
一种改进Mask R-CNN的运动目标定位方法
2020-12-16 00:56李景文陈文达姜建武
科学技术与工程 2020年31期
李景文, 陈文达, 姜建武*
(1.桂林理工大学广西空间信息与测绘重点实验室, 桂林 541004; 2.桂林理工大学测绘地理信息学院, 桂林 541004)
通过视频图像检测实现运动目标检测跟踪及其空间定位是当前图像处理与计算机视觉领域研究的热点问题之一。
近年来学者们提出了一些目标检测和跟踪算法,如肖军等[1]提出了一种基于光流法的运动目标检测与跟踪算法,通过选用Harris角点作为跟踪对象提高了角点检测对尺度变化的抗扰能力,却容易受到外界光线的干扰;刘晓悦等[2]提出一种改进的TLD(tracking-learning-detection)目标跟踪算法,将HOG-SVM(histogram of oriented gradien-support vector machines)结合替换原TLD算法中的2 bit BP(bit binary pattern)特征和集成分类器,但却难以实现多目标的检测。传统的特征提取方法因受到光照反射、复杂背景等因素的干扰无法对特定点进行精准定位,难以满足复杂场景下的定位精度要求。近年来,深度学习为目标跟踪提供了新的技术方法,如魏永强等[3]利用深度卷积神经[4]网络自动提取待跟踪目标的卷积特征来代替传统的手工特征,提高了跟踪算法在复杂干扰背景下的鲁棒性,但单纯的卷积神经网络难以提取深层次的语义信息。
针对以上方法的弊端,从提高空间定位精度角度提出一种基于Mask Region-CNN[5]和卡尔曼滤波的运动目标定位方法,以ResNet101作为特征提取器,实现了运动目标的检测与定位并拥有较强的抗干扰性能。
1 运动目标的空间定位过程
运动目标的空间定位主要包括数字信号采集、特征检测与优化、坐标投影换算三个步骤,主要思路是:通过网络摄像头捕捉视频流并转化为数字信号,将待检测影像传入模型,利用RoIAlign算法得到固定尺寸的特征图输出,匹配尺度不变特征变换(scale-invariant feature transform,SIFT)特征点建立空间坐标系统补偿运动轨迹,最后依据摄像机的位姿参数,通过空间投影换算方法将像素坐标点转换为实际坐标,输出成为连续的运动轨迹,其流程如图1所示。
