
基于IMI-WNB算法的垃圾邮件过滤技术研究
2020-12-16 02:43刘洁,王铮,王辉
计算机工程 2020年12期
刘 洁,王 铮,王 辉
(河南理工大学 计算机科学与技术学院,河南 焦作 454000)
0 概述
电子邮件能够为用户间的通信提供便捷,但垃圾邮件也随之产生。根据卡巴斯基信息安全网站Securelist发布的2018年全球垃圾邮件数据显示,中国成为全球第一垃圾邮件来源地,占全球垃圾邮件来源的11.69%[1]。垃圾邮件不仅占据大量的网络带宽和邮箱空间,容易造成网络拥堵,而且其包含一些恶意软件和钓鱼网站,可能会给用户带来巨大的经济损失。因此,对垃圾邮件进行过滤研究具有重要意义。
目前,关于垃圾邮件的过滤技术主要有基于黑白名单过滤技术、基于行为模式识别技术以及基于内容的过滤技术。其中,基于内容的过滤技术可行性较高、耗费较少,已经成为当前研究垃圾邮件过滤技术的主流方向[2-3],主要包括支持向量机(Support Vector Machine,SVM)、K邻近(K-Nearest Neighbor,KNN)、朴素贝叶斯(Naive Bayes,NB)等[4]。朴素贝叶斯分类器实现较为简单、且准确率高,已成为对垃圾邮件进行过滤的广泛应用分类方法[5-6],但该方法基于条件独立性假设,即假设条件之间完全独立,在一定程度上影响了分类结果的精确度。
在对垃圾邮件分类前,特征选择算法的优劣性对分类效果会造成影响,常见的几种特征选择方法有文档频率(DF)、信息增益(IG)、TF-IDF、开方拟合检验(χ2test)和互信息(Mutual Information,MI)等。其中,互信息效果虽然较差,但是该方法复杂度低、容易理解,是普遍使用的一种特征选择方法[7-8]。传统的互信息方法没有计算特征词的频度,可能会出现低频词汇的互信息值较高的情况,导致分类精确度受到影响[9-10]。
针对特征冗余和独立性假设的问题,研究人员对特征选择和分类算法进行改进,以提高邮件的分类精度。文献[11]将朴素贝叶斯、随机树和随机森林3种机器学习算法应用于垃圾邮件数据集,其分类精度高于仅基于贝叶斯分类器的算法。文献[12]提出一种支持向量机算法与K-均值聚类算法相结合的邮件分类算法,以提高分类精度、减少训练时间。