
消除测试代码异味对代码质量的影响分析
2020-12-11 01:49黄华俊吴海涛高建华黄子杰
小型微型计算机系统 2020年11期
黄华俊,吴海涛,高建华,黄子杰
(上海师范大学 计算机科学与技术,上海 200234)
1 引 言
软件测试是保障软件质量的重要手段,通过发现软件缺陷,软件测试能确保生产代码在复杂使用条件下的健壮性[1,2].大型商业软件中包含数量庞大的测试代码[3],维护工作成本高昂,需要理论和自动化工具的支持.
测试驱动开发(TDD)[4]是一种敏捷开发方法,它提倡在实现业务代码前编写对应的测试用例,以保障代码组件的设计符合预期.作为测试驱动开发的重要组成部分,自动化测试可以在保障软件系统质量的前提下,高效地避免开发过程中出现功能回退和设计错误等问题,从而极大地提高了开发效率[1,2,5].
自动化测试代码是软件系统的重要组成部分,编写和维护具备和生产代码类似的挑战性[6].然而,研究发现开发人员倾向于忽视测试代码的重要性.他们认为,相比生产代码,编写和维护测试代码是一种成本高于回报的负担.因此,测试代码缺乏严谨的重构计划[7],其质量普遍低于生产代码[8-11].提升测试代码质量的实际意义主要基于主观经验得出,仍未被量化研究充分验证和讨论,导致软件测试的意义未被充分重视.因此,选取一个可量化的角度分析测试质量提升的意义是迫在眉睫的.
代码异味(Code Smell)是代码中潜在的不良设计和不良实现[12],它可以衡量生产代码的质量.测试异味(Test Code Smell,简称Test Smell)是代码异味在软件测试中的衍生概念[7],它是软件测试中存在不良设计和不良实现的征兆,使用测试异味度量可以量化测试代码的质量.
目前,已有工作讨论了测试异味的量化检测方式和部分性质[13-15],但缺乏从异味重构的视角探讨其对代码质量的影响,也未能指出对代码质量提升最为有效的测试重构操作[14,15],使开发者难以权衡消除代码异味的代价和收益.
本文检测了6个开源软件的93个发布版本,涉及5种测试异味,包括神秘客人(Mystery Guest)、资源乐观(Resource Optimism)、饿汉测试(Eager Test)、断言轮盘(Assertion Roulette)和敏感恒等(Sensitive Equality).对于软件历史版本中的测试异味消除操作,本文使用SZZ算法量化了测试代码及其关联生产代码(简称测试及生产代码)的缺陷倾向,并利用相对风险RR指标分析缺陷倾向数据,计算测试及生产代码在异味消除前后存在缺陷倾向的可能性,以量化消除异味对代码质量的影响.
本文的主要贡献为:
1)通过对6个开源软件系统中的5种测试异味进行分析和探讨,发现消除测试异味前,测试代码存在缺陷倾向的概率是消除异味后的一倍,验证了消除测试异味可以显著提升测试代码质量;
2)对比分析了测试异味消除前后生产代码的缺陷倾向变化,得出消除测试异味能使生产代码存在缺陷倾向的概率减少59%;
3)分别对5种测试异味分组研究,发现消除饿汉测试异味可以最显著地提升生产代码的质量.
本文的章节安排如下:第2节介绍测试异味的相关术语;第3节详细阐述所提出的方法流程;第4节设计实验并对结果进行分析;第5节总结本文内容并讨论将来的工作.
2 相关工作
2.1 测试异味的定义和检测
参考代码异味的研究成果,Van Deurson等人[7]定义并提出了11种测试异味及其重构方法.Meszaros等人[16]基于Van Deurson等人的成果,针对他们在开发过程中遇到的实际问题,扩充了另外18种测试异味.在18种测试异味的基础上,Tufano等人[14]调查了开源软件中5个常见测试异味即断言轮盘、饿汉测试、通用固件(General Fixture)、神秘客人和敏感恒等的性质.
