
多特征像素级融合的遮挡物体6DoF姿态估计研究*
2020-12-15 08:13梁达勇陈俊洪朱展模黄可思刘文印
计算机与生活 2020年12期
梁达勇,陈俊洪,朱展模,黄可思,刘文印
广东工业大学计算机学院,广州510006
1 引言
近年来,随着机器人的快速发展,机器人在各行业的部署应用也快速增多,例如家庭服务、工业制造等,然而这些应用绝大多只能处理特定操作环境下的场景,对于背景凌乱、物体遮挡和光线不足等环境场景,机器人难以实现精准抓取。要更好地解决该问题,机器人必须对物体的6DoF姿态进行估计,通过三维点云信息有效地掌握物体的形状大小等信息,从而调整自身机械手抓取的角度实现准确抓取,可以说6DoF姿态估计是机器人在真实环境中实现精准抓取的必要工作。
虽然现有的物体抓取研究在RGB数据集上已经取得了很大进展,但是在实际机器人抓取应用场景中,由于缺少深度信息,机器人在与周围环境进行交互操作时无法对物体进行稳定的抓取。对此,人们提出了将RGB图和深度图像进行融合的基于RGBD的姿态估计方法。Xiang等人[1]提出了一种端到端的6D姿态估计网络PoseCNN,通过利用迭代最近点(iterative closest point,ICP)算法来增强深度信息在姿态估计中的作用。Li等人[2]使用深度迭代匹配(deep iterative matching,DeepIM)算法迭代优化6D姿态,但是此类需要点云进行复杂后期优化操作的算法非常耗时,并不适用于现阶段的机器人应用。Jafari等人[3]提出了一个包含了mask感知模块的框架,该模块在定位所有已知对象后将像素密集地映射到三维物体表面的位置,并使用几何优化算法预测6D姿势,取得了不错的效果。Wang等人[4]设计了一个可以单独处理并融合RGB图和深度数据的融合网络,将融合的特征进行姿态回归,然而这个过程需要用到PointNet[5]来处理点云信息,计算量非常庞大。Xu等人[6]在PointNet基础上处理图片和对应的点云,并做回归,输出3D Box。
为了更好地精简网络框架并提高计算效率,本文提出了一个基于像素级融合网络的遮挡物体6DoF姿态估计框架,该框架主要包含三个模块,分别为:RGB特征提取网络、像素融合结构和6D姿态回归网络。其中第一个模块主要利用目标检测从RGB图片中识别出目标物体,并利用编码器与解码器提取RGB像素特征;第二个模块用于提取物体模型特征并与RGB像素特征进行融合;最后一个模块用于计算物体6D姿态。与其他多阶段姿态估计结构的方法相比,本文所提出来的框架在损失较少的精度情况下效率提高了上百倍,并且对于物体被遮挡或部分点云丢失的情况下也具有良好的鲁棒性。
2 相关研究
2.1 基于RGB图片的6D姿态估计
基于RGB图片的6D姿态估计是常见的做法之一,Do等人[7]提出通过改变Mask R-CNN预测分支的方法对物体6D姿态进行估计,但是该方法在物体被遮挡时鲁棒性较差。为了解决该问题,近年来大量方法利用分段网络的方法来预测6D姿态。Kehl等人[8]通过预先估计物体的2D位置和四元数quaternion来计算物体可能的6D姿势池,再通过优化每个池中的估计选择最佳的6D姿态;Xiang等人[1]提出先建立分割网络对物体的具体位置进行估计,再利用物体的位置计算出平移矩阵,并结合图片特征预测四元数。虽然这些方法都可以有效地计算出物体的6D姿态,但是都需要高度复杂的网络结构以及后期的深度信息优化步骤才可以得到准确的6D姿态。
在基于RGB的姿态估计方法中,由于基于特征点匹配的网络框架可以取得较高的精度,因此此类方法受到人们广泛的关注。Peng等人[9]对每个像素点都回归一个关键点后,利用随机抽样一致方法(random sample consensus,RANSAC)投票系统对关键点进行投票,从而选出更适合的关键点;Hu等人[10]提出一个分割驱动型网络框架,该框架先将物体进行分割,再利用物体预测局部的候选6D姿态,最后通过投票计算出最佳的6D姿态,该方法在物体被遮挡的情况下取得了较好的效果。虽然基于RGB的姿态估计方法比较高效,但在缺少深度信息的情况下使得该方法过度依赖RGB信息的完整性,当数据信息缺失严重时,模型估计精度便会大幅度下降,因而结合了深度信息等多特征的方法框架在现实环境中将更具实用性。
2.2 基于RGB-D图片的6D姿态估计
随着硬件的快速发展,近年来利用深度信息对物体的6D姿态进行估计逐渐成为热门方向。文献[11-12]提出利用随机森林从RGB-D图像中抽取局部特征,再通过投票建立3D到2D的对应关系,进而对物体6D姿态进行估计;文献[13-14]利用回归网络将局部采样的RGB-D信息方块应用于6D姿态投票,然而块到块的RGB-D信息提取框架无法有效地将RGB信息和深度信息进行融合。为了解决该问题,最近人们提出基于点云特征融合的方法,该方法通过密集型特征融合的方式将两种信息进行了融合。Xu等人[6]描述了一种像素级融合方法,他们使用密集型融合机制将RGB信息和点云信息进行了融合,并通过网络回归出3D框,最后使用两种投票机制选择出最佳的6D姿态。为了进一步优化融合网络,Wang等人[4,15-16]在原有方法上进行了改进,通过将像素级的2D信息嵌入三维空间点云信息来增强每个点云的作用。虽然以上方法都有较好的效果,但是这些方法过度依赖于PointNet[5]的特征提取分支结构,这导致了系统计算量大。为了解决该缺陷,本文提出使用单个像素级信息源进行密集融合,简化了点云特征的提取网络的结构,从而提高了计算效率。
3 基于像素融合网络的物体姿态估计
本文的目标是从RGB-D图像中预测出一个物体在三维空间下的6D姿态,其中6D姿态表示从物体坐标系到摄像机坐标系下的刚性变换,用[R|T]表示,R表示旋转矩阵,T表示平移矩阵。本文不直接预测[R|T],而是先预测四元数q以及未经过深度信息微调的平移矩阵t,最后进行四元数到旋转矩阵的转换和平移矩阵的微调。总体的框架流程图如图1所示,整个结构分成三个模块:RGB特征提取网络(图1(1))、像素融合结构(图1(2))以及6D姿态回归网络(图1(3)),接下来将具体介绍框架的细节。
3.1 RGB特征提取与融合
为了缩小目标对象范围,使用在图片数据集MSCOCO[17]上预训练过的Mask R-CNN[18]对目标对象进行分割,即预训练模型的参数使用的是Mask R-CNN上提供的基础模型MS-COCO的训练参数。Mask RCNN在Faster R-CNN的基础上加入了Mask分支,可以大幅度提高物体定位精度。然而在分割过程中,由于存在多物体遮挡的情况,导致语义分割得到的感兴趣区域(region of interest,ROI)裁剪图通常会包含其他物体以及无关的背景信息,因此将ROI裁剪图按照相对于指定摄影机坐标系变换而来的点云图进行横向关联,通过这样的方式来对物体的局部像素特征进行选择。经过Mask R-CNN进行分割后,得到了一组ROI识别框B={b1,b2,…,bn}和物体掩码M={m1,m2,…,mn},利用得到的ROI框bn和物体掩码mn,可以为像素融合网络提供对应物体的ROI裁剪图和对应的稀疏点云图,其中ROI裁剪图主要用于RGB特征的提取,而稀疏点云图用于6D姿态回归。