文献[13]将互信息应用于加权朴素贝叶斯,通过加权部分消除朴素贝叶斯条件独立性假设对分类效果的影响,从而提高了朴素贝叶斯的文本分类效果,但该方法存在没有对传统的互信息算法进行改进的问题。文献[14]提出一种TSVM-NB算法,该算法利用朴素贝叶斯算法进行初次训练,并使用支持向量机算法构造最优分类超平面以降低特征项维度。同时,再次利用朴素贝叶斯算法生成分类模型,提高垃圾邮件过滤的速度和正确率,但该算法适用于属性向量重叠较大的语料集,对混叠性较弱的语料集的效率提升有限。文献[15]引入熵的思想,并结合MapReduce技术提出一种基于MapReduce的改进互信息文本特征选择机制,提高文本分类的精度。文献[16]提出一种基于MapReduce的并行特征选择方法,利用最大互信息理论选择信息丰富的特征变量组合。上述方法仅改进分类过程中的特征选择算法,并未联同分类算法对分类进行综合改进。
在以上研究基础上,本文提出一种基于改进互信息的加权朴素贝叶斯(Improved Mutual Information-Weighted Naive Bayes,IMI-WNB)算法。在特征选择阶段,引入词频因子以及类间差异因子对传统的互信息算法进行改进,实现特征降维。在分类阶段引入改进的互信息(IMI)值对朴素贝叶斯算法进行属性加权,实现对垃圾邮件的精确分类。
1 改进的互信息算法
1.1 互信息算法
垃圾邮件在经过文本预处理后引入大量特征项,然而大量的特征项对于分类没有意义,属于噪音特征,不对其进行降维处理将会影响垃圾邮件过滤的分类效果[17]。互信息算法是特征选择算法的一种,互信息值表示出特征项与类别之间的相关程度,且互信息值越大,则该特征项与类别的关联性越紧密。互信息值的计算方法为:
(1)
其中,w表示特征项,C表示类别,P(w,C)表示特征项w与类别C共同出现的概率,P(w)表示特征项在整个训练文本中出现的概率,P(C)表示训练文本中该类别在训练文本中出现的概率,P(w|C)表示特征项w在类别C中出现的概率。
m个类别训练文本的互信息值计算方法为:
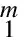
(2)
通过式(2)计算出互信息值,并选取合适的阈值,可针对分类不重要的特征项进行过滤,从而实现特征的选择。
1.2 基于词频因子与类间差异因子的IMI算法
1.2.1 词频因子