表1给出了本文所涉及的测试异味,它们源于Van Deursen等人[7]定义的异味目录,包括神秘客人、资源乐观、饿汉测试、断言轮盘和敏感恒等.选择以上5种测试异味的原因包括:

表1 测试异味及其描述Table 1 Description of test smells
1)它们常见于相关研究[17]和开源软件系统(OSS)项目中[15];
2)这些测试异味的产生原因不同,不存在显著的共现性,且与测试代码的不同特征有关.
在研究测试异味自动化检测工具的相关文献中,最为常见的是Bavota等人[15]实现的异味检测工具,研究指出其精确率能达到88%,召回率能达到100%,但该工具非开源软件.因此,本文选择开源的tsDetect异味检测工具作为替代,在检测测试异味时,它能够达到至少85%的准确率和90%的召回率,其F-Score为96.5%[18].相较于Bavota等人的工具,tsDetect更易获取和验证,且与Bavota等人的工具有着相仿的精确率与召回率.
2.2 测试异味的性质和影响分析
Palomba等人[19]调查了EvoSuite自动生成的测试代码,发现自动测试生成工具没有考虑生成代码的质量,断言轮盘和饿汉测试的问题在生成测试代码中很普遍.
Tahir等人[20]调查了测试异味和类的复杂度、内聚性度量的关系,研究发现复杂性度量,即环路复杂性和加权方法个数,是存在测试异味的强烈信号.
Bavota等人[15]进行了第一次大规模的研究实验.研究发现,测试异味对测试代码的可理解性和可维护性会产生负面影响,软件规模越大,测试异味的影响越严重,且敏感恒等和神秘客人的强度同软件系统的寿命正相关.然而,测试异味对代码质量影响研究仍不够充分.Spadini等人[17]发现测试异味中的测试代码会使关联生产代码产生更高的易错性,但并未论证消除测试代码异味带来的影响.
测试异味使生产代码更易错,但不当的重构可能事倍功半.由于重构测试代码异味的价值不明,开发人员通常难以确定是否应该进行重构,这一现状对测试质量产生长期的负面影响.Hasanain等人[21]发现,爱立信的工业测试代码中普遍存在代码拷贝问题,且测试规模越大,代码拷贝越多.研究还揭示了测试代码拷贝的生成机理,因为测试代码规模庞大、逻辑复杂且长期疏于维护,其可理解性极差.与其重构一个测试方法,不如重新实现,然而,重新实现的测试方法无法避免的再一次引入了代码拷贝问题.因此,明确消除测试异味给代码质量带来的收益,是确定测试异味重构价值的必要条件.
3 分析方法和过程
本文分析测试异味消前后测试及生产代码的缺陷倾向变化,图1给出了分析过程,包括以下3个步骤:
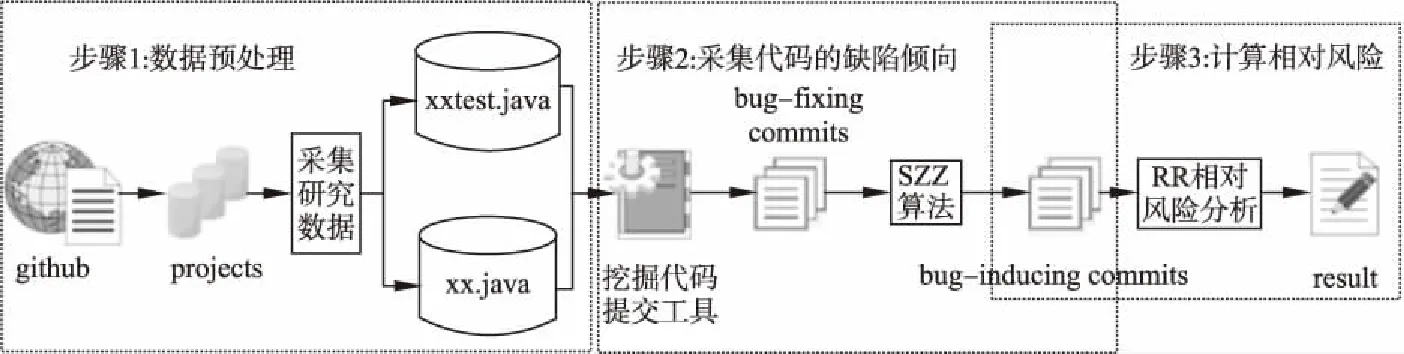
图1 实验步骤Fig.1 Experimental steps
1)数据预处理.本文通过挖掘开源项目中各个历史发布版本的测试代码,对其中存在测试异味,并在而后的历史版本中被消除的测试代码进行收录,以获取测试代码数据集.对测试代码数据集中的测试代码,通过测试代码组件的命名特征,来获取相关联的待测生产代码的数据集;
2)采集代码的缺陷倾向.将缺陷倾向作为代码质量的一般度量,使用挖掘项目历史提交记录工具采集相关的所有修复bug的代码提交(bug-fixing commits),并通过SZZ算法来追溯修复bug的代码提交的源头,即引入bug的代码提交;
3)计算相对风险RR.采用相对风险RR指标来分析异味消除前后缺陷倾向的变化情况.
