
基于集成学习的地质灾害危险性评价
2021-01-14 07:57崔阳阳邓念东曹晓凡邢聪聪
水力发电 2020年10期
崔阳阳,邓念东,曹晓凡,丁 一,邢聪聪
(西安科技大学地质与环境学院,陕西 西安 710054)
0 引 言
地质灾害危险性评价是对一个复杂系统的定量化分析过程[1]。近年来,随着GIS技术快速发展,基于GIS技术的地质灾害危险性评价不仅提高了工作效率,也提升了地质灾害管理的信息化水平[2]。随着机器学习的发展,地质灾害危险性评价模型由简单到复杂,由单一模型逐渐发展为耦合模型和集成模型。常见的单一模型有逻辑回归模型[3]、人工神经网络模型[4]、决策树模型[5]、支持向量机模型[6]等,该类模型对分类器的预测精度要求较高。耦合模型是将2种或2种以上的单一模型进行耦合,预测结果往往比单一模型更可靠。张俊等[7]人采用粒子群优化算法(PSO)与支持向量机回归(SVR)耦合模型对滑坡位移进行预测发现,PSO-SVR耦合模型的预测精度要明显高于BP神经网络模型和支持向量机模型;徐峰等[8]运用自适应变异粒子群优化算法(AMPSO)和支持向量机(SVM)耦合模型对三峡库区白水河滑坡位移进行预测表明,AMPSO-SVM耦合模型对于滑坡位移的预测性能优于BP神经网络预测模型和SVM模型;栗泽桐等[9]以青海沙塘川流域黄土梁峁区为例,对比分析了基于信息量、逻辑回归及两者耦合模型的滑坡易发性评价的技术流程及结果发现,两者耦合模型成功率明显高于其他单一模型。集成学习模型通过将多个单一学习模型按照不同的算法结合而得到,从而获得更准确、稳定和强壮的结果,其往往具有很高的预测精度。大部分集成学习模型分为分类集成学习模型,半监督集成学习模型和非监督集成学习模型3类。其中,分类集成学习模型应用最为广泛,包括一系列常见的分类技术,如Bagging、Boosting、随机森林等[10-12]。
鉴于单一模型与耦合模型对数据参数选取的局限性以及结果的差异性,本文基于集成思想分别采用Bagging、Boosting以及随机森林(RF)3种集成算法,对府谷县地质灾害危险性进行评价研究,并对预测结果以及模型的性能进行检验。该结论为研究区地质灾害危险性评价模型的确定以及后期区内地质灾害防治工程的设计提供参考。
1 研究区概况
府谷县位于陕西省最北端,地处陕、晋、蒙三省(区)交界处,隶属陕西省榆林市管辖,面积3 229 km2,属中温带干旱大陆性季风气候,年均气温 9.1 ℃,年均降水量428.6 mm。地形由东南向西北逐渐抬升,最大高程为1 414 m,最小高程为765 m,河流均属于黄河水系。区内地貌单元主要包括黄土梁岗、黄土梁峁沟壑、峡谷丘陵、河谷阶地等,地质构造总体上为一向西倾斜的单斜构造,地层东老西新,依次出露奥陶系、石炭系碳酸岩类和二叠系、三叠系、侏罗系碎屑岩类,地表多被第四系中、上更新统黄土以及全新统冲洪积层覆盖,岩土体较为松散。区内岩土体类型划分为坚硬块状碳酸岩类,层状坚硬~半坚硬砂泥岩互层碎屑岩类,层状较软弱砂质粘土碎屑岩类,粗砂砾石黄土状土、黄土,风成中细砂等。区内断层发育,主要发育F1、F2、F3、F4、F5共5组断层。区内主要人类工程活动有大范围采矿活动,市政设施、公路和铁路建设以及削坡建房、坡地耕种等。据统计,境内地质灾害主要类型分为崩塌、滑坡、泥石流和地面塌陷4类,共计184处。地理位置及灾害点分布情况见图1。

