,Acc越大,表示分类器越好.精度Prec表示正确预测为正样本的数量与所有预测为正样本数量的比值.召回率Rec表示正确预测为正样本的数量与正样本的实际数量.F1值是精度和召回率的权衡.各评价指标的计算方法为:
其中,TP(True Positive)表示实际为正样本,且被模型预测为正样本的具体数量;TN(True Negative)表示实际为负样本,且被模型预测为负样本的具体数量;FP(False Positive)表示实际为负样本,却被模型预测为正样本的具体数量;FN(False Negative)表示实际为正样本,却被模型预测为负样本的具体数量.
3.4.2 损失函数
针对本文的用户属性预测多分类问题,为了明确评估本文模型的精准性,采用损失函数logloss评估分类精度,损失函数Loss为:
(16)
式中:N是测试集包含的用户数量,j是用户性别-年龄组编号,yij是一个布尔值,表示用户是否属于这一年龄-性别组;pij是由模型计算出的用户属于这一年龄-性别组的概率.损失函数越小表示模型的预测精确度越高.
3.5 实验结果
3.5.1 实验1.Applist2vec特征
利用Word2vec模型,结合用户App使用数据构造Applist2vec特征,用实验验证该特征的效果.实验Word2vec模型的参数包括:特征向量维度为200;考虑当前使用的App与前、后使用的各4个App,上下文窗口设置为8;模型选用的是CBOW网络结构;训练采用自适应学习速率.
利用LightGBM算法,对只有Applist2vec特征、只有其他特征以及Applist2vec特征和其他特征相结合3种情况进行实验,对比3种特征情况下性别-年龄这个多分类问题的准确率,实验结果如表3所示,利用Applist2vec特征的分类准确率高于其他特征,Applist2vec特征与其他特征结合后的损失函数最低为2.5969,准确率最好,证明了该特征的有效性.

表3 Applist2vec特征效果验证Table 3 Verification of Applist2vec feature effect
计算各特征在分类过程中重要性,排名前50的特征如图4所示,排名前50的特征中Embedding特征有26个,占比达到52%,可见该特征的重要性.除此之外,排名前10的重要特征还包括App安装总数量、用户使用App的最早时间、用户在6点时段App使用总时长、用户平均弥天打开App的次数、加权TFIDF信息增益特征.

图4 特征重要性得分图Fig.4 Feature importance score
3.5.2 实验2.LightGBM+FM二分类算法
以多个二分类问题中性别预测为例,分别利用XGB(Extreme Gradient Boosting,简称XGB)、LGB、LGB+LR、XGB+LR、LGB+FM进行实验,以验证二分类器的效果.在设置LightGBM和FM模型参数时,我们选择使用Python库中的GridSearchCV方法,对模型进行参数进行交叉验证以选择出合适的参数,实验设置LightGBM模型的迭代次数为100,叶节点数量限制为32,学习率为0.05,叶子中的最小数据量为200,特征提取比例0.4,树的最大深度8.
利用LightGBM算法,将原特征转化为3200维特征,然后输入到FM模型中进行二分类.设置FM模型的最优迭代次数为246,学习率0.001,采用交叉熵损失函数进行训练.实验结果如表4所示.

表4 性别预测二分类算法比较Table 4 Comparison of gender prediction binary classification algorithms
从表4可以观察到仅用一个模型时,LGB模型在各项指标中优于XGB模型,LGB与LR模型融合后,融合模型在各项指标上均有提升;LGB+FM融合模型效果最优,准确率达到67.65%,AUC值为0.6791,证明将LGB和FM融合模型作为二分类基分类器是效果最好的.
3.5.3 实验3.集成多分类模型
我们对本文提出的基于集成学习的用户属性预测算法的有效性进行验证.将12个二分类器中的用户App使用偏好特征进行合并,同时将12个二分类器的预测结果、基本统计特征、Applist2vec特征拼接到特征集中,得到新特征集为{基本统计特征,Applist2vec特征,合并后的用户App使用偏好特征,概率1,概率2,……,概率12}.将新特征集重新输入到多分类器LGB中进行训练,得到性别-年龄组预测结果.
进一步,为验证本文算法特征融合的有效性,将旧特征集{基本统计特征,Applist2vec特征,用户App使用偏好特征}利用LGB、XGB、随机森林算法进行实验,得到实验结果如图5所示.

图5 用户性别-年龄多分类预测Fig.5 Multi-Classifier prediction of user gender-age
由图5可知,利用本文构造的特征,直接利用LGB、XGB、随机森林算法进行性别-年龄多分类预测时,LGB效果较好.同时,本文算法将多个二分类器预测结果进行融合后,与LGB相比,本文算法的损失函数最小,性别-年龄分类预测准确率最高,说明了前期二分类任务的必要性,进而证明了本文算法的有效性.
4 结束语
针对现有的基于用户App相关数据预测用户属性算法的不足,本文提出基于集成学习的多分类算法以对用户的性别、年龄进行预测.首先将原问题转化为多个二分类问题,并借助LightGBM+FM实现二分类学习;然后把多个二分类器的预测结果与原特征结合,进行多分类的学习.实验结果显示:二分类方面,LightGBM+FM可以实现特征的自动挑选和组合,具有较高的精度;多分类方面,本文提出的算法准确率明显高于其他集成模型,验证了本文模型的有效性.此外,本文目前只对性别及年龄进行预测,后续若补充更多的属性数据,可利用本文提出的基于集成学习的多分类算法进行处理,交叉属性后的多分类问题转为多个二分类问题进行预测,其中二分类器的构造及特征提取方式也可以借鉴使用.在后续研究中,将进一步结合特征工程方法对特征进行处理,减少冗余特征,进一步提高分类准确率.
猜你喜欢
黄河之声(2022年10期)2022-09-27
现代电子技术(2022年15期)2022-07-28
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