互信息算法的计算方式只考虑到特征词的文本频率而没有考虑到词频,这在一定程度上会影响其分类精度。例如,2个特征项wj和wq的文本频率相同,且特征项wj的词频是特征项wq词频的数倍,即tf(wj)>>tf(wq),一般认为词频更大的特征项wj与该类别的相关程度更高。然而按照传统互信息的计算方式,这2个特征项的互信息值是相同的,这显然与实际情况不符。因此,引入词频因子α对不同特征项间的词频差异进行描述,词频因子α可定义为:
(3)
(4)
其中,tfCspam(wi)与tfCham(wi)分别为特征项wi的垃圾邮件与非垃圾邮件类词频,dfCspam(wi)表示特征项wi的垃圾邮件类文本频率,dfCham(wi)表示特征项wi的非垃圾邮件类文本频率。
引入词频因子α后,改进的互信息值计算方法为:
(5)
特征项的词频高于文本频率时,词频因子的权重越大,说明该特征项对邮件分类的能力越强。
1.2.2 类间差异因子
如果特征项在2个类别中都平均分布时,则不利于类别的判定,在某一类别出现较多而在另一类别中极少出现,一般认为该特征项对于邮件类别的判别作用较大。在概率统计中标准差反映了数据集的离散程度,标准差较大的特征项更利于邮件类别的判定。通过计算垃圾邮件类Cspam与非垃圾邮件类Cham之间特征项wi频数的标准差对互信息模型进行改进。假设特征项wi在垃圾邮件Cspam类中的频数为tfCspam(wi),在非垃圾邮件Cham类中的频数为tfCham(wi),频数平均值为tfavg(wi),则有:
(6)
引入类间差异因子σ对类间词频差异进行描述,类间差异因子σ定义为:
(7)
(8)
引入类间差异因子σ后,改进的互信息值计算方法为:
(9)
式(9)在式(5)的基础上增加了类间频数差异权重因子,体现出类间频数差异对邮件分类的影响,提高互信息算法对有效特征项的选择效率。
1.2.3 IMI算法描述
算法1IMI算法
输入邮件特征向量集T={w1,w2,…,wn},特征子集维度k
输出特征子集F={w1,w2,…,wk}
1.计算P(Cham)和P(Cspam)
2.for i=1 to n
3.统计词频tfCspam(wi)和tfCham(wi)
4.统计文档频率dfCspam(wi)和dfCham(wi)
5.计算P(wi|Cspam)和P(wi|Cham)
6.计算P(wi)