3.1 测试及生产代码数据预处理
为了获取研究所需的数据集,本文对采集到的开源数据进行了加工,其过程如图2所示.
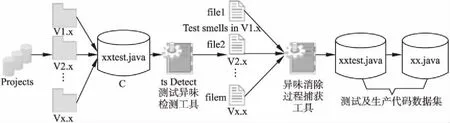
图2 测试及生产代码数据预处理过程Fig.2 Test and production code data preprocessing process
收集数据集中涉及异味消除的测试代码需要3个步骤:
首先,收集项目P中的测试类集合C.根据相关文献[14,22],当类名以“Test”或“Tests”结尾时,可判定它是测试类.
其次,使用tsDetect检测C中的异味,对于C中的任意元素ci,可获得ci在P全部发布版本1至m中的异味分布情况文件集合Fci= {fileci,1,fileci,2,…,fileci,m},其中列出了每个测试类中5种测试异味的分布情况.
最后,本文实现了对测试异味消除过程的捕获工具.如图3所示,对于任意的Fci,该工具可对比和记录fileci,1至fileci,i之间每种异味状态的变化情况,并收集测试异味被消除时的发布版本号.其工作原理如下:
1)当测试类中的其中一种异味满足:在{fileci,1,fileci,2,…,fileci,n}中的该种异味状态为“true”,而在 {fileci,n+1,fileci,n+2,…,fileci,m}中为“false”时,分别分析其他4种异味的分布变化情况;
2)若其他四种异味在{fileci,1,fileci,2,…,fileci,m}中异味状态全为“true”或全为“false”,则记录该异味类型和fileci,n+1对应的发布版本号.
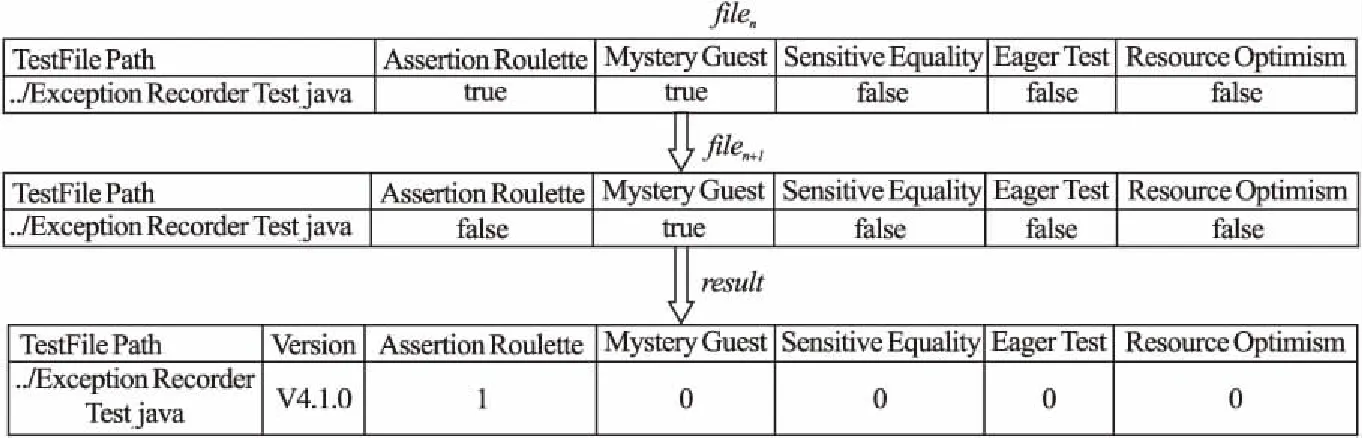
图3 测试异味消除过程捕获工具的输出示例Fig.3 Output example of test smell elimination process capture tool
对于涉及异味消除的测试代码,本文利用一种基于约定俗成的命名方式追溯生产代码,以获取与测试代码对应的生产代码数据集,即通过从JUnit测试类的类名中删除字符串“Test”或“Tests”来识别被测试的生产代码类.Van Rompaey和Demeyer[23]证明该技术与其他可跟踪性方式(例如,基于切片的方式[24])相比,其准确性和可伸缩性最优.