图1 研究区地理位置及灾害点分布
2 评价模型简介
2.1 Bagging算法
Bagging算法又称装袋法,是在同一种基分类器下对训练样本使用Bootstrap抽样法训练多个基分类器,最后通过投票法得出结果[13],可有助于降低训练数据的随机波动导致的误差。Bagging算法最常用的不稳定基分类器有决策树(Decision Tree,DT)和神经网络(Neural Net-works,NN)。本文选取决策树作为集成模型的基分类器,对研究区地质灾害危险性进行评价。
2.2 Boosting算法
Boosting 算法是一种将弱学习器转换为强学习器的迭代方法。通过增加迭代次数,产生一个表现接近完美的强学习器[14],被认为是统计学习中性能最好的方法之一[15]。Boosting算法通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,使分类器对于误分的数据有较好的效果,依据此规则得到最终的Boosting模型。
2.3 随机森林算法
随机森林(RF)是一种结合装袋法(Bagging)生成多个独立的样本集和多棵分类回归树(Classification and Regression Tree,CART)来进行预测的集成学习方法,结果由投票得分最多或取平均决定[16-18]。其主要思想在于多个弱分类器经过一定策略进行组合,形成一个较单一分类器预测性能更加优越的集成模型。
随机森林算法具体实现过程如下:利用装袋法从总的样本中随机有放回地抽取n个(与总样本数相同)样本作为独立空间训练样本集,对每个训练集分别建立决策树。其中,从总的特征数中随机选取m个特征数(m≤特征数)进行内部节点分支,得到n棵独立的随机决策树,将n棵决策树所得结果采取投票原则或取其平均值作为最终预测结果[19-20]。
3 指标因子构建
本文用到的数据来源主要包括:①府谷县地质灾害详查报告;②府谷县1∶50 000地质图、地貌类型图和岩土体类型图;③府谷县分辨率为30 m的DEM数字高程数据;④府谷县 1∶50 000的路网图与水系图;⑤30 m分辨率的Landsat8遥感影像图。根据研究区面积以及地质灾害规模,本文采用30 m×30 m的栅格作为地质灾害预测的评价单元,共划分为3 553 404个栅格。
通过地质灾害详查报告获取地质灾害点位置坐标,利用ArcGIS 10.0软件转化得到地质灾害点图层。利用ArcGIS工具对DEM影像处理,得到高程、坡度、坡向、坡度变率、坡向变率、平面曲率、剖面曲率和曲率图层;利用地貌类型图提取研究区地貌类型,利用ArcGIS工具对其按不同地貌类型进行重分类、面转栅格等操作获得地貌类型图层;同上,利用岩土体类型图和地质图分别提取研究区岩土体类型和断层分布,按不同岩土体类型进行分类,对断层进行欧氏距离分析,得到地质灾害点到各断层的实际距离;利用EARDAS软件对Landsat8遥感影像处理得到研究区归一化植被指数(NDVI)图层;根据研究区年降雨量资料利用ArcGIS工具采用克里金插值获得降雨量等值线图层;利用ArcGIS对路网图以及水系图矢量化,然后用欧氏距离分析工具获得地质灾害点到各要素的距离。提取得到的各因子图层见图2、3、4。

图2 各评价因子图层(一)

图3 各评价因子图层(二)
4 地质灾害危险性评价
采用ArcGIS软件栅格转点工具提取地质灾害点图层以及15类评价因子图层数据,构建地质灾害危险性评价数据库。选取所有灾害点与相等数量的非灾害点数据作为样本点,将灾害点随机分为2个部分,一部分(总灾害点的70%)作为训练样本数据,剩余部分(总灾害点的30%)作为测试样本数据。将样本数据导入R语言中进行训练,得到基于Bagging、Boosting以及RF的危险性评价模型,然后提取整个研究区的数据带入训练好的模型中计算,得到研究区地质灾害危险性指数。将地质灾害危险性指数通过ArcGIS软件赋值到研究区图层中,采用自然间断点法将研究区划分为5个等级(极高危险区、高危险区、中危险区、低危险区和极低危险区),得到基于集成学习算法的研究区地质灾害危险性区划图(见图5)。Bagging、Boosting及随机森林(RF)3种模型的预测正确率分别为76.36%、74.54%和77.28%,均大于70%,预测精度较高。