7.式(2)计算互信息值MI(wi)
8.式(4)计算词频因子αi
9.式(8)计算类间差异因子σi
10.将式(2)、式(4)、式(8)结果代入式(9),计算IMI值
11.end
12.Sort(T) //将特征向量按IMI值降序排列
13.for i=1 to k
14.将特征项wi加入特征子集F中
15.end
算法1是IMI-WNB算法中特征选择阶段的算法,IMI算法改进了传统互信息算法中只考虑到文本频率而未考虑到词频的问题,定义并引入词频因子与类间差异因子,体现词频与类间词频差异对分类的贡献度,在完成特征降维的同时,还增强了特征项的表达能力。
2 基于IMI的朴素贝叶斯分类算法
2.1 朴素贝叶斯分类模型
朴素贝叶斯分类是基于贝叶斯定理与特征条件独立假设的分类方法,其通过计算已有的事件训练集得到事件概率,并对事件发生的概率进行预测。给定类别Cj与文本对象d时,贝叶斯公式可表示为:
(10)
其中,P(Cj)表示Cj类发生的先验概率,对于垃圾邮件分类,类别C可被分为垃圾邮件与非垃圾邮件,即C={Cspam,Cham}。P(Cj|d)表示在给定输入文本对象为d时,该对象属于类别Cj的后验概率。假设文本d的特征项为{w1,w2,…,wn},根据朴素贝叶斯条件独立性假设,则有:
P(d|Cj)=P(w1,w2,…,wn|Cj)=
P(w1|Cj)×P(w2|Cj)×…×P(wn|Cj)=
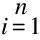
(11)
将式(11)代入式(10)可得:
(12)
先验概率P(d)为标准化常量,是一个常数。因此,朴素贝叶斯计算的最大后验概率类别Cmap如下所示:
(13)
为了避免大量较小数相乘造成下溢出问题,对式(13)乘积取对数可得:
(14)
2.2 基于IMI的加权朴素贝叶斯分类器
朴素贝叶斯分类算法是基于条件独立性假设的分类方法,然而在实际应用中,该独立性假设通常不成立。为了消除部分条件独立性假设对分类造成的不利影响,可通过在朴素贝叶斯公式中加入属性权重值以区分不同特征项对分类的贡献度。IMI值可以作为属性权重应用于贝叶斯分类中,当IMI值计算结果较大时,特征项与类别的相关性较高,当IMI值较低甚至为负值时,表示该特征项对分类的作用较小。互信息值可以在一定程度上表示特征项与类别之间的相关性,消除部分条件独立性假设对分类的不利影响。将式(13)中的后验概率赋予互信息权值可得:
(15)
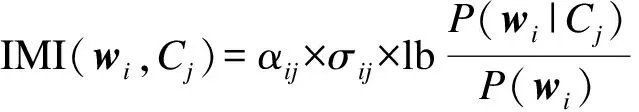
(16)
将属性权值代入上式并取对数可得:
(17)
为避免出现概率为0的情况,本文对互信息公式中的P(wi)和P(wi|Cj)进行拉普拉斯平滑处理,具体如下式所示:
(18)
(19)
其中,df(wi)表示特征项wi在整个训练集中的文本频率,dftotal表示整个训练集的文本频率,dfCj(wi)表示特征项wi在类Cj训练集中的文本频率,dfCj表示类Cj训练集中的文本频率。
IMI-WNB算法的实现过程如下所示:
算法2IMI-WNB算法
输入特征子集F={w1,w2,…,wk},邮件样本集D={d1,d2,…,dl}
输出样本集各样本所属类别C
1.计算P(Cham)和P(Cspam)
2.for i=1 to k
3.统计词频tfCspam(wi)和tfCham(wi)
4.统计文档频率dfCspam(wi)和dfCham(wi)
5.式(19)计算P(wi|Cspam)和P(wi|Cham)
6.式(18)计算P(wi)
7.式(1)计算互信息值MI(wi|Cspam)与MI(wi|Cham)
8.式(3)计算词频因子αij
9.式(7)计算类间差异因子σij
10.将式(1)、式(3)与式(7)结果代入式(16)计算得到IMI(wi,Cspam)与IMI(wi,Cham)值
11.end
12.for i=1 to l
13.for each wiin di
14.计算P(wi,Cspam)和P(wi,Cham)
15.将IMI(wi,Cspam)、IMI(wi,Cham)、P(Cham)、P(Cspam)与P(wi|Cspam)代入式(17)中进行计算
16.end
17.C(d,map)=max{C(di,ham),C(di,spam)} //判别类型
18.end
算法2是垃圾邮件过滤分类阶段算法,在通过特征选择阶段算法1获得特征子集后,算法2将IMI值作为属性权重值应用于朴素贝叶斯分类中,体现出不同特征项对分类决策贡献的差异,消除部分朴素贝叶斯条件独立性假设对分类的不利影响,从而提高分类精度。
2.3 IMI-WNB算法的垃圾邮件过滤流程