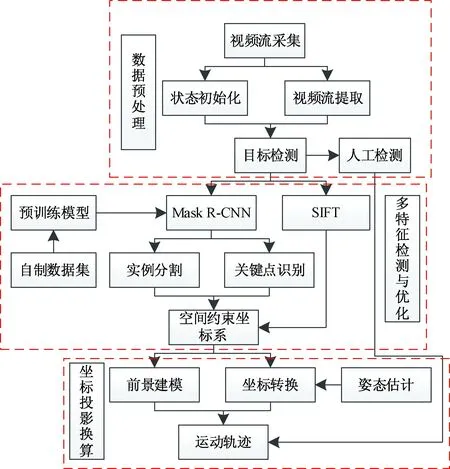
图1 运动目标空间定位的过程Fig.1 The process of spatial positioning of moving targets
2 多特征检测优化方法
特征检测方法的优劣决定了空间定位的精确度,基于深度学习的特征检测经过多年的发展已经取得了很大进步,但还是有许多问题需要得到改善,因此在Mask R-CNN特征检测方法的基础上提出多特征检测优化方法。
2.1 Mask R-CNN特征检测方法
Mask R-CNN是一种在Faster R-CNN的基础上添加一个掩膜预测分支的新型目标检测框架,其特征提取是采用特征金字塔网络和残差网络相结合的方法获取,能够更好地利用多尺度信息,并通过区域建议网络在不同尺寸的特征映射图上生成候选区域,并将其输入RoIAlign得到预测框,最后对预测框进行分类和回归,并生成检测物体的高质量实例分割掩码。
区域建议网络(region proposal network,RPN)是利用特征图计算代表物体在图像中位置的候选框结构,为每个位置生成9种预先设置好长宽比与面积的目标框Anchor。根据回归得出的4个修正坐标的值对每个Anchor的中心和长、宽进行修正,从而得到新的候选框。其损失函数为

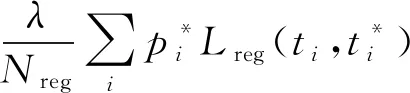
(1)
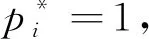
得到候选框之后,兴趣匹配层根据候选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归以及掩码的生成,RoIAlign使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。RoI Loss为
L=Lcls+Lbox+Lmask
(2)
式(2)中:Lcls为分类损失;Lbox为bounding-box回归损失;Lmask为分割损失。
Classifier利用了之前检测到的每一个RoI进行分类和回归,Mask则是在RoI之后通过Fully Convolution Network实现了语义分割。在训练的时候,Classifier和Mask都是同时进行的;在预测的时候,显示得到Classifier的结果,然后再把此结果传入到Mask预测中得到mask。