3.2 计算缺陷倾向
缺陷倾向的量化基于SZZ算法的.缺陷倾向又称易错性,文件的缺陷倾向是指文件在两个版本之间的引入bug的代码提交.对于系统的发布版本集合R= {r1,r2,…,rj}中的任意发布版本rv,计算发布版本rv下某个文件的缺陷倾向,是在rv的上一个修订版本至rv之间进行的,这是因为对于修复文件bug的代码变更提交,旨在修复rv与rv之后的修订版间的bug,而其中的bug是在rv之前引入的.
SZZ算法[25,26]是由Sliwerski、Zimmermann和Zeller提出的,用以追溯引入bug的代码提交的方法,它依赖于版本控制系统的追溯指令annotate或blame指令[26],追溯指令可以查询文件的作者、修订信息、相关URL和历史修改记录,这些信息会以注释的形式展示在对应的文件中.SZZ算法计算类缺陷倾向的思路是:根据代码发生bug时版本控制系统对bug所在类的变更记录,估计bug被引入的时刻.
如图4所示,SZZ的运行原理可以理解为四个步骤:
1)提取更改记录,以查找修复bug提交的变更信息;
2)对比修改前后版本代码差异,并精确定位涉及的源代码行;
3)追溯修改后的代码的上一个修订版本代码提交信息及版本号;
4)输出代码提交的ID列表.
对于发布版本rv下的任意bugB,识别修复B的代码提交,以确定修复操作所涉及到的类集合Cfixed= {c1,c2,…,ck}以及类中变更的源代码行位置集合linecj= {l1,l2,…,li},SZZ算法的工作原理如下:
算法1.SZZ(Sliwerski、Zimmermann and Zeller)算法
输入:发布版本rj下任意的B
输出:引发B的n个代码变更提交
Step 1.对于修复B的代码变更提交,令发生该操作的修订版为rv,提取涉及到的类集合Cfixed.
Step 2.对于其中任意一个类cj,修复B时涉及到cj的源代码行变更集合linecj,通过annotate或blame指令操作标识类中每行代码最后一次更改发生的时间,找到linecj中每个元素lnum对应的上一个修订版本rlnum.
Step 3.将rlnum至rv间的所有代码提交标记为引入bug的代码提交.
Step 4.使用island语法分析器[27]捕获空白行和只包含注释的行,输出引入bug的代码提交列表和数量n.
