
基于变分自编码器的异常小区检测
2020-12-23 06:00滕祖伟周杰华
移动通信 2020年12期
滕祖伟,周杰华
(中国联合网络通信有限公司湖北分公司,湖北 武汉 430020)
0 引言
在智能运维领域中,由于缺少异常样本,有监督方法的使用场景受限。因此,如何利用无监督方法对海量KPI进行异常检测是智能运维领域探索的方向之一。智能运维就是采用机器学习、数据挖掘等方法,来解决异常小区检测、故障根因分析、容量预测等运维领域中的关键问题。其中异常小区检测是在运维领域中非常重要的一个环节。
移动网络小区问题类型涉及多个方面,如无线覆盖、干扰、容量等。传统网优一般采集PM、配置等数据,再结合网优工程师的专家知识和经验,对各项指标分别设置阈值的方式,来发现网元是否存在高负荷、高干扰、覆盖差等异常问题。在网络复杂化和业务多样化的趋势下,网元运行指标众多,KPI数量一般达到30~60维度,传统工作模式简单粗放,存在准确率低、不能适应网络动态调整的问题。
本文提出了一种基于变分自编码器的异常小区检测方法,其基本原理是利用异常小区的KPI数据在通过变分自编码器编码与解码过程中所产生的较大波动来实现异常检测。一般说来,在机器学习中不平衡的训练样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别。在异常小区检测场景中,普遍存在的现象是正常样本数量远远大于异常样本数量,因此,当把不平衡的正常样本和异常样本都输入机器学习算法一起训练时,采用无监督方法就能把异常值检测出来。实验结果表明,该方法在样本不平衡的情况下,通过合理设置重构误差阈值,能够准确地检测出异常小区,其成果已应用于实际网优工作。
1 基于变分自编码器的异常小区检测
1.1 异常小区
要进行异常小区检测,首先要给出异常小区的定义:凡容量、覆盖、干扰等相关KPI指标取值超过期望值一定范围的小区就定义为异常小区。例如:
(a)容量类异常小区:凡是小区的最大连接用户数超过100个,或者下行业务流量超过10GB,或者下行PRB(Physical Resource Block,物理资源块)利用率大于90%,就认为是容量类异常小区;
(b)覆盖类异常小区:凡是上行平均DTX(Discontinuous Transmission,不连续发射)占比超过20%,或者下行平均DTX占比超过30%,就认为是覆盖类异常小区;
(c)干扰类异常小区:凡是PUCCH干扰超过-105 dBm,或者PUSCH干扰超过-105 dBm,就认为是干扰类异常小区。
本文只对异常小区进行检测,不对造成异常的原因进行分析。
1.2 变分自编码器
变分自编码器是一种用于特征提取的神经网络模型,其设计思路是通过对输入数据进行压缩和解压缩来重建输入数据,试图让输出和输入保持一样。它在设计架构上有Encoder(编码器)和Decoder(解码器)两个结构,其中,编码器将输入数据转化为隐含空间中更小更紧凑的编码表达,而解码器则将这一编码重新恢复为原始输入数据。由于它的隐含空间被设计为连续的分布以便进行随机采样和插值,因此可以具有类似正则化防止过拟合的作用。
