
一种基于空间密铺的星型Stencil并行算法
2021-01-05 03:05张云泉徐勇军陆鹏起张广婷
计算机研究与发展 2020年12期
曹 杭 袁 良 黄 珊 张云泉 徐勇军 陆鹏起 张广婷
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
2(中国科学院大学 北京 100049)
Stencil计算(模板计算)是科学工程应用中一类常见的嵌套循环算法,也被称为“结构化网格计算”,是13个伯克利核心计算模式之一.在动态规划、图像处理等领域的很多算法中也包含相似的依赖模式.Stencil定义了一种更新结点所需邻居结点的模式.Stencil计算在时间维度上迭代更新规则的d维网格(也称为数据空间),数据空间沿着时间维度更新,产生的d+1维空间被称为迭代空间.
与其他的数值算法不同,例如稠密或稀疏矩阵计算类型的多样性主要来源于输入数据如稠密或稀疏矩阵的数据量,Stencil的计算类型本质上取决于问题的类型.Stencil可以从不同的角度进行分类,如格点维度(1维,2维,…),邻居数目,即阶数(3点,5点,…),形状(盒型,星型,…),依赖类型(高斯-赛德尔,雅可比,…)和边界条件(常量的,周期的,…)等.
Stencil计算具有计算密集度低的特征,d维Stencil的简单实现由d+1个循环组成,其中最外层循环遍历时间维度,内层循环更新d维空间的所有格点.简单实现的数据重用度较差且典型的带宽受限.
分块是提高多重嵌套循环的数据局部性和并行度最有效的优化技术之一,目前有大量针对Stencil计算分块方案的研究.空间分块算法促进了2维至更高维度Stencil在一个时间步内的数据重用.为了进一步增强数据重用度,往往同时考虑时间维度和空间维度,后文将详细介绍这些技术.另一类工作采用简单的超矩形分块形状[1-4]并引入冗余计算来解决块间数据依赖.这些研究包括自动调优框架[5-12]、编程模型[13-14]、CPU[2,15-18]、GPU[19-23]和Phi[24-25]上的手动调优实现.
不同的Stencil类型也衍生出不同的解决方案.Pluto系统[26]延伸到周期性边界条件Stencil的处理[27].菱形分块最初是针对1维Stencil的分块[28],然后扩展到更高维度的Stencil[29].高速缓存参数无关(cache oblivious)方案从最初的算法[30-31],CORALS(cache oblivious parallelograms)方案[32],发展到能处理任意Stencil并达到最大并发度的Pochoir系统[33].
据我们所知,目前没有针对不同Stencil形状的解决方案,特别是盒型和星型Stencil.星型Stencil只依赖于每个坐标轴上的点,盒型Stencil在此之外还有对角线上的数据依赖.不区分盒型和星型Stencil的根本原因可能是盒型Stencil包含星型Stencil,任何适用于盒型Stencil的算法也能应用到星型Stencil.
本文首先在数据空间上提出“自然块”的概念来确定星型和盒型Stencil之间的区别.然后针对星型Stencil提出了一个新的2层密铺方案,在此方案中,自然块和它的后继块可以密铺整个空间,而他们沿着时间维度扩展后形成对迭代空间的密铺.密铺框架类似于文献[34]中提出的方法.我们将统一阐述基于自然块概念的2种方案并将已有的方案称为盒型密铺而将新提出的方案称为星型密铺.
在密铺方案中区别盒型和星型Stencil有2个主要的优点,分别利用不同层次上的数据局部性.首先,当给定缓存大小时,相比盒型密铺,用星型Stencil的自然块密铺能得到更大的块,这样可以更有效地减少内存系统的压力;其次,我们针对第二后继块中的元素提出了一个新颖的“2次更新”技术,可对1个元素连续进行2次更新,进一步提升了核心数据的重用.
1 相关工作
1.1 分块技术
分块技术[35-39]是探究多层嵌套循环数据局部性和并行度最有效的转换技术之一.Wonnacott和Strout[40]对比了一些现有分块方案的可扩展性,下面我们将总结一些和Stencil计算有关的技术.