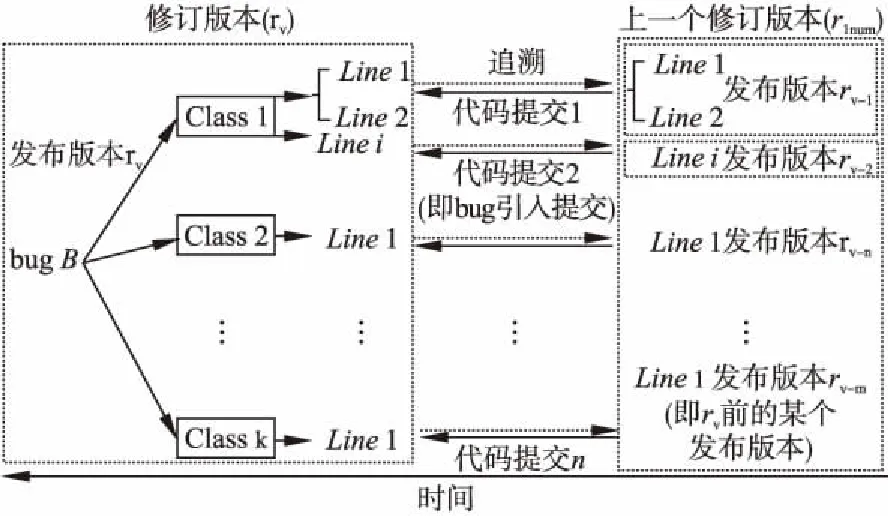
图4 SZZ算法获取缺陷倾向工作原理Fig.4 SZZ algorithm obtains the working principleof defect-prone
至此,SZZ算法可以找到引发B的,所有引入bug的代码提交的相关信息,例如代码提交的ID列表及个数.针对rv中所有修复bug的代码提交修复了的bugbugfixed= {bug1,bug2,…,bugb}.
rv缺陷倾向的计算方式为:对于bugfixed中的每一个bug,SZZ算法所获得的代码提交ID个数的总和.
版本rv下cj缺陷倾向计算方式为:对于bugfixed中的每一个bug涉及到cj的所有引入bug的代码提交个数总和.
3.3 相对风险RR
相对风险是暴露组发生概率与非暴露组发生概率的比值,即一个群体暴露在一定风险下,与未暴露在该风险下某事件的比值.在本文中暴露组是测试异味消除前代码存在缺陷倾向,非暴露组是测试异味消除后代码存在缺陷倾向.RR常被用于前瞻性研究,本文用它衡量测试异味消除前相较于消除后,代码具有更多或更少的缺陷倾向可能性.相对风险RR的计算公式如(1)所示:
(1)
当相对风险RR等于1时,在两个样本中,事件发生的可能性相同.RR大于1时,第一个样本中更有可能发生该事件,例如:测试异味消除前,代码有缺陷倾向.RR小于1时,第二个样本中更有可能发生该事件,例如:测试异味消除后,代码有缺陷倾向.本文采用该方法分析异味消除前后代码发生缺陷情况原因有:1)统计领域报告的结果显示,在进行大规模实证性研究时,这种方法应该是首选[28,29];2)RR相对风险分析等同于优势比分析[30],且可解释性更高[17].
4 实验设计
4.1 实验环境和数据集
实验在Windows 10和Java 8环境下进行.对于tsDetect[18]的有效性,tsDetect工具的开发团队进行了一次大规模的手工验证,在此期间,他们在656个开源Android应用程序中,随机选择测试文件及其相应的生产文件,并邀请了罗切斯特理工学院软件工程系的39名研究生和本科生,来手动检查选出的文件文件是否存在测试气味.所有参与者都是自愿参加的,并且熟悉Java编程,和单元测试.这些参与者在Java开发方面的经验从2到11年不等,其中包括开发单元测试的经验,以此验证了tsDetect能正确识别测试代码异味.

表2 实验数据集Table 2 Experiment dataset
如表2所示,本文参考文献[17],选择了其中的6个规模不同的开源软件系统作为测试数据集,所有版本中都有大量的JUnit测试用例.考虑到次要发布版本(Minor Releases)之间的变更不显著且过于频繁,本文只考虑每个系统主要发布版本(Major Releases).
4.2 问题设计
本文挖掘测试代码中的异味,对比异味在消除前后,测试代码以及受测的生产代码的缺陷倾向的变化,并根据结果评估测试异味消除后多大程度的影响软件的代码质量.实验回答以下3个研究问题:
RQ1:测试异味消除前后,测试代码的缺陷倾向呈现何种变化?
RQ2:测试异味消除前后,生产代码的缺陷倾向呈现何种变化?
RQ3:是否存在影响实验效度的因素?