Fig.1 Overview of pixel-level fusion network图1 像素融合网络框架图
对于ROI裁剪图,由于存在物体被遮挡的情况,因此在ROI裁剪图上随机抽取了Np个像素输入到特征提取结构(embedding)中进行特征的提取,具体结构如图2所示。从图中可以看到,整个特征提取结构主要由Resnet-18[19]特征编码器和基于PPM(pyramid pooling module)[20]设计的解码器组成。其中,PPM解码器是一种较好的充分利用了全局信息的方式,里面的多尺度pooling能在不同尺度下保留全局上下文信息。PPM解码器处理从Resnet-18提取到的特征的方式跟Pyramid Scene Parsing Network[20]里的处理方式一致。并且,为了进一步得到有效的特征,还基于PPM解码器增加了一个卷积神经网络(convolutional neural networks,CNN)进行高层次的特征提取,其中CNN网络包括两层卷积操作,第一层卷积核大小为1×32,输出维度为64×Np,第二层卷积核大小为1×64,输出维度为128×Np。增添的CNN网络的参数设置参考了Pyramid Scene Parsing Network[20]最后的CNN分类网络参数设置,能结合Resnet-18提取的特征获得更完整的特征信息。为了完全提取到深层次的特征,将两层卷积的特征都保留下来,以供后续的像素融合操作。
其中,两层卷积都使用ReLU作为激活函数,步长设置为1,padding设定为0。最后输出128×Np维特征,其中Np为选取的RGB像素个数。为了获取更多特征信息,将经过第一层卷积的特征也保存下来,特征维度为64×Np,最后将两层卷积中分别得到的特征进行融合。
3.2 像素融合结构
RGB信息能为物体姿态估计提供颜色形状特征,但在RGB信息严重缺失时将会失去对物体形状的判断,采用物体模型视图特征融合的方式来增强物体外观信息的特征表示。基于文献[21]中的模型特征提取方法,将物体三维模型从12个角度进行截取,并将这12个物体视图作为像素融合网络的附加嵌入特征,其中对于每一个物体模型截取大小为12×120×120的物体视图,截取角度为0°到300°的方位角以及-30°和30°的仰角,这样即使物体的视觉外观发生了变化,这些物体模型视图仍能够捕获不同方向的真实物体的形状和轮廓[22]。通过获取不同方向上的物体形状和外观信息,可以有效弥补物体像素融合特征的不足,以及降低物体被遮挡情况下的不利影响,从后续的验证结果可知物体视图特征在非对称物体姿态估计上起到了辅助作用。
在获取到不同物体视图后,将其特征与RGB特征进行融合,并进行全局特征的提取,具体的提取和融合过程如图3所示。首先将12张物体视图输入到2.1节所提到的embedding结构进行特征的抽取,相应地得到一个64×Np特征矩阵和一个128×Np特征矩阵,并把128×Np特征矩阵与128×NpRGB特征进行拼接融合。紧接着受PointFusion方法[6]启发,将融合后的特征输入到多层感知机中进行全局特征的抽取,并且在多层感知机最后两层卷积层后分别增加了一层平均池化层进行特征的降维,最终得到一个1×1 024的全局特征矩阵。紧接着把全局特征矩阵拓展Np份嵌入到原来融合所得到的局部特征当中,输出一个维度为1×1 048×Np的特征矩阵,并把该矩阵作为下一步6D姿态回归网络的输入。