1) 重叠分块(overlapped tiling).高性能领域中经常在手动调优的实现中采用超矩形分块[1-4].为了执行多个时间步,往往采用冗余计算[41]来解决分块之间的依赖,这就是重叠分块[28,42].Philips和Fatica[22]提出了GPU上手动调优的手写3.5维分块实现方案,在2.5维分块方案[4]上增加了时间维度上的划分.Demmel等人[43-44]减少了2倍的冗余计算.形状规则的超矩形可以获得更高的并发度和更多细粒度优化.
2) 时间偏移(time skewing).时间偏移分块[45-47](分块形状在2维上是平行四边形,在3维上是平行六面体,在更高维上是超平行体)消除了冗余计算,但是大多数方法只用单一形状的块填充空间,导致流水线启动和有限的并发度[48-49].
3) 菱形分块(diamond tiling).Bondhugula等人[26]对1维Stencil采用菱形分块.Bandishti等人[29,50]将此方法扩展到更高空间维度的Stencil.Grosser等人[51]对2维的菱形尖端粗粒度化形成六边形,在3维上演化成截掉顶端的八面体.
4) 缓存无关分块(cache oblivious tiling).缓存无关技术旨在内存层次结构参数未知时充分利用数据局部性.Frigo和Strumpen提出了第1个串行[30]和并行[31]缓存无关Stencil算法.缓存无关平行四边形方法[32]同时分离时间空间维度,但是会导致波阵面并行.Pochior[33]实现了多维空间划分,能够同时划分所有空间维度.
5) 分裂分块(split tiling).分裂分块方法发掘每个块中的独立子块,然后将这些子块发送给他们的后继块,使得剩下的区域同样可以并发执行[28,52-54].Grosser等人[55]提出了另一个类似于具有缓存无关范式的多维空间划分的分裂分块方法.嵌套分裂分块(the nested split-tiling)[56]能在所有空间维度递归分裂.
6) 混合分块(hybrid tiling).Strzodka等人[57]提出的CATS(cache accurate time skewing)算法结合了菱形分块、平行四边形分块和流水线处理.Grosser等人[58]采用混合六边形和平行四边形的分块算法.这些算法取某一维空间和时间维度组成平面,用六边形分块和菱形分块进行划分,在剩下的空间维度中采用时间偏移分块,从而分解迭代空间.混合分裂分块方法[56]结合了嵌套分裂分块和时间偏移分块.
7) 密铺分块(tessellating).密铺方案[34]适用于包括星型和盒型等不同Stencil类型.空间被一系列分块密铺,分块之间可以无冗余并行执行.相应地,这些分块在时间维度上扩展后得到的扩展块可以在迭代空间中形成密铺.简单明了的数学特性使得这种方法可以与细粒度优化方法相结合.
1.2 优化方法
为了使核心程序达到更高的性能,核心内的优化技术如计算重用[59-60]、计算重组[61]、向量化[15,62-64]和数据布局转换[65-66]等十分关键.但是这些方法大多没有对不同的Stencil形状进行区分.本文设计实现了一个新颖的技术来提升星型Stencil核心程序级别上的数据重用.这种技术也可以应用到其他的分块方法上.
2 算法描述
本节首先介绍一个新的概念,即自然块,来区分不同的Stencil形状特征.然后围绕自然块和后继块这2个方面,详细描述新提出的星型Stencil密铺方案以及已有的盒型密铺方案[34].最后将密铺方案应用于高阶Stencil和不同的边界条件.
Gauss-Seidel Stencil需要执行逐点45°流水线启动,使用分块技术也不能使其完全并发启动[28].因此我们仅考虑Jacobi Stencil.此外,星型Stencil只能应用到2维数据空间中,我们只讨论2维Stencil.在第5节的实验中,对于3维星型Stencil将保留1维数据空间不进行切分.
密铺3维迭代空间对应于计算2维Stencil,我们首先将其划分成多个相同的时间片.在一个时间片开始时所有格点处于同一时间维度,结束时所有格点都更新了t个时间步(在下面的例子中t=4).不失一般性,我们只讨论第1个时间片的密铺,即密铺前所有格点的时间维度均为0,密铺后所有格点的时间维度为t.

Fig. 1 Natural block B0(0)图1 自然块B0(0)
2.1 自然块B0(0)
当所有格点在时间维度上的值相同时,更新某一格点t个时间步所需的最小邻居点集被称为时间步为t的自然块,简称自然块.