4.3 实验过程
1)首先对开源数据进行预处理,获取所有待研究的测试类,并将这些测试类作为测试异味检查工具的输入数据.
2)对于每个测试类,使用静态分析工具tsDetect检测每个发布版本中测试代码的测试异味,并采用测试异味消除过程捕获工具,收集在版本迭代中测试异味被消除的测试代码,并通过命名跟踪技术,找到关联的生产代码的类,作为生产代码数据集.
3)按照5种测试异味类型,对所有的数据集进行归类,将其分为5组.
4)确定测试异味被消除的版本,使用SZZ算法计算该版本前后,所有主要发布版本的测试及生产类的缺陷倾向.本文复现了SZZ算法,根据Fischer等人[31]的方法确定提交是否修复了缺陷,该方法基于版本控制系统在代码提交时记录的消息进行分析.如果提交消息与问题跟踪器中存在的问题ID匹配,或当它包含“bug”,“fix”或“defect”等关键字时,将其视为错误修复提交.为获取错误修复提交,本文使用RepoDriller[32]挖掘所有的代码提交.RepoDriller是一个用来帮助研究人员挖掘软件代码仓库以做研究的Java框架.一旦通过RepoDriller获取到所有涉及的修复bug的代码提交,SZZ算法将通过Git的blame特性记录所有可能的引入bug的代码提交.
5)最后根据SZZ量化的缺陷倾向,计算出测试异味消除前后,代码有缺陷倾相对风险RR指数,通过分析该指数,得出了消除测试异味对代码质量的影响.
4.4 实验分析及结果
RQ1:测试异味消除前后,测试代码的缺陷倾向呈现何种变化?
为了回答RQ1,本文从3个角度分析缺陷倾向呈现何种变化,即:1)整体变化的趋势;2)测试异味消除后,测试代码存在缺陷倾向的可能性变化多少;3)消除不同种类的测试异味对测试代码缺陷倾向的影响,分别对应图5、表3和图6.
图5展示了测试异味消除前后,测试代码缺陷倾向数量分布的对比.观察图5的箱线图,可以看到,相较消除之前,消除异味之后测试代码含有的缺陷倾向数量显著减少.箱线图中也出现了几个异常值,如异味消除前一个测试类最多含有27个缺陷倾向,消除之后最多也是27个,这个结果是由于测试异味的特性所导致的.例如:断言轮盘包括不止一种断言用来检查不同的行为,饿汉测试需要调用生产对象的多个方法,它们所涉及的文件多消除这些异味往往变更量大,所以统计含有这些异味的测试代码的缺陷倾向数量时可能出现异常大的值.这些异味特性的本质使得它们难以被开发人员所理解,进而导致开发人员更容易引入缺陷.
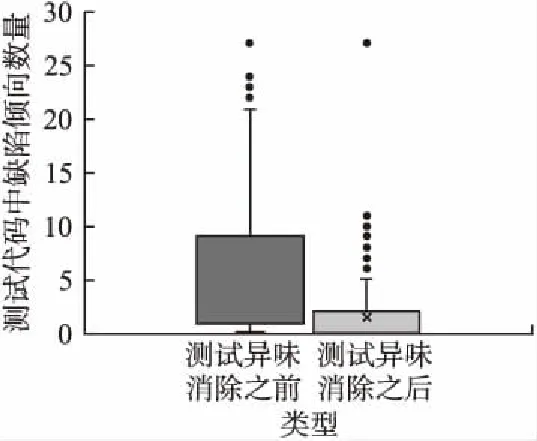
图5 测试异味消除前后测试代码的缺陷倾向数量分布对比Fig.5 Number distribution of defect-proneness in test code before and after test smell removal
表3中统计了180条测试异味被消除的记录,其中暴露组(测试异味消除前)生产代码存在缺陷倾向概率为81%,非暴露组(测试异味消除后)生产代码存在缺陷倾向概率为36%,RR值为2.26,即消除测试异味之后,测试代码有缺陷倾向的可能性较消除之前减少126%.