Fig.2 Embedding feature extraction structure图2 Embedding特征提取结构

Fig.3 Object viewpoints optimization architecture图3 物体视图优化结构
3.3 6D姿态回归网络
6D姿态回归网络的目标是将输入的每一个像素特征进行回归计算,预测出该像素所对应的四元数矩阵、平移矩阵以及对应的矩阵评分,最后根据这些矩阵评分选出最优的矩阵。具体网络结构及参数如图4所示。
从图4中可以看出该网络一共包含4层卷积网络,其中第一个卷积层卷积核大小为1 408×1,输出特征维度为640×Np,第二个卷积层卷积核大小为640×1,输出特征维度为256×Np,第三个卷积层卷积核大小为256×1,输出特征维度为128×Np,第四个卷积层卷积核大小为128×1,输出特征维度Np×j根据预测参数的维度而定。每一层卷积的步长和padding都设定为1,并使用ReLU作为激活函数。
除此之外,还在点云融合层面进行了优化改进,简化了点云特征的提取结构,并把点云信息作为微调信息融入到姿态回归网络中。具体来说,利用Mask R-CNN中所得到的掩码和深度图,经过裁剪得到仅包含目标物体信息的物体深度裁剪图,并且为了降低物体被遮挡时所造成误判的影响,随机选取i个点代表整张裁剪图进行训练,并将这i个点通过相机坐标系的内参转换转化成物体的点云集合P,其中P包含i个点云像素p,这些点云像素可以为RGB图像在像素融合过程中提供足够的空间信息。
定义第i个像素点的预测姿态为,第i个点云pi平移矩阵定义为:


其中,GT(j)代表真实姿态下的物体模型上采样的N个点云中点x(j)的所在位置:



Fig.4 6D pose estimation network图4 6D姿态回归网络
但是由于对称对象可能有无数的6D姿态表示形式,这导致了式(2)并不适用于对称物体的姿态预测。因此针对对称物体,引入了另一损失函数对物体模型上的点云与真实姿态下物体模型最近的点云之间的平均偏移量进行最优化估计,该损失函数如下:

并且,为了从每个像素特征预测的转换矩阵中选出最优的转换矩阵,本文根据PointFusion的评分方法,并结合上文定义的式(2)和式(5)以及网络回归得到的对应矩阵评分Ci,重新设计了一个非监督log损失函数:

其中,Ci表示从M个随机挑选的像素特征中预测出来的矩阵评分,w是个超参数,表示矩阵评分的权重。由最终的非监督损失函数可知,当评分Ci越低时,wlnCi越高,最后整体的评分Lscore就越低。
4 实验结果与分析
4.1 数据集
YCB-Video数据集[23]:该数据集由92个RGB-D视频序列组成,拥有130 000帧真实场景的图像数据以及80 000帧合成模型渲染图像数据,一共涵盖了21个不规则物体,并且每个物体都存在不同程度的物体遮挡或者不良照明等外部影响因素。
YCB-Occlusion数据集:为了测试像素融合网络框架在极端环境下物体姿态估计的鲁棒性,本文根据YCB-Video数据集中的2 949张关键测试帧,添加新的物体掩码制作成新的数据集。具体来说,利用Mask R-CNN中得到的2D掩码对RGB图以及对应的深度图进行随机裁剪,裁剪后每个物体都只保留了大概10%到30%的RGB图像可视区域,剩余区域根据遮挡范围填充零值,表示RGB信息丢失;相应地,在深度图像上也只保留了跟RGB图像相同位置的可视区域,其他区域用零值填充,以表示深度信息丢失,处理后的数据集如图5所示,其中上列为处理过后的RGB图像,下列为相对应的深度图像。

Fig.5 YCB-Occlusion dataset图5 YCB-Occlusion数据集
LINEMOD数据集[24]:该数据集拥有12个未被遮挡的物体,本文主要将其用于测试物体表面特征不明显、背景场景混乱等情况。
4.2 评价指标
对于6D姿态估计,使用最近点云平均距离ADDS[24]对模型进行评判,并且将评价指标分为以下两类:
ADD-S AUC:当预测的点云与实际的点云差值小于10 cm时,认为估计的转换矩阵是正确的。
ADD-S 0.1d:当预测的点云与实际的点云差值小于物体直径的10%,认为估计的转换矩阵是正确的。
4.3 实验设置
在物体定位分割阶段,使用在MS-COCO[16]预训练的Mask R-CNN参数,并在实验中分别使用YCBVideo和LINEMOD数据集进行了参数微调,将Mask R-CNN基础模型的参数作为本文模型的超参数。
在物体姿态估计阶段,把模型学习率设为1×10-4,batch size设为1,并且对于不同的数据集,采取不同的参数设置,对于YCB-Video和YCB-Occlusion数据集,将更新迭代次数设置为30次,像素个数Np设置为1 009个。除此之外,还为每个物体增加1 000张合成模型图以防止过拟合;对于LINEMOD数据集,把更新迭代次数设置为40次,像素个数Np设置为500个,不提供额外的物体合成模型图。
在物体姿态模型测试阶段,为了与PoseCNN进行效果对比,在YCB-Video数据集上使用与PoseCNN相同的物体2D分割掩码,而在LINEMOD数据集上则使用Mask R-CNN预测的分割掩码。
4.4 测试结果与分析
模型实时性分析:经过模型复杂度检测,PFNet+Model模型的参数总数量为29.85 MB,模型计算量FLOPs为22.13 GB,在一张TITAN X显卡上进行实验测试时,PFNet模型在YCB-Video数据集上能实现19 FPS,PFNet+Model模型也能实现14 FPS,测试结果如表1所示,已能满足在现实环境中机器人进行物体实时抓取与操控的姿态估计需求。
Mask R-CNN微调性能分析:在进行6D姿态估计前,利用Mask R-CNN进行物体分割来获取物体特征,在经过YCB-Video以及LINEMOD数据集的数据微调后,物体分割得到较高的平均精度。在YCBVideo数据集测试中,被遮挡的物体分割IoU(intersection over union)超过85%的精度AP85达到49.4%,mAP达到46.5%,以达到Mask R-CNN在遮挡物体上的测试标准。在LINEMOD数据集测试中AP85为82.7%,mAP为72.9%,具体的测试精度如表2所示。
YCB-Video数据集测试结果与分析:将结果与PoseCNN[1]进行了比较,并且为了进一步验证本文所提出的多视角像素融合结构的有效性,将该结构进行了单独的比较,对比结果如表1所示。从表中可以看出,本文所提出的方法精度分别为88.7%和89.3%,精度上比PoseCNN方法稍差,但是在计算效率上,本文方法比前者提高了155倍,这得益于在数据输入时仅将点云作为原始信息来进行输入,而无需进行费时的迭代优化,而PoseCNN需要经过耗时的ICP深度优化之后才能取得不错的效果。除此之外,根据表中可以看到,使用多视角像素融合结构可以在物体少量遮挡的情况下稍微提高实验精度。部分实验结果的可视化效果如图6所示。
YCB-Occlusion测试集测试结果与分析:为了进一步验证本文所提出的多视角像素级融合结构的有效性,对该结构进行了测试,测试结果如表3所示。从表中可以看出,使用该结构的模型在物体RGB信息和深度信息大面积缺失的情况下,仍然可以取得74.9%和77.2%的精确度,比未使用物体模型视图的网络模型要分别高出10.6个百分点和9.7个百分点。其中,对于表面纹路不清晰的木头和碗,以及深度信息容易丢失的黑色记号笔和夹子,精度下降幅度尤为明显。相较于PoseCNN+ICP模型中的ICP优化,PFNet模型中的深度信息能直接对应地进行点云微调,使得深度信息能更好地融合RGB像素特征,从而避免了特征严重缺失带来的点云不匹配问题。而且本文还利用可视化技术对测试结果做了进一步分析,可视化效果如图7所示,可知当物体丢失的信息为该物体的关键特征时,例如物体表面纹路和深度信息时,6D姿态估计的误差就会相对较大;而丢失非关键特征时,例如纹路较浅的颜色特征,则6D姿态估计的误差就会相对较小。