IMI-WNB算法的垃圾邮件过滤流程如图1所示。首先,在邮件预处理阶段对文本进行去停用词处理,然后再对文本进行分词,采用Python中文分词组件jieba对文本进行自动分词。其次,在特征选择阶段使用本文所提IMI算法对文本中的特征项进行特征选择。通过IMI算法可以将对分类无关的特征项筛选出去。最后,在训练阶段统计出样本中的先验概率与条件概率,并在应用阶段使用IMI-WNB分类器分类时代入计算,根据计算出的最大后验概率对邮件文本进行判定,当垃圾邮件概率大于非垃圾邮件概率时,分类器判定该邮件文本为垃圾邮件。

图1 IMI-WNB算法的垃圾邮件过滤流程Fig.1 Spam filtering procedure of IMI-WNB algorithm
3 实验结果与分析
本文使用trec06c邮件语料库对垃圾邮件进行过滤实验,并对IMI-WNB算法与传统的NB算法进行过滤效果对比。同时,为了更充分地体现本文算法的过滤效果与现实意义,实验将本文算法与其他改进算法进行过滤效果对比。
3.1 实验环境与数据
实验在Windows 10下进行,硬件配置为i5-7300HQ 2.50 GHz CPU,内存8.00 GB,硬盘500 GB。采用Python 3.7为实验环境。实验数据来自公开的垃圾邮件语料库trec06c,从中随机抽取14 000封邮件作为样本集,其中7 000封为正常邮件,7 000封为垃圾邮件。
3.2 评价标准
为了对垃圾邮件过滤效果进行评价,实验引入精确度P、召回率R和F值3个评价指标。假设垃圾邮件被判定为垃圾邮件的总数为Tspam,垃圾邮件被判定为正常邮件的总数为Fspam,正常邮件被判定为垃圾邮件的总数为Fham,则3个评价指标的计算方法分别为:
(20)
(21)
(22)
其中,精确度代表了垃圾邮件的检对率,正常邮件被误判为垃圾邮件会降低精确度,召回率代表了垃圾邮件的检出率,召回率低说明有大量垃圾邮件被漏检,F值为综合精确度和召回率的评价标准,其表示邮件过滤的综合效果。
3.3 实验结果
本文实验过程步骤如下:
步骤1对trec06c语料库中选取的邮件样本进行分词处理,建立停用词表去除文本中的停用词,并对文本进行特征选择。使用MI算法得到的特征项集为TMI,使用IMI算法得到的特征项集为TIMI。
