
高校图书馆的智能推荐系统
2020-12-15 06:58彭智彬罗晓莹朱弘扬韩晓强
卷宗 2020年25期
彭智彬 罗晓莹 朱弘扬 韩晓强

摘 要:当今信息化时代,学生面对多种多样的信息会产生迷茫,特别是面对图书馆内庞大的信息,更是难以找寻适合自己的学习资料。本系统是针对大学生而设计的高效率人性化图书馆管理系统。该系统采用分布式数据库Hbase来实现对超大规模数据的实时随机访问,并保证系统的稳定性。大数据模块还会根据用户信息与日志信息,从而通过一系列的指标进行个性化推荐,这种方法可以大大地提高学生学习效率,充分地利用好图书馆内的资源。
关键词:图书馆;分布式数据库Hbase个性化推荐
DOI:10.12249/j.issn.1005-4669.2020.25.160
基金项目:大学生创新创业训练计划项目”智能图书馆大数据研究“(项目编号:570119130)。
信息时代数据的变革必然给图书馆带来冲击,对图书馆的知识服务提出更高的要求和前所未有的挑战,对一般传统的手工检索而言,不仅学生无法达到高效性学习,图书馆本身也难以灵活地给学生以个性化服务。为了更好地提高学生自学效率和时间利用率,实现1+i的学习,大学图书馆的智能推荐系统对我校现有的图书数据进行挖掘,以标签的形式分门别类,对学生的专业和年龄性别进行匹配并推荐图书。
1 项目描述
这是一款根据学生专业和兴趣来推荐相应的书籍与习题的智能系统:高校图书馆的智能推荐系统,主要根据学生的访问行为与个人信息,如专业,则可以匹配到学校图书馆里有相关联系的学习书籍与习题,从而推荐给学生去查阅。同时,这些书籍都是通过有效数据处理而分成不同的阅读难度,这样能更好地提高学生自学效率和时间利用率,实现i+1的学习。
此外,智能图书馆还会添加题库功能供学生学习和备考,收集各科教科书上习题以及考试题型,为每科复习提供考点题型复习,习题练习与解析,错题相同考点题目练习。为学生提供良好的复习平台。
2 核心技术说明
2.1 分布式数据库Hbase
本系统采用分布式数据库Hbase,HBase(HadoopDatabase),是一個高可靠,高性能,面向列,可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据的NoSQL的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。该数据库是建立在HDFS之上,同样是基于这种主从式的一种运行机制,即用一个master节点协调管理多个slave从属机。其中,HBase位于结构化存储层,利用HadoopHDFS作为其文件存储系统,利用HadoopMapReduce来处理HBase中的海量数据,Zookeeper为其提供分布式协同服务,使得查找数据,访问速度快,如图1所示。
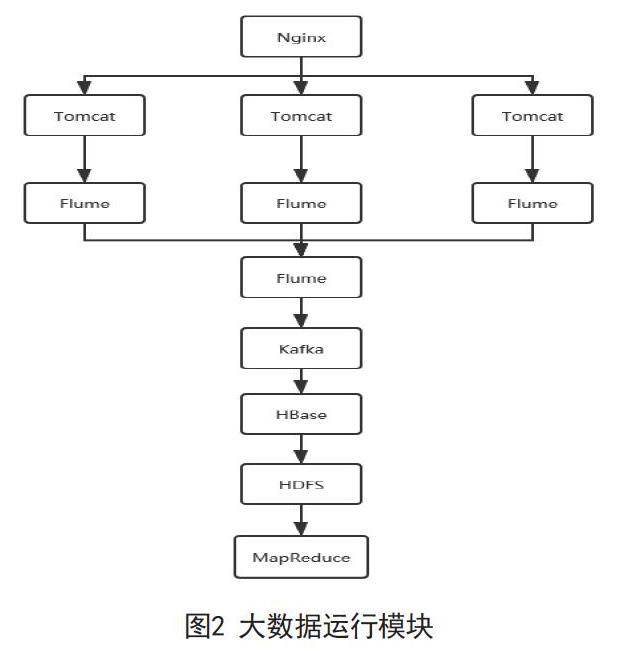
此外,该系统使用了数据-->flume-->kafka-->flume-->HDFS的数据采集模型,分布式发布订阅消息系统Kafka提供了对数据的缓存,保证了系统的高吞吐量,当收集信息遇到峰值时,Flume会在数据生产者和数据收容器之间做出调整,保证其能够在两者之间提供平稳的数据。由于采集到HBase的原生数据的格式无法满足我们对数据处理的基本要求,且数据量过于庞大,难以全部加载到内存中进行分析,这时HadoopMapReduce会将数据分到集群的每个节点进行运算,每个节点得到的数据又会构建成平衡二叉树的结构,通过对平衡二叉树进行遍历,就可以得到我们需要的数据,MapReduce高性能的计算能力方便了我们后面的统计分析,可以使我们根据不同的业务需求对数据进行处理。