表3 测试异味消除前后测试代码有缺陷倾向的相对风险Table 3 Test smell elimination before and after the test code with defect-prone′RR
图6展示了按消除异味的种类分成5组的实验数据,从图中观察的结果可知测试异味消除后,测试代码的缺陷倾向都趋向减少,表明消除测试异味对测试代码的质量起到提升的作用.其中,敏感恒等(Sensitive Equality)的变化趋势非常明显,造成这一现象的原因可能是数据集中软件寿命较长.Bavota等人[15]研究发现敏感恒等的强度同软件系统的寿命呈正相关,本文数据集中软件系统的最早版本发布时间可追溯到10至20年前.在这类系统中,一旦该异味被消除,异味消除前后,缺陷倾向的变化会很大.
利用和RQ1类似的方法,回答RQ2:测试异味消除后,生产代码的缺陷倾向呈现何种变化?
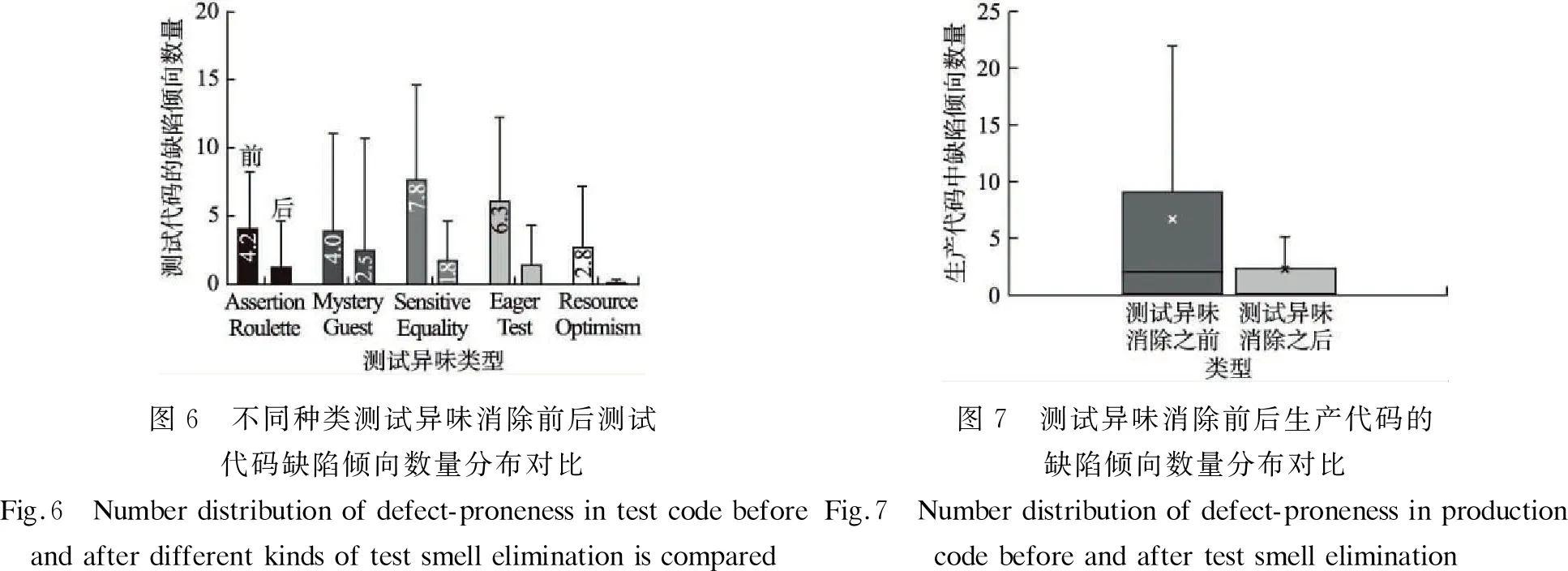
图6 不同种类测试异味消除前后测试代码缺陷倾向数量分布对比图7 测试异味消除前后生产代码的缺陷倾向数量分布对比Fig.6 Number distribution of defect-proneness in test code beforeand after different kinds of test smell elimination is comparedFig.7 Number distribution of defect-proneness in production code before and after test smell elimination
如图7的箱线图,易见测试异味消除前后,生产代码中的缺陷倾向数量下降,表明相较于测试异味消除后,生产代码质量得到了一定的提升.