变分自编码器的处理过程如图1所示:
①首先通过Encoder得到x的隐变量分布参数z_mean和z_log_var;
②然后从N(0,1)采样得到取值很小的随机数ε;
③接着把随机数ε联合隐变量分布参数z_mean和z_log_var得到隐变量z;
④最后利用Decoder将z重构成原始输入。
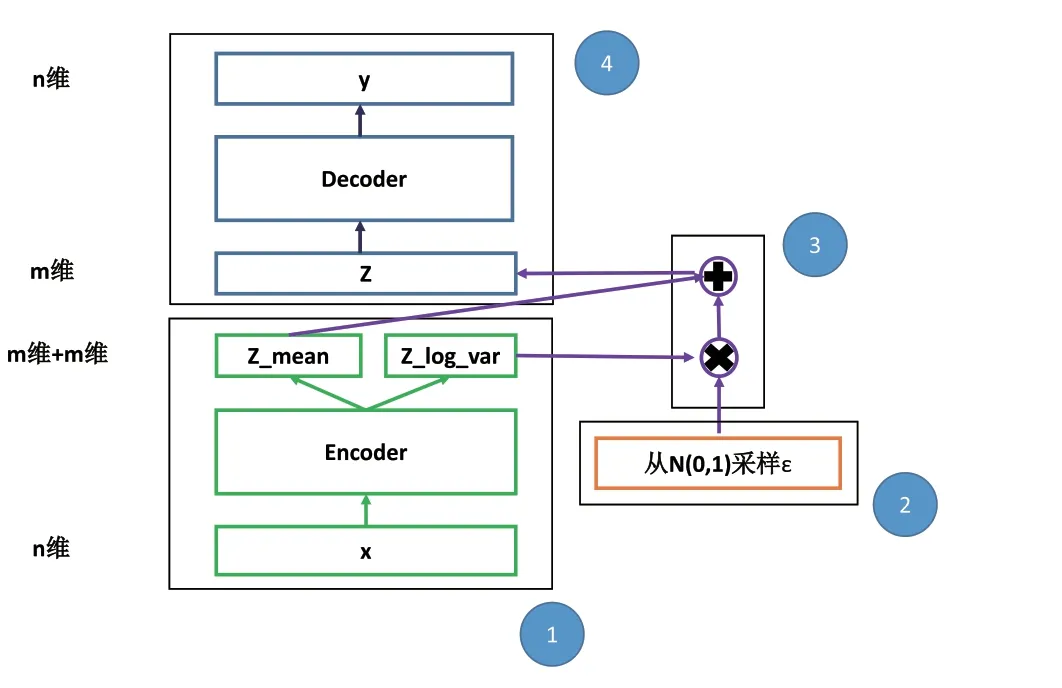
图1 变分自编码器处理过程示意图
VAE(Variational auto-encoder,变分自编码器)的参数通过两个损失函数来进行训练:一个是重构损失(reconstruction loss),它是模型的输入数据与输出数据之间的均方误差。在确定重构误差阈值时,通常参考重构误差的箱型图分布的上限值,例如,把箱型图的上限值设定为重构误差阈值。此时,将重构误差大于等于重构误差阈值的小区判断为异常小区,将重构误差小于重构误差阈值的小区判断为正常小区;另一个是正则化损失(regularization loss),它有助于学习具有良好结构的潜在空间,并可以降低在训练数据上的过拟合。
1.3 基于变分自编码器的异常小区检测
基于变分自编码器的异常小区检测流程分为三个主要阶段:数据采集阶段、模型训练阶段以及异常检测阶段。
(1)数据采集阶段
从OMC采集4G移动网小区的25个KPI数据,涉及容量、覆盖、干扰等类型,具体包括:RRC连接用户数,RRC最大连接用户数,RRC建立尝试次数,下行平均DTX占比,下行每TTI调度用户数,上行每TTI调度用户数,下行每TTI激活用户数,上行每TTI激活用户数,下行业务流量,下行信令流量,上行业务流量,上行信令流量,下行用户速率,上行用户速率,随机接入成功率,随机接入尝试次数,UE功率受限比例,上行平均DTX占比,上行PRB利用率,下行PRB利用率,CQI小于等于6占比,平均CQI,PUSCH干扰,PUCCH干扰等。
(2)模型训练阶段
首先,对小区KPI数据进行归一化处理,以消除不同标度对数据所带来的影响。
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
其中,
X.min(axis=0):每列中的最小值组成的行向量
X.max(axis=0):每列中的最大值组成的行向量
max:要映射到的区间最大值,默认是1
min:要映射到的区间最小值,默认是0
X_std:标准化结果
X_scaled:归一化结果
然后,设定变分自编码器模型网络结构,并进行模型参数训练。
(3)异常检测阶段
变分自编码器在对通过编码器后的数据进行解码还原时,会产生一定的误差。如果原始输入数据中存在异常,则生成的误差相比于常规误差有较大波动。因此,异常小区检测算法的具体步骤如下:
首先,对小区KPI数据进行归一化处理,用以消除不同标度对数据所带来的影响。
然后,利用变分自编码器模型参数对归一化后的数据进行平方误差的计算。如果输入样本为:X=(X1,X2,X3,…,XN),经过VAE重建的结果为则重构误差MSE为如果重构误差MSE值超过了预先设定的阈值,则判定小区KPI数据中存在异常。