步骤2分别从特征项集TMI与TIMI中提取n个特征项t1,t2,…,tn组建特征向量空间RMI与RIMI,在特征向量空间中分别利用NB算法与IMI-WNB算法进行分类。
步骤3将14 000封邮件样本平均分为10份,采用十折交叉法对样本进行计算,即每次选取其中9份样本作为训练集,1份样本作为测试集进行分类实验,每个样本均有一次作为训练集进行测试,每个维度总共进行10次测试,最后计算10次实验平均值作为该维度的数据结果。实验选取向量空间维度n从10到700对邮件进行分类,取平均值后绘制折线图。精确度、召回率、F值的实验结果如图2~图4所示。
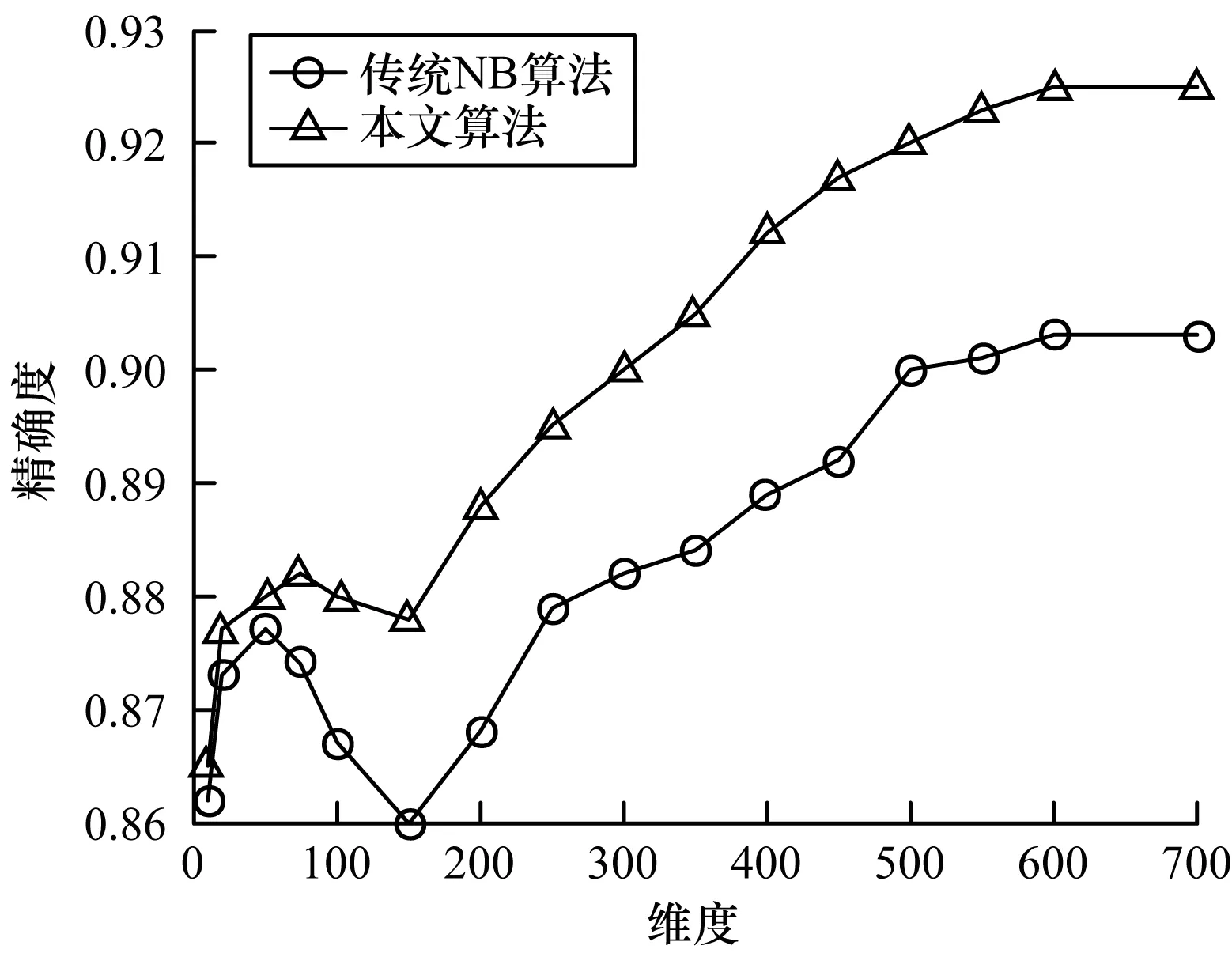
图2 2种算法的精确度实验结果Fig.2 Experimental results of precision of two algorithms
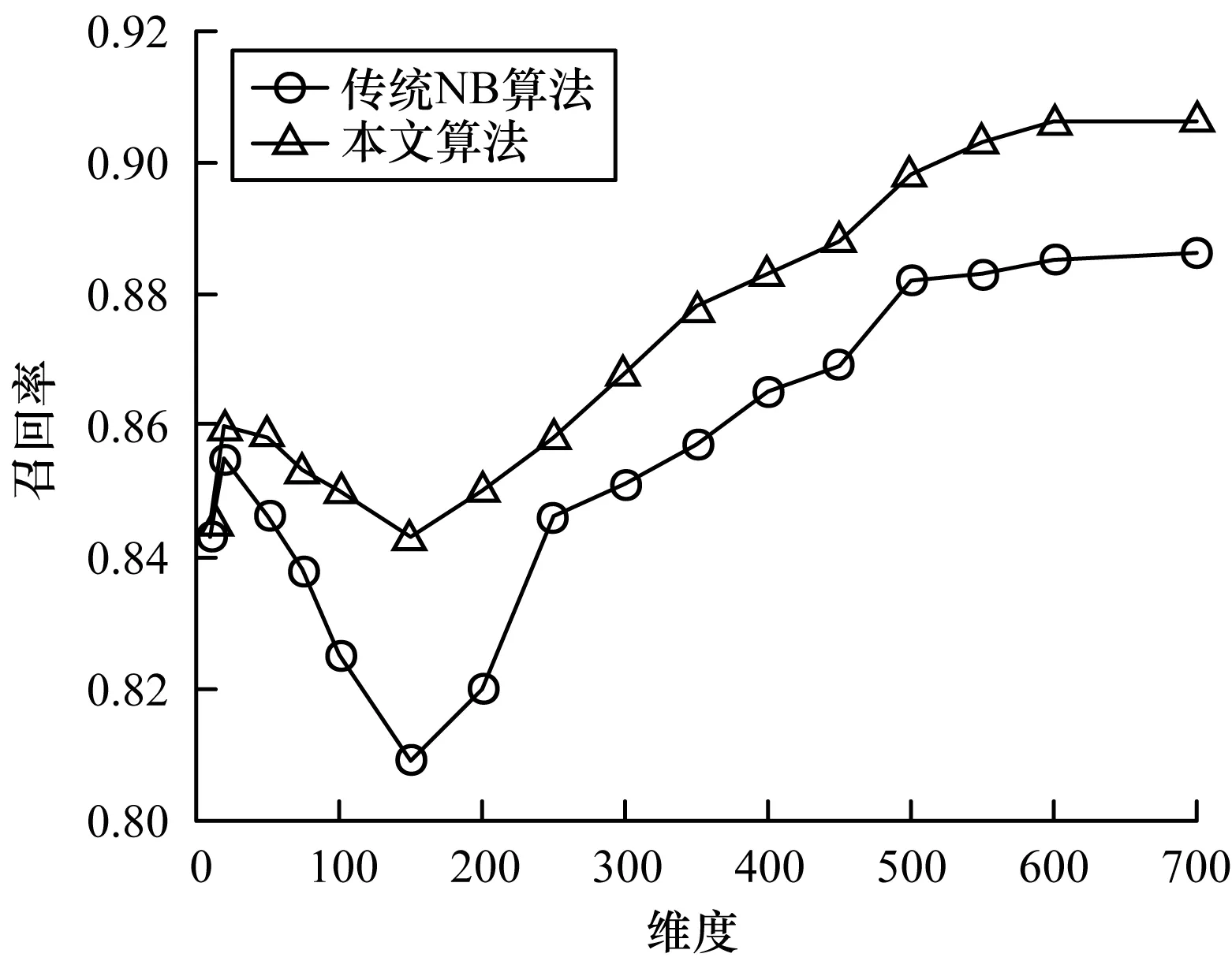
图3 2种算法的召回率实验结果Fig.3 Experimental results of recall rate of two algorithms
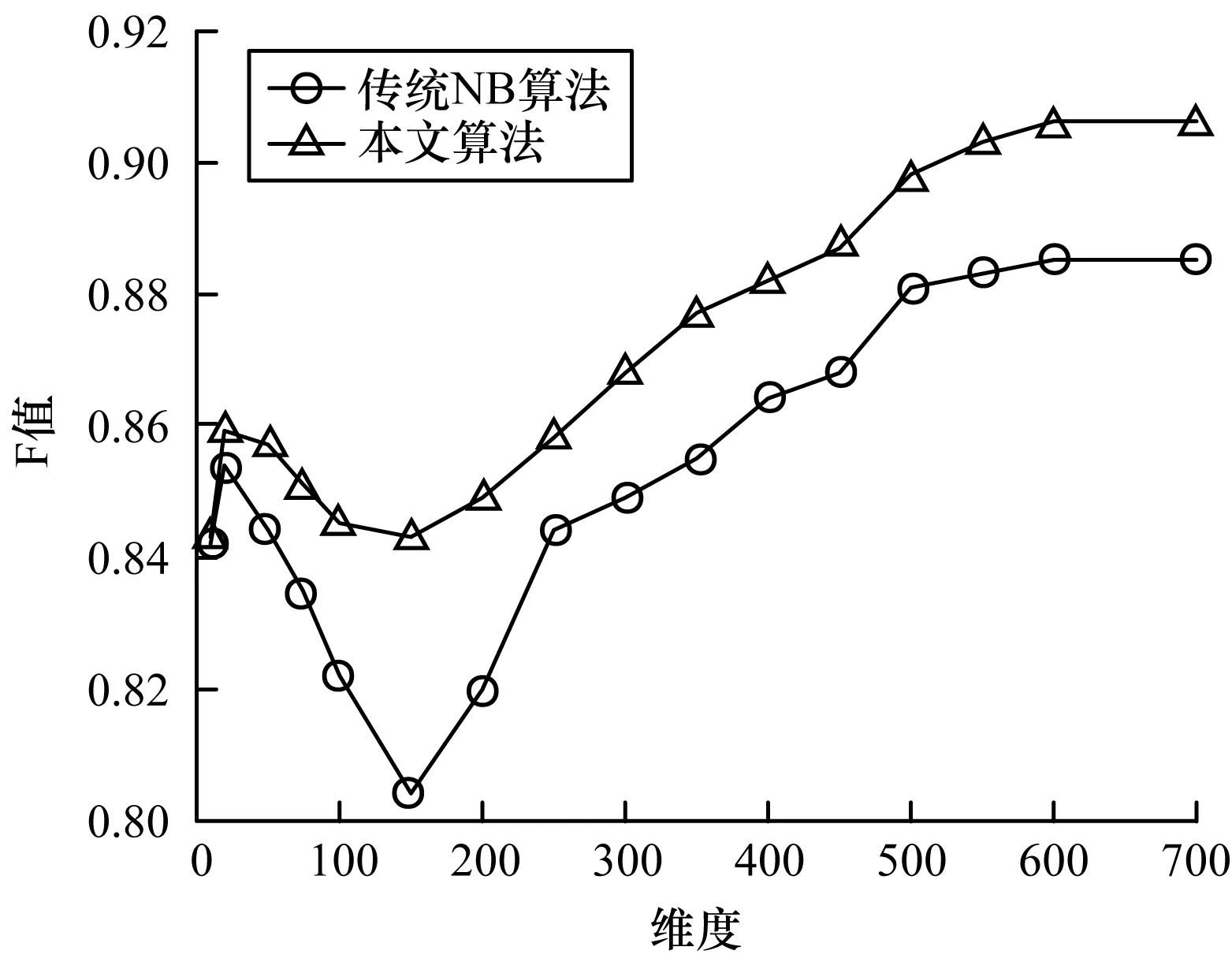
图4 2种算法的F值实验结果Fig.4 Experimental results of F-value of two algorithms
从图2可以看出:传统NB算法的精确度随着特征项维度的增大呈现先增大后降低再增大的趋势,且当维度为150时精确度最低,当特征维度达到500后,精确度逐渐趋于平缓;然而本文算法在低维度时的精确度与传统NB算法相差不大,当特征项的维度达到75后,其精确度开始下降,且在维度为150时达到最低,但其精确度受到的影响明显小于传统NB算法,且本文算法的精确度整体上高于传统NB算法。
从图3可以看出:传统NB算法的召回率在特征维度达到20后开始下降,当特征维度达到150时召回率降至最低,接下来随着特征项维度的增加召回率逐渐增加,当维度达到500时召回率趋于稳定;本文算法的召回率在特征维度为20时开始下降,但下降速度相对传统NB算法更加趋缓,且整体召回率高于传统NB算法。类似地,从图4可以看出,相比传统NB算法,本文算法的F值有明显提高,且波动更加平缓。