据表4,测试异味消除前后生产代码有缺陷倾的相对风险RR值为1.59,表明消除测试异味使生产代码有缺陷的概率降低了59%.

表4 测试异味消除前后生产代码有缺陷倾向的相对风险Table 4 Test smell elimination before and after the production code with defect-prone′RR
图8描述了5组实验数据集的生产代码中缺陷倾向数的分布情况.5种测试异味消除后,生产代码的整体缺陷倾向数量都趋向于减少.相较于其它4种测试异味,饿汉测试的减少趋势最为显著.饿汉测试被消除后,生产代码缺陷倾向的平均值从7.8降低至2.4,减少了69.2%.饿汉测试的存在,可能是待测生产代码质量降低的重要原因.

图8 不同种类测试异味消除前后生产代码缺陷倾向数量分布对比Fig.8 Number distribution of defect-proneness in production code before and after different kinds of test smell elimination is compared
4.5 影响实验效度的因素
对于RQ3,影响实验效度的因素有以下几点:
1)不同规模的软件系统、不同开发团队的代码风格和开发习惯,可能造成测试异味分布不均影响结论的数值.
2)本文的结论基于测试异味检测工具的准确程度,检测工具的质量可能影响实验效度.为了获得有关测试异味的信息,本文使用tsDetect测试异味检测器.尽管此工具精确率能达到85%以上,且召回率在90%以上,非常之高,但数据集中仍然可能存在一些误报.
3)Fischer等人[31]提出的确定提交是否修复了bug的方法,它基于版本控制系统在代码提交时记录的消息进行分析.这种方法在过去被广泛用于识别bug修复[34,35],其精确率接近80%[31,33,35],Spadini等人[17]在实现SZZ算法时使用的是该方法,并认为对于实现SZZ算法这种技术足够准确,因此本文也采用了相同的技术.
4)另一个威胁在于基于命名约定的可追溯性技术,该方法通过测试代码检测相关联的生产代码,但这种关联方式,可能因为开发人员缺乏经验或人为错误导致结果的不准确.这种技术在相关研究中被大量采用[13,14,22].Van Rompaey和Demeyer[23]也对该技术进行了评估,结果报告平均精度为100%,召回率为70%.
5)本文仅讨论了Java项目的测试异味,对于其它使用弱类型系统的动态语言,例如JavaScript,其测试异味与代码质量的关系可能具备不同性质.
5 总结及展望
软件测试代码的重要性经常被忽视,明确测试异味对代码质量的影响,可以降低软件重构和维护的成本,并提升软件代码质量.本文使用SZZ算法量化测试及生产代码的缺陷倾向,并利用RR相对风险计算测试异味消除前后测试及生产代码存在缺陷倾向的可能性,以分析消除测试异味对软件代码质量的影响.本文通过实验研究得出以下结论:
1)消除测试异味能使测试代码的质量得到显著的提升.在测异味消除之后,测试代码存在缺陷倾向的可能性较之前减少约一倍(126%);
2)消除测试异味,能提升生产代码的质量.消除测试异味后,生产代码存在缺陷倾向的概率较之前少59%;
3)相较于其他4种测试异味,重构饿汉测试对生产代码质量的提升更大.
后续工作有三个方向.其一,本文的研究基于Java项目开展,可以基于其他编程语言的开源项目进行研究;其二,本文的研究粒度限制在类级别,可以进一步细化到方法级别,以探究开发人员是在方法级别进行编码的情况;其三,因为测试异味的生命周期很长,项目中消除测试异味的数据较少,可以进一步对各种不同规模的开源项目开展研究.
猜你喜欢
智能计算机与应用(2022年8期)2022-07-29
体育师友(2022年1期)2022-04-17
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
软件和集成电路(2019年7期)2019-08-30
宠物世界·猫迷(2017年7期)2018-01-25
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
祝您健康(2016年4期)2016-04-28