图1(a)和图1(b)分别展示了2D9P盒型Stencil和2D5P星型Stencil时间步长为4的自然块.

最大更新方法[34]与自然块概念相近.具体定义为:在数据空间中给定B,沿着时间维度最大更新每个格点,直到不满足Stencil定义的依赖关系为止.形式上而言,对所有格点b∈B,满足以下2个条件中任一个时,停止更新:
1)time[b]=t,t是给定的最大时间更新步数;
2) 存在至少一个b的邻居b′,b′的时间维度严格小于b(time[b′] 但是这2种概念并不完全等价,实际上它们互为补充.一方面,最大更新没有给出密铺数据空间块的具体形状.盒型密铺[34]采用盒型Stencil的自然块(超立方体)来密铺盒型和星型Stencil,盒型Stencil包含星型Stencil,因此可以保证结果的正确性.在本工作中,我们将采用不同类型Stencil各自的自然块. 盒型Stencil自然块B0的形状是正方形,星型Stencil自然块的形状是菱形,这2种形状都能密铺2维数据空间.图2(a)和图2(b)(忽略灰色区域)分别表示盒型Stencil的4个自然块和星型Stencil的12个自然块.注意这些自然块可以并行执行. Fig. 2 Tessellating data space with B0图2 用B0密铺数据空间 (1) Fig. 3 Determining the center points of B1图3 由0确定B1块的中心点 后继块B1,B2等是对自然块B0进行分裂而后重组格点所产生的.分裂和重组的关键在于确定这些B1的中心点,之后每个格点可以简单地划分给离它最近的中心点.这种方法保证除边界上的点外,每个格点只属于某一个B1,并且B1可以密铺数据空间. 自然块的一个性质是中心点在时间维度更新步数最多,因此最显然的处理方式是将更新次数为0的格点凸集的中心点作为后继块的中心点.需要注意的是,后继块的中心点总在前驱块的边界上,只用考虑边界上标为0的格点凸集. 由图3可知,盒型和星型Stencil中所有标为0的格点分别在正方形和菱形的边界上.根据凸集的要求,4条边被视为4个凸集,因此方框中的4个格点0即为对应4个B1的中心点. 图4(a)和图4(b)中展示了由B0到B1密铺数据空间的转变过程,其中虚线代表对B0的划分,可以看到每个B0被划分成4个子块.图4(c)和图4(d)展示了用B1密铺数据空间的方法,其中共享同一个中心点的B0子块合并组成1个B1.经过此转变过程,盒型Stencil由4个B0转换为12个B1,星型Stencil由12个B0转换为16个B1. Fig. 4 Tessellating data space with B1图4 用B1块密铺数据空间 (2) Fig. 5 1图5 1 Fig. 6 Determining the center points of B2图6 由0和1确定B2的中心点 通过相似的步骤确定图6(a)和图6(b)中所示的2个0点是B2的中心点.从B1到B2的转换过程如图7(a)和图7(b)中虚线所示,由B2密铺数据空间的方式如图7(c)和图7(d)所示.盒型Stencil的密铺方式由12个B1转换为9个B2,星型Stencil由16个B1转换为13个B2. Fig. 7 Tessellating data space with B2图7 用B2块密铺数据空间 (3) Fig. 8 Natural block B2(2)图8 自然块B2(2) 解决周期性边界条件问题时,我们可能需要在1维Stencil中对1个块进行拉伸,或者在高维Stencil中拉伸1组块.