在使用trec06c语料库作为邮件样本进行邮件过滤时,本文算法与PTw2v算法[18]、C4.5算法[19]、GWO_GA算法[20]的性能对比如表1所示。从表1可以看出:PTw2v算法的精确度与召回率相差不大,且有较好的分类效果;本文算法相较C4.5算法召回率更高,说明C4.5算法存在较多的垃圾邮件被漏检,本文算法在F值上也高于该算法,说明本文算法具有更好的分类效果;GWO_GA算法的召回率较高,但在精确度上远低于本文算法,说明该算法存在大量的正常邮件被误判为垃圾邮件,且该算法的F值也略低于本文算法。
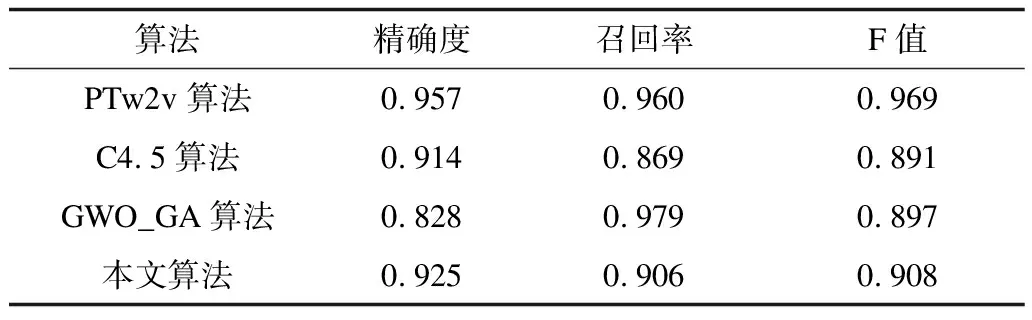
表1 4种算法的性能对比Table 1 Performance comparison of four algorithms
综合分析上述实验结果可知,相比传统NB算法,本文算法的精确度、召回率与F值明显提高,且变化趋势更加稳定。
4 结束语
由于传统互信息算法在特征选择中对于词频以及类间频数差异考虑不足,本文提出一种改进的互信息算法,并针对特征项在文本中的词频数以及类间频数差异对分类的影响进行分析与改进,有效利用训练集中的频数信息,弥补了传统互信息算法仅考虑到文本频率的缺陷。同时,本文对朴素贝叶斯算法进行属性加权并提出一种IMI-WNB算法,部分消除了朴素贝叶斯算法独立性假设对分类的不利影响。仿真实验结果表明,该算法明显提高了邮件分类的精确度、召回率、F值及稳定性,且取得良好的过滤效果。本文的邮件过滤技术是基于邮件的文本内容进行分类,然而除了邮件文本内容外,邮件还有题目、发送时间、收件人与发件人等邮件头信息可供分类判定。因此,下一步将利用加权朴素贝叶斯算法对邮件的文本内容与邮件头信息进行综合分析,以提高邮件过滤分类效果。
猜你喜欢
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
计算机与网络(2020年4期)2020-04-20
计算机应用(2016年10期)2017-05-12
中国修辞(2017年0期)2017-01-31
现代计算机(2016年11期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
读者·校园版(2015年7期)2015-05-14
弹箭与制导学报(2015年1期)2015-03-11