Table 1 Performance comparison of different models on YCB-Video dataset表1 在YCB-Video数据集上的不同模型效果对比

Table 2 Test accuracy of Mask R-CNN表2 Mask R-CNN测试精度%

Table 3 Comparison of model performance on YCB-Occlusion dataset表3 在YCB-Occlusion数据集上的模型效果对比

Fig.7 Visualization of results on YCB-Occlusion dataset图7 YCB-Occlusion数据集结果可视化
由于物体RGB信息丢失以及深度信息丢失两者对像素级融合网络有着不同程度的影响,因此选择四种表面纹理较为明显且不容易丢失深度信息的物体进行测试,分别为:厨师罐头、鱼罐头、汤罐头和杯子。对这四个物体分别设计了三组实验进行对比,分别是:只丢失RGB信息、只丢失深度信息、同时丢失RGB和深度信息的,其中丢失信息的位置相同。对比结果如图8所示,由图可知,只丢失RGB信息的以及同时丢失两种信息的效果都要优于只丢失深度信息的效果,这种验证结果表明:(1)当RGB像素丢失时,深度信息也能对姿态估计进行校准优化,但精度有所下滑;(2)在姿态估计阶段,深度信息的微调起到了关键作用;(3)如果微调过程每个RGB像素特征能在相应位置获得准确的深度信息,那么姿态估计结果较为准确,反之则误差较大。以上对比实验将进一步验证本文所提出的多视角像素级融合结构的有效性。
LINEMOD数据集测试结果与对比:本文还将所提出的模型在LINEMOD数据集上进行测试,测试结果如表4所示。由于LINEMOD数据集的物体并未被遮挡,而且一张图片中只估计一个物体姿态,在MaskRCNN精度较高的情况下,深度信息与RGB信息的融合更加精确,因而姿态估计的精度相较于其他ICP优化的方法有显著提高。从表中可以看到,与经过ICP优化的方法(Implicit 3D[25]以及SSD-6D[8])相比较,本文方法精度提升了18个百分点;由于LINEMOD数据集并未考虑到遮挡问题,也未提供物体三维合成模型,因此本文并未使用物体视图特征进行优化,但本文框架的效果仍要远优于其他ICP优化框架。