2.2 多特征检测优化方法
单一的目标特征信息只能从单一角度描述影像, 不能够全面立体地刻画影像内容,因此采用特征融合将具有不同特征信息的分层特征进行融合从而丰富特征信息,构建新的空间坐标系,进一步优化空间定位的准确度,如图2所示。
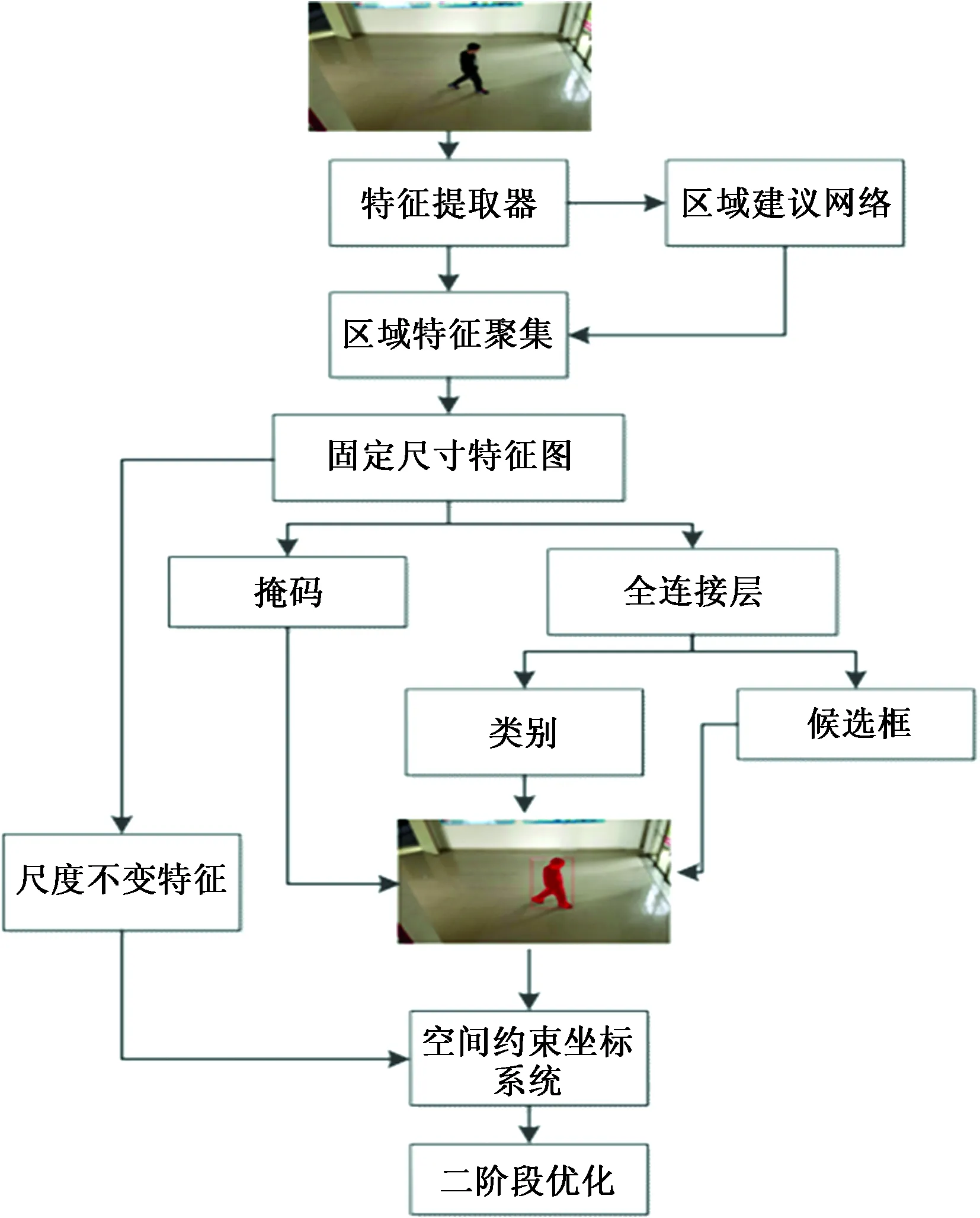
图2 优化Mask R-CNN流程图Fig.2 Optimized Mask R-CNN flow chart
为了解决复杂场景下无法建立稳定的空间坐标体系这一问题,将SIFT[6]算子与Mask R-CNN特征进行融合,在Mask R-CNN的基础上对不同目标建立特征图,通过匹配影像前后帧之间的特征点建立空间约束。
SIFT由可变尺度的高斯函数与图像卷积构建尺度空间,SIFT对图像缩放、旋转甚至是仿射变换均能保持不变性,其图像尺度空间表示为
L(x,y,z)=G(x,y,z)I(x,y)
(3)
式(3)中:G(x,y,z)为高斯函数;I(x,y)为原始图像。
SIFT特征表示了影响底层特征,缺少运动目标的空间信息,但其几何不变性相比Mask R-CNN较好,通过特征融合增强特征点的稳定性及抗干扰能力,建立更为可靠的空间约束。其融合后特征向量表示为
F=iFM+jFS
(4)
式(4)中:FM为Mask R-CNN特征,i为其权重系数;FS为SIFT特征,j为其权重系数。
由于受到外界条件的影响,每帧影像的特征会发生微小的改变,以上观测仅对像素进行了记录,并没有对速度进行观测,在该阶段获取的数据里包含了大量的噪声,使动态追踪变得困难,难以还原运动目标在时间序列下的真实情况。在考虑噪声属于white Gaussian noise,也就是这些偏差跟前后时间是没有关系同时符合Gaussian distribution的情况下,在Kalman filter[7]的基础之上提出了一种优化模型:
(5)
式(5)中:xk为k时刻的系统状态,就是当前时刻的坐标;uk是k时刻对系统的控制量;A和B是系统参数;yk是k时刻的测量值;H是测量系统的参数;qk和rk分别表示过程和测量的噪声。当他们属于white Gaussian noise,他们的covariance分别是Q、R。
对于时间和状态的变化,可表示为
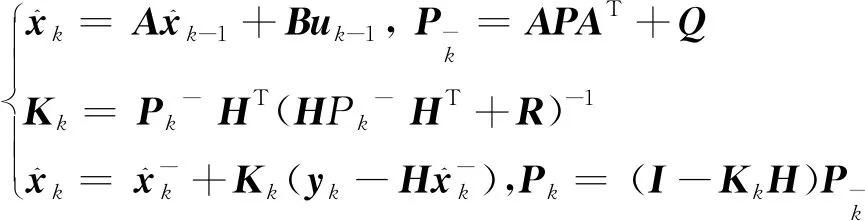