采用拉伸过的六边形块来保证在目标维度2边的2个子块可以组成1个自然块. 基于第2节描述的数学框架可以手工实现代码.本节将介绍手工实现代码的具体细节.自动代码生成工具的实现将作为未来的工作. Fig. 9 Coarsening star tessellation图9 粗粒度化星型密铺 如图9所示,B0和B2块在数据空间中具有同样的形状.因此可以将相邻时间片的B0和B2块合并,减少一次同步并增加数据重用. 此外,从图9中可以看出,2个B0在某一维度的距离等于B0结束区域的大小,这使得B0的开始区域和B2的结束区域完全相同. 在同一阶段的所有块可以并发执行,因此很容易实现并行化密铺方案.因此,我们只在共享内存机器上简单使用OpenMP编译指示parallel for.对于分布式内存计算机,清晰的密铺方案使得我们可以实现一个简单的数据/计算分布以及高效的数据通信,留做下一步工作. 星型密铺方案只适用于2维Stencil,而且B1的计算很难向量化,因此我们只对此方案在3维星型Stencil上的计算性能进行评估.因为3维Stencil中每个维度上的大小通常小于1 000,我们选择不划分单位跨度维度来利用硬件预取的能力,采用pragma simd对最内层循环进行向量化. 代码实现主体包含5层循环,如算法1所示.最外层循环控制时间维度上时间片的切换,与分块相关的时间片大小为tB,t0即为当前时间片的开始时间.内部包含2个4层循环,第1个循环用来进行B0块和B2块的更新,第2个循环更新B1块. 第2个循环的第1层循环遍历所有B1块,在星型密铺中,B1块是沿2个不同的对角线方向合并产生的,可以按照对角线方向的不同将B1块进一步细分为B11块和B12块,对应的dy值分别为1和-1,同时根据B1块的位置可以确定对应数据空间区域边界xmin,ymax.第2层循环遍历B1所在的时间维度,跨度为tB,并根据t计算特定时间维度上对角线区域边界xmax,ymin.第3层循环遍历对角线区域中每条对角线,确定每条对角线的起始坐标x,y和结束横坐标xr.第4层循环遍历某一条对角线上的所有格点,每个格点被连续更新2次. 算法1.2D星型Stencil算法. 输入:时间步长tB;迭代空间上下界0,T;数据空间菱形边界xmin,xmax,ymin,ymax;数据空间(t,x,y); 输出:更新后的数据空间(t,x,y). ① fort0= -tBtoTsteptBdo ② #pragma omp parallel for private(xmin, xmax,ymin,ymax,t,x,y) ③ forn=0 toB0orB2do ④ fort=max(t0,0) to min(t0+2×tB, T) do ⑤set(xmin,xmax,ymin,ymax); ⑥update(t,x,y); /*在边界内更新B0和B2*/ ⑦ end for ⑧ end for ⑨ #pragma omp parallel for private(xmin, xmax,ymin,ymax,t,x,y,xr,dy,i) ⑩ forn=0 toB11orB12do Fig. 10 Performance of size 2563图10 问题规模为2563的性能 我们的实验运行在Intel Xeon E5-2670处理器上,处理器时钟频率为2.70 GHz,实验规模由单核扩展到所有12核.