图4 各评价因子图层(三)
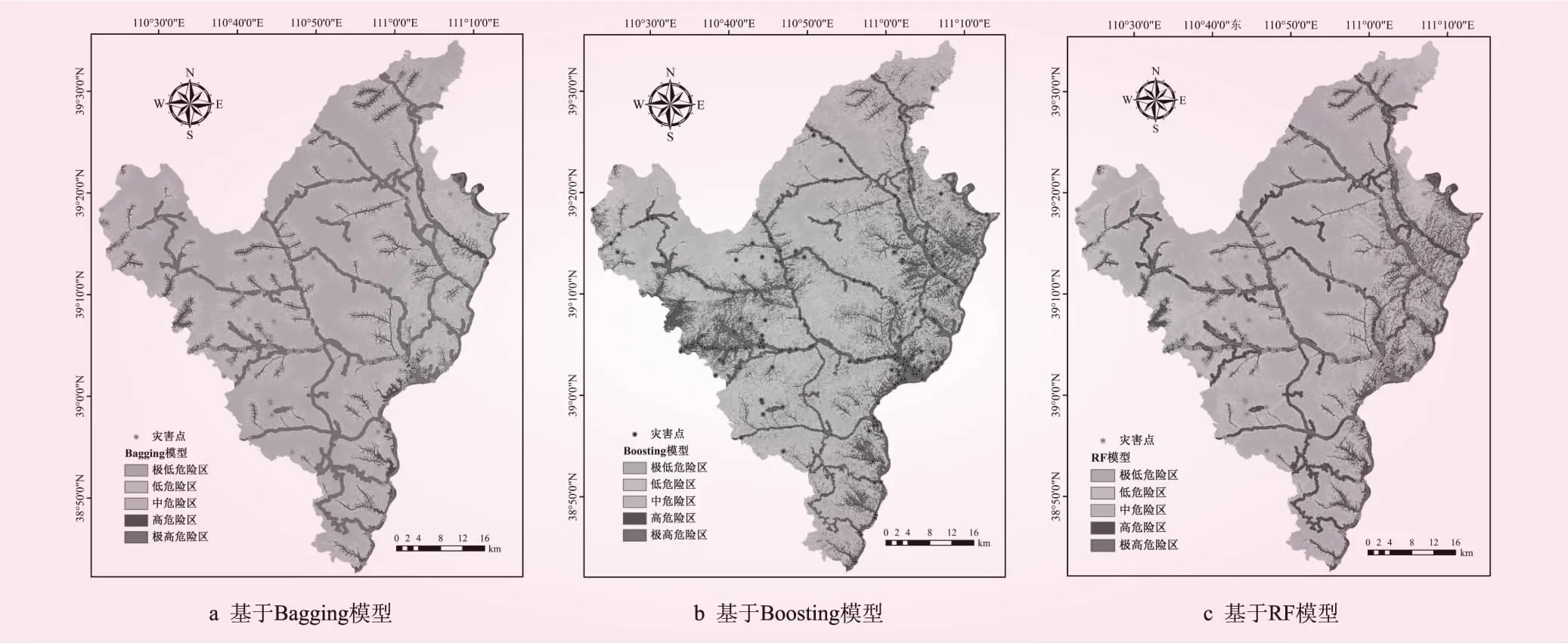
图5 研究区地质灾害危险性区划
本文利用受试者工作特性曲线(Receiver Operating Characteristic,ROC),对3种模型的性能进行检验与对比。ROC曲线横坐标代表特异性,即非灾害点预测为灾害点的占比;纵坐标表示敏感性,即灾害点预测为灾害点的占比。曲线下的面积(AUC)代表模型精确性,AUC取值范围为[0,1],值越大代表模型性能越优越。将3种模型测试数据计算得到的危险性指数带入SPSS软件进行分析,得到3种模型的预测率曲线(见图6)。由图6可知,通过对比3种模型的AUC值可以发现,3种模型的预测精度均较高(AUC>0.7),RF模型在地质灾害空间预测中表现得更好(AUC>0.8)。

图6 3种模型的预测率
根据地质灾害危险性区划图,运用ArcGIS软件多值提取至点功能分别统计各危险性分区内历史灾害点数所占总灾害点的百分比见图7。从图7可知,在Bagging、Boosting以及随机森林(RF)3种模型的结果中,历史灾害点在高~极高危险区所占的比例分别为77.17%、89.67%和91.85%,表明RF模型较其他2种模型历史灾害点在极高~高危险区分布更为集中,其更适用于地质灾害危险分析的实际应用。

图7 各危险区历史灾害点所占比例
5 结 语
本文以府谷县作为研究区,选取了地形地貌类、地质类、水文类、人类工程活动等15种评价因子,结合历史地质灾害点数据,分别采用Bagging、Boosting及随机森林(RF)3种集成学习模型,对该区地质灾害危险性进行了分区评价研究。结论如下:
(1)Bagging、Boosting及随机森林(RF)3种模型的预测正确率分别为76.36%、74.54%和77.28%,预测精度均较高。
(2)通过ROC曲线对比分析,Bagging、Boosting及随机森林(RF)3种模型的AUC值分别为0.792、0.799、0.815,3种集成模型在研究区地质灾害危险性评价的精度均较高,RF模型的性能较其他2种表现更为优越。
(3)分别统计各危险性分区内历史灾害点数所占总灾害点数的百分比表明,Bagging、Boosting及随机森林(RF)3种模型下的历史灾害点在高~极高危险区所占的比例分别为77.17%、89.67%和91.85%,RF模型较其他2种模型灾害点在极高~高危险区分布更为集中,更适用于地质灾害危险分析的实际应用。
猜你喜欢
广东水利水电(2022年10期)2022-11-08
化学工业与工程(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2021年36期)2021-10-15
水上消防(2021年3期)2021-08-21
有色设备(2021年4期)2021-03-16
照相机(2021年11期)2021-02-03
摄影之友(影像视觉)(2018年1期)2018-03-22
科教导刊·电子版(2017年34期)2018-01-31
科技传播(2011年17期)2011-08-15
数码(2009年3期)2009-03-16