(6)
该框架根据运动目标的速度对定位坐标进行实时估计和修正,从而提高对运动目标定位的精度,得到更为可靠和更精确的位置和速度信息。
3 空间坐标投影换算方法
空间坐标投影方法通过三次转换将在特征检测获取到目标特征点的像素坐标转换为世界坐标三维空间内的坐标。像素坐标无法直接转换为世界坐标,要经过相机坐标和图像坐标。在现实场景中,摄影机的位置是固定的或临时摆放的,无法得知相机的外部参数。通过匹配世界坐标系里的参考点和在图像上的特征点及摄像机的内参K可以求得外参[8]。
(1)计算控制点在摄影机参考坐标下的坐标:
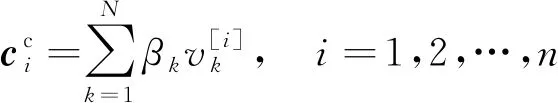
(7)
(2)计算参考点在摄影机参考坐标下的坐标:
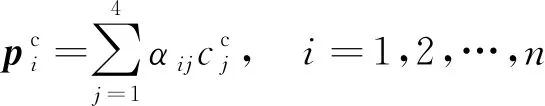
(8)
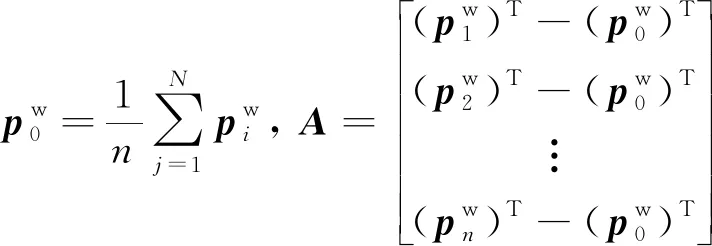
(9)
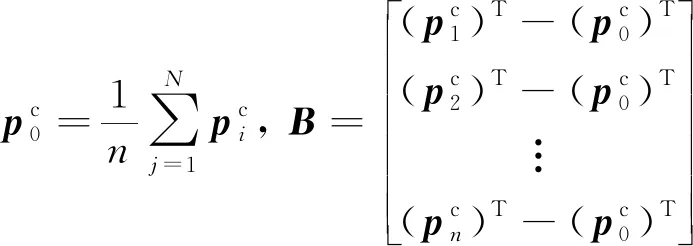
(10)
(5)计算外参中的R和t:
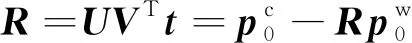
(11)
世界坐标系[9]、摄像机坐标系、图像坐标系、像素坐标系, 分别用(Xw,Yw,Zw)、(Xc,Yc,Zc)、(x,y)、(u,v)表示,具体方法如下所示[10]。

(12)
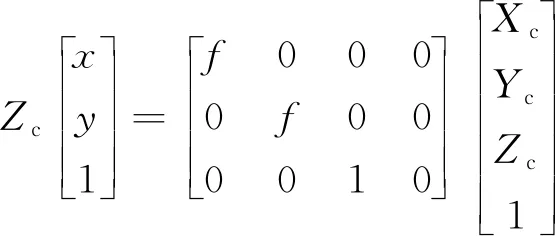
(13)
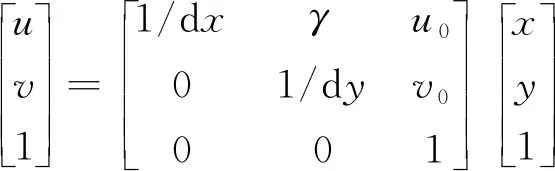
(14)
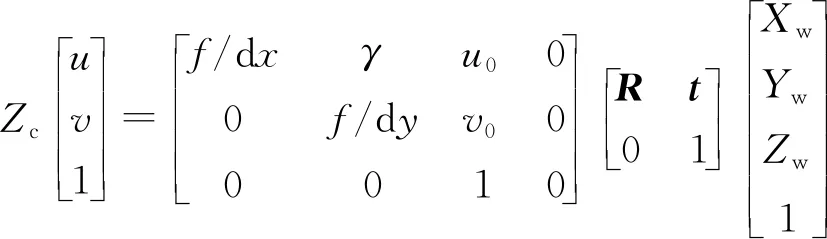
(15)
式中:R为正交矩阵;t为旋转向量;f为摄影设备的焦距;dx和dy分别表示x方向和y方向一个像素占的单位长度;u0、v0表示图像的中心像素坐标和图像原点像素坐标之间相差的横向和纵向像素,为相机的内部参数;γ为扭曲因子,通常情况下为0。将式(12)~式(14)合并,就得到式(15),R、t为相机的外部参数。最后简化得到式(16)[11]:
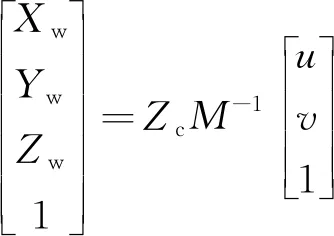
(16)