每个核独享32 KB L1 cache和256 KB L2 cache,12个核共享1个统一的30 MB L3 cache.使用版本号为16.0.1的ICC编译器编译程序并使用优化标志‘-O3 -openmp’. 将我们的方案与1.1节提及的2种高并发方案Pluto和Girih进行比较.盒型密铺、Pochoir和SDSL(Stencil domain specific language)[56]因其较差的性能结果(特别是3维Stencil)不作考虑.测试用例包括3种3维星型Stencil:1阶(3D7P)、2阶(3D13P)和4阶(3D25P)的具有非周期性边界条件的情况.测试的问题规模为2563×500,3843×800,5123×1 000. Girih提供一种自动调优组件来选择不同线程数时的最优分块大小.对于Pluto和星型密铺方案,我们将测试所有可能的分块大小,然后选择12核时性能最优的分块大小并应用于所有1~12核测试中. Fig. 11 Performance of size 3843图11 问题规模为3843的性能 图10~12分别显示了星型密铺(深色柱)、Girih(白色柱)和Pluto(浅色柱)在3D7P,3D13P,3D25P星型Stencil上大小为2563,3843,5123时的性能.其中性能GStencil的定义为:以最内层循环计算量看为一个Stencil,单位时间完成给定的Stencil迭代更新计算的次数为GStencil.由图10~12中可以明显看出,Pluto对应的性能条柱性能都比我们的代码和Girih低,且其结果不是一条直线,特别是在6核或更多核时.这和文献[29]中的结果一致.因此,下面主要分析星型密铺方案和Girih. Fig. 12 Performance of size 5123图12 问题规模为5123的性能 在问题规模大小为2563的3D7P星型Stencil中,星型密铺方案性能比Girih高,相比于Girih,星型密铺方案在2核时最高加速1.24倍,平均加速1.19倍.对于图10中更高阶的Stencil类型,我们的方案仍保持较高的性能,但随着阶数增加,这3种方法对应的性能柱变得更加接近,因为对于给定的自然块大小,更高阶的Stencil会产生更小的时间维度分块,造成更大的内存数据传输,后面将对此进行定量分析. 类似地,问题规模变大时3条性能曲线也会相互接近,也是因为Pluto和我们的密铺方案不对单位跨度的维度进行分块,导致时间维度分块大小受限.我们的方案在核数较少时仍取得了性能提升,在8~12核时虽然性能提升速度比Girih慢,但仍达到了可相比的性能.例如,在大小为3843的3D13P星型Stencil的实验结果中,星型密铺和Girih在12核上的性能分别为4.2,4.4 GStencil. Fig. 13 Memory transfers of size 2563图13 问题规模为2563的数据传输量 图13~15中显示了对应的最后一级cache和内存之间数据传输量.Girih利用整个L3 cache来最大限度开发数据局部性,因此具有最小的数据传输量.Girih在9个测试中的数据传输量都不规则变化,与密铺或Pluto的变化曲线不同,因为自动调优方案在不同核数时确定的分块大小不一样,例如,大小为2563的3D7P