1.4 准确性验证
采集武汉联通4G网络2019年4月18日—4月24日期间每隔1小时的25个KPI性能数据,共得到43150个小区的24小时*25个KPI分布向量。下面根据上述小区的KPI分布向量来分析基于VAE的异常小区检测方法的准确性。
随机挑选某异常小区25个性能KPI数据在一天24小时内的取值分布,发现具有高维度(25*24=600维)、局部异常的特点,如图2所示:

图2 异常小区性能KPI分布特征图
因此,根据小区KPI数据的特征和数量,变分自编码器模型的编码器采用典型的4层卷积神经网络,解码器采用若干卷积层,并采用重构损失和正则化损失函数来进行训练模型。然后,把43150个小区的24*25维KPI向量进行归一化,并按照8:2进行拆分得到训练集和测试集,其中,训练集用于训练变分自编码器模型,测试集用于评估模型检测准确性。
在样本不平衡的情况下,通过设定不同的重构误差门限,分别统计AE和VAE所检测出的异常小区数,验证检测准确率,如表1和表2所示。显然,本文所用VAE方法检测效果明显优于基于AE的异常小区检测效果。根据表1和表2数据绘制AE和VAE的检测准确率对比效果图,如图3。
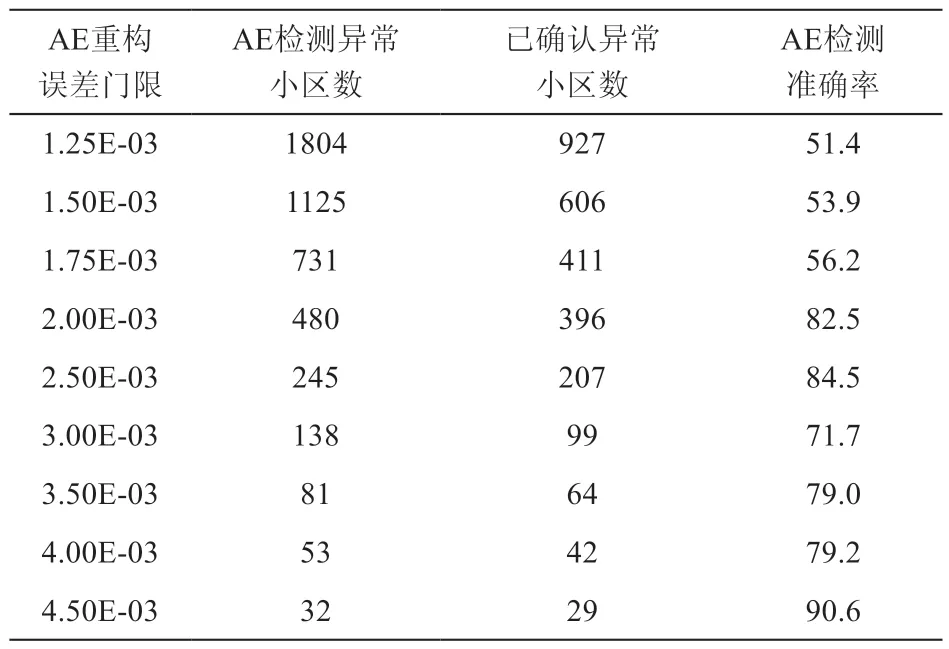
表1 基于AE的异常小区检测准确率统计

表2 基于VAE的异常小区检测准确率统计

图3 AE和VAE检测准确性对比
从图3可知:AE重构误差阈值越高,检测准确率呈上升趋势,但有少许波动,准确率低于90%。而VAE重构误差阈值越高,检测准确率呈明显上升趋势,特别是在VAE重构门限达到9.00E-17后,VAE检测准确率持续高于90%,且检测出的异常小区数最高能达到171个。两者差异原因在于:AE模型容易过拟合,当训练数据存在较多异常点的时候,可能模型的效果就不会特别好,也就是说当异常值占比较大的话,AE可能会过拟合(学习到异常模式)。而VAE学习到的是隐变量的分布(允许隐变量存在一定的噪声和随机性),因此可以具有类似正则化防止过拟合的作用。
2 结束语
本文介绍了VAE模型以及基于VAE的异常小区检测方法,在样本不平衡的情况下,通过合理设置重构误差阈值,能准确地检测出异常小区。但该方法面临一个问题:需要设置重构误差阈值。因为检测异常是通过对比重构后的结果与原始输入的差距,而这个差距多少就算是异常需要人为定义,然而对于大量的不同类型KPI,很难去统一设置阈值,这是采用VAE模型比较大的一个缺陷。
猜你喜欢
摄影世界(2022年1期)2022-01-21
医学食疗与健康(2021年27期)2021-05-13
知识经济·中国直销(2018年12期)2018-12-29
成都信息工程大学学报(2018年3期)2018-08-29
中国交通信息化(2018年5期)2018-08-21
商周刊(2017年6期)2017-08-22
电子设计工程(2017年20期)2017-02-10
山东大学法律评论(2016年0期)2016-08-16
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