计算得到表1所示数据,分别为内参矩阵(dx,dy,u0,v0)、外参矩阵(R、t)[12],通过相机标定可以获得径向畸变(k1、k2、k3)与切向畸变(p1、p2)。

(17)
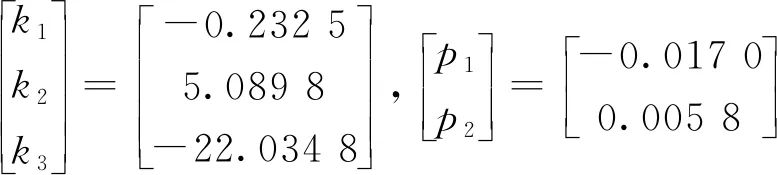
(18)

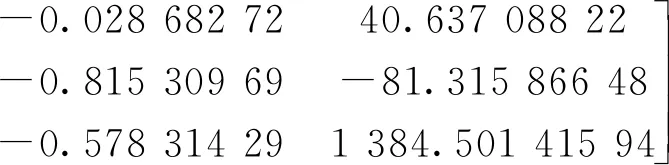
(19)
4 实验分析
4.1 视频流采集
本实验视频端采用单个网络摄像头进行捕捉,将摄像头采集到的RTSP(real time streaming protocol)视频流使用ffmpeg进行编码,推送给远程服务器,解码服务器将码流转换为能够处理的图像格式并直接输出为数字信号,最后每隔3帧进行一次检测。
4.2 模型训练
为了获得实验需要的模型,实验使用了Windows环境下的TensorFlow框架进行模型训练。数据集则是通过labelme对挑选的1 000张人物、车辆等图片进行标注,其中训练集有800张图片,测试集有200张图片,比例为4∶1,验证集包含500张不同场景下的人物图片,如图3所示。

图3 数据集标注过程Fig.3 Dataset labeling process
为了获取更好的特征,实验采用了ResNet101作为特征提取器,底层检测的是低级特征(边缘和角等),较高层检测的是更高级的特征。经过主干网络的前向传播,图像从 1 024×1 024×3(RGB)的张量被转换成形状为 32×32×2 048 的特征图。
RPN会在一个完整的图片上覆盖多种不同形状的anchors,anchors与标注的ground truth(GT box)的IoU(intersection over union)≥0.7为正样本,IoU≤0.3为负样本,IoU为预测框与和真实框的交集和并集的比值。
最终将迭代次数调整为30 000,设置初始学习率为0.000 1,GPU_COUNT = 1,当迭代到10 000,20 000次时,学习率改为原来的0.1 倍,总训练时间为80.3 h,如图4所示。
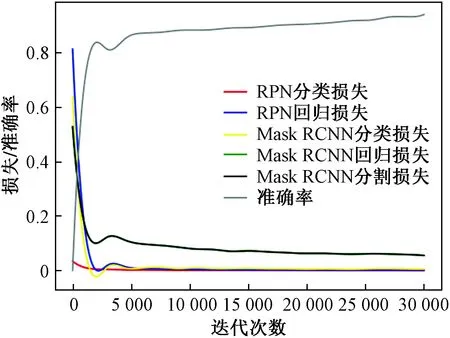
图4 准确率与损失函数Fig.4 Precision and loss function
4.3 数据仿真