Fig.8 Importance comparison of RGB and depth information图8 RGB以及深度信息的重要性对比
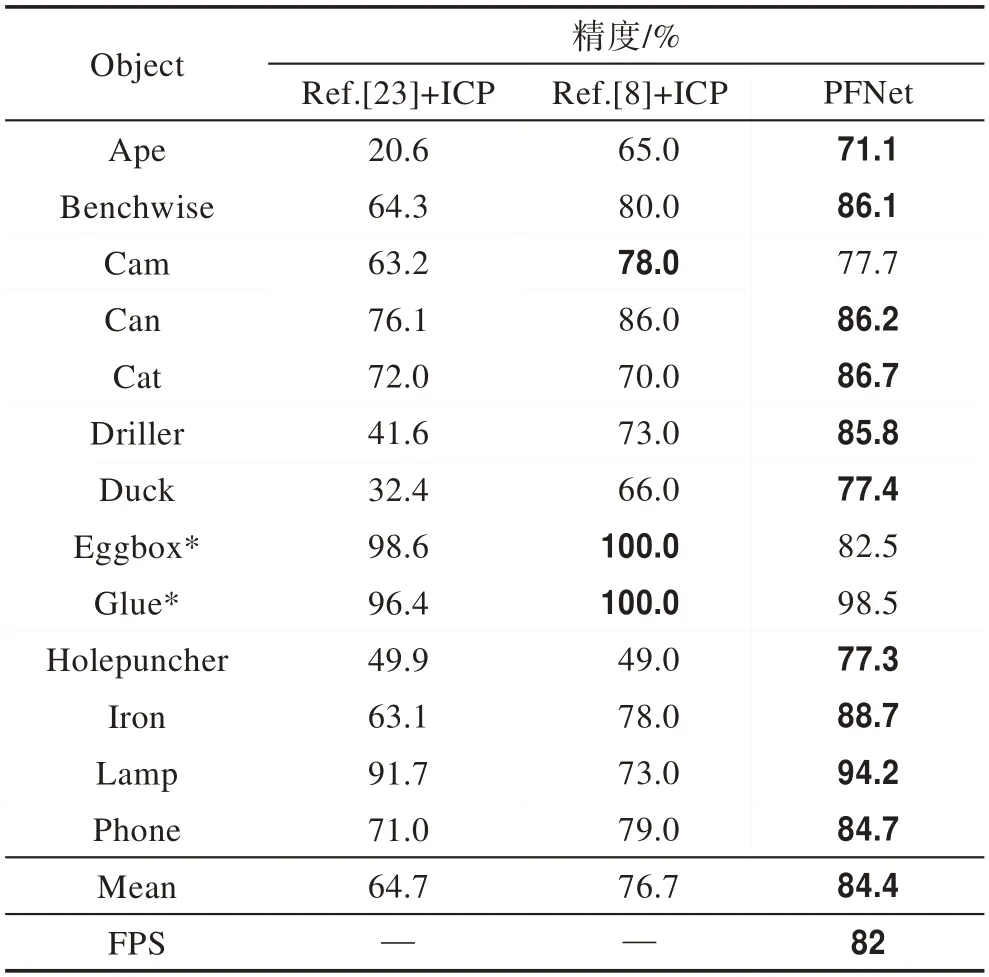
Table 4 Comparison of model performance on LINEMOD dataset表4 在LINEMOD数据集上的模型效果对比
5 结束语
本文提出了一种像素级融合网络框架,该框架能在遮挡环境中结合RGB像素特征和物体视图的局部特征,更有效地预测物体6D姿态,即可利用多模块特征来解决复杂环境下的物体姿态估计。并且通过大量的实验表明,本文方法在物体被严重遮挡以及光线不足情况所导致的物体像素丢失时都能展示鲁棒性。
在以后的工作中,将在以下几个方面进行扩展:(1)将触觉传感器和本文的框架结合起来以获得准确的抓取操作;(2)逐渐削弱融合网络中的RGB像素,使得机器人在黑暗中根据深度信息也能执行抓取等操作。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
学生天地(2020年3期)2020-08-25
红领巾·萌芽(2019年8期)2019-08-27
读与写·教育教学版(2017年10期)2017-11-10
CHIP新电脑(2016年3期)2016-03-10
诗选刊(2015年4期)2015-10-26
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
电影新作(2014年5期)2014-02-27