Stencil的Girih测量值在4核上是10.2 GBps,6核上是19.8 GBps,相应的菱形分块宽度最优值分别为32和16.Girih事实上是菱形分块和波前并行的混合方法,并采用细粒度并行,所有线程同时处理一个块,因此我们不对它进行理论分析. Fig. 14 Memory transfers of size 3843图14 问题规模为3843的数据传输量 Fig. 15 Memory transfers of size 5123图15 问题规模为5123的数据传输量 对于3D25P Stencil,星型密铺方案在3个问题规模上的最优分块大小分别是36×4,28×3,28×3,对应自然块大小分别为3.9 MB,4 MB,5.3 MB.因此30 MB的L3 cache将分别在8核,8核和6核时被完全使用,对应图13(c)~15(c)中星型密铺方案的数据传输量开始增长的位置.尽管核数更大时超出了L3 cache大小,但由于高阶依赖,数据块将快速收缩.此外,用时间维度块大小为2的分块密铺方案等价于原始算法,因此它们产生同样的缓存-内存传输量即T×N2.Pluto在3D25P Stencil上也有类似地变化趋势和原因. 对于另外2个低阶Stencil,L3 cache能保留所有12个核的自然块.例如大小为2563的3D7P Stencil中自然块占用内存为2.5 MB,12核将占用所有30 MB L3 cache.因此,星型密铺的带宽变化接近于水平.但是性能在核数变多时增长变缓,这可能是由于有限的L3带宽. 本文提出了一个新的并行框架,能够高并发执行星型Stencil,并以“自然块”的新概念来标识不同形状Stencil的特征.自然块及其后继块能够密铺数据空间,并且它们沿着时间维度扩展后能形成迭代空间的密铺.我们的方案能够导出简洁的并行框架,揭示一个格点的坐标和它更新时间步之间的关系.此外,专为星型Stencil研发了一个新颖的实现方式即“2次更新”,能够在第1个后继块的执行过程中对每个元素更新2次,从而改进核内数据重用模式.实验结果证明了此方法的有效性. 未来我们将着重于自动调优方法来高效寻找最优块大小,基于提出的框架设计一个工具来自动生成Stencil代码.2.2 用B0(0),B1(1)和B2(2)密铺




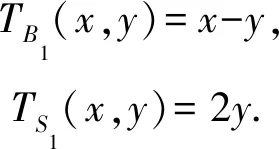





2.3 高阶Stencil和边界条件
3 实现方法
3.1 粗粒度化


3.4 并行化和向量化
3.5 代码实现
4 实验结果
4.1 实验环境
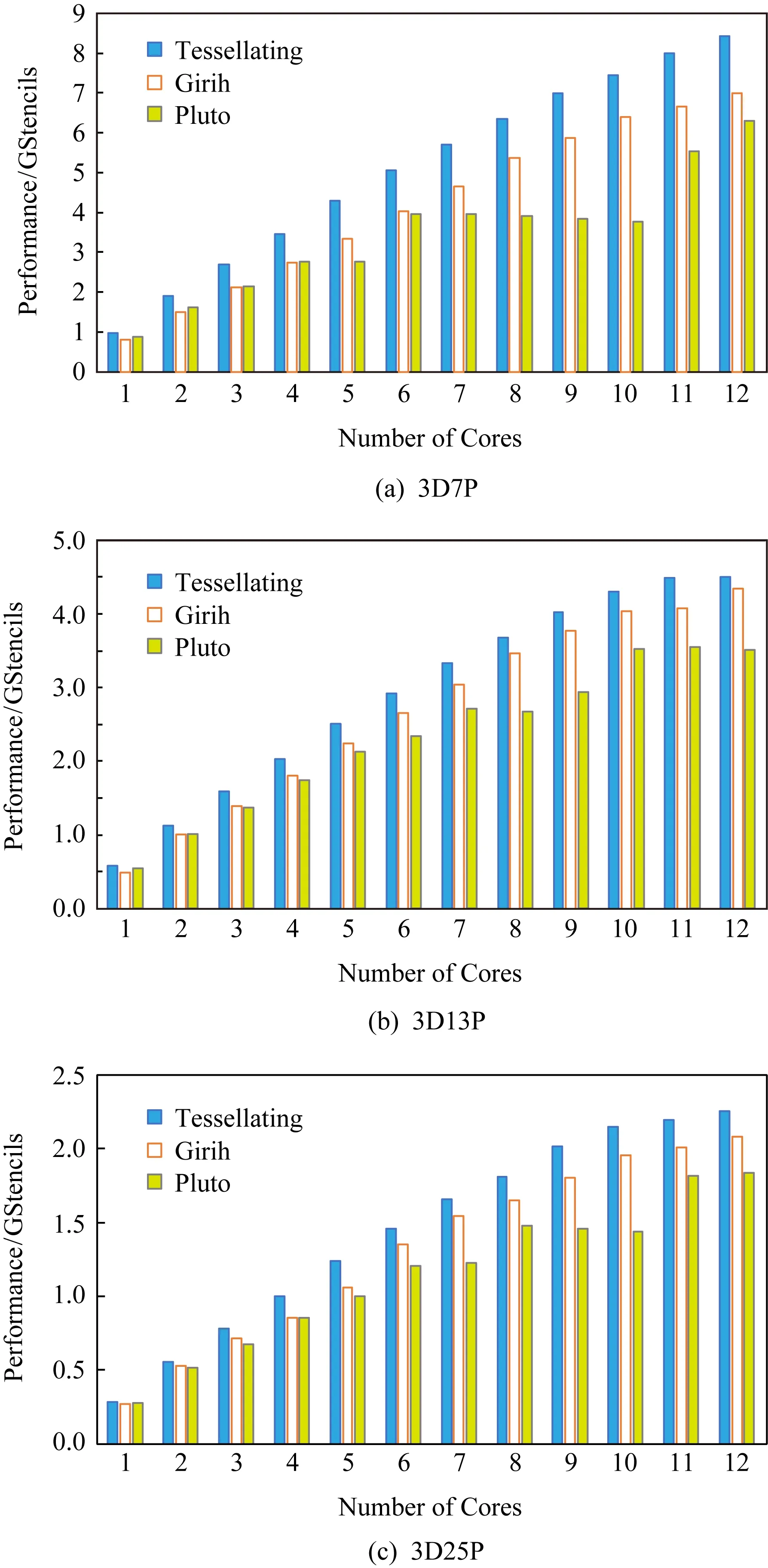

4.2 结果分析





4 总 结
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2022年4期)2022-04-19
房地产导刊(2022年4期)2022-04-19
初中生学习指导·中考版(2021年11期)2021-11-27
当代陕西(2020年22期)2021-01-18
数理化解题研究·综合版(2020年3期)2020-09-10
计算机应用与软件(2020年5期)2020-05-16
中华诗词(2019年7期)2019-11-25
新生代(2019年10期)2019-10-18
初中生世界·九年级(2018年8期)2018-09-08