通过训练完成后的Mask R-CNN模型对采集到的视频流进行关键点识别与SIFT特征融合构建坐标系统,在约束条件下对单帧影像检测结果如图5所示。上述实验所得的数据如表1所示,其中改进后的模型得到的坐标为本文数据的最终坐标,误差为该坐标和实际坐标的差的绝对值。图6为整个运动场景下的误差曲线分布图。

图5 视频分类检测、特征点匹配Fig.5 Video classification detection, feature point matching
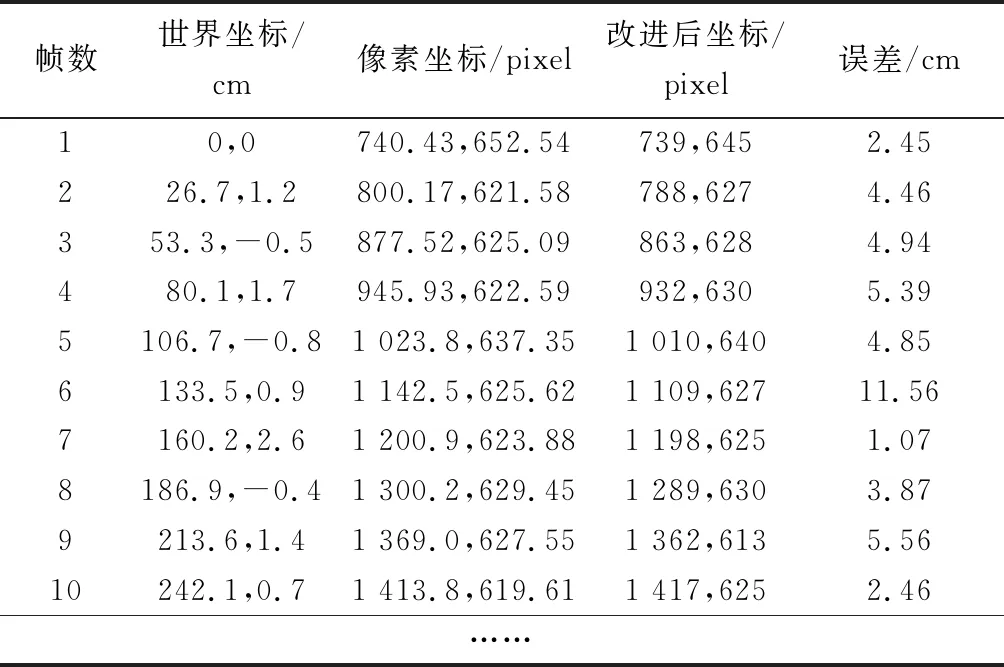
表1 检测点坐标
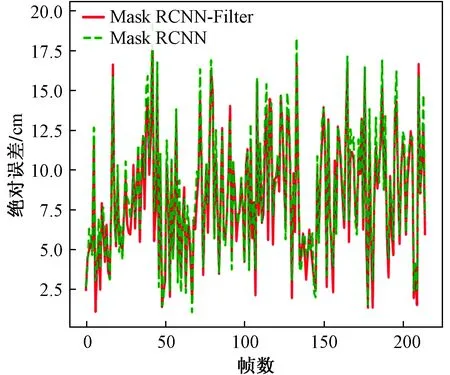
图6 误差分布图Fig.6 Error distribution
4.4 不同模型下的坐标定位精度
为了证实该模型的有效性,分别在不同检测模型框架下进行实验,建立空间坐标系统,得到表2所示数据。根据表2实验数据表明,Mask R-CNN在该方法中的表现最为出色,对目标的识别准确度可以达到90%以上并且在经过优化后的平均误差小于8 cm。
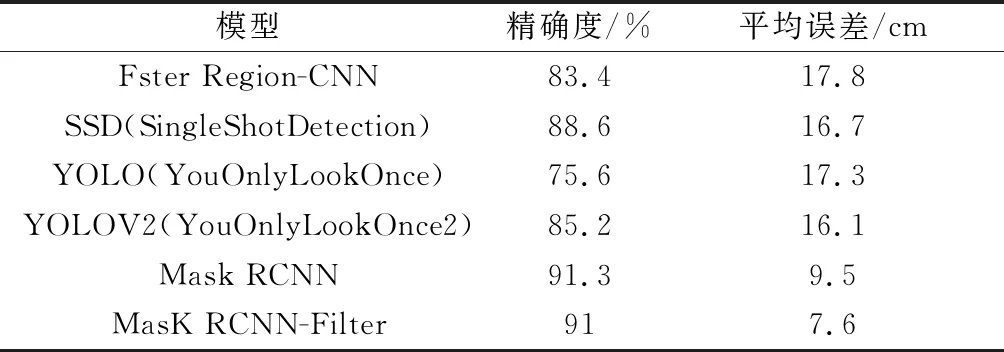
表2 不同算法比较
5 结论
结合Mask R-CNN和卡尔曼滤波器提出了一种运动目标定位模型,在Windows环境下的TensorFlow框架进行了数据训练,并通过训练模型对采集到的视频流进行检测分类及实例分割,提取目标的特征信息和坐标,根据提取出来的特征结合SIFT生成空间约束坐标系,进一步通过单目摄像机参数换算得到世界坐标结合卡尔曼滤波器优化。实验证明该方法可以有效提高追踪目标的定位精度,将平均误差控制在8 cm以内,相比其他模型拥有更快的训练速度和检测精度。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化·七年级数学人教版(2022年6期)2022-06-05
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
导航定位与授时(2020年5期)2020-09-23
中国外汇(2019年20期)2019-11-25
红领巾·萌芽(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
海峡姐妹(2018年2期)2018-04-12
CHIP新电脑(2016年3期)2016-03-10