2.2 个性化推荐技术
用户在访问智能图书馆系统时,系统会对用户的访问行为产生相应的埋点日志(比如点击、收藏、搜索等),这些埋点日志会被发送给系统的后台服务器,大数据模块会根据这些日志信息分析再结合用户的个人信息分析用户的访问行为,并得出一系列统计指标,根据这些统计指标进行系统的书籍推荐、广告推荐等工作。
上报到后台服务器的日志信息数据会经过数据采集、过滤、存储、分析、可视化这5个步骤,系统通过对海量用户行为数据的分析,可以针对用户建立精准的用户画像或者说是用户分类。同时,系统将根据对用户的行为分析,进行书籍推荐和广告推荐等工作。
用户在进入智能图书馆系统之后,session将会开始记录用户的操作,用户在访问系统的过程,就称之为一次session,当用户操作完毕、离开网站、关闭浏览器或者长时间没有做操作,那session就结束了。简单理解,session就是某一天某一个时间段内,某个用户进入系统,并进行了某些操作,最后退出的过程,就叫做session。
可以将session当做系统中的最基本的数据。对用户进行大数据分析,最基本的就是对用户访问session/用户访问行为的分析。
日志信息发送给后台web服务器(nginx),nginx将日志数据负载均衡到多个Tomcat服务器上,Tomcat服务器将会不断将日志数据写入Tomcat日志文件中,之后日志采集系统Flume会将采集到的数据写入到消息队列Kafka之中,之后消息队列Kafka会将数据存入分布式存储系统HBase,计算框架MapReduce将会从分布式存储系统HBase中拉取数据,然后根据数据信息对用户进行行为分析和分类,最后将提取出来的有效数据存入MySQL数据库。
3 结论与展望
为了更好地实现高校图书馆信息化,利用高校图书馆的智能推荐系统对我校现有的图书数据进行挖掘,实现对学生进行推荐图书的功能。图书馆的图书智能推荐系统的实现提高了学生自学效率和时间利用率并且改善对传统图书馆系统使用的流畅性。该系统通过大数据采集、过滤、存储、分析为高校学生实现个性化推荐,并且能够为图书馆带来更好的内在潜力和系统价值。
参考文献
[1]谢琳惠.推荐系统在高校数字图书馆的应用研究[J].现代情报,2006(11):72-74.
[2]丁雪.基于数据挖掘的图书智能推荐系统研究[J].情报理论与实践,2010(33):107-110.
[3]李卫华.浅谈数字图书馆个性化信息推荐系统[J].科技广场,2007(7):109-110.
[4]谢地.基于HBase的海量数据存储和快速检索[J].电脑知识与技术,2019(15).
[5]庄沅英.图书馆智能管理系统设计[J].计算机产品与流通,2018(10).
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
新闻传播(2018年12期)2018-09-19
小学生(看图说画)(2017年6期)2017-11-06
汽车与新动力(2016年6期)2017-01-04
雷达与对抗(2015年3期)2015-12-09
中国卫生(2015年1期)2015-01-22
自动化博览(2014年12期)2014-02-28
电子设计工程(2014年19期)2014-02-27
